はじめに
AWS でディザスタリカバリ (DR) 環境を設計する機会がありましたので紹介します。以下の要件です。
- AZ 間フェイルオーバーは自動
- リージョン間フェイルオーバーは自動または手動
- 静的 IP を公開できる
静的 IP が必要な場合、以下 2 パターンが代表的だと思います。今回は前者の NLB パターンを紹介します。
検証リソースの構築は CDK で一撃化しています。
構成図
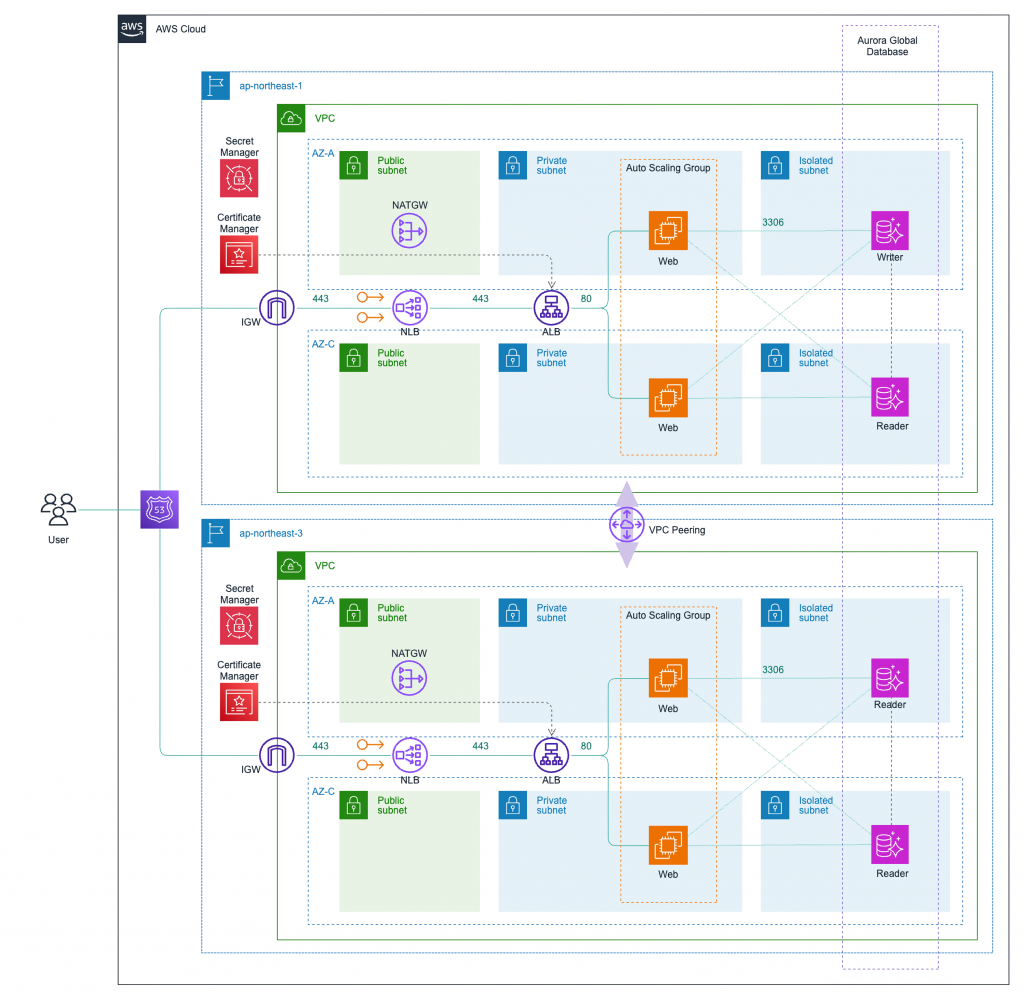
- 静的 IP を得るために ALB の前段に NLB を配置
- TLS 通信は ALB で終端
- ALB 配下の EC2 インスタンスはオートヒーリングで可用性を担保
- DB は Aurora Global Database
DR 方式
こちらの AWS ブログにおけるウォームスタンバイとマルチサイトアクティブ/アクティブの間、いわゆるホットスタンバイ方式を採用します。要件はシビアで、仮に RTO を 30 分、 RPO を数分とします。
AWS では特にデータベースの考え方が重要になります。上記ブログにもある通り、マルチサイトアクティブ/アクティブを採用したい場合は DynamoDB グローバルテーブルを検討する必要があります。
しかし今回は RDB が前提です。RDS や Aurora ではリージョン間で Act-Act 構成を組むのが難しいため、RTO/RPO を可能な限り短縮するために Aurora Global Database を選定します。またその他のリソースは同スペックのリソースをあらかじめセットアップしておきます。災害時は以下の操作でリージョン間フェイルオーバーできる状態を目指します。
- DNS 切り替えによるリクエストの向き先変更 (自動 or 手動)
- データベースのマネージドなフェイルオーバー操作
ちなみにデータベースを RTO/RPO 要件で選定する際はこのドキュメントが有用です。
注意点
注意点がいくつかあります。
- Aurora Global Database は手動でのフェイルオーバー操作が必要
- NLB のターゲットを ALB にする場合の制約に注意
- グローバル IP が AZ の数だけ必要
Aurora Global Database は手動でのフェイルオーバー操作が必要
Aurora Global Database の利点は、リージョン間でデータのレプリケーションをマネージドでいい感じにやってくれるところです。ドキュメントに以下の記載があり、非常に高性能であることがわかります。
| AWS database service | Replication method to DR Region | Possible standby classification | RTO | RPO |
|---|---|---|---|---|
| Amazon Aurora MySQL | グローバルデータベースが別のリージョンにセカンダリクラスタを持つ | – 読み込みトラフィックをサポートする機能を備えたホットスタンバイ – 読み込みトラフィックをサポートする機能を備えたウォームスタンバイ |
通常は 1 分未満 | 通常は 1 秒未満 |
| Amazon Aurora PostgreSQL | 同上 | 同上 | 同上 | 同上 |
別リージョンの DB クラスターに Writer 機能を移すオペレーションはユーザーが手動で行います。簡略化されたマネージドな操作が提供されますが、自動で実行されるわけではないことに注意が必要です。
スイッチオーバーとフェイルオーバーの 2 つがあり、状況によってどちらを行うかを選択します (ドキュメント)
スイッチオーバー
この操作は、以前は「管理された計画的フェイルオーバー」と呼ばれていました。
