はじめに
ログ基盤について、前回は様々なアクセスログを JSON 形式へ変換して中間データ用のバケットに集約するところまでをやってみました。
今回はその続きとして、AWS Glue の ETL ジョブで必要な加工をした上で Parquet 形式に変換し、Athena で閲覧するところまでやってみたいと思います。
概要
下の図の Intermediate bucket のところまでが前回のスコープなので、そこから先をやってみます。CDK で環境を作ったあとは、ほとんど Glue ETL ジョブの話になります。
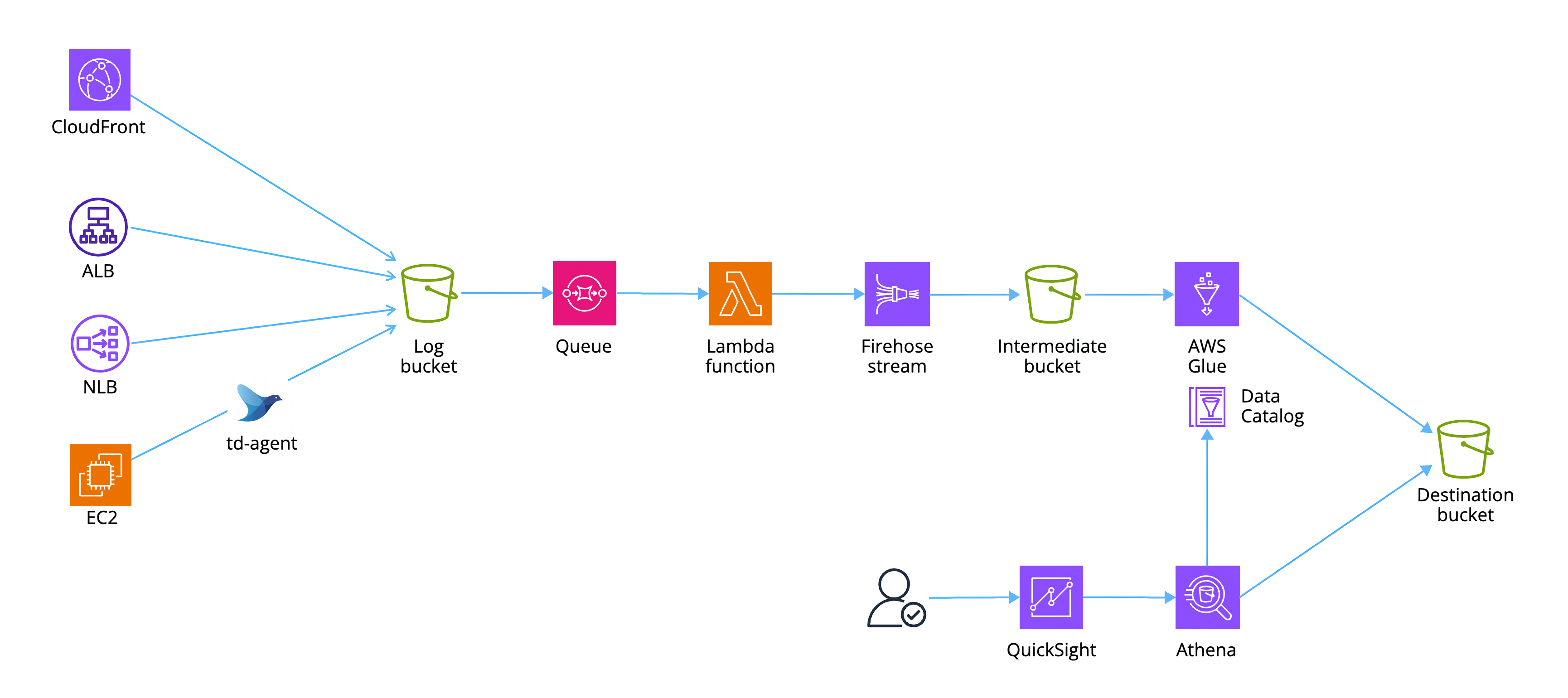
CloudFront, ALB, NLB, EC2 (Apache common log format)の各アクセスログをそれぞれ Glue ジョブで処理し、NLB 以外に関しては Web アクセスの統合テーブルも構築してみます。
CDK コード
各 ETL ジョブは以下のローカルパスにファイルとして配置されているとします。
src/ ├── glue │ ├── alb.py │ ├── cf.py │ ├── clf.py │ ├── nlb.py : └── web.py
この前提で、CDK で Glue の環境を構築します。前回の CDK コードの lib/constructs 配下に glue.ts を追加します。
import * as cdk from "aws-cdk-lib";
import * as glue from "@aws-cdk/aws-glue-alpha";
import { Construct } from "constructs";
export interface GlueProps {
serviceName: string;
bucket: cdk.aws_s3.Bucket;
}
export class Glue extends Construct {
constructor(scope: Construct, id: string, props: GlueProps) {
super(scope, id);
const dstBucket = new cdk.aws_s3.Bucket(this, "DestinationBucket", {
bucketName: `${props.serviceName}-destination`,
blockPublicAccess: cdk.aws_s3.BlockPublicAccess.BLOCK_ALL,
publicReadAccess: false,
encryption: cdk.aws_s3.BucketEncryption.S3_MANAGED,
enforceSSL: true,
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
versioned: false,
objectOwnership: cdk.aws_s3.ObjectOwnership.BUCKET_OWNER_PREFERRED,
});
const jobRole = new cdk.aws_iam.Role(this, "JobRole", {
roleName: `${props.serviceName}-glue-job-role`,
assumedBy: new cdk.aws_iam.ServicePrincipal("glue.amazonaws.com"),
managedPolicies: [cdk.aws_iam.ManagedPolicy.fromAwsManagedPolicyName("service-role/AWSGlueServiceRole")],
});
const logGroup = new cdk.aws_logs.LogGroup(this, "LogGroup", {
logGroupName: `/aws-glue/${props.serviceName}-glue-job`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
retention: cdk.aws_logs.RetentionDays.THREE_DAYS,
});
const database = new glue.Database(this, "Database", {
databaseName: `${props.serviceName}-glue-database`,
});
const cfJob = new glue.Job(this, "CFJob", {
jobName: `${props.serviceName}-glue-job-cf`,
role: jobRole,
workerType: glue.WorkerType.G_1X,
workerCount: 4,
executable: glue.JobExecutable.pythonEtl({
glueVersion: glue.GlueVersion.V4_0,
pythonVersion: glue.PythonVersion.THREE,
script: glue.Code.fromAsset(`src/glue/cf.py`),
}),
defaultArguments: {
"--enable-glue-datacatalog": "true",
"--enable-metrics": "true",
"--enable-observability-metrics": "true",
"--job-bookmark-option": "job-bookmark-enable",
"--SRC_BUCKET_PATH": `s3://${props.bucket.bucketName}/cf/`,
"--DST_BUCKET_PATH": `s3://${dstBucket.bucketName}/cf/`,
"--GLUE_DATABASE_NAME": database.databaseName,
"--GLUE_TABLE_NAME": `${props.serviceName}-glue-table-cf`,
},
continuousLogging: {
enabled: true,
logGroup: logGroup,
logStreamPrefix: "cf",
},
});
props.bucket.grantRead(cfJob);
dstBucket.grantWrite(cfJob);
const albJob = new glue.Job(this, "ALBJob", {
jobName: `${props.serviceName}-glue-job-alb`,
role: jobRole,
workerType: glue.WorkerType.G_1X,
workerCount: 4,
executable: glue.JobExecutable.pythonEtl({
glueVersion: glue.GlueVersion.V4_0,
pythonVersion: glue.PythonVersion.THREE,
script: glue.Code.fromAsset(`src/glue/alb.py`),
}),
defaultArguments: {
"--enable-glue-datacatalog": "true",
"--enable-metrics": "true",
"--enable-observability-metrics": "true",
"--job-bookmark-option": "job-bookmark-enable",
"--SRC_BUCKET_PATH": `s3://${props.bucket.bucketName}/alb/`,
"--DST_BUCKET_PATH": `s3://${dstBucket.bucketName}/alb/`,
"--GLUE_DATABASE_NAME": database.databaseName,
"--GLUE_TABLE_NAME": `${props.serviceName}-glue-table-alb`,
},
continuousLogging: {
enabled: true,
logGroup: logGroup,
logStreamPrefix: "alb",
},
});
props.bucket.grantRead(albJob);
dstBucket.grantWrite(albJob);
const nlbJob = new glue.Job(this, "NLBJob", {
