
NewRelic NRQLアラート条件 重要パラメーター解説
はじめに
NewRelic NRQLアラート条件(Conditions)のパラメーターの中で、 筆者が重要と思うものをピックアップして、解説をしている記事です。
集計関数/Window Durationの解説
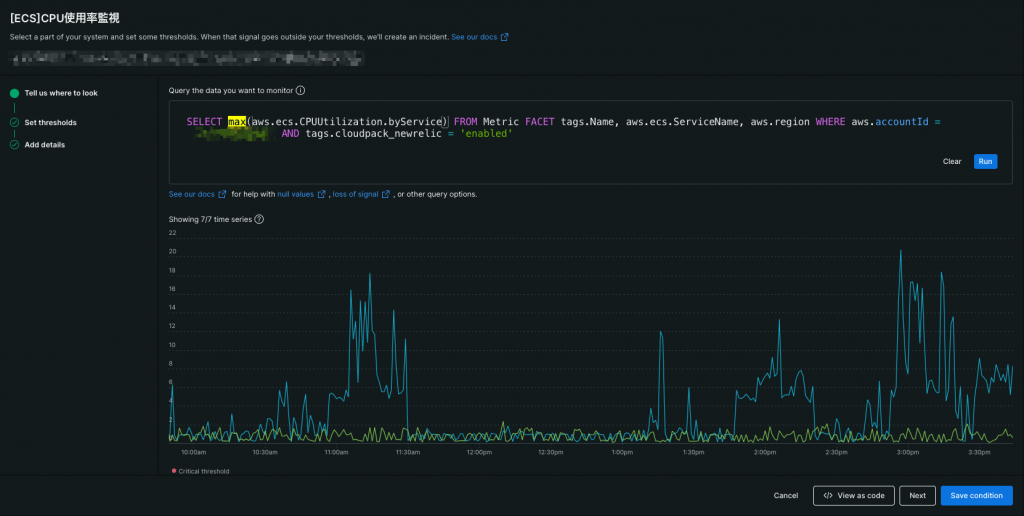
集計関数(スクショ上でハイライトしてある部分)には、様々な種類がありますが、 Window Duration(スクショ下でハイライトしてある部分)との組み合わせによって、集計されるデータ値に差異が出ます。
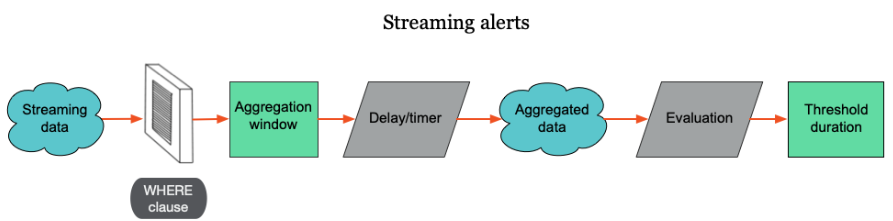
データ集計までの流れとしては、上記の図(NewRelicの公式ドキュメントより引用)の通り、データをNRQLのWHEREでフィルタリング → Aggregation windowに格納 → 集計関数、Window Duration、Delay/Timer(後述)に沿ってデータを集計といった流れになります。
たとえば、データの間隔が60秒毎で値が1,2,3,4,5、Window Durationが300秒、集計関数がmaxの時、集計後のデータ値は5といった感じです。
ちなみに、データの間隔とWindow Durationの値がイコールの場合は、基本的にはAggregation windowに格納されるデータが1つなので、集計関数に何を選ぼうが集計結果に変化はありません。
ただ、この場合においても、データのタイムスタンプのズレで、Window Durationに2つ以上のデータが格納されるパターンがあるようです(同僚の検証結果より)。
例えば、10:00:00と10:00:59のタイムスタンプを持つデータがあったとすると、それらは1つのAggregation windowに格納されます。
Streaming methodの解説
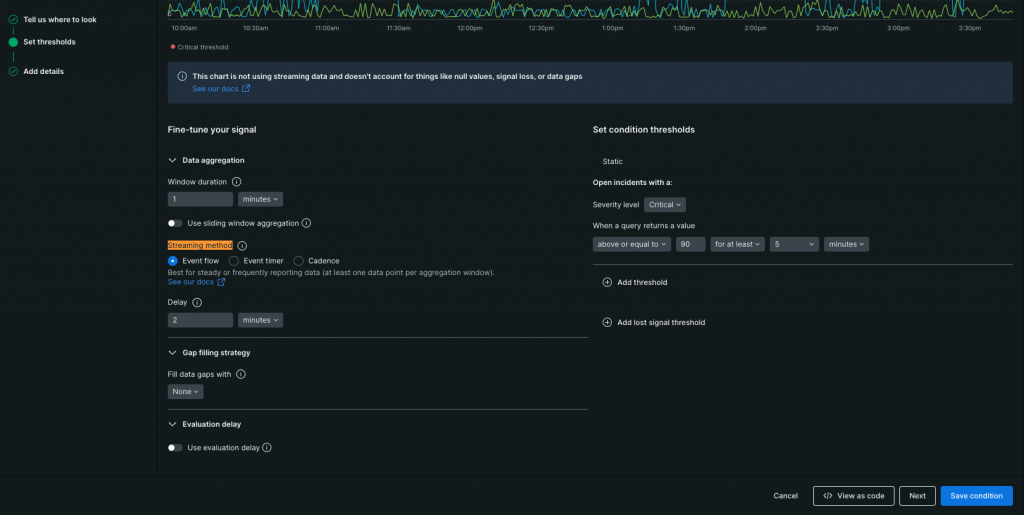
前述のデータ集計ですが、集計のトリガー条件(スクショでハイライトしてある部分)には2つのメソッドが存在します。
