はじめに
ログ解析についていろいろ書いてきました。並べてみると、ひとつのテーマを軸にだいぶ引っ張っています。
- AWS サービスのアクセスログを正規表現でパースする
- Go でアクセスログパーサーを自作してみた
- Go で AWS のアクセスログを解析するツールを作った
- [運用効率化] いろんなアクセスログを構造化フォーマットに変換するツールを作りました (再掲)
- 自作ログパーサーを AWS で使ったら便利だった件
- td-agent と Go 製ログパーサーを使った EC2 アクセスログ収集パターン
残すところログ基盤の構築ができればこのテーマにも終止符が打てそうです。
概要
以下のような構成を目指します。
構成
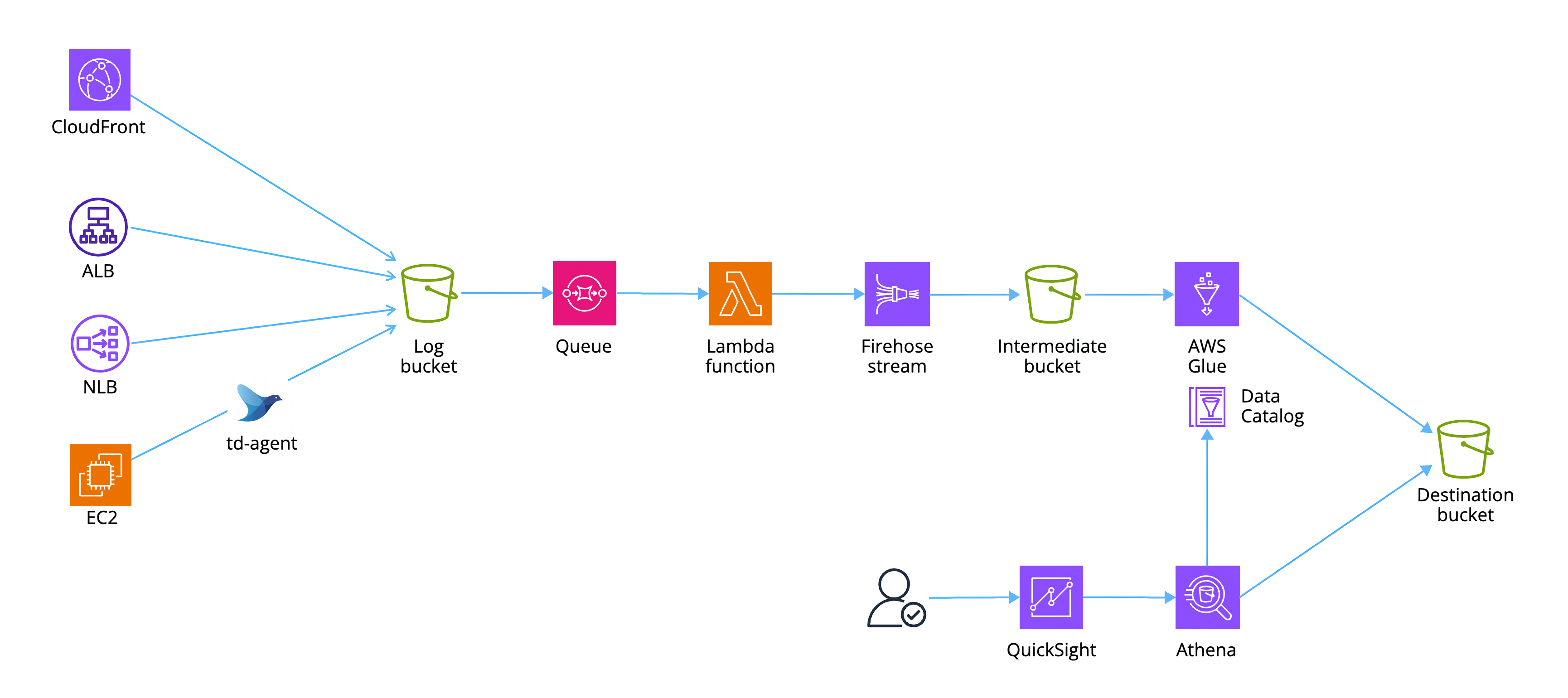
- 各アクセスログを単一のバケットに集約し、プレフィックスにリソース名を設定して管理する
- ログバケットへの PUT イベントを契機に SQS にイベントメッセージを溜める
- イベントメッセージを Lambda 関数でポーリングし、以下のように処理する
- ログ行にリソース種別、リソース名を追加
- JSON 形式へ変換
- PutRecordBatch API の制限を考慮してデータを分割しつつ Firehose に PUT
- Firehose の動的パーティショニングでリソース種別ごとにプレフィックスを切った上で中間バケットに PUT
- Glue ジョブで ETL 処理
- Athena でクエリ
- QuickSight で可視化
スコープ
本記事では構造化フォーマットに変換したログを中間バケットに集約するところまでをスコープとします。赤枠の部分です。
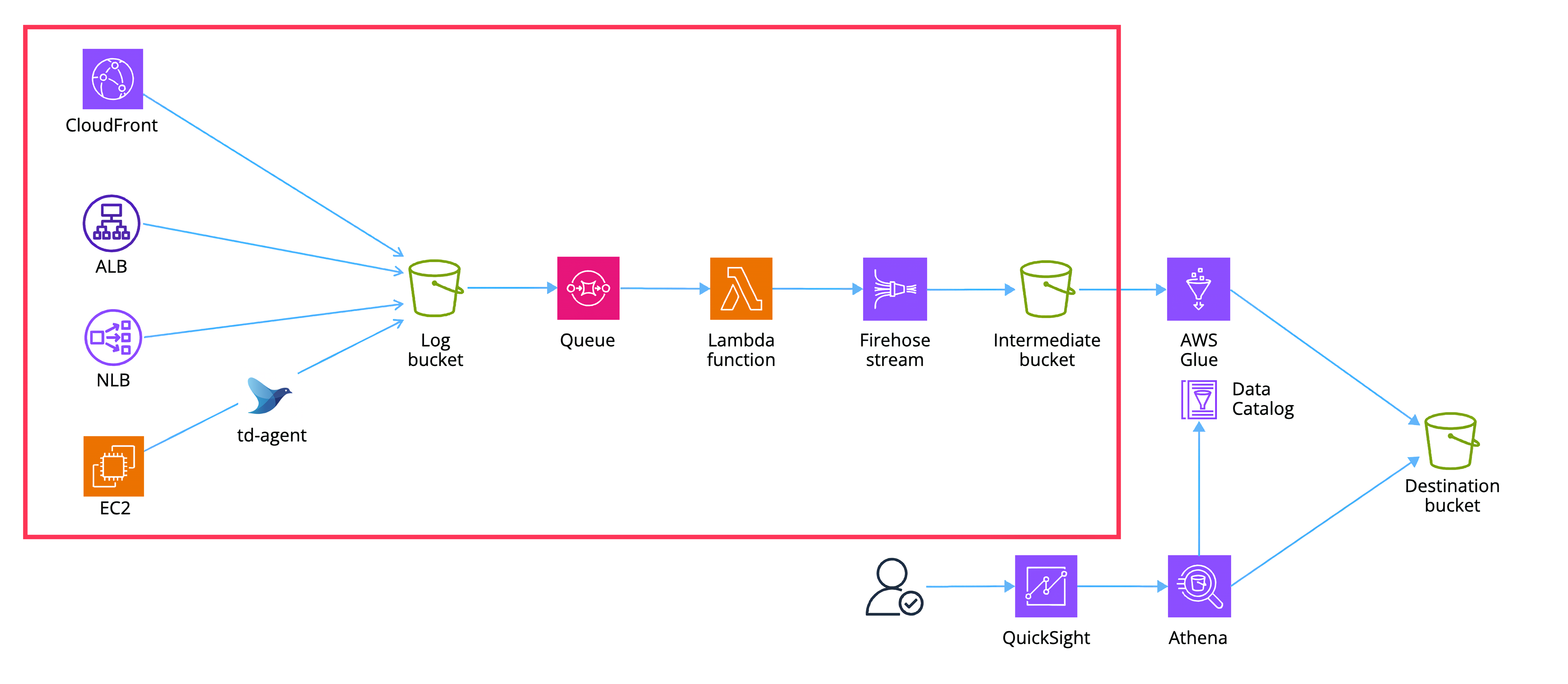
今回はこのように 3 レイヤーのデータ変換にしてみました。段階を踏むことでフローが明確になりますし、中間データが保持されることで必要に応じて様々な ETL 処理を適用できます。
| バケット | 説明 |
|---|---|
| Log bucket | 生ログを格納するバケット (今回) |
| Intermediate bucket | リソース名やリソース種別を付与し、JSON 形式に変換したログを格納するバケット (今回) |
| Destination bucket | Parquet 形式への変換や統合テーブルなど、より閲覧や分析に適した形に変換されたデータを格納するバケット (次回) |
構築
リソースの構築は CDK で行います。リポジトリはこちらです。前回までの記事と重複する点は GitHub へのリンクのみ記載します。
ログ格納用バケット
まずは生ログの置き場所となる S3 バケットを作ります。
VPC
VPC を作ります。
EC2 Instance Connect Endpoint