jobName: `${props.serviceName}-glue-job-nlb`,
role: jobRole,
workerType: glue.WorkerType.G_1X,
workerCount: 4,
executable: glue.JobExecutable.pythonEtl({
glueVersion: glue.GlueVersion.V4_0,
pythonVersion: glue.PythonVersion.THREE,
script: glue.Code.fromAsset(`src/glue/nlb.py`),
}),
defaultArguments: {
"--enable-glue-datacatalog": "true",
"--enable-metrics": "true",
"--enable-observability-metrics": "true",
"--job-bookmark-option": "job-bookmark-enable",
"--SRC_BUCKET_PATH": `s3://${props.bucket.bucketName}/nlb/`,
"--DST_BUCKET_PATH": `s3://${dstBucket.bucketName}/nlb/`,
"--GLUE_DATABASE_NAME": database.databaseName,
"--GLUE_TABLE_NAME": `${props.serviceName}-glue-table-nlb`,
},
continuousLogging: {
enabled: true,
logGroup: logGroup,
logStreamPrefix: "nlb",
},
});
props.bucket.grantRead(nlbJob);
dstBucket.grantWrite(nlbJob);
const clfJob = new glue.Job(this, "CLFJob", {
jobName: `${props.serviceName}-glue-job-clf`,
role: jobRole,
workerType: glue.WorkerType.G_1X,
workerCount: 4,
executable: glue.JobExecutable.pythonEtl({
glueVersion: glue.GlueVersion.V4_0,
pythonVersion: glue.PythonVersion.THREE,
script: glue.Code.fromAsset(`src/glue/clf.py`),
}),
defaultArguments: {
"--enable-glue-datacatalog": "true",
"--enable-metrics": "true",
"--enable-observability-metrics": "true",
"--job-bookmark-option": "job-bookmark-enable",
"--SRC_BUCKET_PATH": `s3://${props.bucket.bucketName}/clf/`,
"--DST_BUCKET_PATH": `s3://${dstBucket.bucketName}/clf/`,
"--GLUE_DATABASE_NAME": database.databaseName,
"--GLUE_TABLE_NAME": `${props.serviceName}-glue-table-clf`,
},
continuousLogging: {
enabled: true,
logGroup: logGroup,
logStreamPrefix: "clf",
},
});
props.bucket.grantRead(clfJob);
dstBucket.grantWrite(clfJob);
const webJob = new glue.Job(this, "WebJob", {
jobName: `${props.serviceName}-glue-job-web`,
role: jobRole,
workerType: glue.WorkerType.G_1X,
workerCount: 4,
executable: glue.JobExecutable.pythonEtl({
glueVersion: glue.GlueVersion.V4_0,
pythonVersion: glue.PythonVersion.THREE,
script: glue.Code.fromAsset(`src/glue/web.py`),
}),
defaultArguments: {
"--enable-glue-datacatalog": "true",
"--enable-metrics": "true",
"--enable-observability-metrics": "true",
"--job-bookmark-option": "job-bookmark-enable",
"--DST_BUCKET_PATH": `s3://${dstBucket.bucketName}/web/`,
"--GLUE_DATABASE_NAME": database.databaseName,
"--GLUE_TABLE_BASE_NAME": `${props.serviceName}-glue-table`,
},
continuousLogging: {
enabled: true,
logGroup: logGroup,
logStreamPrefix: "web",
},
});
dstBucket.grantReadWrite(webJob);
}
}
以下を作成しています。各ジョブには入出力の各バケットに対して grantRead/Write で権限を与える必要があります。
- 行き先用 S3 バケット
- ジョブ共通の IAM ロール
- CloudWatch Logs ロググループ
- Glue データベース
- CloudFront 用 ETL ジョブ (cfJob)
- ALB 用 ETL ジョブ (albJob)
- NLB 用 ETL ジョブ (nlbJob)
- EC2 (Apache common log format) 用 ETL ジョブ (clfJob)
- 統合テーブル用 ETL ジョブ (webJob)
今回 Glue テーブルは各ジョブが作成するため、CDK で定義する必要はありません。
stack.ts に以下コードを挿入し、スタックの最後に Glue 関連のリソースが構築されるように修正します。その後 cdk synth/deploy を実行してスタックを更新します。
new Glue(this, "Glue", {
serviceName: props.serviceName,
bucket: stream.bucket,
});
Glue ETL ジョブ
ジョブを実行する対象データは前回までで JSON 形式に変換され、resource_type, resource_name といったリソース識別用のフィールドが追加された状態です。各アクセスログ用のジョブでは概ね次のような処理を実行します。
- 日時フィールドを元に
timestamp型のフィールドtimestampを追加 - パーティション用に
date型のフィールドpartition_dateを追加 - 各フィールドに対して、アクセスログでよくあるプレースホルダ
"-"を null に変換 - 各フィールドのデータ型を変換
- Parquet 形式に変換
- Snappy 形式で圧縮
- 行き先用 S3 バケットに配置
CloudFront
まず CloudFront のアクセスログです。以下のようなスクリプトにしました。
import sys
from awsglue.transforms import *
from awsglue.dynamicframe import DynamicFrame
from awsglue.utils import getResolvedOptions
from awsglue.job import Job
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.sql.functions import concat, col, lit, to_timestamp, when
args = getResolvedOptions(
sys.argv,
[
"JOB_NAME",
"SRC_BUCKET_PATH",
"DST_BUCKET_PATH",
"GLUE_DATABASE_NAME",
