
この記事は「もくもく会ブログリレー」 21 日目 の記事です。
音楽生成AIのUdioに曲を作ってもらい、Demucsを使って音源分離していきます。
ソースコードはこちらからコピペして使ってください。
Demucsのgithubはこちらです。
Udioは2024/07/17時点ではまだBeta版ですがクオリティが非常に高いです。
1. アカウント登録
Udioはアカウント登録せずとも曲を聞くことは可能ですが、生成したい場合は登録必須です。
登録方法はとても簡単で、写真のどれかのパターンで登録するだけで使えます。
2. タグの設定
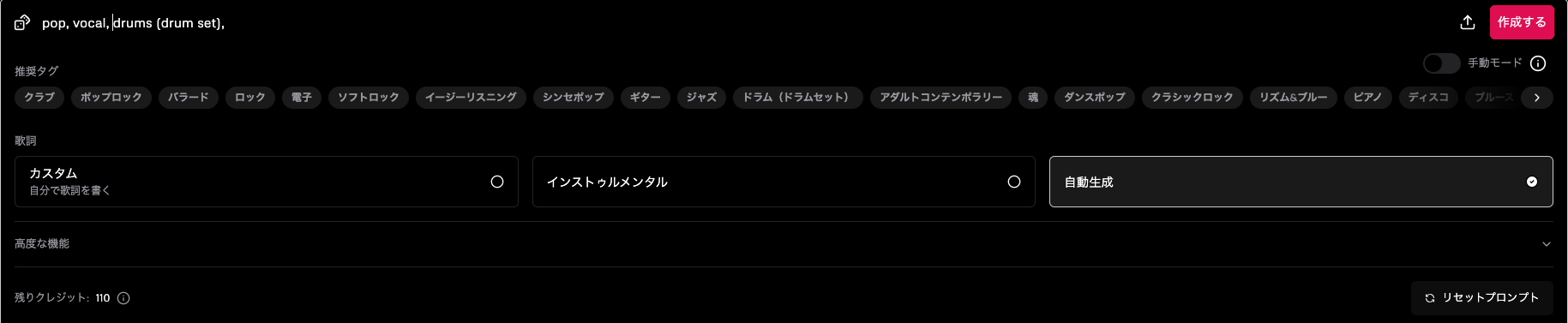
曲を作るには、タグなどを設定する必要があります。
今回はシンプルに、[pop, vocal, drums (drum set)]の三つのタグで生成します。
3. 音楽生成
作成すると写真のように二つ音楽が生成されます。
無料版でも100/月 + 10/日分の曲を作成することができます。

4. Demucsを使用するための環境用意
次にUdioで作った曲を音源分離していきます。
先ほど作成した音楽データはダウンロードしてColaboratory上の/content/in-data/music.mp3にアップロードしておきます。
環境はGoogle Colaboratoryを使って作っていきます。
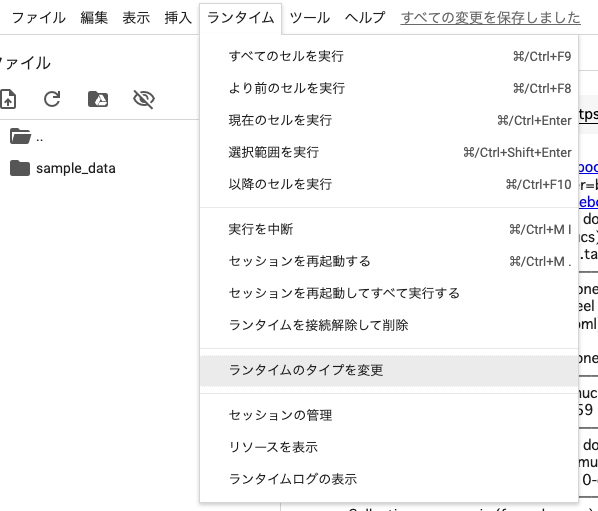