踏み台用の EIC エンドポイントを作ります。
ログ送信元リソース
アクセスログの送信元となるリソースを作ります。CDK のコードサンプルとしても使えるかもしれません。
EC2 インスタンスでは UserData を利用して httpd と td-agent のセットアップをしています。S3 バケットのプレフィックスには変更される可能性のあるホスト名や IP アドレスではなく論理名がほしいので、instanceName (Name タグ) を設定するようにしました。UserData として設定される時点で変数を展開したいので td-agent.conf もインラインで書いています。
const prefix = "web";
this.instanceName = `${props.serviceName}-${prefix}-instance`;
const userData = cdk.aws_ec2.UserData.forLinux({ shebang: "#!/bin/bash" });
userData.addCommands(
"# setup httpd",
"sudo yum update -y",
"sudo yum install -y httpd",
"sudo systemctl start httpd",
"sudo systemctl enable httpd",
"sudo touch /var/www/html/index.html",
'echo "Hello from httpd" | sudo tee -a /var/www/html/index.html',
"",
"# setup td-agent",
"curl -L https://toolbelt.treasuredata.com/sh/install-amazon2-td-agent3.sh | sh",
'sudo sed -i -e "s|^User=td-agent|User=root|g" /usr/lib/systemd/system/td-agent.service',
'sudo sed -i -e "s|^Group=td-agent|Group=root|g" /usr/lib/systemd/system/td-agent.service',
"sudo cp /etc/td-agent/td-agent.conf /etc/td-agent/td-agent.conf.bk",
"",
`CONFIG=$(
cat <<EOF
<source>
@type tail
path /var/log/httpd/access_log
pos_file /var/log/td-agent/access_log.pos
tag access_log
<parse>
@type none
</parse>
</source>
