
はじめに
クラウドコンピューティングサービスを使用するにあたり、AWS を使ったことのある方は多いとおもいますが、マルチクラウド環境を構築する必要があったり、所属する組織のルールなどでAWS以外のクラウドを使用する必要に迫られることもあるかとおもいます。
本記事では、私が実務においてGoogle Cloud でインフラ構築をする際に感じたAWSとの違いや、構築時のポイントについて、リソースごとに3回に分けて取り上げたいとおもいます。
今回は第3回目の記事となります。前回、前々回の記事は以下です。是非併せてご覧ください。
対象リソース・記載範囲
本記事では以下リソースの概要と、設計・構築におけるポイントを取り上げます。リソースの詳細については触れていない部分があること、使用料金、運用保守関連については記載対象外としておりますのでご承知おきください。
- Cloud SQL
- Cloud Spanner
Cloud SQL
概要
Cloud SQL は、Google Cloud で提供されるフルマネージド型のリレーショナルデータベースサービスです。MySQL, PostgreSQL, Microsoft SQL Server の3つの主要なリレーショナルデータベースシステムをサポートしています。AWS でいう Amazon RDS にあたるサービスです。
主な特徴
- フルマネージド
Google がインフラのメンテナンス、バックアップ、アップデートなどの運用タスクを管理するため、アプリケーション開発などに注力することが可能となります。 - 高可用性
レプリケーション、自動フェイルオーバー、およびバックアップ機能の利用が可能です。 - セキュリティ
Cloud SQLはGoogle Cloudのデータセンター内でホストされ、Googleのセキュリティモデルの恩恵を受けます。また、デフォルトで暗号化されており、Cloud Identity and Access Management (IAM) を利用してアクセスを制御することができます。 - スケーラビリティ
トランザクションの増加に対し、スケールアップが可能なほか、リードレプリカの使用による読み込み処理に対する負荷分散も可能です。
設計・構築のポイント
データベースエンジンの選択
概要で触れたように、CloudSQL では、MySQL, PostgreSQL, Microsoft SQL Server の3つのデータベースエンジンがサポートされています。オンプレミスからデータベースサーバーを移行するケースで、 CloudSQL でサポートされているデータベースエンジンを使用していれば同じものを使用します。Oracle Database を移行する場合、Bare Metal Solution の使用を検討します。
Cloud SQL for MySQL と for PostgreSQL にはエディションというものがあり、Enterprise と Enterprise Plus という2つのエディションが存在します。エディションによって読み取り・書き込みのパフォーマンスや、使用できるデータベースエンジンのバージョンが異なりますので、確認のうえ適しているものを選択します。エディションは CloudSQL インスタンスごとに設定することが可能となっています。
Cloud SQL のエディションの概要
ネットワーク
Amazon RDS と大きな違いがあると感じた点がネットワークです。CloudSQL は、ユーザーが作成するVPC 上ではなく、Google Cloud が所有する VPC 内のサブネットに構築されます。 Compute Engine などから CloudSQL に接続する場合、以下2つの方法があります。特徴を理解したうえで、ワークロードの特性に適した方法で接続するようネットワークを設計します。
- パブリックIPを使用した接続
- プライベートIPを使用した接続
パブリックIPを使用した接続
CloudSQL インスタンス(Google Cloud サーバー上で実行されている仮想マシン(VM))にグローバルIPを割り当て、インターネット経由で接続する方法です。
プライベートIPを使用した接続
CloudSQL インスタンス にプライベートIP のみを割り当てて接続する場合、プライベートサービスアクセスというものを使用する必要があります。CloudSQL インスタンスが作成される Google の VPC は サービス プロデューサーの VPC と呼ばれ、ユーザーが作成した VPC とサービス プロデューサーの VPC を VPC ピアリング で接続することを プライベートサービスアクセスと言います。