ランタイムは「T4 GPU」のほうが実行速度が速いのでこちらを使用するのをおすすめします。
変更方法
- ランタイム
- ランタイムのタイプを変更
- T4 GPU
- 保存
5. ライブラリインストール
- demucsはpipでinstallすることが可能ですが、最新版を使用したい場合はgithubから直接installします。
![]()
6. モジュールのインポート
IPython.displayは音楽を再生するときに使用します。

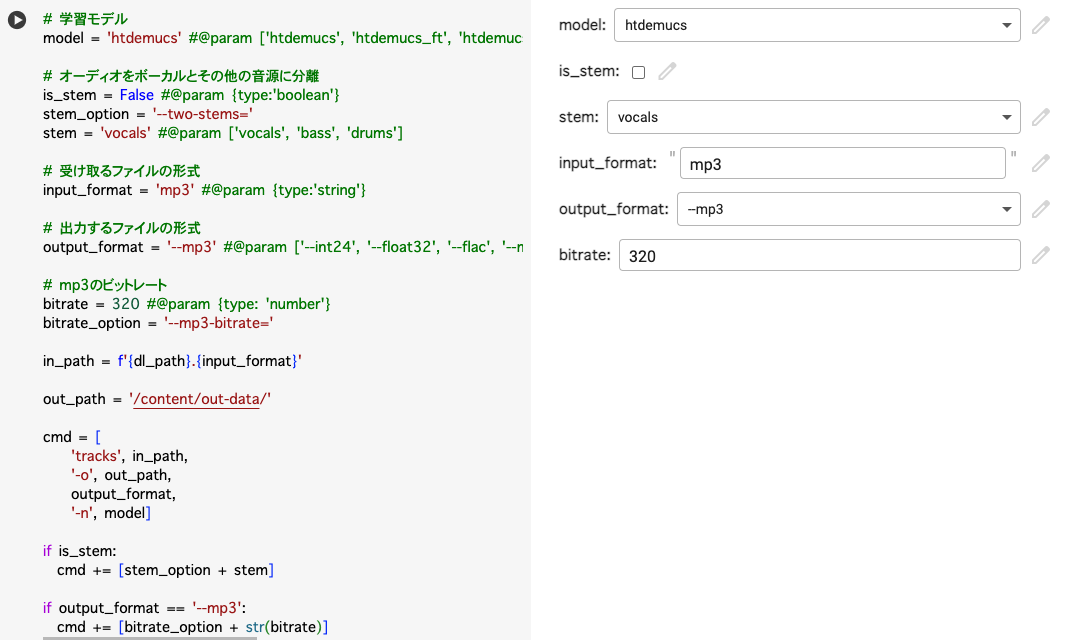
7. 音源分離のオプション選択
音源分離する学習モデルの選択や、受け取るファイル形式などを変更することができます。
 8. 実行
8. 実行
![]()
音源分離が完了するとファイルに追加されているのが確認できます。
ダウンロードもこちらからすることができます。
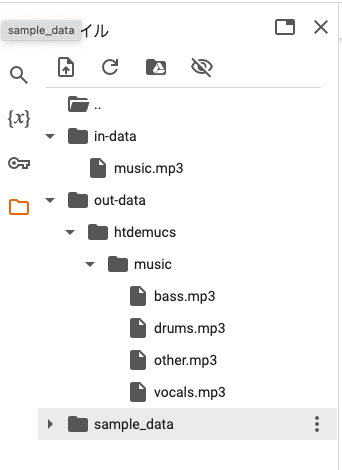
9. 再生する音楽の選択
実際にダウンロードして聞いてみるのもいいですが、都度ダウンロードするのは時間がかかるのでColaboratory上で聞けるようにします。
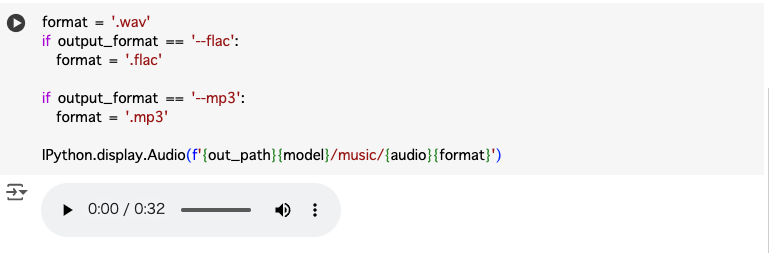
 10. 音楽再生
10. 音楽再生
スタートボタンを押すことで分離された音楽を聞くことができます
興味のある方はぜひ試してみてください!
明日の記事は、Yuutakkumaさんの「React Native with Expo 環境別Sentry設定方法」です。


