
Amazon Athenaを利用してS3バケットにあるJSONファイルをParquet形式に変換するときにHIVE_TOO_MANY_OPEN_PARTITIONSというエラーが発生したので原因調査して対策を考えてみました。
Parquet形式とは
なんぞ?という方は下記が参考になると思います。
カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜 – Retty Tech Blog
https://engineer.retty.me/entry/columnar-storage-format
Amazon Athena: カラムナフォーマット『Parquet』でクエリを試してみた #reinvent | Developers.IO
https://dev.classmethod.jp/cloud/aws/amazon-athena-using-parquet/
Apache Parquet
https://parquet.apache.org/documentation/latest/
データを列指向フォーマットにすることで、クエリ実行時のデータ読み込みサイズを抑えてコスト削減できて(゚д゚)ウマーとなります。
Parquetはパーケイと読むそうです。(未だに読めないorz
Spark Meetup 2015 で SparkR について発表しました #sparkjp – ほくそ笑む
https://hoxo-m.hatenablog.com/entry/20150910/p1
再現手順
エラーを再現させて対策する手順となります。
下準備
S3バケットを用意してJSONファイルをアップロードします。
# バケット作成
> aws s3 mb s3://<S3バケット名>/ \
--region <YOUR RIGION>
make_bucket: <S3バケット名>
# JSONファイル作成
> cat <<EOF > example-001.json
{"hoge1": 1, "hoge2": 11,"hoge3": 111}
EOF
> ls
example-001.json
# S3バケットにコピー
> aws s3 cp example-001.json s3://<S3バケット名>/json/test=001/
upload: ./example-001.json to s3://<S3バケット名>/json/test=001/example-001.json
# S3バケットにたくさんコピー
> for i in {002..200} ; do aws s3 cp s3://<S3バケット名>/json/test=001/example-001.json s3://<S3バケット名>/json/test=$(printf '%03d' $i)/example-$(printf '%03d' $i).json; done
copy: s3://<S3バケット名>/json/test=001/example-001.json to s3://<S3バケット名>/json/test=002/example-002.json
copy: s3://<S3バケット名>/json/test=001/example-001.json to s3://<S3バケット名>/json/test=003/example-003.json
(略)
copy: s3://<S3バケット名>/json/test=001/example-001.json to s3://<S3バケット名>/json/test=198/example-198.json
copy: s3://<S3バケット名>/json/test=001/example-001.json to s3://<S3バケット名>/json/test=199/example-199.json
copy: s3://<S3バケット名>/json/test=001/example-001.json to s3://<S3バケット名>/json/test=200/example-200.json
> aws s3 ls --recursive s3://<S3バケット名>/json/ | wc -l
200
Amazon Athenaでテーブル作成
S3バケットへJSONファイルがアップロードできたらAmazon Athenaでテーブルを作成します。
事前にAmazon Athenaでワークグループの設定やクエリ実行結果を保存するS3バケットを指定済みとします。
json/test=xxx/とパーティション区切りしているので、PARTITIONED BYで指定します。
CREATE EXTERNAL TABLE IF NOT EXISTS sampledb.hoge_json ( hoge1 int, hoge2 int, hoge3 int ) PARTITIONED BY ( test string ) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' LOCATION 's3://<S3バケット名>/json/';
AWSマネジメントコンソールでクエリを実行して完了すると以下のようなメッセージが表示されるので、パーティションをロードします。
Query successful. If your table has partitions, you need to load these partitions to be able to query data. You can either load all partitions or load them individually. If you use the load all partitions (MSCK REPAIR TABLE) command, partitions must be in a format understood by Hive. Learn more.
