
はじめに
遅れながら Bedrock まわりのキャッチアップをしています。かなりアップデートが多く状況が流動的な印象を受けました。LangChain まわりもカオスな印象を受けました。めげずにキャッチアップしていきたいと思います。
インフラ構築を含めて検証していきたいので、手始めに Knowledge Bases for Amazon Bedrock へリクエストする簡単なサンプル画面を ECS Fargate で動かしてみます。
この記事の価値としては、この構成を CDK で構築するところになるかと思います。
概要
簡略化していますが、以下のような構成です。リージョンはバージニア北部とします (新たなモデルが出てくるのはオレゴンの方が早いようですが)
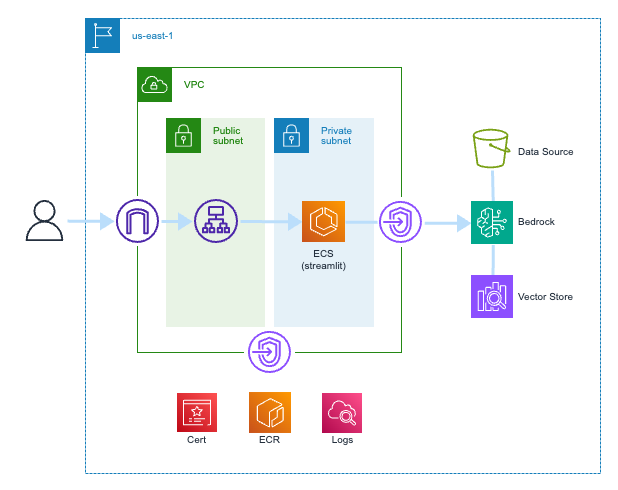
VPC エンドポイント経由で通信する
VPC エンドポイントを使って通信が極力 AWS のネットワークを通るようにします。NAT ゲートウェイは作成しません。今回は以下エンドポイントが必要になります。
| サービス名 | エンドポイントタイプ |
|---|---|
| com.amazonaws.us-east-1.ecr.api | Interface |
| com.amazonaws.us-east-1.ecr.dkr | Interface |
| com.amazonaws.us-east-1.logs | Interface |
| com.amazonaws.us-east-1.s3 | Gateway |
| com.amazonaws.us-east-1.bedrock-runtime | Interface |
| com.amazonaws.us-east-1.bedrock-agent-runtime | Interface |
Bedrock に関してはドキュメントで必要な VPC エンドポイントを調べました。今回は ECS Fargate でホストするアプリケーションが次の API を叩く想定のため bedrock-runtime と bedrock-agent-runtime へのアクセスが必要でした。
bedrock:InvokeModelbedrock:Retrievebedrock:RetrieveAndGenerate
Streamlit を使う
チャット画面を簡単に構築できる Streamlit を Docker コンテナで動かします。
データソースは前回と同じ
前回の記事を踏襲して YAMAHA の VPN ルーター RTX1200 のユーザーガイド、コマンドリファレンス、設定例集を読み込ませます。
CDK コード
リポジトリはこちらです。lib/image/app 配下がサンプルアプリですが、環境構築には rye を使いました。
. ├── README.md ├── bin │ └── main.ts ├── cdk-bedrock.code-workspace ├── cdk.context.json ├── cdk.example.json ├── cdk.json ├── docs │ └── diagram.png ├── jest.config.js ├── lib │ ├── constructs │ │ ├── ecs.ts │ │ └── kb.ts │ ├── content │ │ └── doc │ │ └── data.zip │ ├── image │ │ └── app │ │ ├── README.md │ │ ├── pyproject.toml │ │ ├── requirements-dev.lock │ │ ├── requirements.lock │ │ └── src │ │ └── app │ │ ├── Dockerfile │ │ ├── app.py │ │ └── requirements.txt │ └── stack.ts ├── package-lock.json ├── package.json ├── test │ └── cdk-bedrock.test.ts └── tsconfig.json
前準備
cdk.json に必要な情報を入れます。パブリックホストゾーンと ECR リポジトリは既存のものを使う前提なので、ここで設定します。
// 例
{
...
"context": {
...
