はじめに (AWS Glue Git統合)
Git統合の⼿順
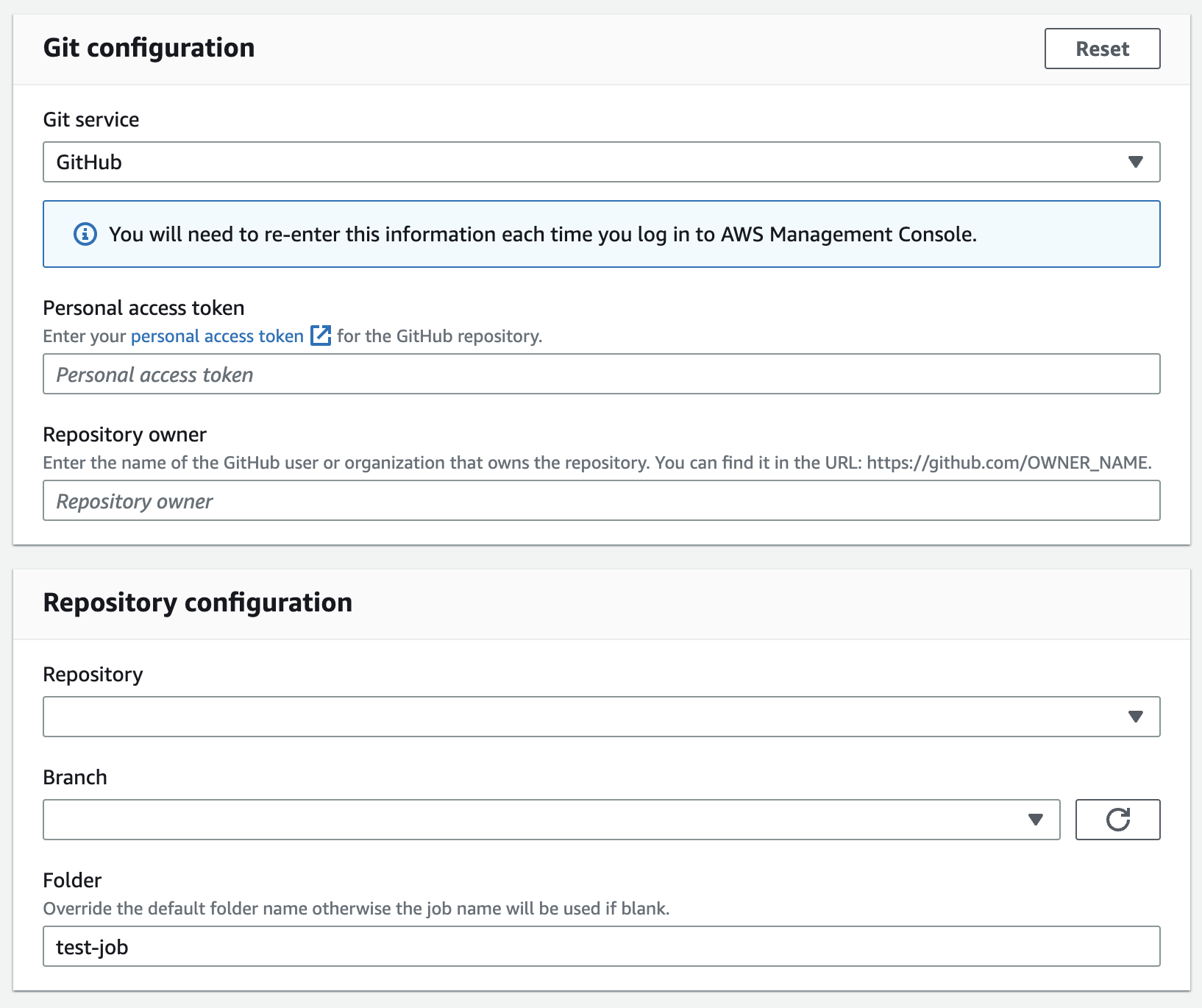
AWS GlueにはGit統合機能が備わっています。対応されているGitサービスプロバイダは、2023年5⽉現在「AWS Code Commit」と「GitHub」のみです。
今回案件で使⽤しているGitサービスはGitHubなので、GitHubを選択しました。GitHubの場合、個⼈⽤のアクセストークンが必要です。
GitHub 個⼈⽤のアクセストークンを格納後、上記の画像内の「Repository configuration」欄に対象のリポジトリやブランチが選択可能な状態になるので、最適なアイテムを選択してください。
これでGit統合の初期設定が終了しました。
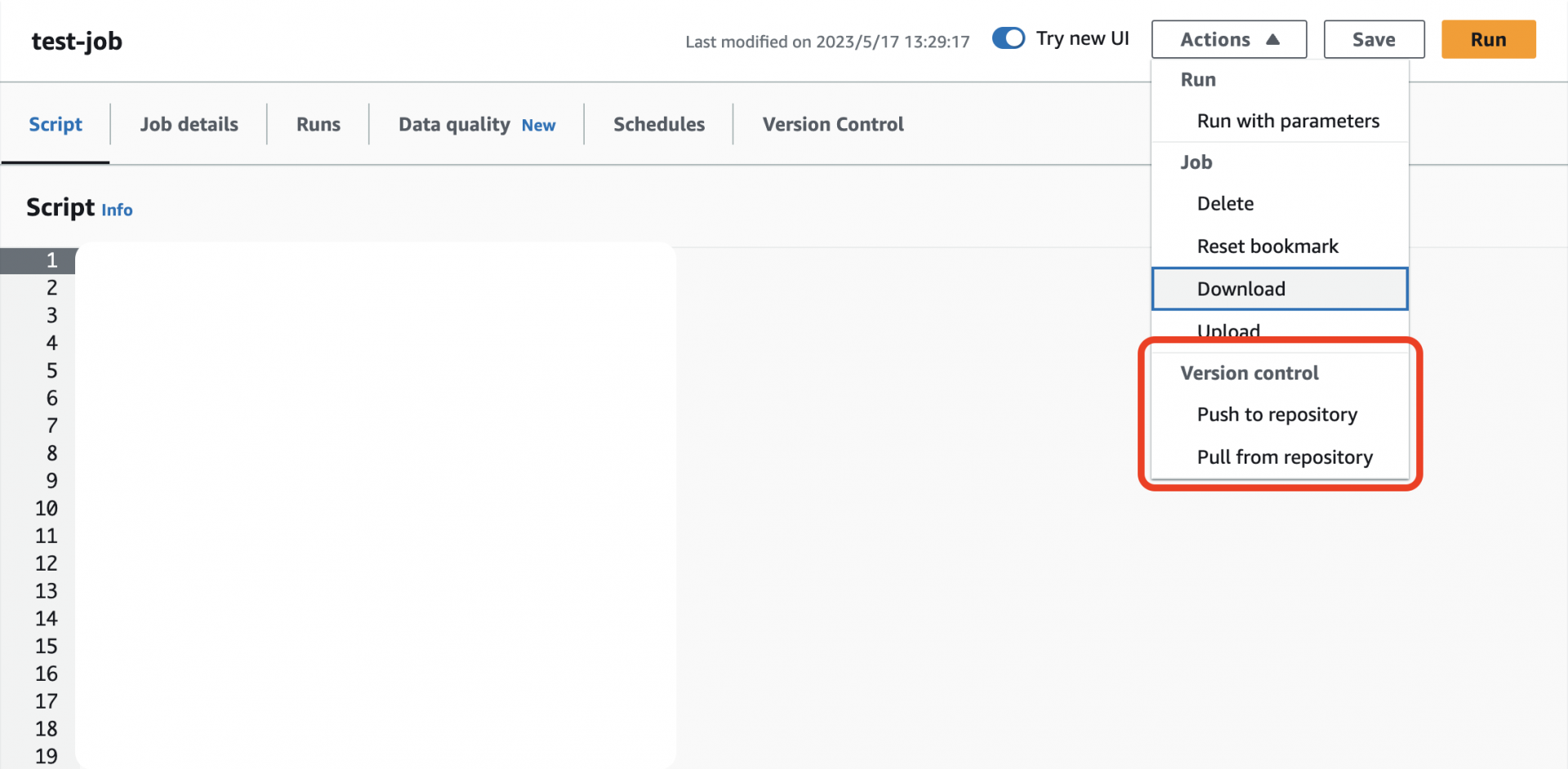
初期設定後は簡単です。ローカルでコーディングしたスクリプトをGitHubへpush後、AWS Glueのアクションから「Pull from repository」を押すと対象のETLジョブにスクリプトが反映されます。
逆も然りで、AWS Glue上で変更した内容をGithubへPushすることも可能です。その際スクリプトファイルだけではなく、ジョブの設定内容をテンプレート化したJSONファイルも⼀緒にPushされます。これにより複数のジョブに対して共通のジョブ設定をアタッチすることが可能です。
注意点
⼀⾒便利なGit統合機能ですが、実はかなり不便なデメリットが存在します。それは以下の⼤⽂字の通りです。
【 AWS セッションを切るとGitHub 個⼈⽤アクセストークンの格納がリセットされる 】