MSCK REPAIR TABLE sampledb.hoge_json;
これでS3バケットからデータが読み込めるようになります。
SELECT count(*) FROM sampledb.hoge_json;
Parquet形式に変換する
Amazon AthenaのCTAS(CREATE TABLE AS)で新しいテーブルとデータファイルを作成することができるので、これをJSONからParquet形式への変換に利用します。
Amazon Athena が待望のCTAS(CREATE TABLE AS)をサポートしました! | Developers.IO
https://dev.classmethod.jp/cloud/aws/amazon-athena-support-ctas/
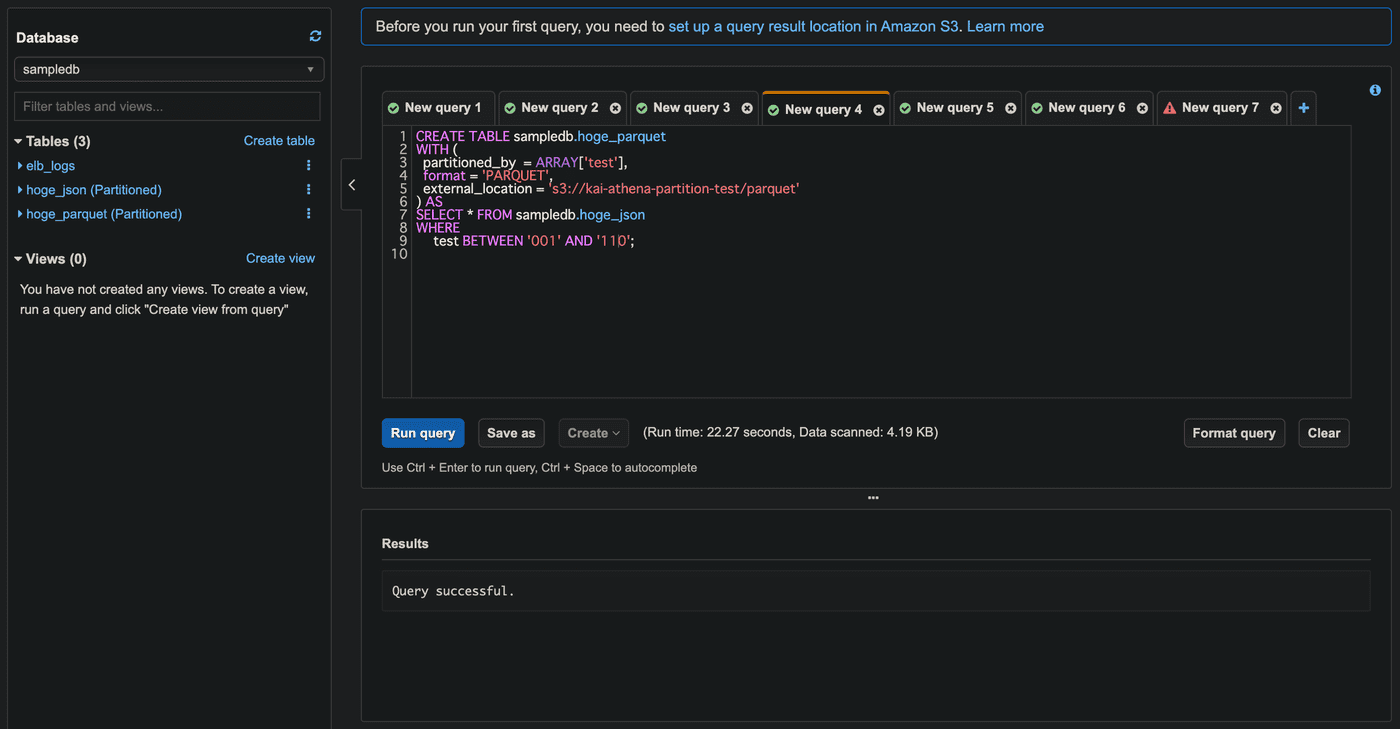
新しいテーブルhoge_parquetをCREATE TABLE AS SELECTクエリで作成します。WITHでパーティションやデータ形式、データファイルを保存するS3バケットを指定します。
CREATE TABLE sampledb.hoge_parquet WITH ( partitioned_by = ARRAY['test'], format = 'PARQUET', external_location = 's3://<S3バケット名>/parquet' ) AS SELECT * FROM sampledb.hoge_json;
これを実行するとエラーとなります。
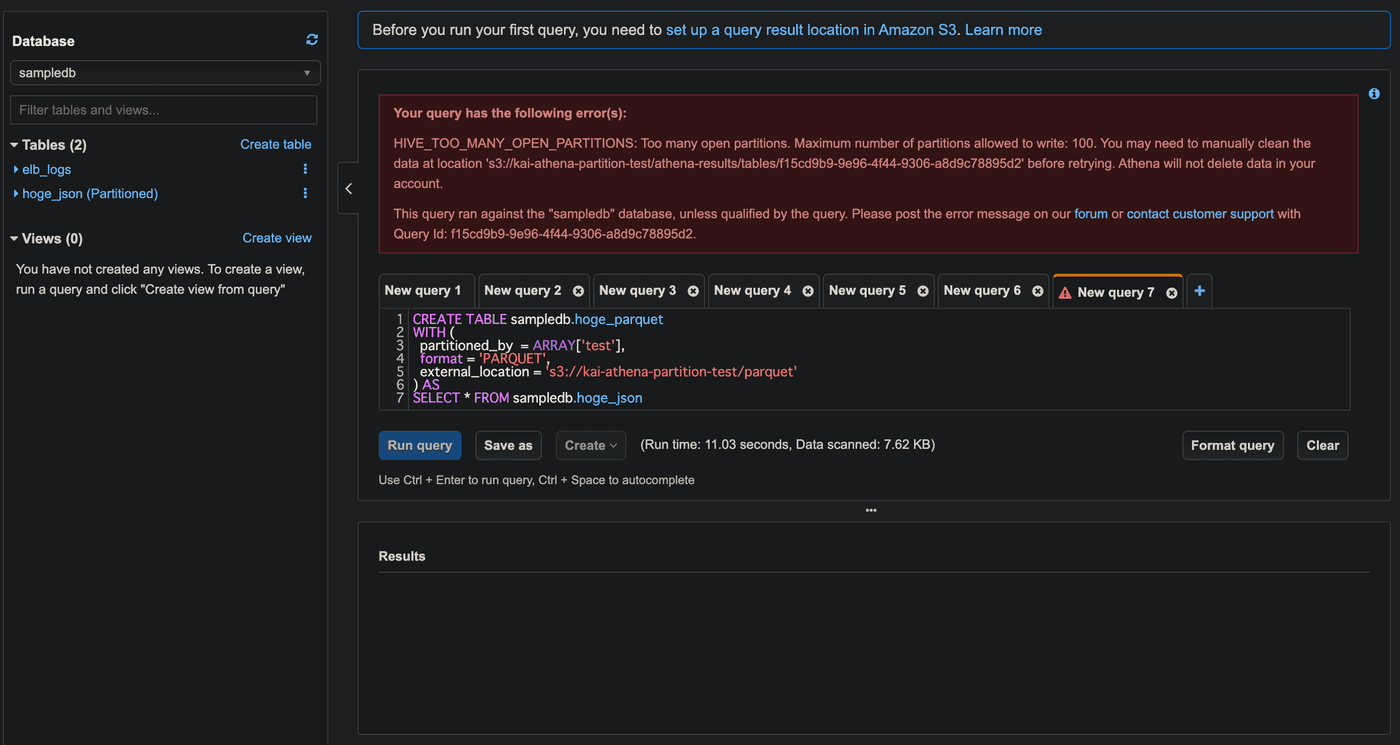
エラー内容
エラー内容は下記となり、1度に開くことができるパーティションは100まで。とのことです。
要は1度に作成できるパーティション数は100まで。

テーブルあたりのパーティション数の制限は?
サービス制限 – Amazon Athena
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/service-limits.html
AWS Glue データカタログ にまだ移行していない場合、テーブルあたりのパーティションの数は 20,000 です。制限の引き上げをリクエストできます。
Amazon Athenaでテーブル作成する場合、AWS Glueと連携しているので、AWS Glueの制限をみるとテーブルあたりのパーティションの数は10,000,000 !!!とあります。
AWS Glue との統合 – Amazon Athena
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/glue-athena.html
AWS Glue がサポートされるリージョンの場合、Athena は AWS アカウント全体のテーブルメタデータの一元的な保存および取得の場所として AWS Glue データカタログを使用します。
AWS サービスの制限 – AWS 全般のリファレンス
https://docs.aws.amazon.com/ja_jp/general/latest/gr/aws_service_limits.html#limits_glue
なので、あくまでも1度に作成するパーティション数の上限は100ということみたいです。
エラー詳細
HIVE_TOO_MANY_OPEN_PARTITIONS: Too many open partitions. Maximum number of partitions allowed to write: 100. You may need to manually clean the data at location 's3://<S3バケット名>/athena-results/tables/f15cd9b9-9e96-4f44-9306-a8d9c78895d2' before retrying. Athena will not delete data in your account. This query ran against the "sampledb" database, unless qualified by the query. Please post the error message on our forum or contact customer support with Query Id: f15cd9b9-9e96-4f44-9306-a8d9c78895d2.
