
この記事について
以前、【検証】画像PDFを検索可能化してRAGデータソースに活用するという記事で、Google Cloud のOCRサービスである、Document AIを使って、画像PDFをRAG検索可能なPDFに変換する、という検証を行いました。
本記事では、この検証で得られたことを発展させ、「Boxに配置された画像PDFをLambda内で処理し、Document AIでOCRを行い、S3に同期する」という実装を行いました。
実装で苦戦したポイントなど、実際の経験も交えながら解説していきます。
キーワード
本記事において核となる技術要素について最初にまとめました。
- Box V2 Webhook
- Boxに配置されたファイルのイベント検知
- Workload Identity 連携
- 外部IDプロバイダから、安全にGoogle Cloudサービスを呼び出すための認証連携機能
- Google Cloud Document AI
- Google CloudのOCRサービス
- documentai-tool-box・ocrmypdf・pymupdf
- OCR結果を加工し、最終的にPDFにするために利用したライブラリ
実装の全体像
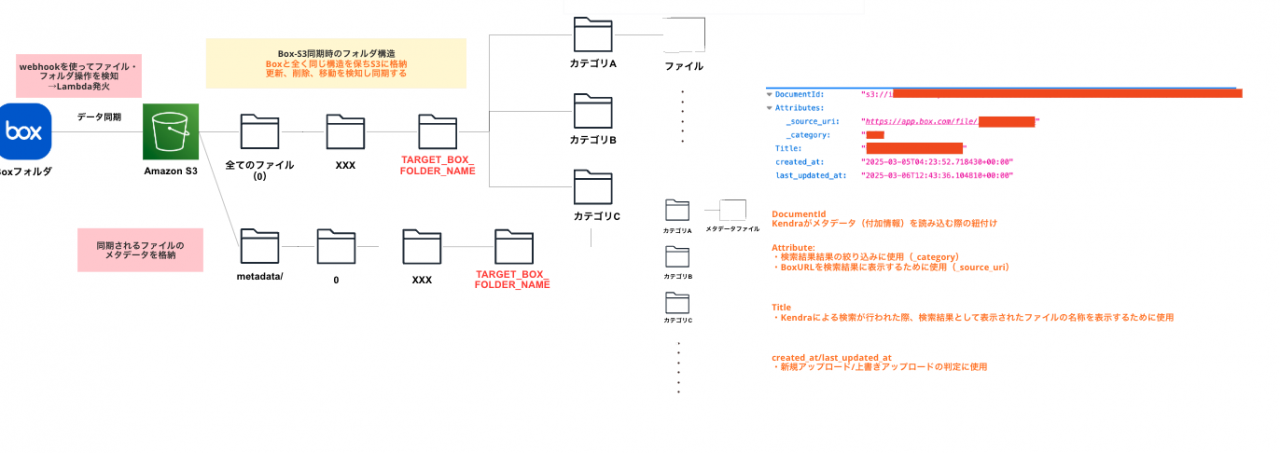
実装にはAWS SAM(Serverless Application Model)を使用しています。環境はPython 3.12です。