※正確には3つですが、1つは古いメソッドなので割愛します
Event Flowの解説
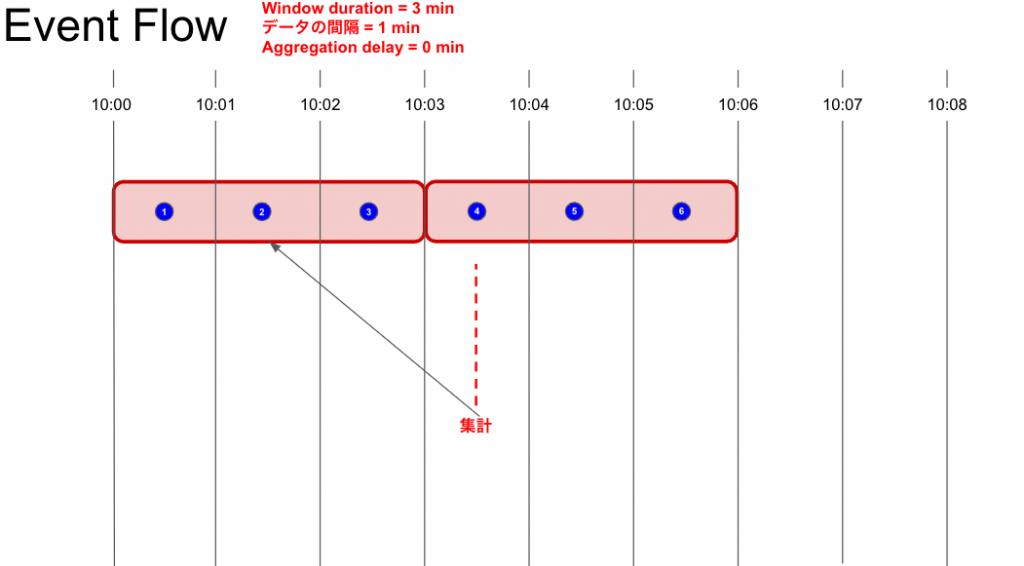
Event Flowは後続のAggregation windowに最初のデータが到着したときに、Aggregation window内のデータを集計します。
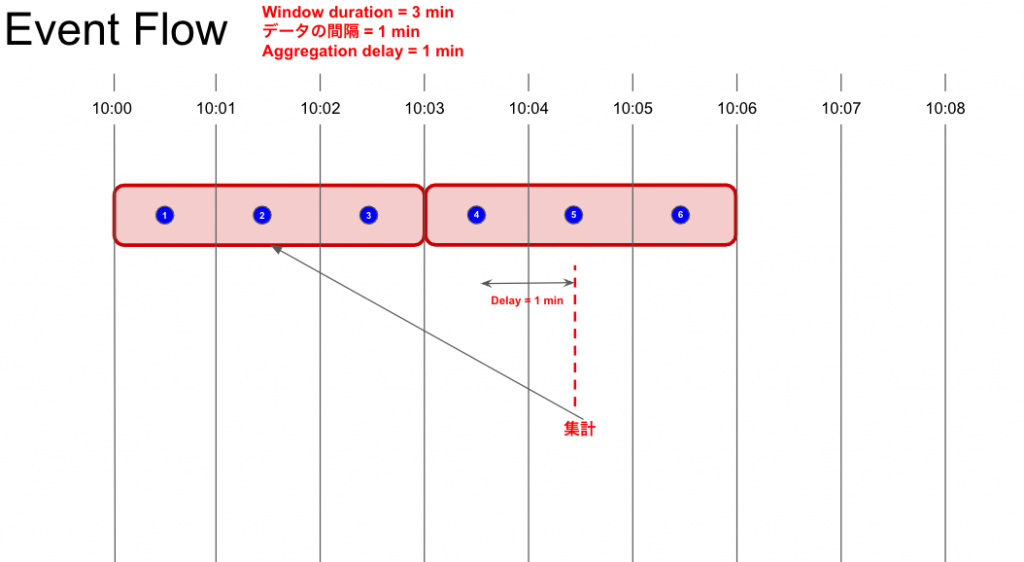
遅延によってデータの到着順番が前後することがあるので(上記図の③のデータが④のデータの後に到着する感じ)、確実にAggregation windowにデータが揃った状態で集計を実施する為のDelayを設定できます。
また、データのタイムスタンプはNewRelicがデータを受信した時間ではなく、データ内のタイムスタンプが参照されます。
これらの仕様から、Event Flowはコンスタントにデータが到着する & 確実にAggregation windowにデータが揃った状態で集計を行いたい監視に適しています。
逆に、後続のAggregation windowにデータが到着しないと、永遠にAggregation window内のデータが集計されない = データが評価されない = 閾値超過していてもアラートが発報されないことがあるといったデメリットもあるので、データの性質によっては適してないメソッドである点は要注意です。
Event Timerの解説
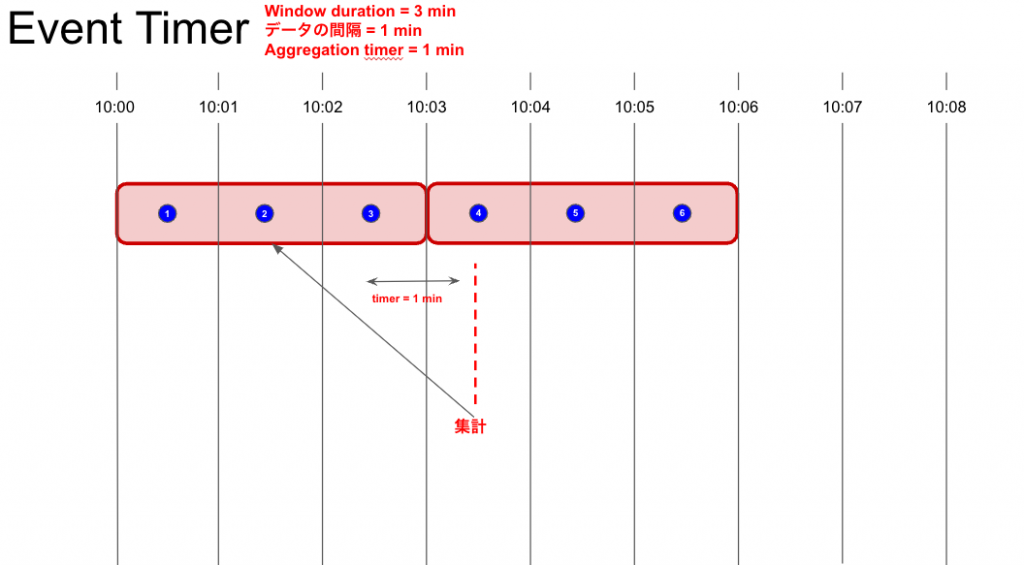
Event TimerはAggregation windowにデータが到着するとTimerのカウントダウンが始まり、カウントダウンが完了する前に、Aggregation windowに次のデータが入ってこないとAggregation window内のデータを集計します。
カウントダウン完了前にAggregation windowに次のデータが入ってきた場合はカウントダウンをリセットし、さらに次のデータ到着を待機します。