HIVE_TOO_MANY_OPEN_PARTITIONSをキーワードに情報を探してみましたが、どうやらAmazon Athenaの裏で動いているPrestoというクエリエンジンの制限のようです。
too many open partitions? – Google グループ
https://groups.google.com/forum/#!topic/presto-users/5gFbvUoOF5I
パーティションの書き込み時に多くのマシンに分散するように設計されていてhive.max-partitions-per-writerrsって設定でデフォルト100になってる。そうです。
パーティション分割にはHiveを利用しているそうなのでそうなのでしょう。
データのパーティション分割 – Amazon Athena
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partitions.html
データをパーティション分割することで、各クエリでスキャンするデータの量を制限し、パフォーマンスの向上とコストの削減を達成できます。Athena では、データのパーティション分割に Hive を使用します。
クエリ実行はPrestoだそうです。
よくある質問 – Amazon Athena | AWS
https://aws.amazon.com/jp/athena/faqs/
Amazon Athena では、標準 SQL をフルサポートした Presto を使用し、CSV、JSON、ORC、Apache Parquet、Avro を含むさまざまな標準データ形式で機能します。
HiveとPrestoの違いについて調べてみた – Qiita
https://qiita.com/haramiso/items/122d4ea0e5660e0b4e41
もう少し調べてみたところしっかりと公式ドキュメントにも記載がありました。