"GLUE_TABLE_NAME",
],
)
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
df = glueContext.create_dynamic_frame.from_options(
format_options={"multiline": False},
connection_type="s3",
format="json",
connection_options={"paths": [args["SRC_BUCKET_PATH"]], "recurse": True},
transformation_ctx="datasource0",
).toDF()
if df.count() > 0:
df = df.select(
[when(col(c) == "-", None).otherwise(col(c)).alias(c) for c in df.columns]
)
df = df.withColumn(
"timestamp",
to_timestamp(concat(col("date"), lit(" "), col("time")), "yyyy-MM-dd HH:mm:ss"),
)
df = df.withColumn("partition_date", col("timestamp").cast("date"))
dyf = DynamicFrame.fromDF(df, glueContext, "dyf")
dyf = ApplyMapping.apply(
frame=dyf,
mappings=[
("resource_type", "string", "resource_type", "string"),
("resource_name", "string", "resource_name", "string"),
("date", "string", "date", "string"),
("time", "string", "time", "string"),
("x_edge_location", "string", "x_edge_location", "string"),
("sc_bytes", "string", "sc_bytes", "int"),
("c_ip", "string", "c_ip", "string"),
("cs_method", "string", "cs_method", "string"),
("cs_host", "string", "cs_host", "string"),
("cs_uri_stem", "string", "cs_uri_stem", "string"),
("sc_status", "string", "sc_status", "string"),
("cs_referer", "string", "cs_referer", "string"),
("cs_user_agent", "string", "cs_user_agent", "string"),
("cs_uri_query", "string", "cs_uri_query", "string"),
("cs_cookie", "string", "cs_cookie", "string"),
("x_edge_result_type", "string", "x_edge_result_type", "string"),
("x_edge_request_id", "string", "x_edge_request_id", "string"),
("x_host_header", "string", "x_host_header", "string"),
("cs_protocol", "string", "cs_protocol", "string"),
("cs_bytes", "string", "cs_bytes", "int"),
("time_taken", "string", "time_taken", "float"),
("x_forwarded_for", "string", "x_forwarded_for", "string"),
("ssl_protocol", "string", "ssl_protocol", "string"),
("ssl_cipher", "string", "ssl_cipher", "string"),
(
"x_edge_response_result_type",
"string",
"x_edge_response_result_type",
"string",
),
("cs_protocol_version", "string", "cs_protocol_version", "string"),
("fle_status", "string", "fle_status", "string"),
("fle_encrypted_fields", "string", "fle_encrypted_fields", "string"),
("c_port", "string", "c_port", "int"),
("time_to_first_byte", "string", "time_to_first_byte", "float"),
(
"x_edge_detailed_result_type",
"string",
"x_edge_detailed_result_type",
"string",
),
("sc_content_type", "string", "sc_content_type", "string"),
("sc_content_len", "string", "sc_content_len", "int"),
("sc_range_start", "string", "sc_range_start", "string"),
("sc_range_end", "string", "sc_range_end", "string"),
("timestamp", "timestamp", "timestamp", "timestamp"),
("partition_date", "date", "partition_date", "date"),
],
transformation_ctx="applymapping1",
)
sink = glueContext.getSink(
path=args["DST_BUCKET_PATH"],
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=["partition_date"],
enableUpdateCatalog=True,
transformation_ctx="datasink2",
)
sink.setCatalogInfo(
catalogDatabase=args["GLUE_DATABASE_NAME"],
catalogTableName=args["GLUE_TABLE_NAME"],
)
sink.setFormat("glueparquet", compression="snappy")
sink.writeFrame(dyf)
job.commit()
流れを説明します。バケットパス、Glue のデータベース名、テーブル名をパラメータで外部から渡すようにしており、これらは getResolvedOptions() を使って取得できます (JOB_NAME はデフォルトのサンプルスクリプトの時点で設定されています)
args = getResolvedOptions(
sys.argv,
[
"JOB_NAME",
"SRC_BUCKET_PATH",
"DST_BUCKET_PATH",
"GLUE_DATABASE_NAME",
"GLUE_TABLE_NAME",
],
)
S3 バケットを指定して Glue の DynamicFrame を作り、加工しやすいように一度 toDF() で DataFrame に変換します。
df = glueContext.create_dynamic_frame.from_options(
format_options={"multiline": False},
connection_type="s3",
format="json",
connection_options={"paths": [args["SRC_BUCKET_PATH"]], "recurse": True},
transformation_ctx="datasource0",
).toDF()