データの欠損がない場合は、そのAggregation windowの最後のタイムスタンプを持つデータの到着後にカウントダウンが開始され、そのカウントダウンが完了したタイミングで、Aggregation window内のデータは集計されます。
上記図の場合は、③のデータの到着後の1分後に10:00 ~ 10:03のAggregation window内のデータが集計されます。
④は10:03 ~ 10:06のAggregation windowに格納されるデータなので、④のデータ到着では③のデータ到着後のカウントダウンはリセットされない点に注意です。
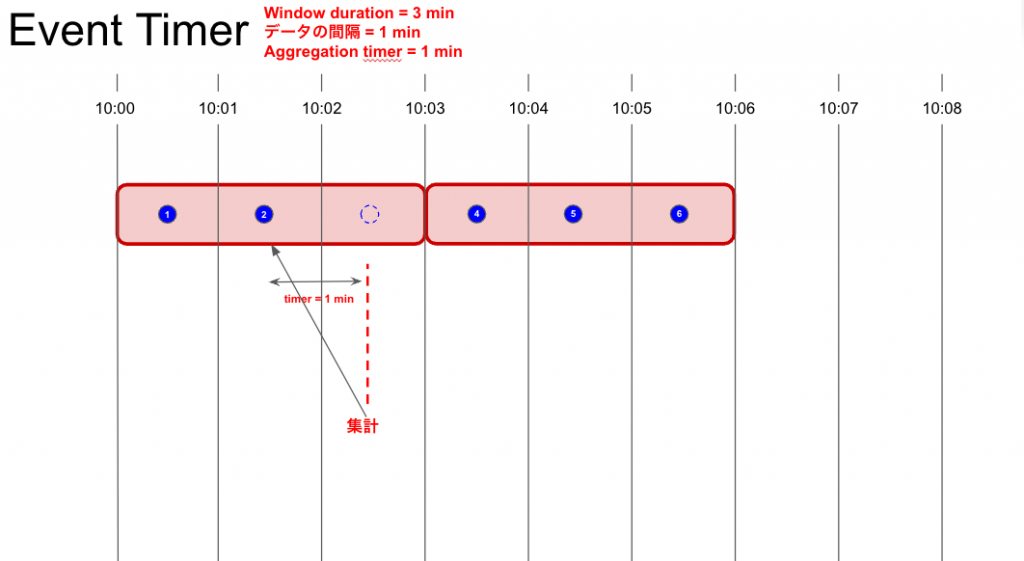
データの欠損がある場合、そのAggregation windowの最後のデータの到着後のカウントダウンが完了したタイミングで、Aggregation window内のデータが揃ってなくともデータが集計されます。
上記図の場合は、②のデータの到着後に③のデータが到着しなかった為、②のデータの到着後の1分後に10:00 ~ 10:03のAggregation window内のデータが集計されます。
これらの仕様から、Event Timerはデータの欠損がありうる & Aggregation windowにデータが揃ってなくても良いから集計を行い、確実にアラートを発報したい監視に適しています。
また、Timerの秒数は少なくともデータの間隔以上に設定する必要があります。
そうしないと、遅延と欠損なくデータが到着してるのにも関わらず、カウントダウンが完了して、Aggregation window内のデータが揃って無い状態で毎回集計がされてしまうからです。
データ到着に遅延があることを考慮すると、TimerはAggregation window以上の秒数を設定した方が良いとされてます。
Threshold duration/Threshold occurrencesの解説
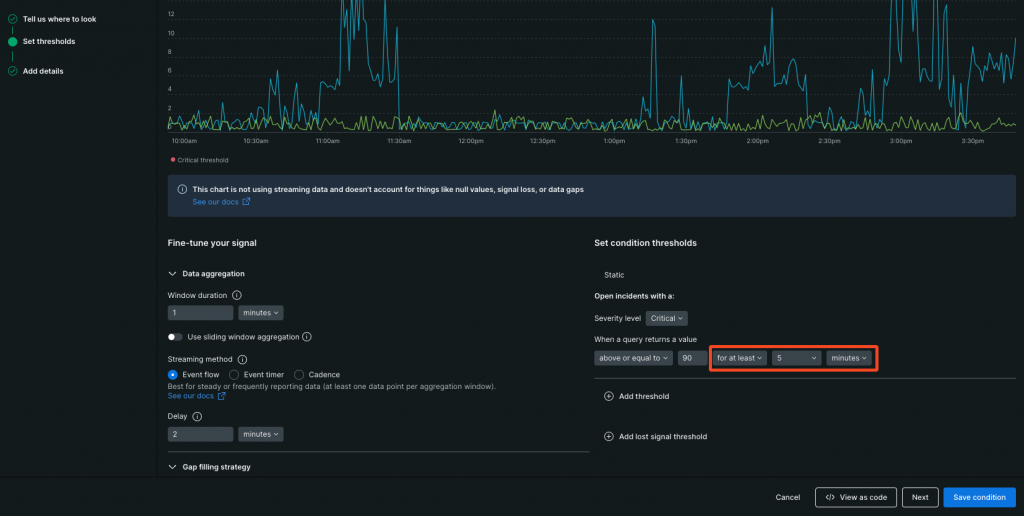
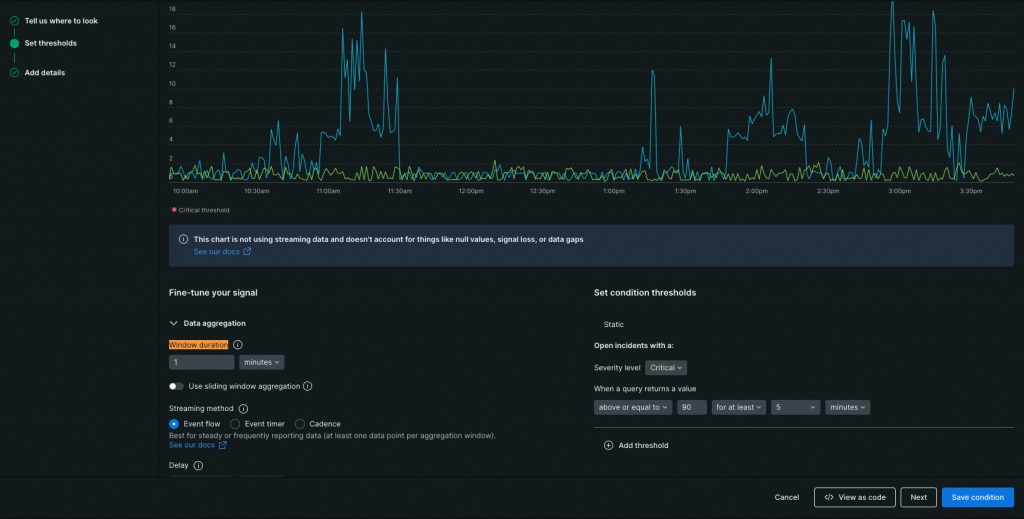