<match access_log>
@type s3
s3_bucket ${props.logBucket.bucketName}
s3_region ap-northeast-1
path ${this.instanceName}/
time_slice_format %Y/%m/%d/%H-%M-%S
<format>
@type single_value
</format>
<buffer>
@type file
path /var/log/td-agent/s3
timekey 5m
timekey_wait 5m
chunk_limit_size 256m
</buffer>
</match>
EOF
)`,
"",
'echo "$CONFIG" | sudo tee /etc/td-agent/td-agent.conf >/dev/null',
"sudo systemctl restart td-agent.service"
);
なお、CloudFront ディストリビューションも distributionName として論理名を決めて使っています。
this.distributionName = `${props.serviceName}-distribution`;
小ネタですが EC2 インスタンスの L2 コンストラクトは T 系インスタンスタイプの CPUCredits を直接変更できません。このため以下のようにエスケープハッチで unlimited から standard に変更しています。
const cfnInstance = instance.node.defaultChild as cdk.aws_ec2.CfnInstance;
cfnInstance.addPropertyOverride("CreditSpecification.CPUCredits", "standard");
Stream
Firehose ストリームを作ります。今回は L1 コンストラクトで動的パーティショニングを設定しています。
import * as cdk from "aws-cdk-lib";
import { Construct } from "constructs";
export interface StreamProps {
serviceName: string;
}
export class Stream extends Construct {
readonly deliveryStream: cdk.aws_kinesisfirehose.CfnDeliveryStream;
constructor(scope: Construct, id: string, props: StreamProps) {
super(scope, id);
const stack = cdk.Stack.of(this);
...
