
はじめに
2023/1/13にオーケー株式会社様における会員カードアプリの導入事例が公開されました。
アイレットはデザインから開発、そしてインフラ構築・運用までをご支援させていただきました。
当該記事はインフラ構築の裏側について解説する記事となります。
複数回に分けて順次公開させていただいており、今回はデータ分析、開発コンポーネントに関する内容となります。
前回までの記事はこちら:
概要
焦点を当てる内容としては赤枠箇所の以下となります。
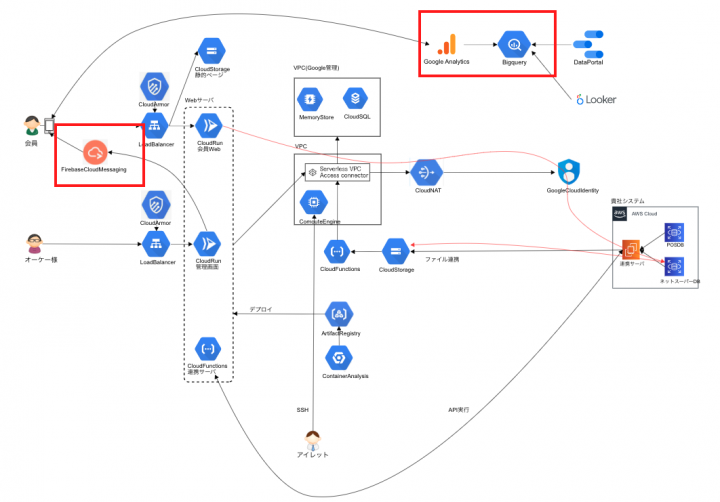
- データ分析
・BigQuery - 開発
・Firebase
・Google Cloud Identity
各コンポーネント詳細
【BigQuery】
BigQueryの用途については事例にて一部例が記載されておりますが(事例参照)、それらを行うために以下2パターンの方法でBigQueryへデータ連携を行っております。
- Googleサービスである、Google Analytics、Firebase Cloud Messaging、セグメント情報の連携
- 別プロジェクトで運用中のBigQueryへのCloud SQLのデータ連携
これらの目的に応じたデータ連携を行い、分析することで、アプリの実用性向上を行っております。
図に表すと以下のような内容です。
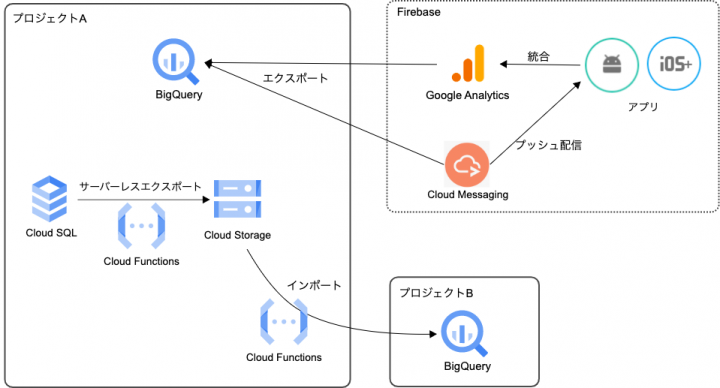
これら2パターンの連携についてそれぞれ記載します。
Googleサービスとの連携
Firebase内でBigQueryとそれそれのサービスを統合することで、BigQueryからのエクスポートが容易に行えます。
別の統合不可なサービスであれば、データエクスポートする手法やインポートする手法を検討し、実装するという過程が必要ですが、その点を省き実現することができました。
別プロジェクトへの連携
Cloud Functionsにて以下2つの処理を実装し、BigQueryへのデータインポートまで行いました。
また処理上でのポイントも併せて記載しています。
- Cloud SQLのデータをCloud Storageへエクスポート
・サーバーレスエクスポートを利用し、構築されたインスタンスに負荷をかけずにエクスポート処理を実施 - Cloud StorageからBigQueryへインポート
・データ内がNULLの値であったり、ダブルクオーテーションであることを加味し、ジョブ内のconfigを設定
・Cloud Storageにファイル作成されたことを検知後にキックするイベントドリブンなアーキテクチャで実装
・別プロジェクトへのインポートであるため、対向プロジェクト上で当該プロジェクトで利用するCloud Functionsのサービスアカウントを追加し、BigQueryへのインポートに必要な権限を付与しております。
【Firebase】
以下のような開発で利用するツール群を一元的に管理しています。
- プッシュ通知でFCM(Firebase Cloud Messaging)
- テストアプリの配信でFirebase App Distribution
- BigQuery部分で記載ずみですが、Google Data Analytics及びFCMのBigQueryとの連携
FCM
今回は配信規模を加味し、トピック配信としており、お客様の目的に応じて配信対象を絞れるような設計とし、より効率的なプッシュ通知を行える形としております。
Firebase App Distribution
テストアプリの配信状況、配信内容を一元管理できるよう、当該サービスを利用しています。また以下により効率的な改修を行えております。
- テスト配信することで本配信前にお客様にて動作確認が可能
- Firebase上での配信履歴にプロジェクト管理ツールの課題番号を紐付け、改修内容を容易に把握可能
【Identity Platform】
アプリのユーザはもちろんですが、別システムのネットスーパーの会員情報の管理及び認証情報をCloud Identityへ移行し、顧客情報のID管理基盤として、統合的に管理することが可能となりました。
それぞれが分散されたID管理の場合、ID管理基盤間で情報認証に関する連携を行う必要がございましたが、それらを纏めて管理することで、余分な連携がなく、効率的な管理が行える形としました。
考慮点及びコメント
考慮点
構成の解説でも記載しておりますが、必要な開発ツールや利用するデータをGoogleサービスに集約することで、BigQueryへのデータ集約を効率化することができました。
コメント
クラウドサービスは充実し、それと同時に手法も多岐に渡るため、その手法によってはインフラと開発の境目が難しい部分があります。ただ、お互いに交わる部分もあるため、今回のデータ分析の連携部分(後続の記事で予定している負荷試験や監視もですが)は、交わる箇所で協力して進行を行うことができ、お互いのチームのナレッジとしても溜まり、良いケースになったのではないか、と感じました。
当該記事はインフラ担当した亀田、齋藤(寛隆)にて記載しております。