前述の流れで、集計されたデータはThreshold duration(スクショで赤枠で囲ってる5minutesの部分)とThreshold occurrences(スクショで赤枠で囲ってるfor at leastの部分)に沿って、アラート判定が行われます。
判定は一度ではなく、Window Duration、Threshold durationの設定値に沿って数回行われたのち、アラート発報となります。
Window Duration = Threshold durationの場合は、判定回数は1回Window Duration < Threshold durationの場合は、判定回数はThreshold duration ÷ Window Duration
たとえば、Window Durationが60秒でThreshold durationが300秒の場合、判定回数は5回になります。
その数回の判定の中で、何回判定がNGだったらアラート発報するのかを決めるのが、Threshold occurrencesです。
Threshold occurrencesに設定できる値は以下の通りです。
- for at least(Threshold duration間の全て集計データで判定NG)
- at least once in(Threshold duration間のいずれかの集計データで判定NG)
これらの仕様から、Threshold durationはAggregation windowの整数倍以上の値を設定する必要があります。
Window Duration = Threshold durationとWindow Duration < Threshold duration & Threshold duration = at least once inとでは、判定が一度でもNGの場合はアラート発報といった点で差異はありませんが、何回判定がNGだったかをThreshold occurrencesで切り替え可能といった点から、個人的には Window Duration < Threshold duration が良いと考えています。
Fill dataの解説
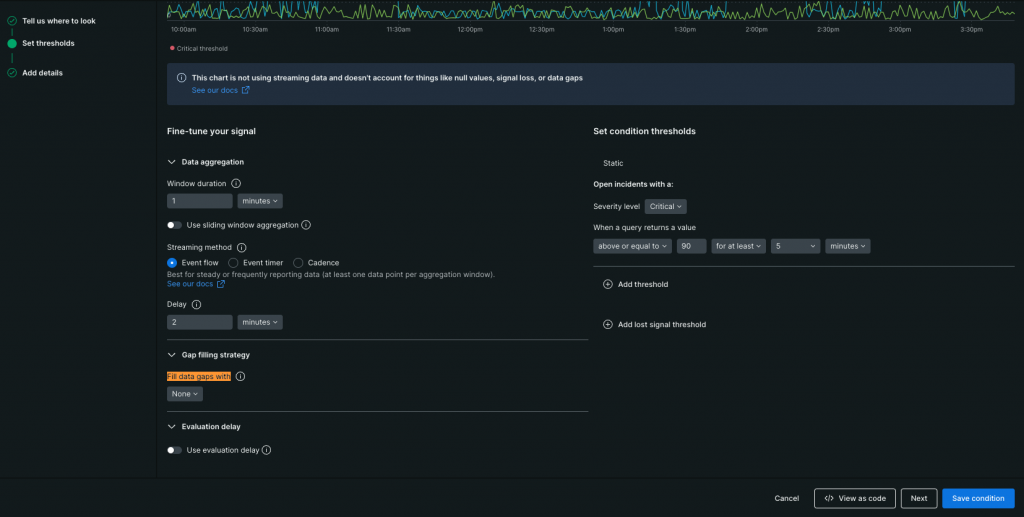