ゼロ件で処理するとエラーになるため、対象がある場合にのみ処理するようにします。件数が多く count() のオーバーヘッドが気になる場合は、例えば先頭 N 件を取ってから確認するなどパフォーマンスを気にしてみてもいいと思います。
if df.count() > 0:
# 処理
以下ではリスト内包表記を使って、全フィールドを走査してプレースホルダ "-" を null に変換しています。
df = df.select(
[when(col(c) == "-", None).otherwise(col(c)).alias(c) for c in df.columns]
)
以下では date フィールドと time フィールドを結合して時刻文字列を作り、PySpark 組み込みの to_timestamp で timestamp 型にキャストし、timestamp という名前で新しいフィールドを追加しています。
df = df.withColumn(
"timestamp",
to_timestamp(concat(col("date"), lit(" "), col("time")), "yyyy-MM-dd HH:mm:ss"),
)
以下では timestamp を date 型にキャストし、partition_date というパーティション用のフィールドを追加しています。
df = df.withColumn("partition_date", col("timestamp").cast("date"))
ここまでで必要な加工が終わったので、DynamicFrame に戻します。
dyf = DynamicFrame.fromDF(df, glueContext, "dyf")
元データが JSON 形式で、テーブルのスキーマ判定の際に各フィールドが文字列型として判断されてしまうため、各フィールドにあった型に明示的に変換します。
dyf = ApplyMapping.apply(
frame=dyf,
mappings=[
...
("sc_bytes", "string", "sc_bytes", "int"),
...
("cs_bytes", "string", "cs_bytes", "int"),
("time_taken", "string", "time_taken", "float"),
...
("c_port", "string", "c_port", "int"),
...
("sc_content_len", "string", "sc_content_len", "int"),
...
("timestamp", "timestamp", "timestamp", "timestamp"),
("partition_date", "date", "partition_date", "date"),
],
transformation_ctx="applymapping1",
)
変換したデータを S3 バケットに書き込みます。列志向でデータ分析向けのフォーマットである Parquet 形式に変換し、Snappy 形式で圧縮する設定にしています。
sink = glueContext.getSink(
path=args["DST_BUCKET_PATH"],
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=["partition_date"],
enableUpdateCatalog=True,
transformation_ctx="datasink2",
)
sink.setCatalogInfo(
catalogDatabase=args["GLUE_DATABASE_NAME"],
catalogTableName=args["GLUE_TABLE_NAME"],
)
sink.setFormat("glueparquet", compression="snappy")
sink.writeFrame(dyf)
Job オブジェクトをコミットして処理を終了します。
job.commit()
ALB
ALB は以下のようなスクリプトです。CloudFront と異なる部分だけ説明します。
import sys
from awsglue.transforms import *
from awsglue.dynamicframe import DynamicFrame
from awsglue.utils import getResolvedOptions
from awsglue.job import Job
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.sql.functions import col, when, to_timestamp
args = getResolvedOptions(
sys.argv,
[
"JOB_NAME",
"SRC_BUCKET_PATH",
"DST_BUCKET_PATH",
"GLUE_DATABASE_NAME",
"GLUE_TABLE_NAME",
],
)
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
df = glueContext.create_dynamic_frame.from_options(
format_options={"multiline": False},
connection_type="s3",
format="json",
connection_options={"paths": [args["SRC_BUCKET_PATH"]], "recurse": True},
transformation_ctx="datasource0",
).toDF()
if df.count() > 0:
df = df.select(
[when(col(c) == "-", None).otherwise(col(c)).alias(c) for c in df.columns]
)
df = df.withColumn(
"request_processing_time",
when(col("request_processing_time") == -1, None).otherwise(
col("request_processing_time")
),
)
df = df.withColumn(
"target_processing_time",
when(col("target_processing_time") == -1, None).otherwise(
col("target_processing_time")
),
)
df = df.withColumn(
"response_processing_time",
when(col("response_processing_time") == -1, None).otherwise(
col("response_processing_time")
),
)
df = df.withColumn(
"timestamp", to_timestamp(col("time"), "yyyy-MM-dd'T'HH:mm:ss.SSSSSS'Z'")
)
df = df.withColumn("partition_date", col("timestamp").cast("date"))
dyf = DynamicFrame.fromDF(df, glueContext, "dyf")
dyf = ApplyMapping.apply(
frame=dyf,
mappings=[
("resource_type", "string", "resource_type", "string"),
("resource_name", "string", "resource_name", "string"),
("type", "string", "type", "string"),
("time", "string", "time", "string"),
("elb", "string", "elb", "string"),
("client_port", "string", "client_port", "string"),
("target_port", "string", "target_port", "string"),
("request_processing_time", "string", "request_processing_time", "float"),
("target_processing_time", "string", "target_processing_time", "float"),
