
以前、S3ってなんじゃ?(s3cmd編)の記事を紹介しましたが、先日s3cmdで調査が必要な場面に遭遇したため、
今回はその件について紹介したいと思います。
○問題
WEBサーバからS3へのファイル同期にs3cmdを使ったプロジェクトがありました。
しかし、linuxのサーバからS3へファイルを同期するのにs3cmdのsyncコマンドを使用しており、
その同期がとても遅いというのです。
ローカルで1ファイルを追加したとしても同期の度に数時間かかっているようでした。
確認してみたところ、同期対象のS3バケットに数百万という数のファイルが存在しており、
それが問題となっているようでした。
そこで、対処方法を調べてみました。
○再現
まず、手元のEC2環境で同じ状況を再現してみます。
適当なディレクトリにgitからある程度サイズのあるプロジェクトをいくつかcloneします。
# mkdir /root/dist
# cd /root/dist
# git clone https://github.com/mirrors/perl.git
# git clone https://github.com/apache/cassandra.git
# git clone https://github.com/v8/v8.git
# git clone https://github.com/symfony/symfony.git
# git clone https://github.com/torvalds/linux.git
# ls -lR | wc -l
72694
ファイル数がこの位あれば、ある程度のシミュレートができそうです。
まずはs3cmdをインストールしますが、今回はyumを使用します。
# curl http://s3tools.org/repo/RHEL_6/s3tools.repo
# curl -OL http://s3tools.org/repo/RHEL_6/s3tools.repo
# sed -i -e s/enabled=1/enabled=0/ s3tools.repo
# yum install s3cmd --enablerepo=s3tools
# s3cmd --configure
configureの内容はS3ってなんじゃ?(s3cmd編)で紹介したものと同じです。
次にテスト用のバケットを作成します。
それではsyncしてみます。
# /usr/bin/s3cmd sync -P /root/dist/ s3://memorycraft-sync/
.....
次々と同期のログが標準出力に出されていきますが、それが30分経過しても終わる気配がありません。
7万ファイルもあるためだったのか、結局全部同期させるのに1時間30分以上かかりました。
さらにその後、1ファイル追加して再度syncしてみます。
# echo "hoge" > /root/dist/symfony/src/Symfony/Component/Process/hoge.txt
# /usr/bin/s3cmd sync -P /root/dist/ s3://memorycraft-sync/
.....
結果、反応がありません。
–skip-existingを付けてみたところ、3分程で同期が終了しました。
1ファイルの同期に3分かかるのでは利用するのが難しいので、原因をさらに調査してみます。
○調査
今回s3cmdはyumでインストールしましたが、ソースをダウンロードし解析してみました。
# cd /usr/local/src/
# curl -OL http://ftp.jaist.ac.jp/pub/sourceforge/s/s3/s3tools/s3cmd/1.0.1/s3cmd-1.0.1.tar.gz
# tar xzvf s3cmd-1.0.1.tar.gz
# cd s3cmd-1.0.1
$ tree .
.
├── INSTALL
├── NEWS
├── PKG-INFO
├── README
├── S3
│ ├── ACL.py
│ ├── AccessLog.py
│ ├── BidirMap.py
│ ├── CloudFront.py
│ ├── Config.py
│ ├── Exceptions.py
│ ├── PkgInfo.py
│ ├── Progress.py
│ ├── S3.py
│ ├── S3Uri.py
│ ├── SimpleDB.py
│ ├── SortedDict.py
│ ├── Utils.py
│ └── __init__.py
├── s3cmd
├── s3cmd.1
├── setup.cfg
└── setup.py
ソースの内容を見てみると、S3配下がS3への接続とユーティリティ部分で、s3cmdがコマンドのロジック関連に
あたる部分のようです。
s3cmdを見てみると、各コマンドのメソッドがcmd_…となっており、ローカルからリモートのsyncは
cmd_sync_remote2remoteというメソッドで処理されているようです。
def cmd_sync_local2remote(args):
##~略~
s3 = S3(cfg)
if cfg.encrypt:
error(u"S3cmd 'sync' doesn't yet support GPG encryption, sorry.")
error(u"Either use unconditional 's3cmd put --recursive'")
error(u"or disable encryption with --no-encrypt parameter.")
