以前、Elastic MapReduceでMahoutを使ってリコメンデーションの記事でEMR上でMahoutを使って、リコメンデーションを試してみました。
今回は、同様にEMR & Mahoutで、「この商品を買った人はこんな商品も買っています」を試してみました。

実際試すにあたり、MahoutのItemSimilarityJobを利用したのですが、下記の情報が大変参考になりました。
(感謝いたします)
[Hadoop]Hadoop上でMahoutを使って「このアイテムを見た人は、
こちらのアイテムも見ています」というレコメンドをやってみる | GENDOSU@NET
○S3にMahoutライブラリ(JAR)を配置
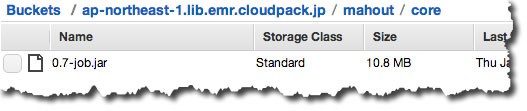
ライブラリ自体は、Index of /net/apache/mahout/0.7よりダウンロードしました。

○S3に作業領域を作成
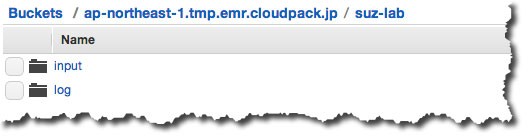
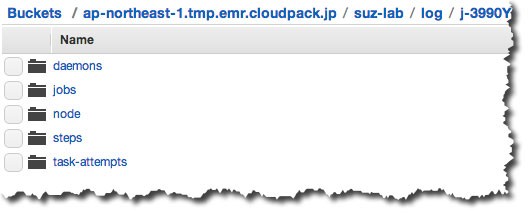
入力ファイルの配置先(input)とログの配置先(log)を用意しておきます。
EMRからの出力ファイルはoutputというディレクトリが自動作成後、配置されます。
(outputディレクトリを予め作っておくとエラーになります)
○入力ファイルの配置