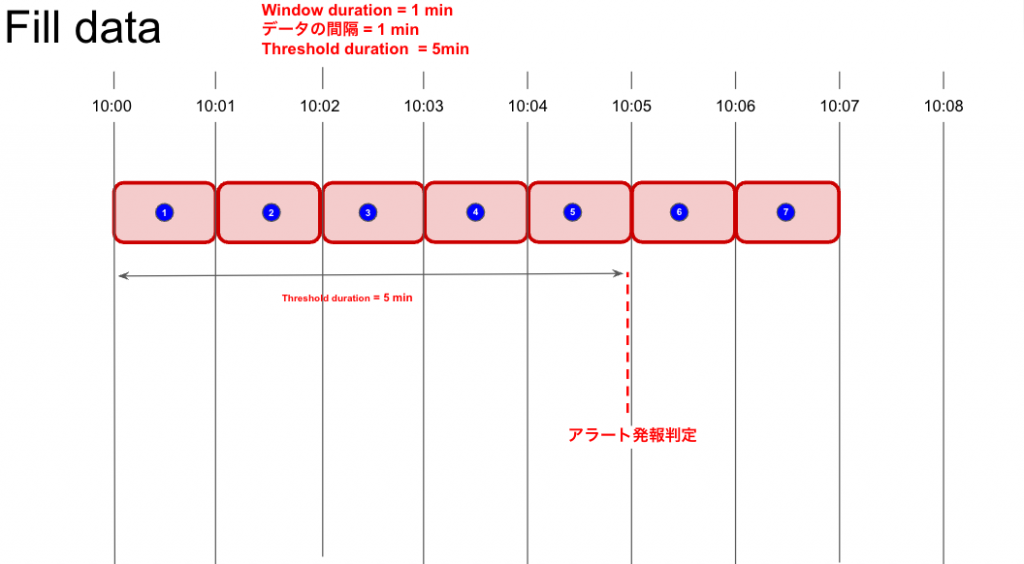
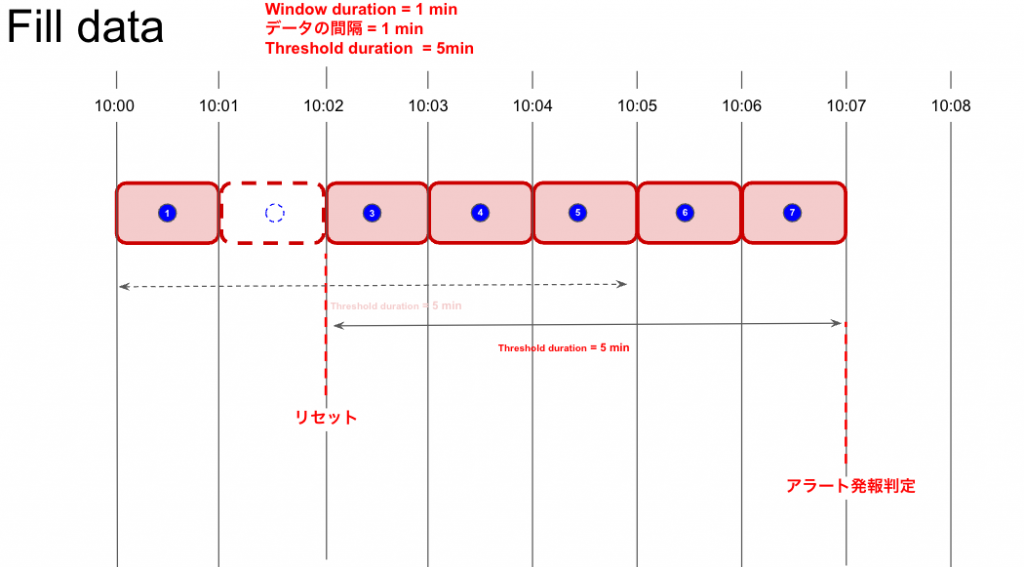
何かしらの理由(Event Flowを選択時、後続のAggregation windowにデータが到着しなかった等)で、Aggregation windowのデータが集計されなかった時、Threshold durationの起点がリセットされる為、状況によってはアラート発報が遅延したり、アラート発報の抜けが発生したりします。
これらを避ける為に、欠損した集計データの穴埋めの振る舞いを設定するパラメーターがFill data(スクショでハイライトしてある部分)です。
Fill dataに設定できる値は以下になります。
- None(集計データを穴埋めしない)
- Custom static value(任意の値で集計データを穴埋め)
- Last known value(直近のAggregation windowで集計されたデータ値で穴埋め)
Streaming methodの考慮をしっかり行い、そもそもの集計データの欠けを極力無くしてるのであれば、個人的にはNoneで良いと考えています。
集計データの欠けが起きやすいデータを監視しており、アラート発報の遅延/抜けが許されないような、厳しい要件がある場合に使用を検討で良いでしょう。
Signal lossの解説
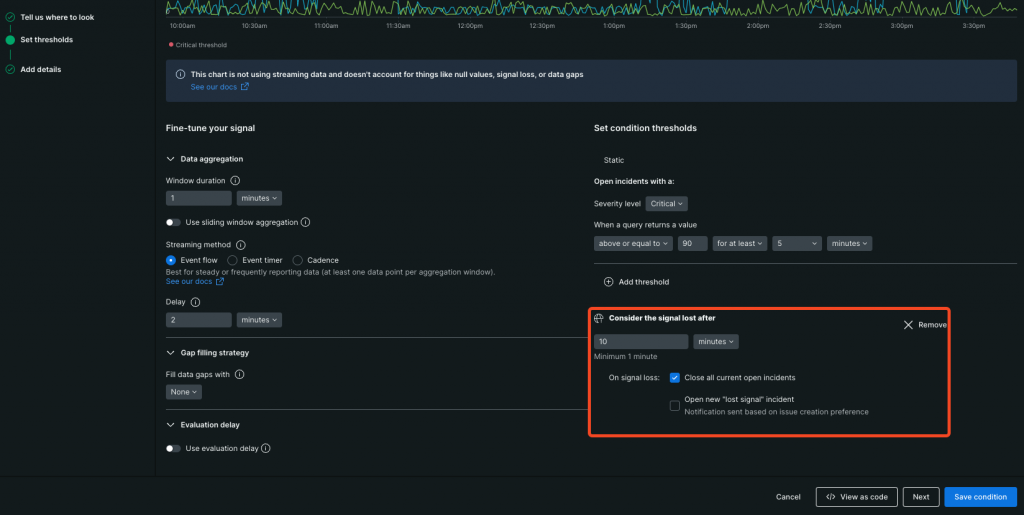
データがNRQLのWHEREでフィルタリングされる → Aggregation windowに格納の流れの中で、何らかの理由(監視対象の削除、監視対象側の障害でデータが送信されない等々)でAggregation windowに指定の時間データが格納されない時、それを信号損失と見なし、その振る舞いを設定するパラメーターがSignal loss(スクショで赤枠で囲ってる部分)です。
信号損失っていうと仰々しいですが、大本のデータが記録されてない時(例えば、レイテンシーやエラーレート系のCloudWatchメトリクスはリクエストが無いとデータが記録されません)や、ログ監視等で、WHAREで異常時の文言をフィルタリングしており、正常時はフィルタリング条件に合致しない時、これらもNewRelic的には信号損失として扱われるので、注意です。