このアプローチは、運用保守やその他の計画的な運用手順など、管理されたシナリオに使用します。
この機能は、他の変更を行う前にセカンダリ DB クラスタをプライマリと同期するため、RPO は 0(データ損失なし)です。
フェイルオーバー
この操作は、計画外の停止から回復するために使用します。
このアプローチでは、Aurora グローバル・データベースのセカンダリ DB クラスタの 1 つにリージョンをまたいだフェイルオーバーを実行します。このアプローチの RPO は通常、秒単位で測定されるゼロ以外の値です。
データ損失の量は、障害発生時の AWS リージョン間の Aurora グローバルデータベースのレプリケーションラグに依存します。
意図的な Writer 機能の移転は前者、実際の災害対応は後者になります。災害時は問答無用で片側が落ちるため、その時のレプリケーションラグに応じてデータがロスするということです。
AWS CLI でも実行できます。フェイルオーバーの場合は --allow-data-loss フラグを明示的に設定する必要があるようです。
# switchover aws rds --region region_of_primary \ switchover-global-cluster --global-cluster-identifier global_database_id \ --target-db-cluster-identifier arn_of_secondary_to_promote
# failover aws rds --region region_of_selected_secondary \ failover-global-cluster --global-cluster-identifier global_database_id \ --target-db-cluster-identifier arn_of_secondary_to_promote \ --allow-data-loss
DNS 向き先変更などでフロント側が自動で DR 切り替えできても、この手順を頭に入れておかなければ DB 書き込みワークロードが落ちたままになってしまうことが想定されます。読み込みワークロードは平常時からクロスリージョンを考慮しておくことで救えるかもしれませんね。
また重要な点として、クラスター間で DB のエンジンバージョンに互換性がない場合、このようなマネージド操作ができずマニュアル操作が必要になります。
NLB のターゲットを ALB にする場合の制約
NLB は通常、自身で TLS 443 を終端し、配下のリソースに TCP 80 で転送できます。
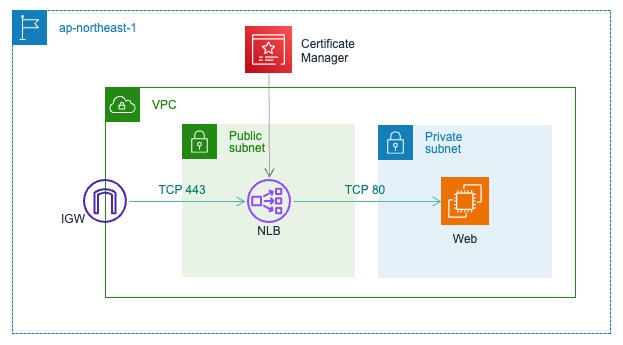
しかし NLB のターゲットを ALB にする場合は以下の制約があります。
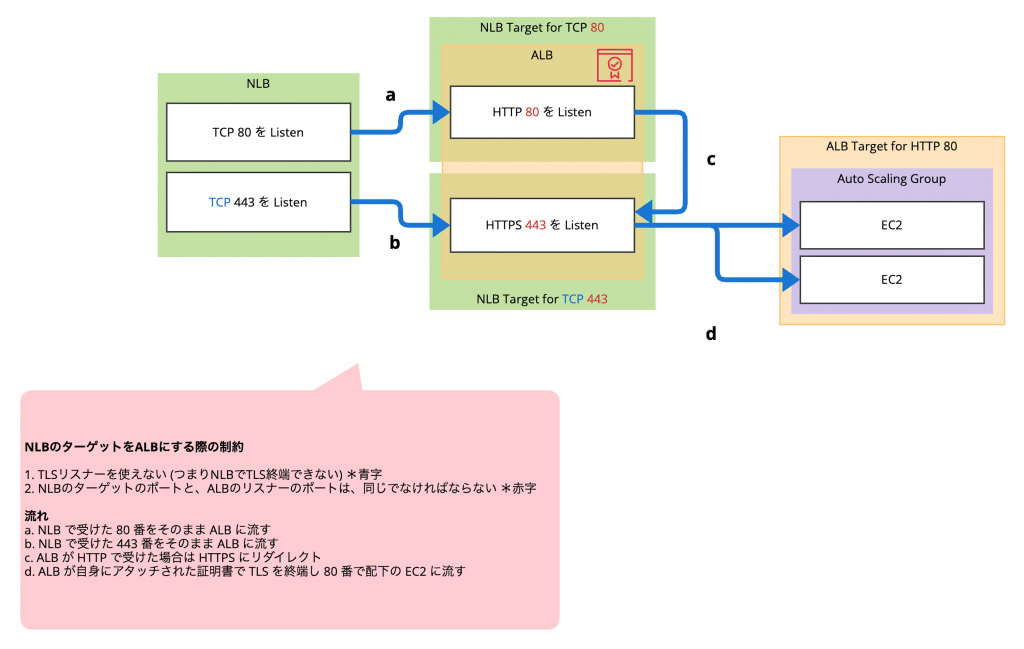
- TLS リスナーを使えない (つまり NLB で TLS 終端できない)
- NLB のターゲットのポートと ALB のリスナーのポートは同じでなければならない
ドキュメントにさらっと書いてありますね。
デフォルトはポート 80 で TCP トラフィックを受け入れるリスナーです。TCP リスナーだけがアプリケーションロードバランサーのターゲットグループにトラフィックを転送できます。Protocol は TCP のままにしておく必要がありますが、Port は必要に応じて変更できます。
この設定で、アプリケーションロードバランサーの HTTPS リスナーを使って TLS トラフィックを終了させることができます。
リスナーについては、任意のポートに HTTP または HTTPS リスナーを作成できます。ただし、このリスナーのポート番号が、このアプリケーションロードバランサーが常駐するターゲットグループのポート番号と一致していることを確認する必要があります。