("response_processing_time", "string", "response_processing_time", "float"),
("elb_status_code", "string", "elb_status_code", "int"),
("target_status_code", "string", "target_status_code", "int"),
("received_bytes", "string", "received_bytes", "int"),
("sent_bytes", "string", "sent_bytes", "int"),
("method", "string", "method", "string"),
("request_uri", "string", "request_uri", "string"),
("protocol", "string", "protocol", "string"),
("user_agent", "string", "user_agent", "string"),
("ssl_cipher", "string", "ssl_cipher", "string"),
("ssl_protocol", "string", "ssl_protocol", "string"),
("target_group_arn", "string", "target_group_arn", "string"),
("trace_id", "string", "trace_id", "string"),
("domain_name", "string", "domain_name", "string"),
("chosen_cert_arn", "string", "chosen_cert_arn", "string"),
("matched_rule_priority", "string", "matched_rule_priority", "string"),
("request_creation_time", "string", "request_creation_time", "timestamp"),
("actions_executed", "string", "actions_executed", "string"),
("redirect_url", "string", "redirect_url", "string"),
("error_reason", "string", "error_reason", "string"),
("target_port_list", "string", "target_port_list", "string"),
("target_status_code_list", "string", "target_status_code_list", "string"),
("classification", "string", "classification", "string"),
("classification_reason", "string", "classification_reason", "string"),
("timestamp", "timestamp", "timestamp", "timestamp"),
("partition_date", "date", "partition_date", "date"),
],
transformation_ctx="applymapping1",
)
sink = glueContext.getSink(
path=args["DST_BUCKET_PATH"],
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=["partition_date"],
enableUpdateCatalog=True,
transformation_ctx="datasink2",
)
sink.setCatalogInfo(
catalogDatabase=args["GLUE_DATABASE_NAME"],
catalogTableName=args["GLUE_TABLE_NAME"],
)
sink.setFormat("glueparquet", compression="snappy")
sink.writeFrame(dyf)
job.commit()
float 型に変換したい次のフィールドは無効な場合 -1 が設定され、かつ 0 のケースもあって煩雑なので -1 を null に変換します。
df = df.withColumn(
"request_processing_time",
when(col("request_processing_time") == -1, None).otherwise(
col("request_processing_time")
),
)
df = df.withColumn(
"target_processing_time",
when(col("target_processing_time") == -1, None).otherwise(
col("target_processing_time")
),
)
df = df.withColumn(
"response_processing_time",
when(col("response_processing_time") == -1, None).otherwise(
col("response_processing_time")
),
)
日付フィールド time を元に timestamp を作ります。
df = df.withColumn(
"timestamp", to_timestamp(col("time"), "yyyy-MM-dd'T'HH:mm:ss.SSSSSS'Z'")
)
NLB
NLB の場合は以下のようなスクリプトです。
import sys
from awsglue.transforms import *
from awsglue.dynamicframe import DynamicFrame
from awsglue.utils import getResolvedOptions
from awsglue.job import Job
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.sql.functions import col, when, to_timestamp
args = getResolvedOptions(
sys.argv,
[
"JOB_NAME",
"SRC_BUCKET_PATH",
"DST_BUCKET_PATH",
"GLUE_DATABASE_NAME",
"GLUE_TABLE_NAME",
],
)
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
df = glueContext.create_dynamic_frame.from_options(
format_options={"multiline": False},
connection_type="s3",
format="json",
connection_options={
"paths": [args["SRC_BUCKET_PATH"]],
"recurse": True,
},
transformation_ctx="datasource0",
).toDF()
if df.count() > 0:
df = df.select(
[when(col(c) == "-", None).otherwise(col(c)).alias(c) for c in df.columns]
)
df = df.withColumn("timestamp", to_timestamp(col("time"), "yyyy-MM-dd'T'HH:mm:ss"))
df = df.withColumn("partition_date", col("timestamp").cast("date"))
dyf = DynamicFrame.fromDF(df, glueContext, "dyf")
dyf = ApplyMapping.apply(
frame=dyf,
mappings=[
("resource_type", "string", "resource_type", "string"),
("resource_name", "string", "resource_name", "string"),
("type", "string", "type", "string"),