Close all current open incidentsの解説
NewRelicの自動インシデントクローズの方法には、以下の3つがあります。
- 閾値の条件を満たさなくなったことによるクローズ
- Close open incidents afterによる時間クローズ
- Signal lossのClose all current open incidentsによる信号損失クローズ
あるべきクローズ方法は1番の閾値の条件を満たさなくなったことによるクローズですが、インシデントオープン後に、監視対象からのデータがAggregation windowに格納されない時、クローズの判定が出来ず、インシデントがオープンされたままになってしまいます。
それを防ぐ為のクローズ方法が3番のSignal lossのClose all current open incidentsによる信号損失クローズです。
ただ、2番の Close open incidents afterによる時間クローズとの兼ね合いがややこしいので、個人的にはこの機能は無効化で良いと考えています。
有効化するにしても、Signal loss < Close open incidents afterになるようにしないと、Signal lossのClose all current open incidentsが機能しなくなるので注意が必要です。
Open new lost signal incidentsの解説
信号損失と判定された時にアラートを発報する設定です。
なんらかの理由で信号損失が発生し、それが継続した場合は、監視が正常に行えてないことになります。
それを検知する為の設定がOpen new lost signal incidentsです。
ただ、アラートの内容が通常のアラートとOpen new lost signal incidentsとで差異が無い為、場合によっては混乱を招く恐れがあります。