このため、以下のような設定でリスナーとターゲットグループを設定し、ALB で TLS を終端する必要があります。
ALB
- HTTP 80 のリスナーを作成
- HTTPS 443 のリスナーを作成
- HTTP 80 で受けたら HTTPS 443 にリダイレクトするアクションを設定
- HTTPS 443 のターゲットグループを作成
- HTTPS 443 で受けたら HTTP 80 で配下のインスタンスに流すように設定 (ここで TLS 終端)
NLB
- TCP 80 のリスナーを作成
- TCP 443 のリスナーを作成
- TCP 80 のターゲットグループを作成
- TCP 80 のターゲットグループには ALB の HTTP 80 を登録
- TCP 443 のターゲットグループを作成
- TCP 443 のターゲットグループには ALB の HTTPS 443 を登録
このように、手数が多くなります。図で表すとこんな流れでしょうか。
グローバル IP が AZ の数だけ必要
これは当然といえば当然ですが、意識しておくべきです。NLB は AZ ごとに Elastic IP をアタッチするので、2 AZ で可用性を担保するなら 2 IP、かつマルチリージョンなら 4 IP になります。別記事で紹介する予定の Global Accelerator であれば 2 IP で済みます。
構築
この構成は CDK を使って一撃化することが可能です。
. ├── bin │ └── main.ts ├── lib │ ├── constructs │ │ ├── database.ts │ │ ├── dns.ts │ │ ├── network.ts │ │ ├── peering.ts │ │ └── service.ts │ ├── peering-stack.ts │ └── regional-stack.ts ├── scripts │ └── helper │ └── request.sh ├── src │ └── ec2 │ ├── userdata-osaka.sh │ └── userdata-tokyo.sh ├── test │ └── aws-dr-sample.test.ts ├── LICENSE ├── README.md ├── cdk.context.json ├── cdk.example.json ├── cdk.json ├── jest.config.js ├── package-lock.json ├── package.json └── tsconfig.json
サービス
NLB, ALB, Auto Scaling Group などは Service という名付けでコンストラクトにまとめています。NLB-ALB 間の一連の設定や Auto Scaling の設定はこちらを参考にしてください。
ピアリング
VPC を作るだけならなんら難しくないのですが、リージョン間ピアリングで内部的に通信可能な状態にしたい場合は少々面倒です。該当のコードはこちらです。
東京側
- 東京リージョンで VPC ピアリングを作成する
- 各ルートテーブルで大阪側 VPC の CIDR を向いた通信のターゲットをピアリング接続にする
- 大阪側スタックの作成時に指定するため、ピアリング接続を props で渡せるようにする
大阪側
- 各ルートテーブルで東京側 VPC の CIDR を向いた通信のターゲットをピアリング接続にする
コード
まずルート追加用の関数を作ります。
// Function for create route to VPC peering connection
const createRoutes = (
scope: Construct,