sys.exit(1)
## Normalize URI to convert s3://bkt to s3://bkt/ (trailing slash)
destination_base_uri = S3Uri(args[-1])
if destination_base_uri.type != 's3':
raise ParameterError("Destination must be S3Uri. Got: %s" % destination_base_uri)
destination_base = str(destination_base_uri)
local_list, single_file_local = fetch_local_list(args[:-1], recursive = True)
remote_list = fetch_remote_list(destination_base, recursive = True, require_attribs = True)
##~略~
このようにdst_list = fetch_remote_listというところで同期先S3バケットの何かのリストを
再帰的に持って来ているようです。
さらにfetch_remote_listメソッドを見てみます。
def fetch_remote_list(args, require_attribs = False, recursive = None):
##~略~
if recursive:
for uri in remote_uris:
objectlist = _get_filelist_remote(uri)
for key in objectlist:
remote_list[key] = objectlist[key]
##~略~
def _get_filelist_remote(remote_uri, recursive = True):
##~略~
s3 = S3(Config())
response = s3.bucket_list(remote_uri.bucket(), prefix = remote_uri.object(), recursive = recursive)
##~略~
S3.pyを見てみると、bucket_listは、特定パス配下のオブジェクトリストをS3のAPIで取得しているようです。
つまりsyncでは、同期しようとしているフォルダ配下のオブジェクトすべてを取得しているということになります。
S3のオブジェクトリストの取得にはページネーションも発生するため、これでは配下にS3オブジェクトが
数百万あれば、同期の前にファイルリストの取得の時点で多大な時間が掛かることが予測されます。
○対策
せめて変更があったファイルだけ、ローカルからリモートで同期できるようinotifyを使ってみました。
inotifyはファイルシステムのイベント監視のためのツールで、それを利用したinotify-toolsというものがあります。
ファイルの変更等を検知して、それをトリガーにプログラムを実行できます。
早速ですが、インストールしてみます。
# cat /etc/yum.repos.d/dag.repo
[dag]
name=Dag RPM Repository for Red Hat Enterprise Linux
baseurl=http://ftp.riken.jp/Linux/dag/redhat/el$releasever/en/$basearch/dag
gpgcheck=1
gpgkey=http://ftp.riken.go.jp/pub/Linux/dag/RPM-GPG-KEY.dag.txt
enabled=0
# yum install inotify-tools
# yum -y --enablerepo=dag install inotify-tools
ここでは、inotify-toolsのinotifywaitというコマンドを使います。
inotifywaitに関してはinotify でディレクトリを監視してみるのページで詳しく説明されていますが、
指定したパス配下でイベントが発生すると標準出力にイベントと発生元のファイルパスが出力されます。
また監視するイベントは指定することができます。
上述のサイトにあるサンプルを参考にして、先程のソースファイル群のディレクトリの変更を検知し、
S3にsyncするよう設定してみました。
ポイントは下記の通りです。
- 変更のあったファイル群を5秒間バッファしてリスト化
- ファイル追加時に属性変更のイベントも同時に発生するため、リストから重複を除去
- S3でフォルダ内を検索しないよう、s3cmd syncはファイル単位で1ファイルごとに呼び出し
- 通常の呼び出しだとシリアルになってしまうため、&でs3cmdを非同期呼び出し
○inotify.sh
#!/bin/sh
TIMEOUT=5
NOTIFYPATH=/root/dist/
BUCKETPATH=s3://memorycraft-sync/
/usr/bin/inotifywait -e create,delete,modify,move,attrib
-mrq $NOTIFYPATH | while [ 1 ]; do
paths="";
while read -t $TIMEOUT line; do
path=`echo $line | /usr/bin/awk '{print $1$3}'`
paths="${paths}$path@RET@"
done
if [ -n "$paths" ]; then
echo $paths | sed 's/@RET@/n/g' | sort | uniq | while read path; do
if [ $path -a -f $path ]; then
filename="`basename $path`"
dpath="`dirname $path`/"
rpath=`echo $dpath | sed "s:$NOTIFYPATH::"`
if [ "$rpath" == $NOTIFYPATH ]; then
rpath=""
fi
echo "/usr/bin/s3cmd sync -P $path $BUCKETPATH$rpath$filename"
/usr/bin/s3cmd sync -P $path $BUCKETPATH$rpath$filename &
fi
done
fi
done
※1ファイルずつ行うため、普通にアップするだけならばs3cmd putで良いかもしれません。
これを実行します。
# cd /root/bin/
# chmod 755 inotify.sh
# ./inotify.sh
別ターミナルで、監視配下の任意の場所にファイルを作ってみます。
# echo "moge" > /root/dist/symfony/src/Symfony/Component/Process/moge.txt
そうすると、バッファタイムアウトで設定した5秒後にinotifyのターミナルで、同期が実行された旨のログが
すぐに出力されました。
# ./inotify.sh
start 2013年 2月 5日 火曜日 19:11:04 JST
path=
end 2013年 2月 5日 火曜日 19:11:04 JST
path=/root/dist/symfony/src/Symfony/Component/Process/moge.txt
/usr/bin/s3cmd sync -P /root/dist/symfony/src/Symfony/Component/Process/moge.txt s3://memorycraft-sync/symfony/src/Symfony/Component/Process/moge.txt
end 2013年 2月 5日 火曜日 19:11:04 JST
/root/dist/symfony/src/Symfony/Component/Process/moge.txt -> s3://memorycraft-sync/symfony/src/Symfony/Component/Process/moge.txt [1 of 1]
5 of 5 100% in 0s 72.34 B/s done
Done. Uploaded 5 bytes in 0.1 seconds, 70.15 B/s
S3を見てみると、無事にアップされていました。
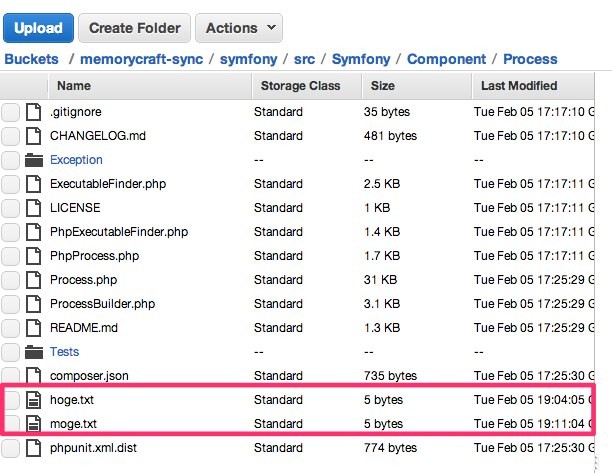
1ファイルずつsyncするため、一度に追加や変更するファイル量が大量になる場合や
空のバケットに対する初期同期の場合は通常のsyncの方が良いと思います。
ただ、今回のように同期先のS3にファイルが大量にある場合や更新ファイル数が少ない場合等は
inotifyで1つずつファイルを指定してsyncまたはputする方が早いと思います。
こちらの記事はなかの人(memorycraft)監修のもと掲載しています。
元記事は、こちら