なお、プライベートIPのみを使用した場合、当然インターネット上にエンドポイントは公開されないほか、パブリックIPを使用した接続よりもネットワークレイテンシを低く抑えることが可能です。
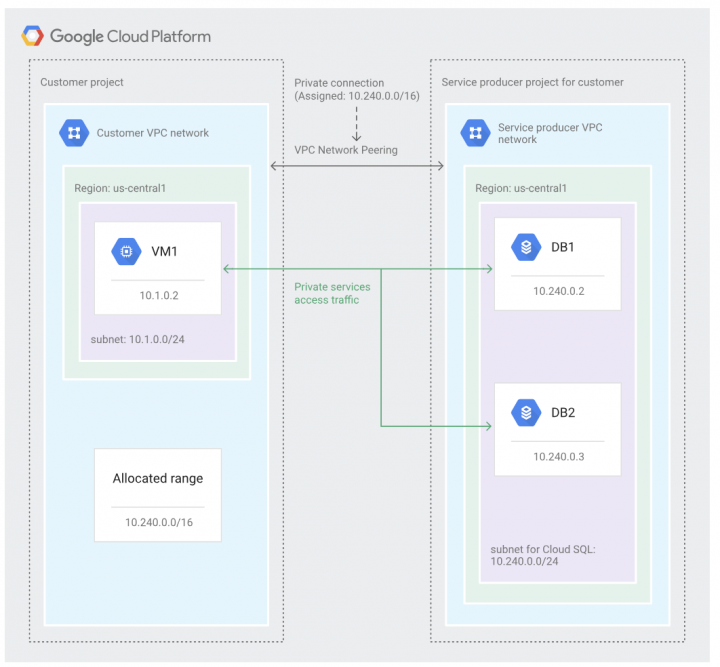 ※ プライベートIPでの接続図 公式ドキュメントから引用
※ プライベートIPでの接続図 公式ドキュメントから引用
サイジング・スケーリング
適切な vCPU とメモリを検討のうえ選択します。指定後にスケールアップも可能ですが、その場合インスタンスの再起動が必要となります。
また、マシンタイプで共有コアまたは専用コアを選択します。共有コアの場合、CloudSQL の SLA 対象外となるなどのデメリットがあるため、本番用ワークロードでは専用コアの選択が望ましいと言えます。
ストレージは SSD と HDD から選択が可能です。通常は SSD の使用を検討します。 HDD は大規模なデータセット(10 TB 超)を保存する場合や、レイテンシがあまり重要でない場合、またはアクセス頻度が低い場合などで使用を検討します。
ストレージ容量は増加に対して自動容量増加機能がありますので、設定しておく方が無難だとおもいます。
可用性
CloudSQL では容易に高可用性(HA)構成を実現することが可能です。サポートしているデータベースエンジン全てにおいて、リージョン内の2つのゾーンを使用して HA 構成を取ることで冗長化ができます。設定方法はインスタンスの作成時に HA 構成を取るかのオプションにチェックを入れるだけです。
HA 構成を取ると、プライマリインスタンスとセカンダリインスタンスが作成され、インスタンスやゾーンに障害が発生した場合、自動でフェイルオーバーが行われます。また、インスタンスが2台稼働するため、料金は2台分かかることとなります。
バックアップ
Cloud SQL のバックアップでは、手動によるオンデマンドバックアップとスケジュールによる自動バックアップが用意されています。複数回バックアップを取得した場合、2回目以降は増分バックアップとなります。また、トランザクションログを保持することでポイントタイムインリカバリでの復元も可能です。
デフォルトではバックアップは2箇所のリージョンに保存され、保存されるリージョンは、CloudSQL インスタンスのロケーションに最も近いマルチリージョンとなっています。要件等にてバックアップを特定のリージョン内に限定する必要がある場合は、カスタム バックアップ ロケーション を使用してリージョンを指定します。
セキュリティ
データの暗号化
Google Cloud では、デフォルトで全てのデータがストレージ保存時に暗号化され、データがVPCネットワーク転送中においても暗号化されます。CloudSQL についてもユーザーのデータはデフォルトで暗号化されます。
追加で検討する事項としては、顧客管理の暗号鍵(CMEK)を使用するかや、CloudSQL インスタンスの接続に関して SSL/TLS 証明書を使用するか、また、クライアント側でのデータベースに保存するデータの暗号化などがあります。詳細は公式ドキュメントをご参照ください。
通信経路
ネットワークの所で触れたように、CloudSQL インスタンスへの接続には、パブリックIPとプライベートIPの使用が可能です。本番用ワークロードなど、パブリックIP の使用が望ましくない環境においては、プライベートサービスアクセスを使用したプライベートIPのみでの接続を検討するなどします。
開発環境において、ローカルマシンからデータベースへの接続を行いたい場合など、パブリックIPを使用する場合は、Cloud SQL Auth Proxy を使用することでセキュアに接続ができますので、検討してもよいと考えます。
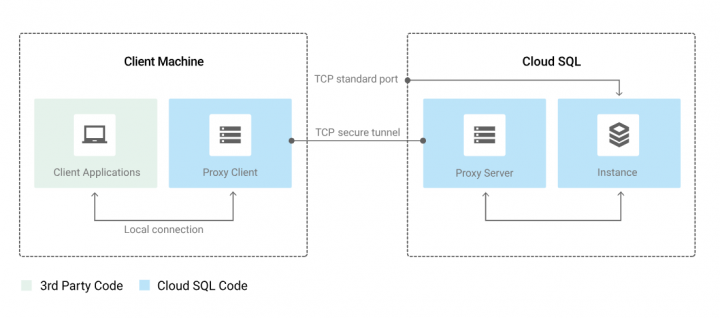 ※ Cloud SQL Auth Proxy 接続イメージ(公式ドキュメントから引用)
※ Cloud SQL Auth Proxy 接続イメージ(公式ドキュメントから引用)
Cloud Spanner
概要
Cloud Spanner は フルマネージドのデータベースサービスであり、関係データベース(RDBMS)の特性と、NoSQLの分散データベースの特性を併せ持つのが特徴です。大規模なデータに対しても高い可用性、一貫性、耐久性を持ちつつ、従来のRDBMS と同様に、スキーマ、トランザクション、SQLクエリの使用が可能となっています。