area: "Tokyo" | "Osaka",
targetCidrBlock: string,
subnets: cdk.aws_ec2.ISubnet[],
subnetType: "Public" | "Private" | "Isolated",
connection: cdk.aws_ec2.CfnVPCPeeringConnection
) => {
subnets.forEach((subnet: cdk.aws_ec2.ISubnet, index: number) => {
new cdk.aws_ec2.CfnRoute(scope, `VpcRoute${area}${subnetType}${index}`, {
routeTableId: subnet.routeTable.routeTableId,
destinationCidrBlock: targetCidrBlock,
vpcPeeringConnectionId: cdk.Token.asString(connection.attrId),
});
});
};
リクエスタである東京では以下のようにします。
対向リージョンを peerRegion で、対向 VPC の ID を peerVpcId で渡す必要があります。
// lib/constructs/peering.ts
...
export interface RequesterProps {
serviceName: string;
vpcPrimary: cdk.aws_ec2.IVpc;
vpcSecondary: cdk.aws_ec2.IVpc;
peerRegion: string;
}
export class Requester extends Construct {
public readonly vpcPeeringConnection: cdk.aws_ec2.CfnVPCPeeringConnection;
constructor(scope: Construct, id: string, props: RequesterProps) {
super(scope, id);
// VPC peering connection
this.vpcPeeringConnection = new cdk.aws_ec2.CfnVPCPeeringConnection(this, "PeeringConnection", {
vpcId: props.vpcPrimary.vpcId,
peerVpcId: props.vpcSecondary.vpcId,
peerRegion: props.peerRegion,
});
cdk.Tags.of(this.vpcPeeringConnection).add("Name", `${props.serviceName}-peering-connection`);
createRoutes(
this,
"Tokyo",
props.vpcSecondary.vpcCidrBlock,
props.vpcPrimary.publicSubnets,
"Public",
this.vpcPeeringConnection
);
createRoutes(
this,
"Tokyo",
props.vpcSecondary.vpcCidrBlock,
props.vpcPrimary.privateSubnets,
"Private",
this.vpcPeeringConnection
);
createRoutes(
this,
"Tokyo",
props.vpcSecondary.vpcCidrBlock,
props.vpcPrimary.isolatedSubnets,
"Isolated",
this.vpcPeeringConnection
);
}
}
...