("version", "string", "version", "string"),
("time", "string", "time", "string"),
("elb", "string", "elb", "string"),
("listener", "string", "listener", "string"),
("client_port", "string", "client_port", "string"),
("destination_port", "string", "destination_port", "string"),
("connection_time", "string", "connection_time", "int"),
("tls_handshake_time", "string", "tls_handshake_time", "int"),
("received_bytes", "string", "received_bytes", "int"),
("sent_bytes", "string", "sent_bytes", "int"),
("incoming_tls_alert", "string", "incoming_tls_alert", "int"),
("chosen_cert_arn", "string", "chosen_cert_arn", "string"),
("chosen_cert_serial", "string", "chosen_cert_serial", "string"),
("tls_cipher", "string", "tls_cipher", "string"),
("tls_protocol_version", "string", "tls_protocol_version", "string"),
("tls_named_group", "string", "tls_named_group", "string"),
("domain_name", "string", "domain_name", "string"),
("alpn_fe_protocol", "string", "alpn_fe_protocol", "string"),
("alpn_be_protocol", "string", "alpn_be_protocol", "string"),
(
"alpn_client_preference_list",
"string",
"alpn_client_preference_list",
"string",
),
(
"tls_connection_creation_time",
"string",
"tls_connection_creation_time",
"timestamp",
),
("timestamp", "timestamp", "timestamp", "timestamp"),
("partition_date", "date", "partition_date", "date"),
],
transformation_ctx="applymapping1",
)
sink = glueContext.getSink(
path=args["DST_BUCKET_PATH"],
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=["partition_date"],
enableUpdateCatalog=True,
transformation_ctx="datasink2",
)
sink.setCatalogInfo(
catalogDatabase=args["GLUE_DATABASE_NAME"],
catalogTableName=args["GLUE_TABLE_NAME"],
)
sink.setFormat("glueparquet", compression="snappy")
sink.writeFrame(dyf)
job.commit()
EC2 (Apache common log format)
Apache common log format のログの変換です。httpd のロギング設定はデフォルトのままです。
import sys
from awsglue.transforms import *
from awsglue.dynamicframe import DynamicFrame
from awsglue.utils import getResolvedOptions
from awsglue.job import Job
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.sql.functions import col, when, to_timestamp, substring
args = getResolvedOptions(
sys.argv,
[
"JOB_NAME",
"SRC_BUCKET_PATH",
"DST_BUCKET_PATH",
"GLUE_DATABASE_NAME",
"GLUE_TABLE_NAME",
],
)
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
df = glueContext.create_dynamic_frame.from_options(
format_options={"multiline": False},
connection_type="s3",
format="json",
connection_options={"paths": [args["SRC_BUCKET_PATH"]], "recurse": True},
transformation_ctx="datasource0",
).toDF()
if df.count() > 0:
df = df.select(
[when(col(c) == "-", None).otherwise(col(c)).alias(c) for c in df.columns]
)
df = df.withColumn(
"timestamp",
to_timestamp(
substring(col("datetime"), 2, 20),
"dd/MMM/yyyy:HH:mm:ss",
),
)
df = df.withColumn("partition_date", col("timestamp").cast("date"))
dyf = DynamicFrame.fromDF(df, glueContext, "dyf")
dyf = ApplyMapping.apply(
frame=dyf,
mappings=[
("resource_type", "string", "resource_type", "string"),
("resource_name", "string", "resource_name", "string"),
("remote_host", "string", "remote_host", "string"),
("remote_logname", "string", "remote_logname", "string"),
("remote_user", "string", "remote_user", "string"),
("datetime", "string", "datetime", "string"),
("method", "string", "method", "string"),
("request_uri", "string", "request_uri", "string"),
("protocol", "string", "protocol", "string"),
("status", "string", "status", "int"),
("size", "string", "size", "int"),
("referer", "string", "referer", "string"),
("user_agent", "string", "user_agent", "string"),
("timestamp", "timestamp", "timestamp", "timestamp"),
("partition_date", "date", "partition_date", "date"),
],
transformation_ctx="applymapping1",
)
sink = glueContext.getSink(
path=args["DST_BUCKET_PATH"],