"owner": "user",
"serviceName": "my-service",
"hostZoneName": "example.com",
"allowedIps": ["0.0.0.0/0"],
"httpProxy": "http://my-proxy.com:port",
"repository": "user/reponame"
}
}
- 今回はサンプルのため、アプリケーションに認証機能がありません。このため実際には
allowdIpsで社内のグローバル IP に限定するようにしています。 - 弊社特有の事情によるものですが、コンテナのビルド時に通信が社内プロキシを通るため
httpProxyの設定をしています。流用の際はご注意ください。
Knowledge Bases for Amazon Bedrock の構築
コード。現状 CDK でナレッジベースを作りたい場合、@cdklabs/generative-ai-cdk-constructs を使うのがいちばん楽かと思います。
ナレッジベース
vectorStore を明示的に渡さない場合は、裏で自動的に OpenSearch Serverless が構築されます。ロールも暗黙的に作られます。また instruction でナレッジベースへの問い合わせが必要かどうかを判断させています。
this.knowledgebase = new bedrock.KnowledgeBase(this, "KnowledgeBase", {
name: `${props.serviceName}-knowledgebase`,
description: `${props.serviceName}-knowledgebase`,
embeddingsModel: bedrock.BedrockFoundationModel.COHERE_EMBED_MULTILINGUAL_V3,
instruction:
"YAMAHAというメーカーが開発したRTX1200というVPNルーターに関する質問に回答してください。参考ドキュメントにはユーザーガイド、コマンドリファレンス、設定例集が含まれています。",
})
データソース
埋め込みモデルが COHERE_EMBED_MULTILINGUAL_V3 の場合、チャンクサイズの上限値は 512 でした (ドキュメント)
new bedrock.S3DataSource(this, "DataSource", {
bucket: bucket,
knowledgeBase: this.knowledgebase,
dataSourceName: `${props.serviceName}-knowledgebase-datasource`,
chunkingStrategy: bedrock.ChunkingStrategy.FIXED_SIZE,
maxTokens: 512,
overlapPercentage: 20,
});
S3 バケットへのドキュメントのデプロイも一緒にやっています。
new cdk.aws_s3_deployment.BucketDeployment(this, "BucketDeployment", {
sources: [cdk.aws_s3_deployment.Source.asset("lib/content/doc/data.zip")],
destinationBucket: bucket,
logRetention: cdk.aws_logs.RetentionDays.THREE_DAYS,
});
ECS の構築
コード。AppRunner でホストできれば楽だったのですが、Streamlit は WebSocket で通信するためサポート外でした (経緯)
コンテナイメージのビルド
cdk.aws_ecr_assets.DockerImageAsset を使い、ローカルの Dockerfile をビルドおよびデプロイします。今回はプロキシを通したいので、URL を buildArgs で渡します。イメージは cdk-hnb659fds-container-assets-${account}-${region} という ECR リポジトリにデプロイされます。
const image = new cdk.aws_ecr_assets.DockerImageAsset(this, "Image", {
directory: "lib/image/app/src/app",
buildArgs: {
HTTP_PROXY: props.httpProxy,
},
});
自前のリポジトリに配置したいので、cdk-ecr-deploymentを使います。src から dest にイメージをコピーできます。
const repository = cdk.aws_ecr.Repository.fromRepositoryName(this, "Repository", props.repository);
new ecrdeploy.ECRDeployment(this, "ImageDeployment", {
src: new ecrdeploy.DockerImageName(image.imageUri),
dest: new ecrdeploy.DockerImageName(repository.repositoryUriForTag(tag)),
});
IAM ロール
タスク実行ロールは特にいじる必要ないのですが、名前だけ決めて権限を CDK に任せる場合は以下のようにします。
const executionRole = new cdk.aws_iam.Role(this, "ExecutionRole", {
roleName: `${props.serviceName}-execution-role`,
assumedBy: new cdk.aws_iam.CompositePrincipal(
new cdk.aws_iam.ServicePrincipal("ecs-tasks.amazonaws.com")
),
});
タスクロールにはアプリが Bedrock にアクセスするための権限を追加で設定します。
const taskRole = new cdk.aws_iam.Role(this, "TaskRole", {
roleName: `${props.serviceName}-task-role`,
assumedBy: new cdk.aws_iam.CompositePrincipal(new cdk.aws_iam.ServicePrincipal("ecs-tasks.amazonaws.com")),
inlinePolicies: {
ECSTaskRoleAdditionalPolicy: new cdk.aws_iam.PolicyDocument({
statements: [
new cdk.aws_iam.PolicyStatement({
effect: cdk.aws_iam.Effect.ALLOW,
actions: ["bedrock:*"],
resources: ["*"],
}),
],
}),
},
});
タスク定義
コンテナをビルドするローカルマシンが M2 Mac なので CPU アーキテクチャは Arm64 にしました。ビルド環境によって異なります。
const taskDefinition = new cdk.aws_ecs.FargateTaskDefinition(this, "TaskDefinition", {
family: `${props.serviceName}-task-definition`,
cpu: 256,
memoryLimitMiB: 512,
runtimePlatform: {
operatingSystemFamily: cdk.aws_ecs.OperatingSystemFamily.LINUX,
cpuArchitecture: cdk.aws_ecs.CpuArchitecture.ARM64, // <- これ
},
executionRole: executionRole,
taskRole: taskRole,
});
コンテナの設定
コンテナに渡したい変数について今回は環境変数で設定しました。SSM パラメーターストア経由でもいいと思います。モデルの ID、モデルの生えているリージョン、ナレッジベースの ID を渡しています。command を指定しない場合は Dockerfile の CMD が実行されるのでここでは指定しません。