アクセプタである大阪側はピアリング接続の作成が不要ですが、東京側で作ったピアリング接続の情報を渡す必要があります。
// lib/constructs/peering.ts
...
export interface AccepterProps {
serviceName: string;
vpcPrimary: cdk.aws_ec2.IVpc;
vpcSecondary: cdk.aws_ec2.IVpc;
connection: cdk.aws_ec2.CfnVPCPeeringConnection | undefined; // <= コレ
}
export class Accepter extends Construct {
constructor(scope: Construct, id: string, props: AccepterProps) {
super(scope, id);
cdk.Tags.of(props.connection!).add("Name", `${props.serviceName}-peering-connection`);
createRoutes(
this,
"Osaka",
props.vpcPrimary.vpcCidrBlock,
props.vpcSecondary.publicSubnets,
"Public",
props.connection!
);
createRoutes(
this,
"Osaka",
props.vpcPrimary.vpcCidrBlock,
props.vpcSecondary.privateSubnets,
"Private",
props.connection!
);
createRoutes(
this,
"Osaka",
props.vpcPrimary.vpcCidrBlock,
props.vpcSecondary.isolatedSubnets,
"Isolated",
props.connection!
);
}
}
...
スタックでは tokyo | osaka で分岐させます。connection に対して undefined を許容し、東京の場合は connection を外部に渡せるようにしておきます。一方、大阪ではその東京側スタックの connection を使うので undefined にします。
// lib/peering-stack.ts
...
export interface DrSamplePeeringStackProps extends StackProps {
serviceName: string;
area: "tokyo" | "osaka";
vpcPrimary: cdk.aws_ec2.IVpc;
vpcSecondary: cdk.aws_ec2.IVpc;
peerRegion: string;
connection: cdk.aws_ec2.CfnVPCPeeringConnection | undefined;
}
export class DrSamplePeeringStack extends Stack {
public readonly connection: cdk.aws_ec2.CfnVPCPeeringConnection | undefined;
constructor(scope: Construct, id: string, props: DrSamplePeeringStackProps) {
super(scope, id, props);
if (props.area === "tokyo") {
const connection = new Requester(this, "PeeringRequester", {
serviceName: props.serviceName,
vpcPrimary: props.vpcPrimary,
vpcSecondary: props.vpcSecondary,
peerRegion: props.peerRegion,
});
this.connection = connection.vpcPeeringConnection;
} else if (props.area === "osaka") {
new Accepter(this, "PeeringAccepter", {
serviceName: props.serviceName,
vpcPrimary: props.vpcPrimary,
vpcSecondary: props.vpcSecondary,
connection: props.connection,
});
this.connection = undefined;
}
}
}
あとは以下のようにそれぞれパラメータを指定してスタックをデプロイします。
// bin/main.ts
...
// Deploy stack for VPC peering tokyo side
const tokyoPeeringStack = new DrSamplePeeringStack(app, "DrSamplePeeringStackTokyo", {
env: {
account: process.env.CDK_DEFAULT_ACCOUNT,
region: "ap-northeast-1",
},
terminationProtection: false,
crossRegionReferences: true,
serviceName: serviceName,
area: "tokyo",
vpcPrimary: tokyoStack.vpc,
vpcSecondary: osakaStack.vpc,
peerRegion: osakaStack.region,
connection: undefined,
});
// Deploy stack for VPC peering osaka side
const osakaPeeringStack = new DrSamplePeeringStack(app, "DrSamplePeeringStackOsaka", {
env: {
account: process.env.CDK_DEFAULT_ACCOUNT,
region: "ap-northeast-3",
},
terminationProtection: false,
crossRegionReferences: true,
serviceName: serviceName,
area: "osaka",
vpcPrimary: tokyoStack.vpc,
vpcSecondary: osakaStack.vpc,
peerRegion: osakaStack.region,
connection: tokyoPeeringStack.connection, // <= これが重要
});
...