// Create firehose delivery stream
this.deliveryStream = new cdk.aws_kinesisfirehose.CfnDeliveryStream(this, "Firehose", {
deliveryStreamName: `${props.serviceName}-firehose`,
deliveryStreamType: "DirectPut",
extendedS3DestinationConfiguration: {
bucketArn: dstBucket.bucketArn,
roleArn: firehoseRole.roleArn,
cloudWatchLoggingOptions: {
enabled: true,
logGroupName: firehoseLogGroup.logGroupName,
logStreamName: firehoseLogStream.logStreamName,
},
compressionFormat: "GZIP",
prefix: "!{partitionKeyFromQuery:resource_type}/!{timestamp:yyyy}/!{timestamp:MM}/!{timestamp:dd}/",
errorOutputPrefix: "errors/!{firehose:error-output-type}/!{timestamp:yyyy}/!{timestamp:MM}/!{timestamp:dd}/",
bufferingHints: {
sizeInMBs: 128,
intervalInSeconds: 300,
},
dynamicPartitioningConfiguration: {
enabled: true,
},
processingConfiguration: {
enabled: true,
processors: [
{
type: "RecordDeAggregation",
parameters: [
{
parameterName: "SubRecordType",
parameterValue: "JSON",
},
],
},
{
type: "MetadataExtraction",
parameters: [
{
parameterName: "MetadataExtractionQuery",
parameterValue: "{resource_type: .resource_type}",
},
{
parameterName: "JsonParsingEngine",
parameterValue: "JQ-1.6",
},
],
},
{
type: "AppendDelimiterToRecord",
parameters: [],
},
],
},
},
});
}
}
以下が動的パーティションを含んだ Prefix の設定です。timestamp は組み込みのものをそのまま使い、先頭に resource_type を設定します。こうすることで、ログフォーマットごとにパーティションが分割されます。この値は処理時に実際のデータを読み込んで取得されます。
prefix: "!{partitionKeyFromQuery:resource_type}/!{timestamp:yyyy}/!{timestamp:MM}/!{timestamp:dd}/",
errorOutputPrefix: "errors/!{firehose:error-output-type}/!{timestamp:yyyy}/!{timestamp:MM}/!{timestamp:dd}/",
上記のように設定した場合、動的パーティショニングは明示的に有効化する必要があります。
dynamicPartitioningConfiguration: {
enabled: true,
},
データを読み込んでパーティションを設定するので、詳細な設定が必要です。MetadataExtraction で JSON をパースするためのパラメータを設定します。また RecordDeAggregation の SubRecordType を JSON に設定します。
processingConfiguration: {
enabled: true,
processors: [
{
type: "RecordDeAggregation",
parameters: [
{
parameterName: "SubRecordType",
parameterValue: "JSON",
},
],
},
{
type: "MetadataExtraction",
parameters: [
{
parameterName: "MetadataExtractionQuery",
parameterValue: "{resource_type: .resource_type}",
},
{
parameterName: "JsonParsingEngine",
parameterValue: "JQ-1.6",
},
],
},
{
type: "AppendDelimiterToRecord",
parameters: [],
},
],
},
Handler
Lambda 関数のリソース設定です。
重要な点として、環境変数でリソースのマッピング情報を渡しています。今回は対象が少ないので環境変数を使っていますが、リソース数が多い場合は SSM パラメーターストアなどを検討しましょう。props で渡された各リソースの名前をキーに、リソース種別を値にしています。
// Create resoure map for determine log format
const resourceMap: { [kye: string]: string } = {};
resourceMap[props.alb.loadBalancerName] = "alb";
resourceMap[props.nlb.loadBalancerName] = "nlb";
resourceMap[props.instanceName] = "clf";
resourceMap[props.distributionName] = "cf";
...