あまりにも不便なため太⽂字と括弧で強調してしまいました。要はAWSからログアウトすると個⼈⽤のアクセストークンもリセットされるため、再度⼀番上のGit統合の初期設定から⾏わなければなりません。
これでは何のためのGit統合機能なのか分からないので、現時点ではGithubサービスはAWS Glueのジョブ開発に向いていません。
AWS GlueとGitHubをセットで使⽤し開発を⾏う⽅はご注意ください。
GitHub Actionsを使⽤したCI/CD

継続的にデプロイしていくにはAWS GlueのGit統合機能はCI/CDパイプラインに向いてない事が分かりました。そこでGitHub Actionsを活⽤してCI/CDパイプラインを構築していく事にします。
ETLジョブ スクリプトの保存先
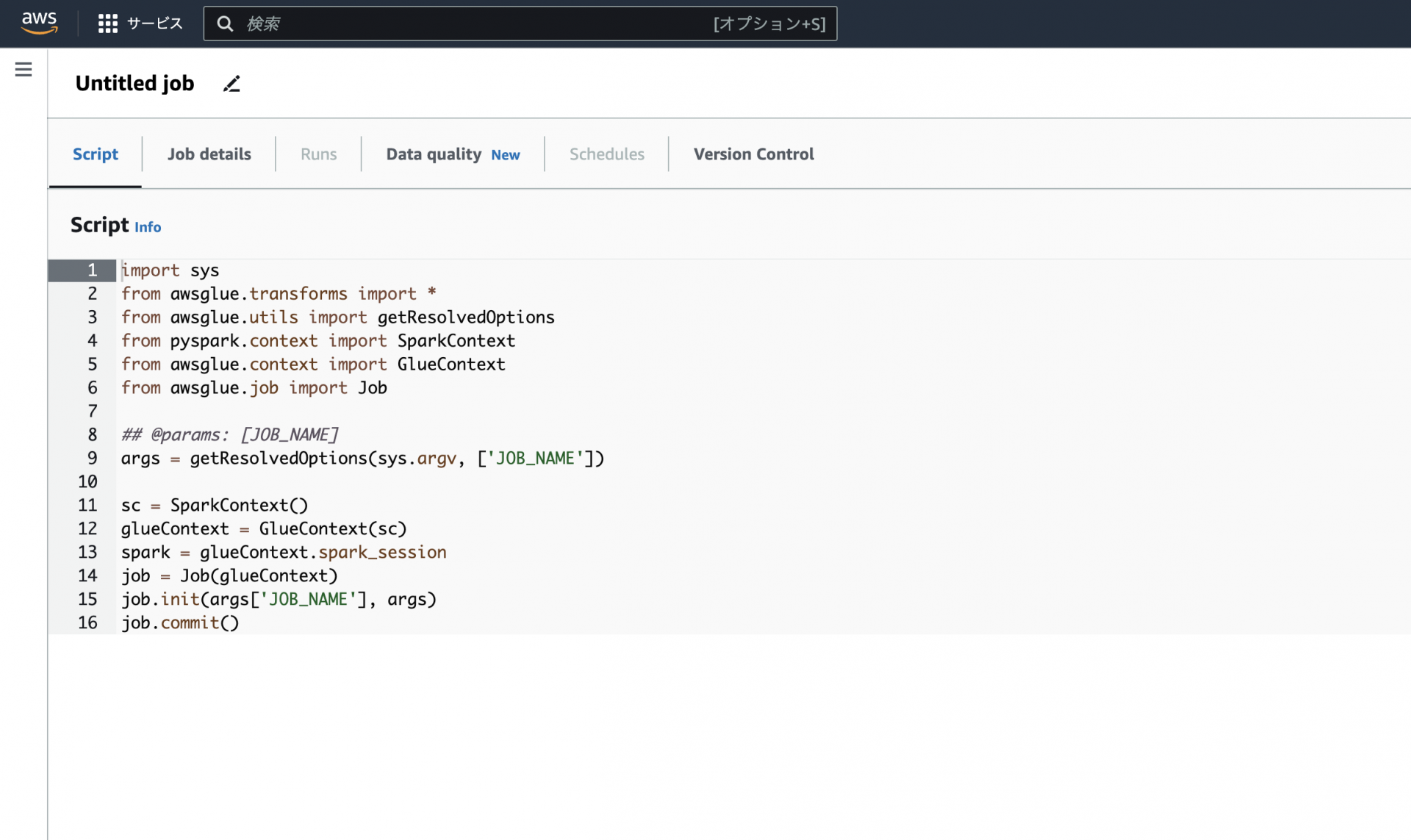
上記の画像はETLジョブのSpark scriptを新規で作成した際に最初に書かれているコードになります。
pySparkを呼び出しジョブを初期化後、Glueに通知をするという簡単なコードになります。
しかし⼀つ疑問が浮かびいます。こちらのスクリプト、どこに保存されているのでしょうか。
正解は、S3です。
そのためローカルで開発したETLジョブはAWS CLIで新規作成・更新を⾏い、ジョブの内容はS3に保存されているスクリプトファイルを参照できればCI/CDのパイプライン構築が可能になります。
またGitHubにPull Requestを作成後、マージをトリガーに、先程の⼯程を⾃動的に⾏う事が可能であれば、開発者は新たなジョブを作成する⼿間を省けETLジョブ開発に専念することができます。