taskDefinition.addContainer("Container", {
containerName: contanerName,
image: cdk.aws_ecs.ContainerImage.fromEcrRepository(repository, tag),
logging: cdk.aws_ecs.LogDrivers.awsLogs({
logGroup: logGroup,
streamPrefix: "logs",
}),
environment: {
TARGET_REGION: stack.region,
MODEL_ID: bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_V2.modelId,
KNOWLEDGE_BASE_ID: props.knowledgebase.knowledgeBaseId,
},
portMappings: [
{
containerPort: containerPort,
protocol: cdk.aws_ecs.Protocol.TCP,
},
],
});
ALB
ALB のセキュリティグループでインバウンドの HTTPS アクセスが解放されないように明示的に open: false を設定します。逆にいうとこれを書かないと 0.0.0.0/0 が勝手に設定されます。
const alb = new cdk.aws_elasticloadbalancingv2.ApplicationLoadBalancer(this, "ALB", {
loadBalancerName: `${props.serviceName}-alb`,
vpc: vpc,
vpcSubnets: publicSubnets,
internetFacing: true,
securityGroup: albSecurityGroup,
})
const albListener = alb.addListener("Listener", {
protocol: cdk.aws_elasticloadbalancingv2.ApplicationProtocol.HTTPS,
certificates: [
{
certificateArn: cert.certificateArn,
},
],
open: false, // <- こいつ
});
アプリケーション
Dockerfile は以下の形です。弊社環境にあわせるために HTTP_PROXY を設定しています。CDK 側で定義した buildArgs 経由で適用されます。
FROM python:3.12
ARG HTTP_PROXY
ARG DIR=app
COPY ./ /$DIR/
WORKDIR /$DIR
RUN set -eux \
&& apt-get update -y -qq \
&& apt-get clean -y \
&& rm -rf /var/lib/apt/lists/* \
&& pip install --no-cache-dir -r requirements.txt --proxy ${HTTP_PROXY}
EXPOSE 8501
ENTRYPOINT ["streamlit", "run"]
CMD ["app.py"]
肝心のスクリプトですが、このようにしました。プロンプトは研究中です。
import os
import streamlit as st
from langchain.prompts import PromptTemplate
from langchain_aws.llms import BedrockLLM
from langchain_aws.retrievers import AmazonKnowledgeBasesRetriever
from langchain_core.runnables import RunnablePassthrough
template = """
###ドキュメント
{context}
###
###質問
{question}
###
Human: あなたは優秀なネットワークエンジニアです。ドキュメントセクションの内容を参照し、質問セクションに対して1000文字程度の日本語で回答してください。
もし質問セクションの内容がドキュメントにない場合は「ドキュメントに記載がありません」と回答してください。
またドキュメントにはコマンドリファレンスを含むため、質問に沿ったコマンドをコードブロックで回答してください。
Assistant:
"""
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id=os.environ["KNOWLEDGE_BASE_ID"],
retrieval_config={
"vectorSearchConfiguration": {"numberOfResults": 4},
},
region_name=os.environ["TARGET_REGION"],
)
prompt = PromptTemplate(
input_variables=["context", "question"],
template=template,
)
model = BedrockLLM(
model_id=os.environ["MODEL_ID"],
model_kwargs={"max_tokens_to_sample": 1000},
verbose=True,
region_name=os.environ["TARGET_REGION"],
)
chain = {"context": retriever, "question": RunnablePassthrough()} | prompt | model
st.title("TEST")
input_text = st.text_input("Input")
submit = st.button("Submit")
if submit:
result = chain.invoke(input_text)
st.write(result)
最近は LangChain Expression Language という、chain をパイプ繋ぎで書く記法が推奨のようです。パブリッククラウドの LLM まわりのアップデートは忙しないですが、LangChain まわりはそれ以上にカオスな感じがします。AWS 関連のコードは langchain-aws に切り出されましたし。
chain = {"context": retriever, "question": RunnablePassthrough()} | prompt | model
Streamlit はまだ使いこなせていないので、最低限のガワを被せる程度です。逆にこれだけで動くのがすごい。
st.title("TEST")
input_text = st.text_input("Input")
submit = st.button("Submit")
if submit:
result = chain.invoke(input_text)
st.write(result)
動かしてみる
デプロイします。
cdk synth cdk deploy
忘れがちなのが、データソースの同期です。自動で実行されるわけではないので、マネコンなどで同期しておきましょう。同期の完了後、アクセスしてみます。無事に画面が表示されました。
質問してみます。
DHCPで特定のMACアドレスに特定のIPアドレスを配布するコマンドを教えてください。
問題なく回答が返ってきます。形式もコードブロックを含んだものになっており、想定通りです。

ただし、例えば「L2TP/IPsecを使用して外出先のPCからリモートアクセスするためのVPN設定例をドキュメントから探して提示してください」のような、複合的な質問にはうまく答えられませんでした。
プロダクションレベルで使うためには、こういった質問にも正確な回答を引き出すようなプロンプトのチューニングやデータソースのチャンキング戦略が必要なのだろうと想像できます。
おわりに
Knowledge Bases for Amazon Bedrock + ECS Fargate を CDK で構築する方法を紹介しました。エージェント機能や Converse API など、さわれていない機能がまだまだあるので、引き続き検証していきたいと思います。