environment: {
FIREHOSE_STREAM_NAME: props.deliveryStream.deliveryStreamName!,
RESOURCE_MAP: JSON.stringify(resourceMap),
},
関数エイリアスを発行し、イベントソースに SQS キューを設定します。maxConcurrency は関数の reservedConcurrentExecutions と同じにします。
// Update function alias
const alias = new cdk.aws_lambda.Alias(this, "LogParserAlias", {
aliasName: "live",
version: logParser.currentVersion,
})
// Set queue to lambda event source
alias.addEventSource(
new cdk.aws_lambda_event_sources.SqsEventSource(queue, {
batchSize: 10,
maxConcurrency: 2,
})
);
ここまでで定義したリソースをデプロイします。
cdk synth cdk deploy
Lambda 関数
今回 Lambda 関数では、サポートしているログフォーマットであればどれがきても処理できるようにする必要があります。まず全体像です。
package main
import (
"bytes"
"compress/gzip"
"context"
"encoding/json"
"fmt"
"log"
"os"
"strings"
"github.com/aws/aws-lambda-go/events"
"github.com/aws/aws-lambda-go/lambda"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/firehose"
"github.com/aws/aws-sdk-go-v2/service/firehose/types"
"github.com/aws/aws-sdk-go-v2/service/s3"
parser "github.com/nekrassov01/access-log-parser"
)
const (
maxRecs = 400 // limit: 500
maxSize = 3 * 1024 * 1024 // limit: 4MiB
)
var cfg aws.Config
func init() {
var err error
cfg, err = config.LoadDefaultConfig(context.Background())
if err != nil {
log.Fatalf("cannot load aws sdk config: %v", err)
}
}
func getResourceMap(name string) (map[string]string, error) {
s := os.Getenv(name)
if s == "" {
return nil, fmt.Errorf("failed to get value from environment variable \"%s\"", name)
}
m := make(map[string]string)
if err := json.Unmarshal([]byte(s), &m); err != nil {
return nil, err
}
return m, nil
}
func getParser(ctx context.Context, buf *bytes.Buffer, k, v string) (parser.Parser, error) {
lineHandler := func(labels, values []string, isFirst bool) (string, error) {
ls := make([]string, 0, len(labels)+2)
ls = append(ls, "resource_type", "resource_name")
ls = append(ls, labels...)
vs := make([]string, 0, len(values)+2)
vs = append(vs, v, k)
vs = append(vs, values...)
return parser.JSONLineHandler(ls, vs, isFirst)
}
opt := parser.Option{
LineHandler: lineHandler,
}
ec2opt := parser.Option{
LineHandler: lineHandler,
Filters: []string{"user_agent !~* ^ELB-HealthChecker"},
}
cfopt := parser.Option{
LineHandler: lineHandler,
SkipLines: []int{1, 2},
}
var p parser.Parser
switch v {
case "clf":
p = parser.NewApacheCLFRegexParser(ctx, buf, ec2opt)
case "clfv":
p = parser.NewApacheCLFWithVHostRegexParser(ctx, buf, ec2opt)
case "s3":
p = parser.NewS3RegexParser(ctx, buf, opt)
case "cf":
p = parser.NewCFRegexParser(ctx, buf, cfopt)
case "alb":
p = parser.NewALBRegexParser(ctx, buf, opt)
case "nlb":
p = parser.NewNLBRegexParser(ctx, buf, opt)
case "clb":
p = parser.NewCLBRegexParser(ctx, buf, opt)
default:
return nil, fmt.Errorf("invalid resource type: \"%s\"", v)
}
return p, nil
}
func splitData(data []byte) [][]byte {
var (
chunks [][]byte
chunk []byte
count int
size int
)
for _, record := range bytes.Split(data, []byte("\n")) {
if count >= maxRecs || size+len(record)+1 > maxSize {
chunks = append(chunks, chunk)
chunk = nil
count = 0
size = 0
}
chunk = append(chunk, record...)