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=["partition_date"],
enableUpdateCatalog=True,
transformation_ctx="datasink2",
)
sink.setCatalogInfo(
catalogDatabase=args["GLUE_DATABASE_NAME"],
catalogTableName=args["GLUE_TABLE_NAME"],
)
sink.setFormat("glueparquet", compression="snappy")
sink.writeFrame(dyf)
job.commit()
datetime フィールドが [08/May/2024:05:58:14 +0000] のような文字列なので、substring で時刻として有効な範囲を取り出してから to_timestamp で変換します。
df = df.withColumn(
"timestamp",
to_timestamp(
substring(col(datetime), 2, 20),
"dd/MMM/yyyy:HH:mm:ss",
),
)
統合テーブル
Web アクセスについては簡易的な統合テーブルも作ってみたいと思います。NLB 以外の Glue テーブルを対象とするので、先に各テーブルが作成されている必要があります。フィールドは以下のように定義しました。
| フィールド名 | 型 |
|---|---|
| resource_type | string |
| resource_name | string |
| client_ip | string |
| client_port | string |
| method | string |
| host | string |
| request_uri | string |
| protocol | string |
| status | int |
| timestamp | timestamp |
| partition_date | date |
以下のような流れで処理します。
- CloudFront, ALB, EC2 (Apache common log format) の各 Glue テーブルからデータを読み込む
- 各テーブルのデータを前述のスキーマ定義に合致するように加工する
- スキーマの均一化されたデータを結合する
- データ型を合わせる
- S3 にデータを書き込む
以下のような内容にしました。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.types import StringType
from pyspark.sql.functions import lit, col, date_format, split, expr
args = getResolvedOptions(
sys.argv,
[
"JOB_NAME",
"DST_BUCKET_PATH",
"GLUE_DATABASE_NAME",
"GLUE_TABLE_BASE_NAME",
],
)
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
cf = glueContext.create_dynamic_frame.from_catalog(
database=args["GLUE_DATABASE_NAME"],
table_name=args["GLUE_TABLE_BASE_NAME"] + "-cf",
transformation_ctx="datasource0_cf",
).toDF()
alb = glueContext.create_dynamic_frame.from_catalog(
database=args["GLUE_DATABASE_NAME"],
table_name=args["GLUE_TABLE_BASE_NAME"] + "-alb",
transformation_ctx="datasource1_alb",
).toDF()
clf = glueContext.create_dynamic_frame.from_catalog(
database=args["GLUE_DATABASE_NAME"],
table_name=args["GLUE_TABLE_BASE_NAME"] + "-clf",
transformation_ctx="datasource2_clf",
).toDF()
if cf.count() > 0 and alb.count() > 0 and clf.count() > 0:
cf = cf.select(
"resource_type",
"resource_name",
col("c_ip").alias("client_ip"),
col("c_port").alias("client_port"),
col("cs_method").alias("method"),
col("x_host_header").alias("host"),
col("cs_uri_stem").alias("request_uri"),
col("cs_protocol_version").alias("protocol"),
col("sc_status").alias("status"),
"timestamp",
"partition_date",
)
alb = (
alb.withColumn("client_ip", split(col("client_port"), ":").getItem(0))
.withColumn("client_port", split(col("client_port"), ":").getItem(1))
.withColumn(
"timestamp",
date_format(col("timestamp"), "yyyy-MM-dd HH:mm:ss"),
)
.withColumn("host", expr("parse_url(request_uri, 'HOST')"))
.withColumn("request_uri", expr("parse_url(request_uri, 'PATH')"))
.select(
"resource_type",
"resource_name",
"client_ip",
"client_port",
"method",
"host",
"request_uri",
"protocol",
col("elb_status_code").alias("status"),
"timestamp",
"partition_date",
)
)
clf = (
clf.withColumn("client_port", lit(None).cast(StringType()))
.withColumn("host", lit(None).cast(StringType()))
.select(
"resource_type",
"resource_name",
col("remote_host").alias("client_ip"),
"client_port",
"method",
"host",
"request_uri",
"protocol",
"status",
"timestamp",
"partition_date",
)
)
df = cf.union(alb)
df = df.union(clf)
dyf = DynamicFrame.fromDF(df, glueContext, "dyf")
dyf = ApplyMapping.apply(
frame=dyf,
mappings=[
("resource_type", "string", "resource_type", "string"),
("resource_name", "string", "resource_name", "string"),
("client_ip", "string", "client_ip", "string"),
("client_port", "string", "client_port", "string"),
("method", "string", "method", "string"),
("host", "string", "host", "string"),
("request_uri", "string", "request_uri", "string"),
("protocol", "string", "protocol", "string"),