CTAS クエリに関する考慮事項と制約事項 – Amazon Athena
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/considerations-ctas.html
Athena では、100 個の一意のパーティションとバケットの組み合わせへの書き込みがサポートされます。たとえば、送信先テーブルにバケットが定義されていない場合、最大 100 個のパーティションを指定できます。バケットを 5 個指定すると、(それぞれ 5 個のバケットを持つ) 20 個のパーティションが許可されます。この数を超えると、エラーが発生します。
バケット化というのがまだわかってないので追って調べようかと思います。
対策
作成するパーティション数が100を超える場合はクエリを複数に分けるのがよさそうなので試してみます。
CREATE TABLE AS SELECTは複数回実行できませんので、最近サポートされたINSERT INTO SELECTでパーティション作成されるようにします。
Amazon Athena がついにINSERT INTOをサポートしたので実際に試してみました! | Developers.IO
https://dev.classmethod.jp/cloud/aws/20190920-amazon-athena-insert-into-support/
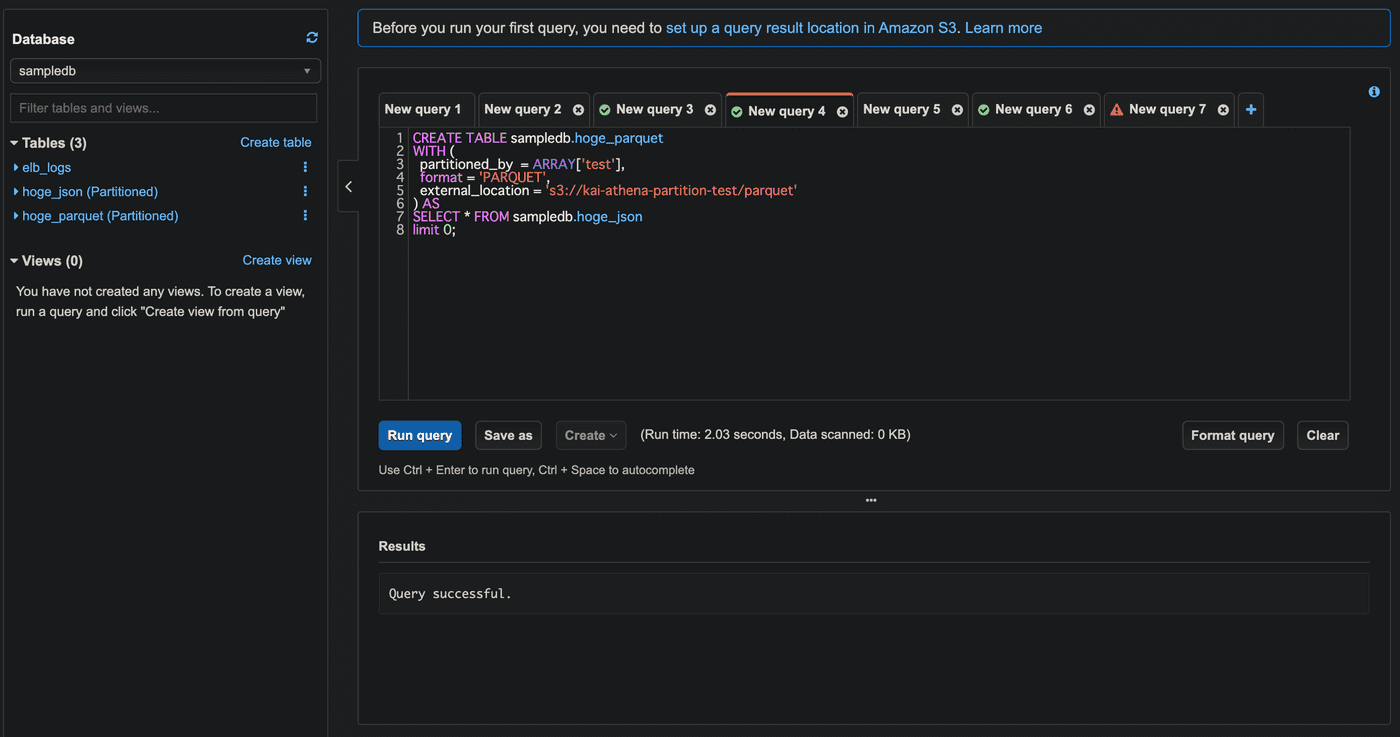
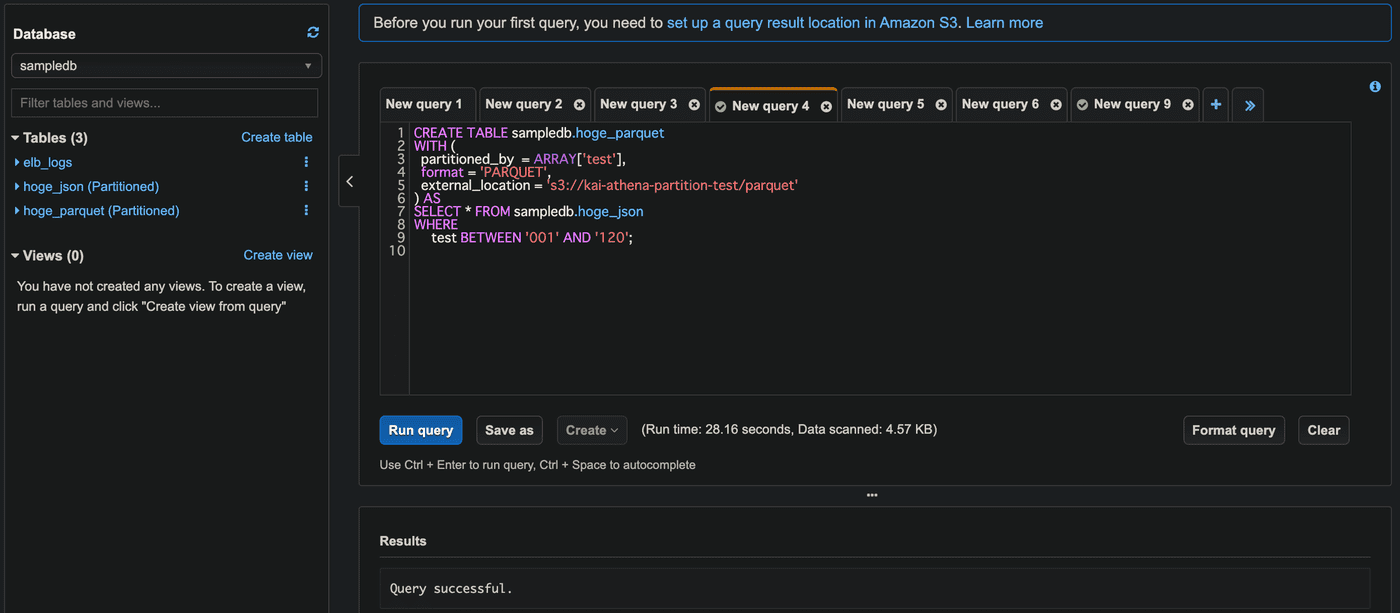
CREATE TABLE AS SELECTクエリではlimit 0としてデータ投入されないようにします。
CREATE TABLE sampledb.hoge_parquet WITH ( partitioned_by = ARRAY['test'], format = 'PARQUET', external_location = 's3://<S3バケット名>/parquet' ) AS SELECT * FROM sampledb.hoge_json limit 0;