chunk = append(chunk, '\n')
count++
size += len(record) + 1
}
if len(chunk) > 0 {
chunks = append(chunks, chunk)
}
return chunks
}
func handleRequest(ctx context.Context, event events.SQSEvent) error {
rmap, err := getResourceMap("RESOURCE_MAP")
if err != nil {
return err
}
buf := &bytes.Buffer{}
s3client := s3.NewFromConfig(cfg)
firehoseClient := firehose.NewFromConfig(cfg)
for _, record := range event.Records {
var s3event *events.S3Event
if err := json.Unmarshal([]byte(record.Body), &s3event); err != nil {
return err
}
for _, rec := range s3event.Records {
key := rec.S3.Object.Key
name := strings.Split(key, "/")[0]
obj, err := s3client.GetObject(ctx, &s3.GetObjectInput{
Bucket: aws.String(rec.S3.Bucket.Name),
Key: aws.String(key),
})
if err != nil {
return err
}
j, _ := json.Marshal(map[string]string{"key": key})
fmt.Println(string(j))
v, ok := rmap[name]
if !ok {
fmt.Printf("skip because cannot determine log format of \"%s\"\n", name)
continue
}
p, err := getParser(ctx, buf, name, v)
if err != nil {
return err
}
r, err := gzip.NewReader(obj.Body)
if err != nil {
return err
}
defer r.Close()
result, err := p.Parse(r)
if err != nil {
return err
}
b, err := json.Marshal(result)
if err != nil {
return err
}
fmt.Println(string(b))
}
}
if buf.Len() == 0 {
return fmt.Errorf("abort process because buffer is empty")
}
for _, data := range splitData(buf.Bytes()) {
resp, err := firehoseClient.PutRecordBatch(ctx, &firehose.PutRecordBatchInput{
DeliveryStreamName: aws.String(os.Getenv("FIREHOSE_STREAM_NAME")),
Records: []types.Record{
{
Data: data,
},
},
})
if err != nil {
return err
}
if resp != nil {
b, err := json.Marshal(resp)
if err != nil {
return err
}
fmt.Println(string(b))
}
}
return nil
}
func main() {
lambda.Start(handleRequest)
}
以下の関数で環境変数からリソースのマッピング情報を取得し、JSON 文字列を Go の map に変換します。環境変数が取得できなければエラーになります。
func getResourceMap(name string) (map[string]string, error) {
s := os.Getenv(name)
if s == "" {
return nil, fmt.Errorf("failed to get value from environment variable \"%s\"", name)
}
m := make(map[string]string)
if err := json.Unmarshal([]byte(s), &m); err != nil {
return nil, err
}
return m, nil
}
getParser ではログパーサーをセットアップします。以下では行に対する変換処理を担う parser.JSONLineHandler をカスタマイズし、resource_type と resource_name を追加しています。
lineHandler := func(labels, values []string, isFirst bool) (string, error) {
ls := make([]string, 0, len(labels)+2)
ls = append(ls, "resource_type", "resource_name")
ls = append(ls, labels...)
vs := make([]string, 0, len(values)+2)
vs = append(vs, v, k)
vs = append(vs, values...)
return parser.JSONLineHandler(ls, vs, isFirst)
}
EC2 インスタンスの場合はヘルスチェックのログがあった場合に除外する設定を入れています。
ec2opt := parser.Option{
LineHandler: lineHandler,
Filters: []string{"user_agent !~* ^ELB-HealthChecker"},
}
CloudFront の場合はヘッダー2 行を除外する設定を入れています。
cfopt := parser.Option{
LineHandler: lineHandler,
SkipLines: []int{1, 2},
}
あとは resource_type に応じた適切なログパーサーを設定します。
var p parser.Parser
switch v {
case "clf":
p = parser.NewApacheCLFRegexParser(ctx, buf, ec2opt)
case "clfv":
p = parser.NewApacheCLFWithVHostRegexParser(ctx, buf, ec2opt)
case "s3":
p = parser.NewS3RegexParser(ctx, buf, opt)
case "cf":
p = parser.NewCFRegexParser(ctx, buf, cfopt)
case "alb":
p = parser.NewALBRegexParser(ctx, buf, opt)
case "nlb":
p = parser.NewNLBRegexParser(ctx, buf, opt)
case "clb":
p = parser.NewCLBRegexParser(ctx, buf, opt)
default:
return nil, fmt.Errorf("invalid resource type: \"%s\"", v)
}
PutRecordBatch API の制限を考慮したデータ分割もしています。以下の制限です。
The PutRecordBatch operation can take up to 500 records per call or 4 MiB per call, whichever is smaller. This quota cannot be changed.