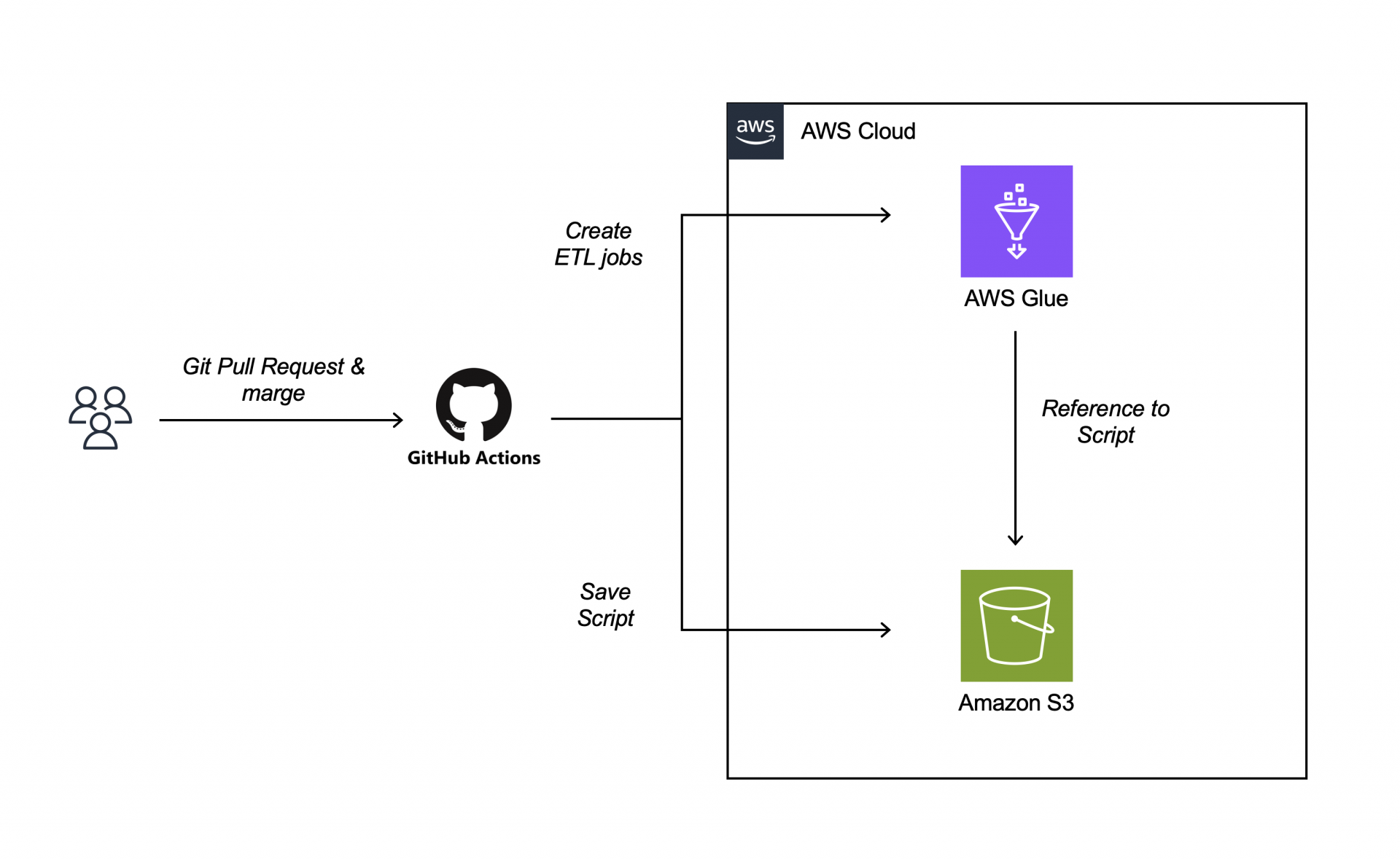
以上の画像のようなCI/CDパイプラインを今回実装していきたいと思います。
GitHub Actions workflows
.github/workflows/yml
name: Sample
on:
pull_request:
branches:
- main
types:
- closed
env:
AWS_REGION: 'ap-northeast-1'
S3_BUCKET: '...'
GLUE_JOB_ROLE: 'arn:aws:iam::...:role/...'
jobs:
deploy:
runs-on: ubuntu-latest
permissions:
id-token: write
contents: read
steps:
- name: Checkout code
uses: actions/checkout@v2
- uses: aws-actions/configure-aws-credentials@v1
with:
role-to-assume: ${{ env.GLUE_JOB_ROLE }}
role-session-name: github-actions-${{ github.run_id }}
aws-region: ${{ env.AWS_REGION }}
- run: aws sts get-caller-identity
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install boto3