INSERT INTO SELECTクエリのWHEREで投入するデータを絞り込みます。
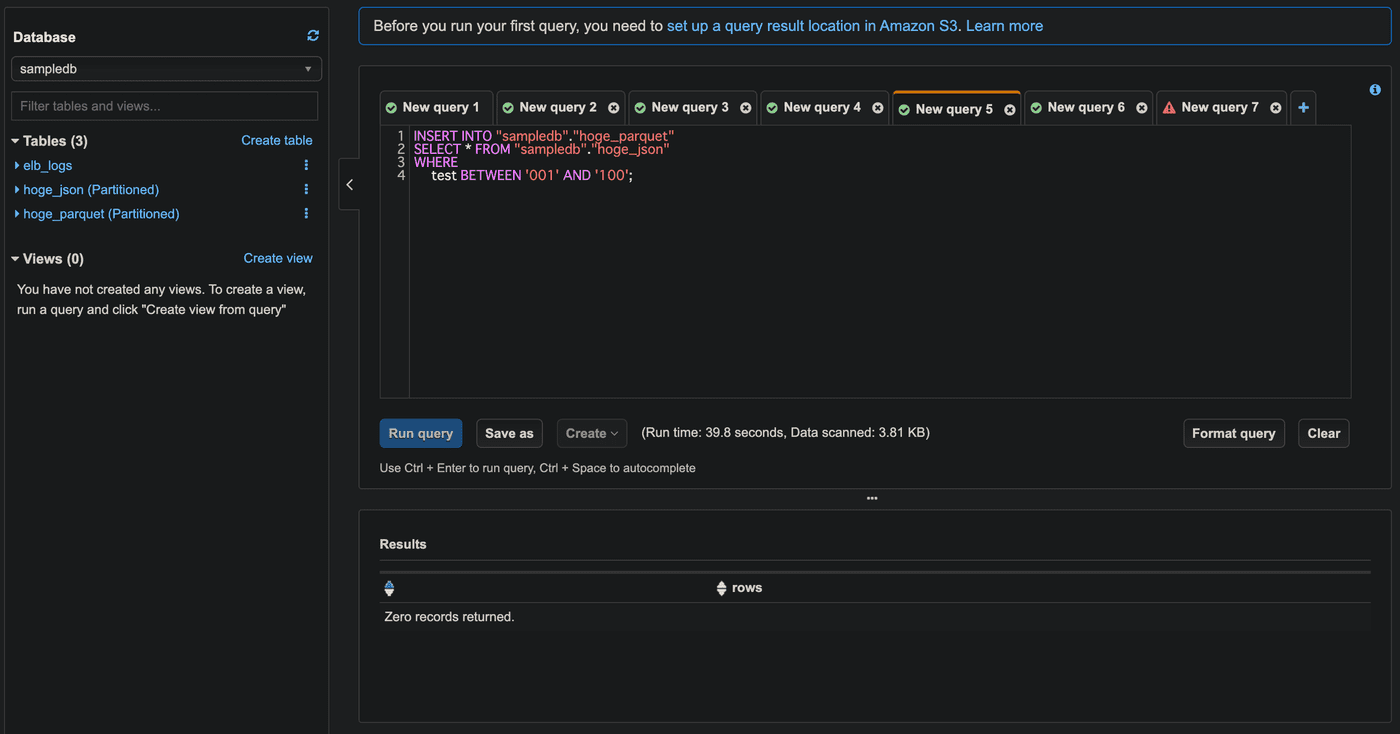
INSERT INTO sampledb.hoge_parquet
SELECT * FROM sampledb.hoge_json
WHERE
test BETWEEN '001' AND '100';
INSERT INTO sampledb.hoge_parquet
SELECT * FROM sampledb.hoge_json
WHERE
test BETWEEN '101' AND '200';
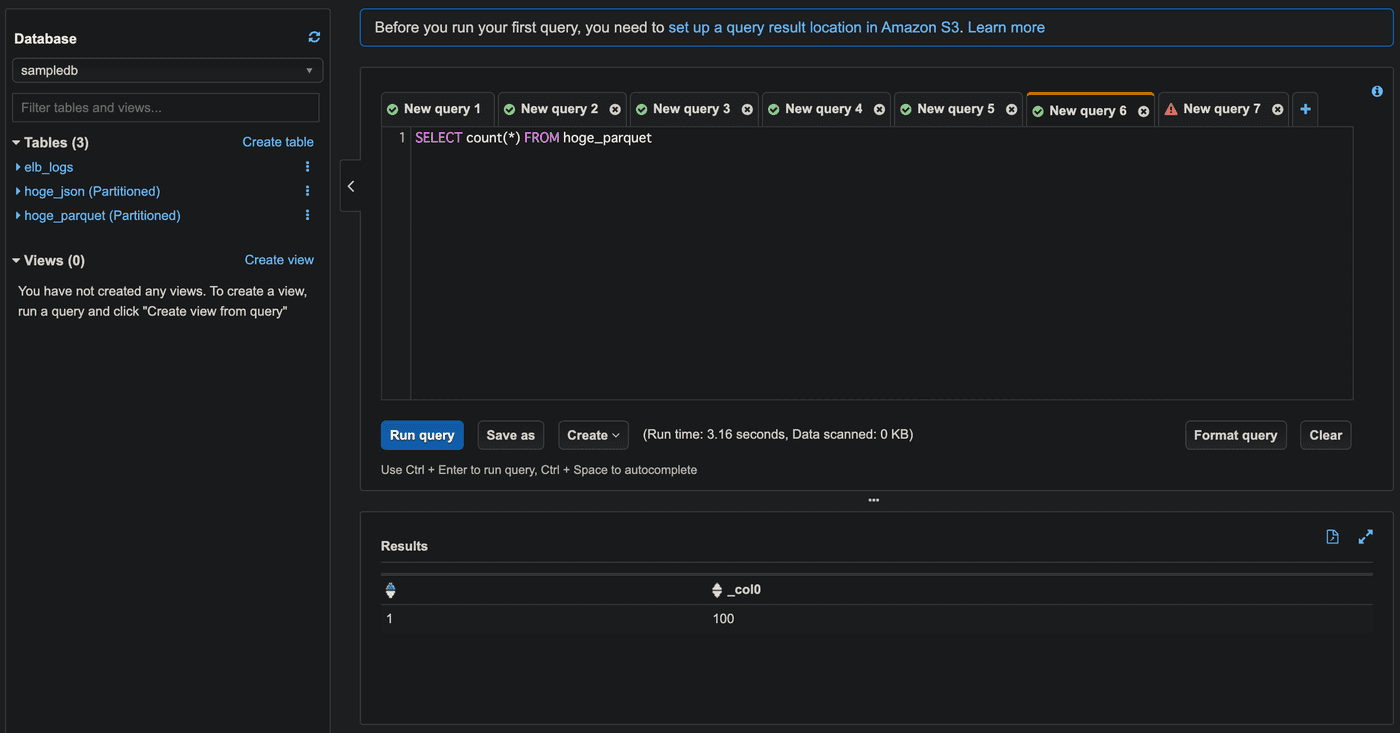
SELECT count(*) FROM sampledb.hoge_parquet;
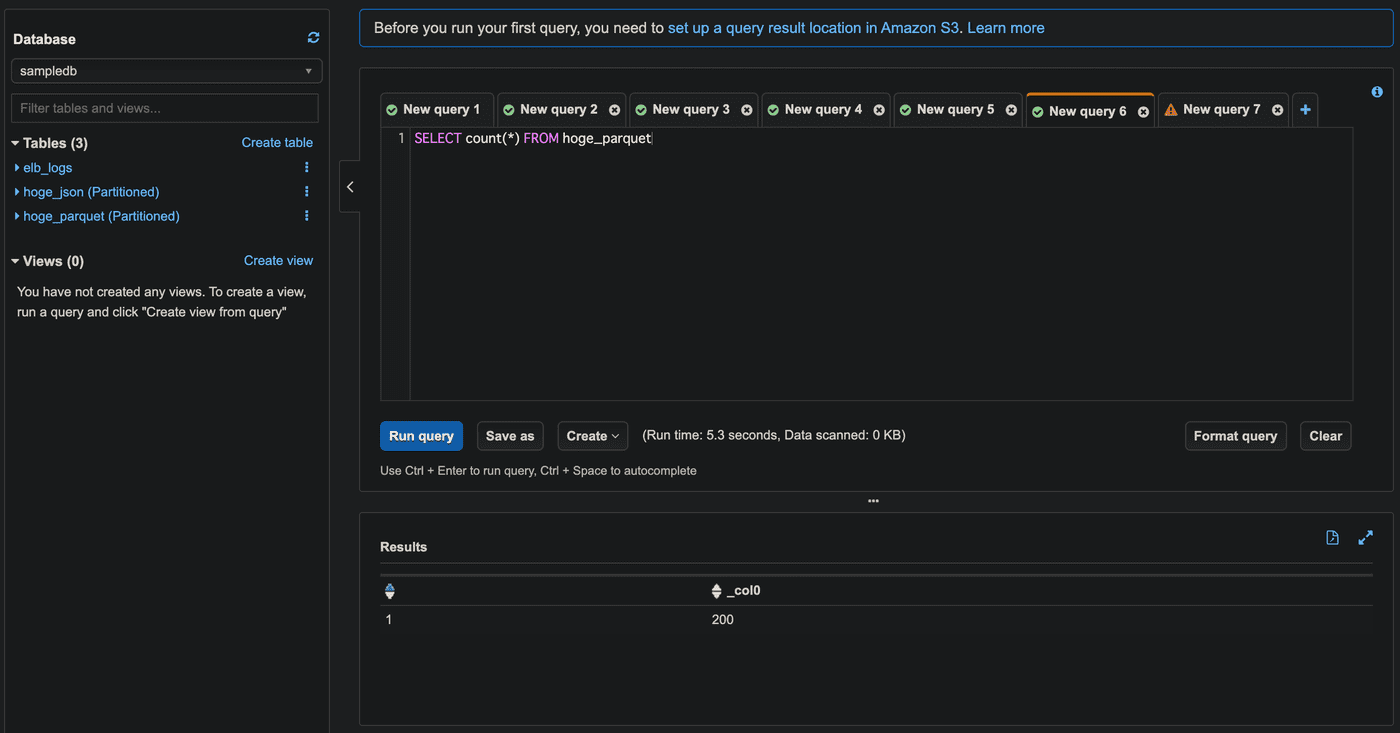
これでパーティション数が100を超える場合にも対処できるようになりました。
初期投入時以外は細かく変換して投入するのが良さそうです。
ちなみに
INSERT INTO SELECT クエリでも作成するパーティション数が100を超えるとエラーとなります。
INSERT INTO sampledb.hoge_parquet SELECT * FROM sampledb.hoge_json;
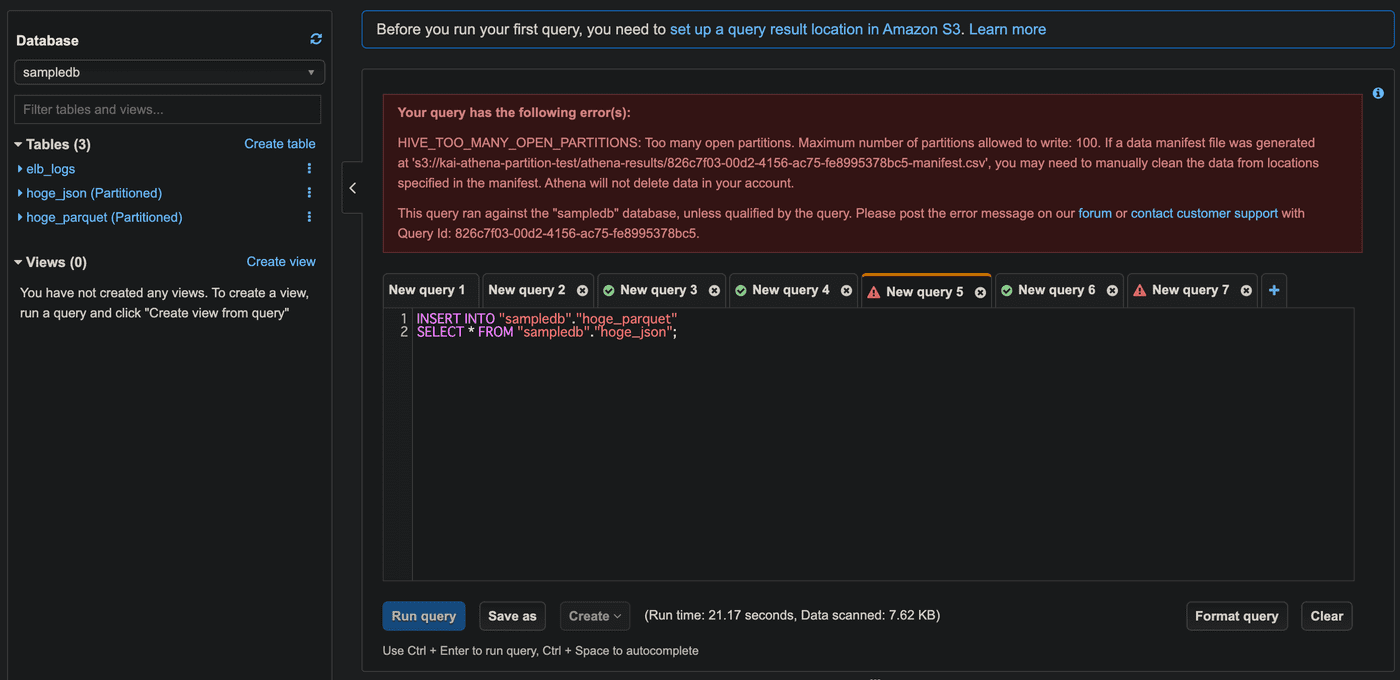
また、INSERT INTO SELECTで同じデータを投入した場合、主キーがないのでエラーもなくデータは重複して投入されるので注意が必要です。
パーティション数の制限値は厳密に100ではなさそう
エラーメッセージに100となるので、それに従っておけばよいわけですが、エラー再現させるのにしきい値を確認してみたら、どうも厳密には100ではなさそうでした。