(訳) PutRecordBatch オペレーションは、1 コールあたり 500 レコードまたは 4MiB のいずれか小さい方まで取ることができる。このクォータは変更できない。
まず、余裕を持った上限値を設定しておきます。
const (
maxRecs = 400 // limit: 500
maxSize = 3 * 1024 * 1024 // limit: 4MiB
)
splitData 関数ではレコード数と容量を検査してバイト列を分割します。
<br />func splitData(data []byte) [][]byte {
var (
chunks [][]byte
chunk []byte
count int
size int
)
for _, record := range bytes.Split(data, []byte("\n")) {
if count >= maxRecs || size+len(record)+1 > maxSize {
chunks = append(chunks, chunk)
chunk = nil
count = 0
size = 0
}
chunk = append(chunk, record...)
chunk = append(chunk, '\n')
count++
size += len(record) + 1
}
if len(chunk) > 0 {
chunks = append(chunks, chunk)
}
return chunks
}
handleRequest 関数では splitData で分割した塊ごとに PutRecordBatch API をコールすることでエラーを回避します。
func handleRequest(ctx context.Context, event events.SQSEvent) error {
...
for _, data := range splitData(buf.Bytes()) {
resp, err := firehoseClient.PutRecordBatch(ctx, &firehose.PutRecordBatchInput{
DeliveryStreamName: aws.String(os.Getenv("FIREHOSE_STREAM_NAME")),
Records: []types.Record{
{
Data: data,
},
},
})
if err != nil {
return err
}
if resp != nil {
b, err := json.Marshal(resp)
if err != nil {
return err
}
fmt.Println(string(b))
}
}
return nil
}
動作確認
各リソースに対してブラウザアクセスし、ログが収集されるか確認します。
生ログ
プレフィックスが想定通りに設定されています。

変換後のログ
こちらも Firehose の動的パーティショニングによってログフォーマットごとに振り分けられています。あとは AWS Glue を使ってこのプレフィックスごとにテーブル化すれば、整理されたログの状態が実現できそうです。まだ検証できていませんが Glue の ETL 処理で統合テーブルをセットアップしてもよさそうですね。
resource_type、resource_name も問題なく付与されています (一部マスクしています)
{"resource_type":"clf","resource_name":"kawashima-test-web-instance","remote_host":"0.0.0.0","remote_logname":"-","remote_user":"-","datetime":"[24/Mar/2024:16:35:20 +0000]","method":"GET","request_uri":"/","protocol":"HTTP/1.1","status":"304","size":"-","referer":"-","user_agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
{"resource_type":"clf","resource_name":"kawashima-test-web-instance","remote_host":"0.0.0.0","remote_logname":"-","remote_user":"-","datetime":"[24/Mar/2024:16:35:21 +0000]","method":"GET","request_uri":"/","protocol":"HTTP/1.1","status":"304","size":"-","referer":"-","user_agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
{"resource_type":"clf","resource_name":"kawashima-test-web-instance","remote_host":"0.0.0.0","remote_logname":"-","remote_user":"-","datetime":"[24/Mar/2024:16:35:21 +0000]","method":"GET","request_uri":"/","protocol":"HTTP/1.1","status":"304","size":"-","referer":"-","user_agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
{"resource_type":"clf","resource_name":"kawashima-test-web-instance","remote_host":"0.0.0.0","remote_logname":"-","remote_user":"-","datetime":"[24/Mar/2024:16:35:22 +0000]","method":"GET","request_uri":"/","protocol":"HTTP/1.1","status":"304","size":"-","referer":"-","user_agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
{"resource_type":"clf","resource_name":"kawashima-test-web-instance","remote_host":"0.0.0.0","remote_logname":"-","remote_user":"-","datetime":"[24/Mar/2024:16:35:22 +0000]","method":"GET","request_uri":"/","protocol":"HTTP/1.1","status":"304","size":"-","referer":"-","user_agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
おわりに
AWS でのログ基盤構築において、フォーマットの異なる様々なログの集約と構造化までをやってみました。次回は AWS Glue を使って ETL 処理したり Amazon Athena を使ってクエリしたりといった、よりデータ分析っぽい内容を検証してみたいと思います。
私自身データ分析系の AWS サービスは今まで使ってこなかったので、構成に関してはまだ最適化の余地があると思います。が、現在のところ多様なログを単一のフローに沿って処理できているので、比較的シンプルな構成になっているのではないでしょうか。