- name: Upload ETL scripts to S3 and register them as AWS Glue Jobs
run: |
python .github/workflows/deploy.py
こちらが今回実装したGitHub Actionsのworkflowsになります。タイミングはPull Requestされたブランチがmainブランチへマージされるとworkflowsが実⾏されます。
環境変数に最適なS3のバケット名、AWS GlueとS3への最⼩アクセス権限が付与されたIAMロールを格納して下さい。
steps最後にpython.github/workflows/deploy.pyとpythonが実⾏されています。こちらのファイルの中⾝が今回最も重要なGlueのジョブを新規作成と任意のS3バケットにスクリプトファイルが保存される処理が記載されている場所になります。
deploy.py
.github/workflows/deploy.py
import boto3
import os
S3_BUCKET = os.environ["S3_BUCKET"]
GLUE_JOB_ROLE = os.environ["GLUE_JOB_ROLE"]
s3 = boto3.client('s3')
glue = boto3.client('glue')
for root, dirs, files in os.walk('src'):
for file in files:
if file.endswith('.py'):
relative_path = os.path.relpath(root, 'src')
s3_path = os.path.join('etl_scripts', relative_path, file)
local_path = os.path.join(root, file)
s3.upload_file(local_path, S3_BUCKET, s3_path)
glue_job_name = os.path.splitext(file)[0]
response = glue.create_job(
Name = glue_job_name,
Role = GLUE_JOB_ROLE,
ExecutionProperty = { 'MaxConcurrentRuns': 1 },
Command = {
'Name': 'glueetl',
'ScriptLocation': f's3://{S3_BUCKET}/{s3_path}',
'PythonVersion': '3'
},
DefaultArguments = { '--job-language': 'python' },
GlueVersion = '2.0'
)
deploy.pyはAWS SDK for Python (Boto3)を使⽤しています。
ymlファイルに宣⾔された環境変数を呼び出し、S3バケット名とIAMロールを取得します。任意のフォルダ内(今回はsrc)のpyファイルを検索し、ファイル名を取得、S3バケットにファイルをアップロードし、boto3のcreate_job()関数で取得したpythonのファイル名をETLジョブ名にし、ScriptLocationに保存した先のURLを格納します。
後は適宜、ご⾃⾝に合ったジョブ設定やCI/CDを設計して下さい。