その為、厳しい要件がある場合は、有効化を検討する形で良いでしょう。
Close open incidents afterの解説
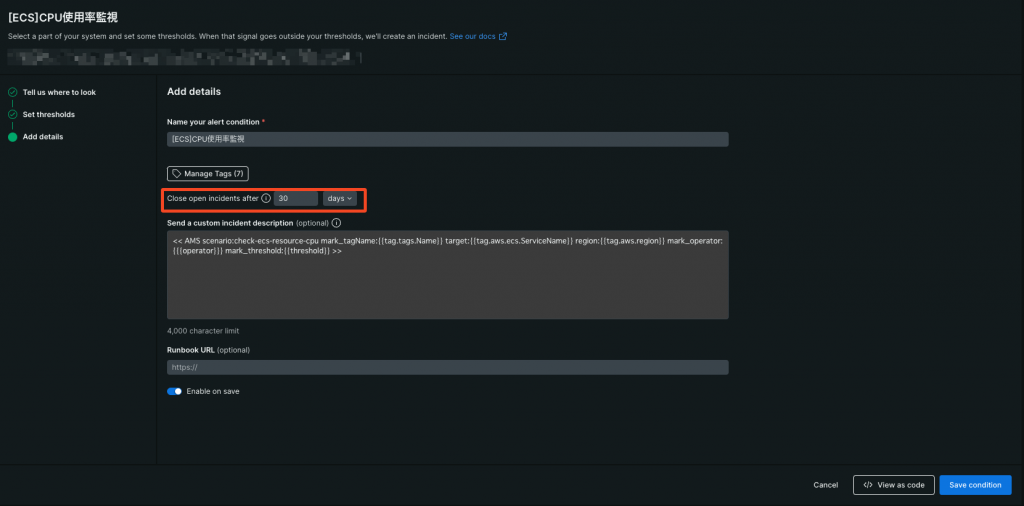
時間経過でインシデントを自動クローズする時間を設定するパラメーターがClose open incidents after(スクショで赤枠で囲ってる部分)です。
時間経過で自動クローズしないといった選択肢は無く、設定値は最短で5minutes、最長で30daysとなってます。
Signal lossの箇所でも少し触れましたが、あるべきクローズ方法は閾値の条件を満たさなくなったことによるクローズなので、基本的には最長の30daysを設定しておき、あるべきクローズ方法が取れないNRQLアラート条件(Conditions)については、自動クローズするまでの時間を個別に調整する形で良いでしょう。
以下仕様があるので、自動クローズするまでの時間は、監視内容、監視要件によって吟味が必要です。
- インシデントがオープンのままだと再発時にアラートが発報されない
- 障害継続中にインシデントが自動クローズされてしまうと、その都度アラートが発報される
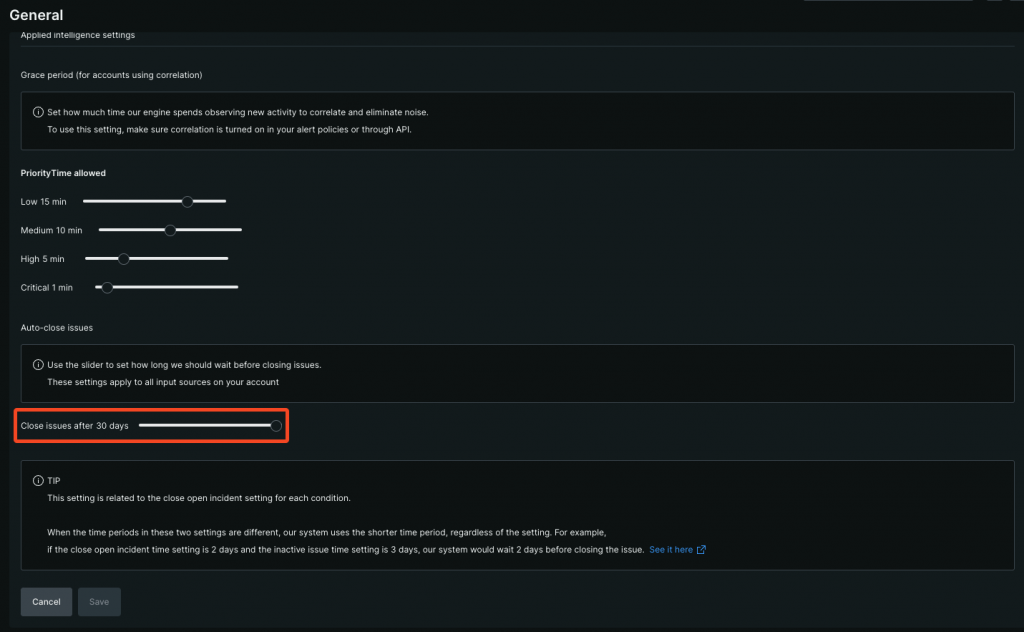
また、アカウント全体の自動クローズ設定(スクショで赤枠で囲ってる部分)とで、設定値が短い方が優先される仕様があるので、注意が必要です。
筆者は、アカウント全体の自動クローズ設定を最長に設定し、NRQLアラート条件(Conditions)側で、個別に自動クローズ設定を実施しています。
おまけ
Dashboard
Dashboardで表示するデータも、NRQLアラート条件(Conditions)と同じくNRQLでクエリする形になるのですが、Dashboard固有で考慮するパラメーターもあるので、ピックアップしたものを、おまけとして記載します。
LIMIT
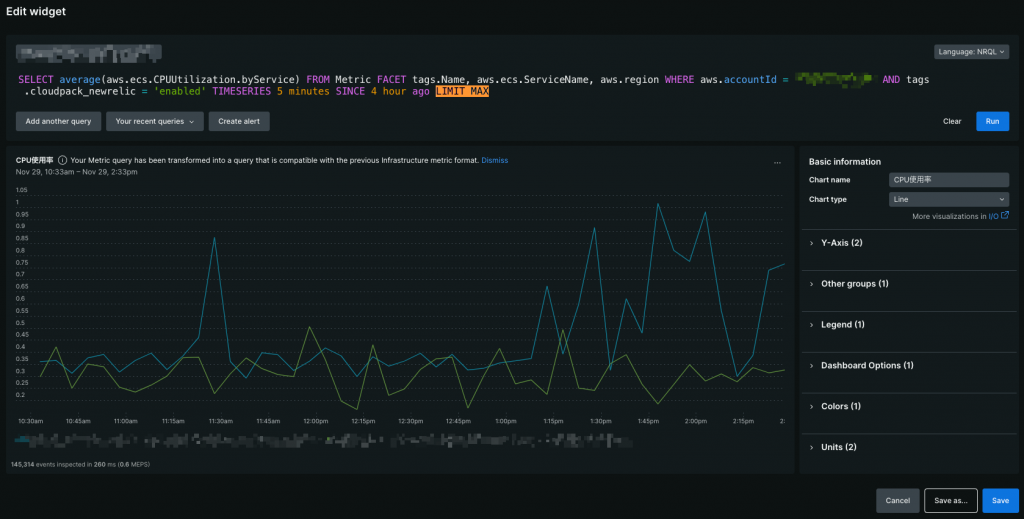
Dashboardに表示させる対象(エンティティ)の数を制限するクエリ句(スクショ上でハイライトしてある部分)です。