("status", "string", "status", "int"),
("timestamp", "string", "timestamp", "timestamp"),
("partition_date", "string", "partition_date", "date"),
],
transformation_ctx="applymapping3",
)
sink = glueContext.getSink(
path=args["DST_BUCKET_PATH"],
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=["partition_date"],
enableUpdateCatalog=True,
transformation_ctx="datasink4",
)
sink.setCatalogInfo(
catalogDatabase=args["GLUE_DATABASE_NAME"],
catalogTableName=args["GLUE_TABLE_BASE_NAME"] + "-web",
)
sink.setFormat("glueparquet", compression="snappy")
sink.writeFrame(dyf)
job.commit()
以下ではそれぞれの Glue テーブルから対象のデータを取得して DataFrame に変換しています。GLUE_TABLE_BASE_NAME は各テーブルの共通のプレフィックスです。
cf = glueContext.create_dynamic_frame.from_catalog(
database=args["GLUE_DATABASE_NAME"],
table_name=args["GLUE_TABLE_BASE_NAME"] + "-cf",
transformation_ctx="datasource0_cf",
).toDF()
alb = glueContext.create_dynamic_frame.from_catalog(
database=args["GLUE_DATABASE_NAME"],
table_name=args["GLUE_TABLE_BASE_NAME"] + "-alb",
transformation_ctx="datasource1_alb",
).toDF()
clf = glueContext.create_dynamic_frame.from_catalog(
database=args["GLUE_DATABASE_NAME"],
table_name=args["GLUE_TABLE_BASE_NAME"] + "-clf",
transformation_ctx="datasource2_clf",
).toDF()
今回はデータがないテーブルがひとつでもあったら処理しないようにしています。
if cf.count() > 0 and alb.count() > 0 and clf.count() > 0:
# 処理
前述のスキーマに合わせてデータを変換する処理ですが、CloudFront はフィールド名の変換だけでいけました。
cf = cf.select(
"resource_type",
"resource_name",
col("c_ip").alias("client_ip"),
col("c_port").alias("client_port"),
col("cs_method").alias("method"),
col("x_host_header").alias("host"),
col("cs_uri_stem").alias("request_uri"),
col("cs_protocol_version").alias("protocol"),
col("sc_status").alias("status"),
"timestamp",
"partition_date",
)
ALB はいろいろ処理が必要でした。
client_portはhostとportが含まれるので、:で分割してclient_ipとclient_portにそれぞれマッピングしますtimestampは結合した際にマイクロ秒の有無で差分が出るので、ALB ではマイクロ秒を切り捨てますhostはrequest_uriのホスト部分から抽出します。PySpark 組み込みのexprとparse_urlを使います- 同様に
request_uriはパス部分を使います
alb = (
alb.withColumn("client_ip", split(col("client_port"), ":").getItem(0))
.withColumn("client_port", split(col("client_port"), ":").getItem(1))
.withColumn(
"timestamp",
date_format(col("timestamp"), "yyyy-MM-dd HH:mm:ss"),
)
.withColumn("host", expr("parse_url(request_uri, 'HOST')"))
.withColumn("request_uri", expr("parse_url(request_uri, 'PATH')"))
.select(
"resource_type",
"resource_name",
"client_ip",
"client_port",
"method",
"host",
"request_uri",
"protocol",
col("elb_status_code").alias("status"),
"timestamp",
"partition_date",
)
)
Apache common log format は、デフォルトだとホスト名がなかったりポート番号がなかったりします。これらには null を設定しています。
clf = (
clf.withColumn("client_port", lit(None).cast(StringType()))
.withColumn("host", lit(None).cast(StringType()))
.select(
"resource_type",
"resource_name",
col("remote_host").alias("client_ip"),
"client_port",
"method",
"host",
"request_uri",
"protocol",
"status",
"timestamp",
"partition_date",
)
)
以下で各データを結合しています。
df = cf.union(alb) df = df.union(clf)
Athena で閲覧
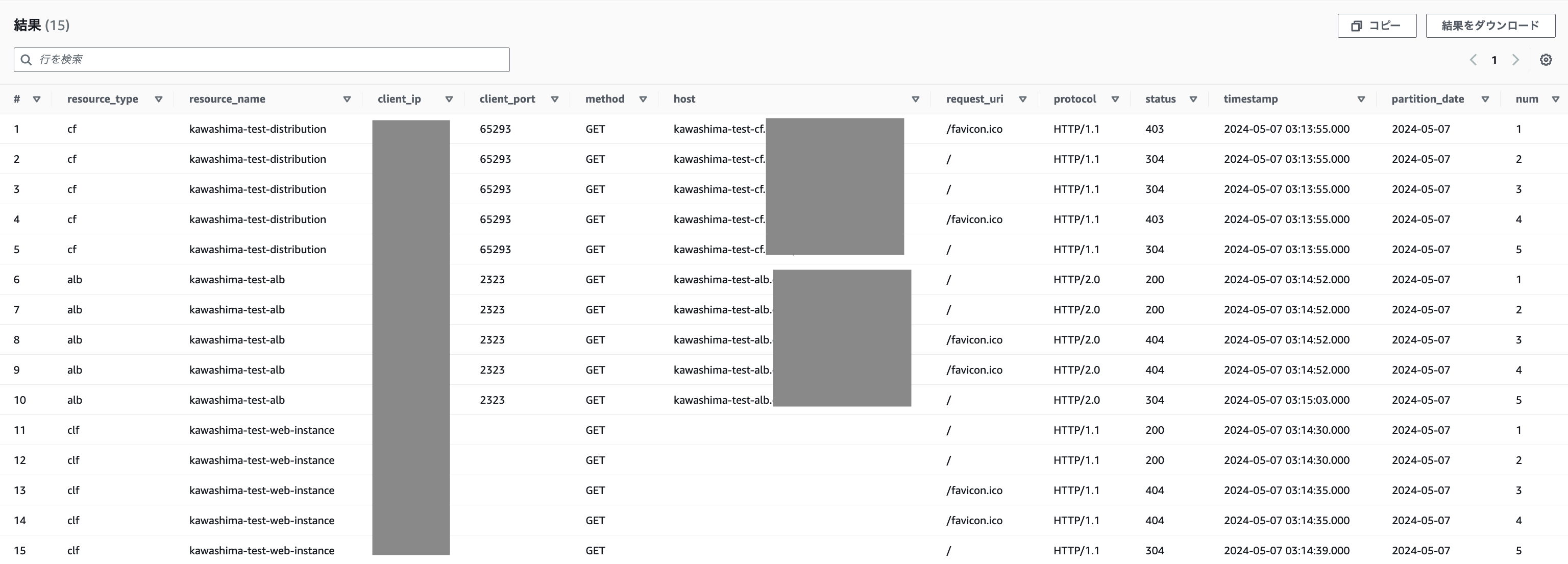
以下の SQL で、統合テーブルに対してリソースタイプごとに 5 件ずつ取得してみます。
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY resource_type ORDER BY timestamp) as num
FROM "kawashima-test-glue-database"."kawashima-test-glue-table-web"
WHERE resource_type IN ('cf', 'clf', 'alb')
)
WHERE num <= 5;
以下のように、正常に結果を取得することができました。
補足
ETL ジョブを動かす際、前回までに処理していないデータだけを処理したい場合、ブックマーク機能を有効にする必要があります。前述の CDK コードの以下の部分です。
defaultArguments: {
...
"--job-bookmark-option": "job-bookmark-enable",
...
},
これを有効にすると差分だけ処理するようになりますが、ジョブスクリプトで以下を満たしている必要があります。
job.init()でジョブを初期化しているjob.commit()でジョブを終了している- Glue 処理で引数
transformation_ctxを設定している
おわりに
コードばかりの内容になってしまいましたが、ログ基盤を構築して ETL 処理する流れを一通りやってみました。今回でシンプルなログ基盤を構築するための基本的な部分を押さえることができたと思います。
これに WAF や API Gateway などのログも統合するとなった場合、難易度はそこそこ上がると思います。機会があればさらに掘り下げてみたいと思います。