スクリーンショットを取り忘れましたが最大でパーティション数が150でもエラーがでなかったりと。。。裏でスケールアウトして制限値が調整されていたり???
マネージドなサービスで裏の仕組みはわからないので、おとなしくエラーメッセージに従うのが良さそうです。
参考
カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜 – Retty Tech Blog
https://engineer.retty.me/entry/columnar-storage-format
Amazon Athena: カラムナフォーマット『Parquet』でクエリを試してみた #reinvent | Developers.IO
https://dev.classmethod.jp/cloud/aws/amazon-athena-using-parquet/
Apache Parquet
https://parquet.apache.org/documentation/latest/
Spark Meetup 2015 で SparkR について発表しました #sparkjp – ほくそ笑む
https://hoxo-m.hatenablog.com/entry/20150910/p1
Amazon Athena が待望のCTAS(CREATE TABLE AS)をサポートしました! | Developers.IO
https://dev.classmethod.jp/cloud/aws/amazon-athena-support-ctas/
サービス制限 – Amazon Athena
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/service-limits.html
AWS Glue との統合 – Amazon Athena
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/glue-athena.html
AWS サービスの制限 – AWS 全般のリファレンス
https://docs.aws.amazon.com/ja_jp/general/latest/gr/aws_service_limits.html#limits_glue
too many open partitions? – Google グループ
https://groups.google.com/forum/#!topic/presto-users/5gFbvUoOF5I
データのパーティション分割 – Amazon Athena
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partitions.html
よくある質問 – Amazon Athena | AWS
https://aws.amazon.com/jp/athena/faqs/
HiveとPrestoの違いについて調べてみた – Qiita
https://qiita.com/haramiso/items/122d4ea0e5660e0b4e41
CTAS クエリに関する考慮事項と制約事項 – Amazon Athena
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/considerations-ctas.html
Amazon Athena がついにINSERT INTOをサポートしたので実際に試してみました! | Developers.IO
https://dev.classmethod.jp/cloud/aws/20190920-amazon-athena-insert-into-support/
元記事はこちら
「Amazon Athenaでパーティション数が多いJSONのテーブルをParquet形式のテーブルに変換できずにハマった」