明示的に数を指定しないと、デフォルトで10個の対象しか表示されないので注意です。
SINCE
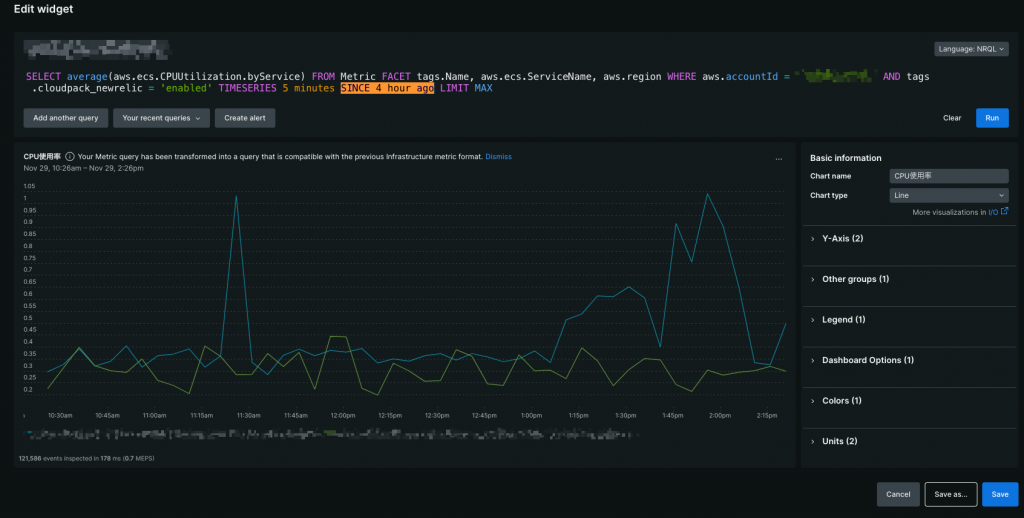
データの表示範囲(時間幅)を指定するクエリ句(スクショ上でハイライトしてある部分)です。
SINCEで指定した時間はあくまでもデフォルト値であって、データの表示範囲はDashboard上で都度調整可能です。
TIMESERIES(Window Duration)
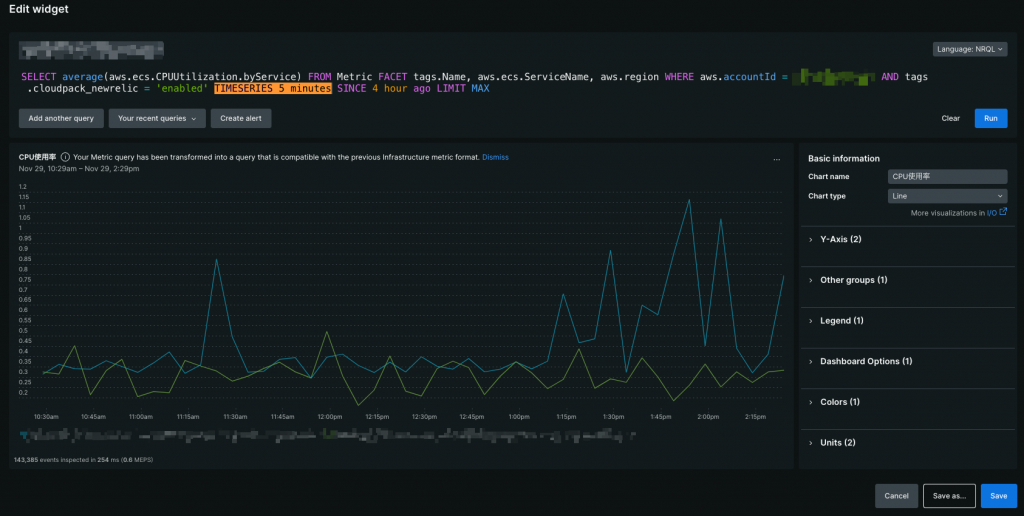
データをグラフ表示する為のクエリ句(スクショ上でハイライトしてある部分)です。
TIMESERIESのXXXの部分で、グラフのメモリの粒度を指定します。
ここの値はNRQLアラート条件(Conditions)のWindow Durationに相当します。
XXXの部分を明示的に指定しないと、グラフの表示範囲(SINCE)に応じて自動調整されますが、 表示範囲が比較的小さくても、粒度が結構荒くなるので、明示的に設定することをおすすめします。
グラフの表示範囲毎に表示できるメモリの粒度には限界が存在するので、その限界を超えてる場合は、明示的に設定していたとしても、ここの値は自動調整される点には注意です。
また、Dashboardの性質上、グラフの表示範囲を大きくすることがある(1ヶ月とか) = メモリの粒度が大きくなりやすい = 集計されるデータの数が多くなりやすいので、NRQLアラート条件(Conditions)以上に、どの集計関数を選択するかの考慮が必要になります。
理由としては、メモリの粒度が5分程度なら大きな影響はありませんが、これが1日以上とかになってくると、集計関数にmaxやmin等を用いてる場合、グラフの波打ちが極端になる可能性があるからです。
グラフを均す為にも、Dashboardの集計関数にはaverageが向いてるケースが多いです。
さいごに
筆者の「それってあなたの感想ですよね?」記述もあり、誤りもあるかもしれませんが、NRQLアラート条件(Conditions)のパラメーター理解の助けになれたら幸いです。