AWS や他パブリッククラウドにおいて類似のサービスがない、Google Cloud ならではのサービスといえるとおもいます。
主な特徴
- グローバル分散
地理的に分散されたデータセンターにデータを保存・複製することができ、高い可用性と低レイテンシでのデータアクセスを提供します。 - 高可用性
処理能力が不足し、増強させたい場合、ノードを追加することでスケールアウトが可能です。 - 強いトランザクション一貫性
Cloud Spannerは、分散データベースでありながらも、ACIDトランザクションをサポートしており、データの一貫性を確保します。
設計・構築のポイント
インターフェース
Cloud Spanner のデータはSQLによって操作ができ、データベースの作成時において、GoogleSQL と PostgreSQL のいずれかを選択します。開発チームや組織が PostgreSQL に慣れている場合やpsql クライアントを使用したい場合などは、PostgreSQLを選択します。
スケーリング
Cloud Spanner では、負荷の増大時にノードを追加してスケールアウトを行うことにより対応が可能となっています。ノードとは、Cloud Spanner インスタンス内で読み書き処理を実行するコンピューティングリソースです。シングルリージョン構成の場合、リージョンに属する各ゾーンに同じ構成のノード、ストレージが配置されます。
また、Cloud Spanner 用のオートスケールツールを使用した自動スケーリングも可能です。
Cloud Spanner の自動スケーリング
可用性
Cloud Spanner は、ゾーン間やリージョン間での冗長構成を取ることができるため、高可用性を実現することが可能です。(シングルリージョンで99.99%, マルチリージョンで99.999%の可用性)
非機能要件などにより、ワークロードを提供するロケーションによって、シングルリージョン構成かマルチリージョン構成かを検討します。
バックアップ
可用性で触れたように、Cloud Spanner はゾーン、リージョンをまたいで高可用性を実現可能となっています。そのため、障害を想定したバックアップの重要性は低めと言えます。アプリケーション側の原因など、他の理由によるデータ削除などを想定したバックアップを検討します。
バックアップ機能には、バックアップと復元、インポートとエクスポートの2つがあります。
バックアップと復元
バックアップは、オンデマンドで元のデータベースと同じインスタンスに作成されます。保存期間が1年となっているため、1年以上保存する要件がある場合はデータベースのエクスポートを検討します。なお、バックアップはインスタンスのサーバー リソースを利用しない専用ジョブを使用して実行されるため、パフォーマンスへの影響はありません。
また、ポイントインタイム リカバリ機能も備えているため、特定の日時の状態に復元することも可能です。
インポートとエクスポート
データ形式として、CSV とAvro がサポートされています。エクスポートされたデータベースは Google Cloud Storage に保存され、CSV または Avro をサポートしている任意のシステムにデータを移行することが可能です。詳細は 公式ドキュメント をご参照ください。
セキュリティ
暗号化
CloudSQL と同様に、デフォルトで データベースやバックアップのデータや、Google の内部ネットワークを通過するデータは暗号化されます。要件に応じて、顧客管理の暗号鍵(CMEK)の使用を検討します。
認証・認可
Cloud Spanner のインスタンス、テーブルへのアクセスについては、IAM にて制御を行うこととなります。必要な最小の権限をユーザー、グループ、サービスアカウント等に対して付与することが望ましいです。
おわりに
本記事では、Google Cloud のデータベース系サービスについて取り上げてきました。全てのデータベースサービスについては触れていませんが、ワークロードの特徴に応じて、使用するデータベースサービスを検討することも重要であると言えます。公式ブログ にてユースケースの紹介もされいますので、そちらもご参照のうえ、使用するデータベースを決定の参考にしていただければとおもいます。
 ※ 公式ブログより引用
※ 公式ブログより引用