DNS フェイルオーバー
Route 53 を利用したリージョン間切り替えは自動/手動どちらも可能ですが、今回は自動フェイルオーバーを設定してみました。これはリージョンごとに設定すればよく、東京側を PRIMARY、大阪側を SECONDARY にすれば OK です。エイリアスレコードなので、ヘルスチェックも不要です。
// lib/constructs/dns.ts
...
export interface DNSProps {
serviceName: string;
area: "tokyo" | "osaka";
globalDomainName: string;
failoverType: "PRIMARY" | "SECONDARY";
hostedZone: cdk.aws_route53.IHostedZone;
nlb: cdk.aws_elasticloadbalancingv2.INetworkLoadBalancer;
}
export class DNS extends Construct {
constructor(scope: Construct, id: string, props: DNSProps) {
super(scope, id);
// A record for DNS failover
const nlbARecord = new cdk.aws_route53.CfnRecordSet(this, "RecordSet", {
name: props.globalDomainName,
type: cdk.aws_route53.RecordType.A,
aliasTarget: {
dnsName: props.nlb.loadBalancerDnsName,
hostedZoneId: props.nlb.loadBalancerCanonicalHostedZoneId,
evaluateTargetHealth: true,
},
failover: props.failoverType,
healthCheckId: dnsHealthCheck.attrHealthCheckId,
hostedZoneId: props.hostedZone.hostedZoneId,
setIdentifier: `${props.serviceName}-${props.area}-id`,
});
}
}
ここまでの設定で、リクエストの向き先は自動で切り替えられ、DB は書き込みワークロード回復のために手動オペレーションを行うことで災害対応できる状態になりました。いずれにせよマネージド操作だけで完結します (アプリ設定は変更する必要があるかもしれませんが)
フェイルオーバー検証
以下の流れで、簡単なテストを試みます。
- 東京側のパブリックサブネットのネットワーク ACL でインバウンド HTTP/HTTPS 通信を拒否
- curl を定期的に実行して RTO を計測
- DB は今回やりません
パブリックな NLB の DNS 名に対してヘルスチェックしており、かつ今回は NLB にセキュリティグループを設定していないので、ネットワーク ACL でパブリックサブネットへの HTTP/HTTPS 通信を遮断します。
なお、EC2 起動時の UserData で東京か大阪かわかるようにしています。
#!/bin/bash sudo yum update -y sudo yum install -y httpd sudo systemctl start httpd sudo systemctl enable httpd sudo touch /var/www/html/index.html echo "Hello from tokyo!" | sudo tee -a /var/www/html/index.html # <= ここが違う
以下のようなヘルパースクリプトで計測してみましょう。遮断する前に起動しておきます。
#!/usr/bin/env bash
while true; do
response=$(curl -s --max-time 3 -o /dev/null -w "%{http_code}" "$1")
if [ "$response" -eq 200 ] || [ "$response" -eq 301 ]; then
echo "Request succeeded at $(date)"
else
echo "Request failed with HTTP code $response at $(date)"
fi
sleep 1
done
こんな感じになりました。誤算はネットワーク ACL で遮断したため 504 どころかステータスコードが取れていない点です。
$ sh scripts/helper/request.sh https://your-domain.com # (省略) Request succeeded at Wed Jan 31 17:49:13 JST 2024 Request succeeded at Wed Jan 31 17:49:14 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:18 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:22 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:26 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:30 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:34 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:38 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:42 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:47 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:51 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:55 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:49:59 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:03 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:07 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:11 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:15 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:19 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:23 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:27 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:31 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:35 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:39 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:43 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:47 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:51 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:55 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:50:59 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:51:03 JST 2024 Request failed with HTTP code 000 at Wed Jan 31 17:51:07 JST 2024 Request succeeded at Wed Jan 31 17:51:08 JST 2024 Request succeeded at Wed Jan 31 17:51:10 JST 2024
fail してから再び succeeded になるまで 110 秒でした。 DNS ヘルスチェックを自前で設定した場合は変わるかもしれませんね。これに DB のフェイルオーバー時間を加えた時間がざっくりとした RTO の目安になりそうです。
おわりに
静的 IP を持つマルチリージョン DR 構成において、NLB を使ったパターンを注意点を踏まえながら紹介しました。次回は Global Accelerator を使ったパターンを紹介します。