ファイルの内容は下記(ユーザーID,商品ID,重み)の通りです。
100,200,10.0
100,201,10.0
100,202,10.0
100,203,10.0
100,204,10.0
100,205,10.0
100,206,10.0
100,207,10.0
100,208,10.0
100,209,10.0
101,200,10.0
101,201,10.0
101,202,10.0
101,203,10.0
101,204,10.0
101,205,10.0
101,206,10.0
101,207,10.0
101,208,10.0
102,200,10.0
102,201,10.0
102,202,10.0
102,203,10.0
102,204,10.0
102,205,10.0
102,206,10.0
102,207,10.0
103,200,10.0
103,201,10.0
103,202,10.0
103,203,10.0
103,204,10.0
103,205,10.0
103,206,10.0
104,200,10.0
104,201,10.0
104,202,10.0
104,203,10.0
104,204,10.0
104,205,10.0
105,200,10.0
105,201,10.0
105,202,10.0
105,203,10.0
105,204,10.0
106,200,10.0
106,201,10.0
106,202,10.0
106,203,10.0
107,200,10.0
107,201,10.0
107,202,10.0
108,200,10.0
108,201,10.0
109,200,10.0
今回のデータは、結果をわかりやすくするために、番号が一番若い(100)ユーザーはすべての商品を買っており、
ユーザーIDが増えるに従い購入商品を後ろから一つずつ減らしていくようにしました。
(109は200の商品しか購入していない)
一番多くのユーザーに購入されている200と201のペアが、類似度が一番高くなると予想されます。
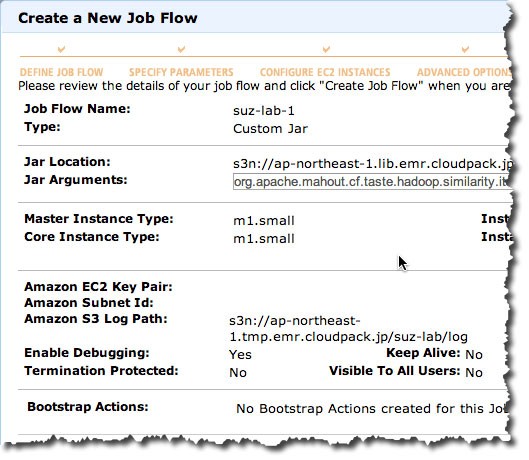
○Job Flowの作成
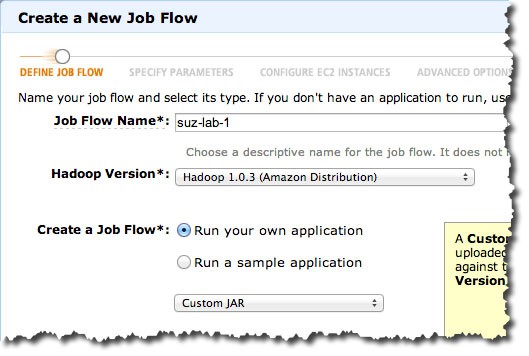
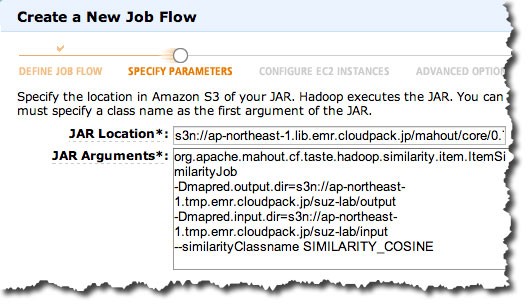
JAR Locationは上述した、s3n://ap-northeast-1.lib.emr.cloudpack.jp/mahout/core/0.7-job.jarを指定しています。
JAR Argumentsも上述したItemSimilarityJobや入出力ディレクトリを指定しています。
org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob
-Dmapred.output.dir=s3n://ap-northeast-1.tmp.emr.cloudpack.jp/suz-lab/output
-Dmapred.input.dir=s3n://ap-northeast-1.tmp.emr.cloudpack.jp/suz-lab/input
--similarityClassname SIMILARITY_COSINE
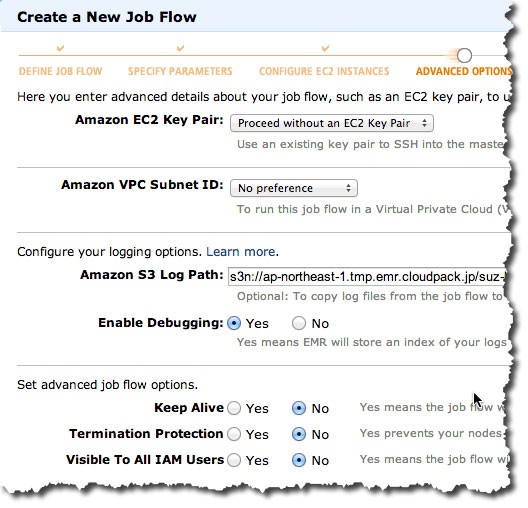
Amazon S3 Log Pathも上述した、s3n://ap-northeast-1.tmp.emr.cloudpack.jp/suz-lab/logを指定しています。
○出力結果
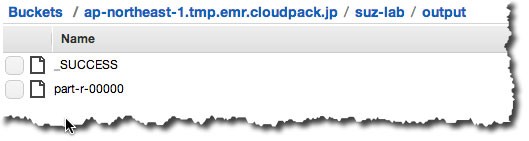
出力結果は、outputが作成されpart-r-00000に下記のように書き出されます。
200 201 0.9486832980505138
200 202 0.8944271909999159
200 203 0.8366600265340756
200 204 0.7745966692414835
200 205 0.7071067811865475
200 206 0.6324555320336759
200 207 0.5477225575051661
200 208 0.4472135954999579
200 209 0.31622776601683794
201 202 0.9428090415820634
201 203 0.8819171036881968
201 204 0.816496580927726
201 205 0.7453559924999298
201 206 0.6666666666666666
201 207 0.5773502691896257
201 208 0.4714045207910316
201 209 0.3333333333333333
202 203 0.9354143466934852
202 204 0.8660254037844386
202 205 0.7905694150420948
202 206 0.7071067811865475
202 207 0.6123724356957945
202 208 0.4999999999999999
202 209 0.35355339059327373
203 204 0.9258200997725515
203 205 0.8451542547285167
203 206 0.7559289460184545
203 207 0.6546536707079772
203 208 0.5345224838248488
203 209 0.37796447300922725
204 205 0.9128709291752768
204 206 0.816496580927726
204 207 0.7071067811865475
204 208 0.5773502691896257
204 209 0.408248290463863
205 206 0.8944271909999159
205 207 0.7745966692414833
205 208 0.6324555320336758
205 209 0.4472135954999579
206 207 0.8660254037844386
206 208 0.7071067811865475
206 209 0.5
207 208 0.8164965809277259
207 209 0.5773502691896257
208 209 0.7071067811865475
フォーマットは、下記のようになります。
商品ID 商品ID 二つの商品の類似度
上記のように、ほとんどのユーザーが購入している200と201のペアは類似度が高く(0.9486832980505138)、
誰も購入していない200と209のペアは類似度が低く(0.31622776601683794)なっています。
あとは、上記の情報をDBなどに保存して、類似商品の選択に利用するだけです。
尚、下記のように様々なログが出力されています。