SAMプロジェクトの構成は以下に示した形で、BoxSyncFunctionと、OcrFunctionという2つのLambdaから構成されています。(本記事では重要な点をかいつまんで解説します。)
box_s3_sync/配下(BoxSyncFunction)- Boxに配置されたファイル・フォルダをS3に同期する
- 本記事ではファイルアップロード時の同期について解説
- S3へのファイルアップロード完了時に、EventBridgeでイベントを発行する
- Boxに配置されたファイル・フォルダをS3に同期する
validate_file/配下(OcrFunction)- S3にアップロードされたファイルのファイルのタイプ(.pdf/xlsx…..)を判定
- PDFかつPDF内に文字情報がない場合、Document AIによるOCRを処理を行い、テキスト情報を入れ込んだPDFを再度アップロード元のS3にアップロードする
.(project-name) ├── src/ │ ├── box_s3_sync/ # Boxファイルの、S3同期処理 │ │ ├── __init__.py │ │ ├── main.py │ │ ├── box_operation.py # Box操作関連の処理 │ │ ├── get_content_type.py # Content-Type判定処理 │ │ └── initialize_box_client.py # Boxクライアント初期化 │ ├── validate_file/ # Boxにアップロードされたファイルタイプの判定処理 │ │ ├── __init__.py │ │ ├── main.py │ │ ├── transcription_by_document_ai.py # Google Document AIによるOCR処理 │ │ ├── requirements.txt # 依存パッケージ定義 │ │ ├── Dockerfile # Lambda用コンテナイメージ定義 │ │ └── clientLibraryConfig-<your-google-cloud-project-name>.json │ ├── common/ # 共通モジュール │ │ ├── config.py # 共通設定(S3バケット名等) │ │ ├── logger_util.py # ロガー設定 │ │ └── document_ai_utils.py # Document AIを使ったOCR関連の処理 ├── layers/ # Lambda Layers │ └── common_layer/ │ └── python/ │ ├── __init__.py │ ├── config.py # 共通設定 │ ├── logger_util.py # ロガー設定 │ └── requirements.txt # 依存パッケージ定義 │ ├── template.yaml ├── samconfig.toml # SAM設定ファイル ├── pyproject.toml # uvプロジェクト設定 ├── uv.lock # 依存関係のロックファイル └── README.md
事前準備: 各種サービスの設定
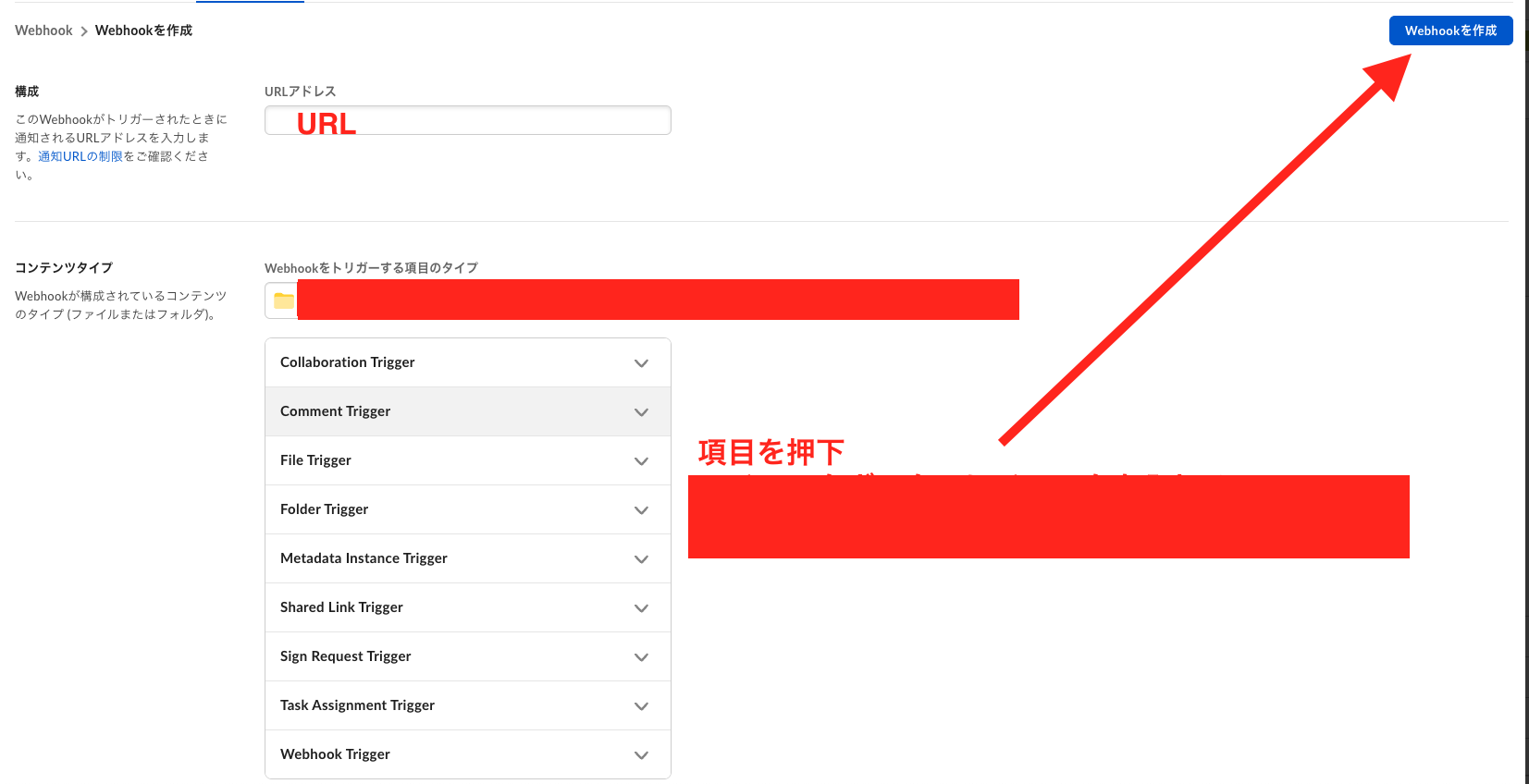
①BoxアプリとWebhookの設定
Box Developer Consoleでアプリを作成し、認証情報を取得します。その後、Webhookを設定し、通知先のURLに後ほど作成するLambda関数のURLを指定します。
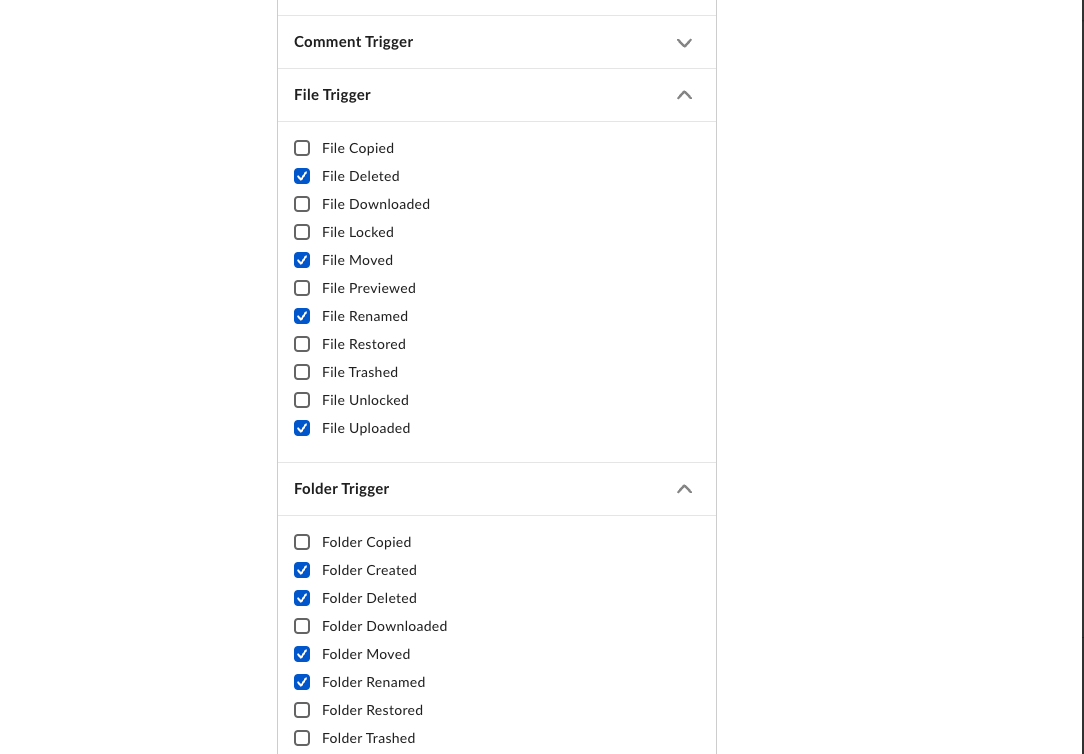
さらに、Webhookをトリガーする項目のタイプで、各種ファイル・フォルダのトリガーイベントの選択しておく必要があります。
※以下画像参照。
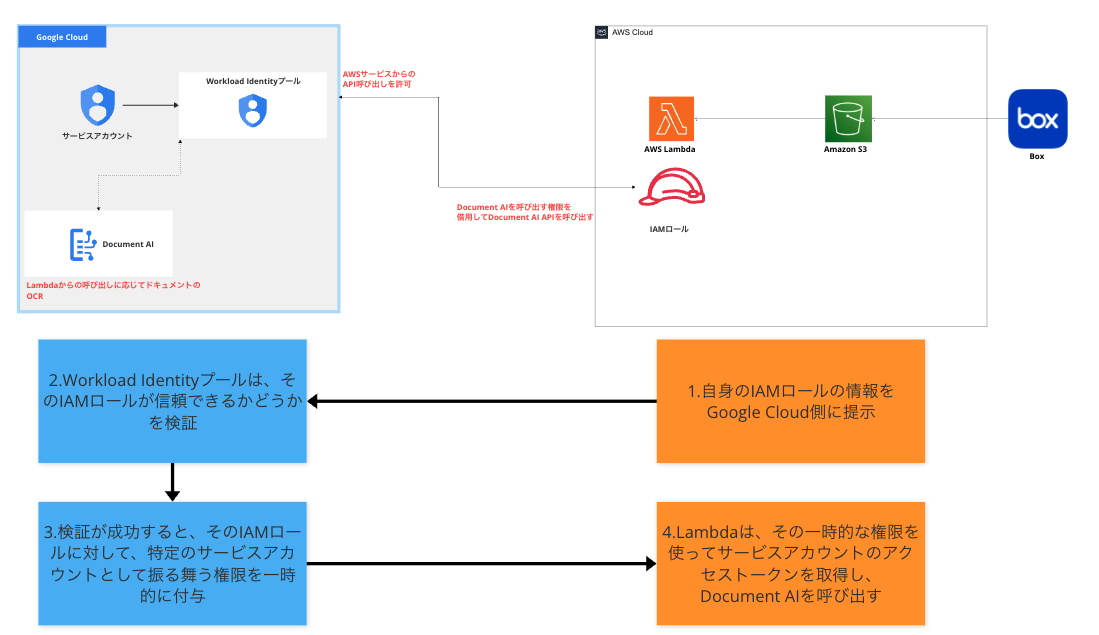
②Workload Identity連携を行うための設定
AWS LambdaからDocument AIを呼び出すため、Workload Identity連携設定が必要です。
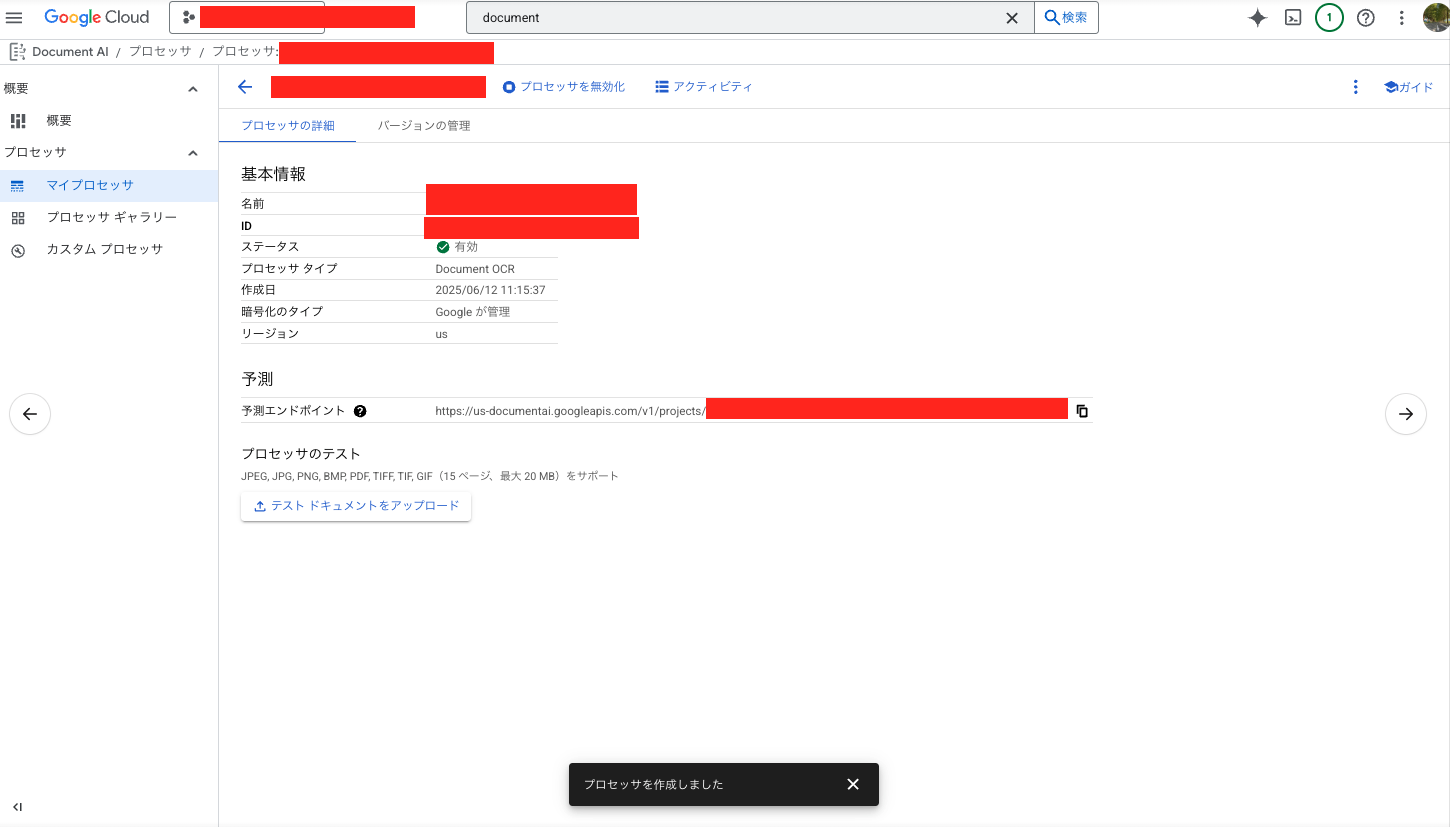
1.Google Cloud コンソールでDocument AI APIを有効化し、Documen AI プロセッサを作成する
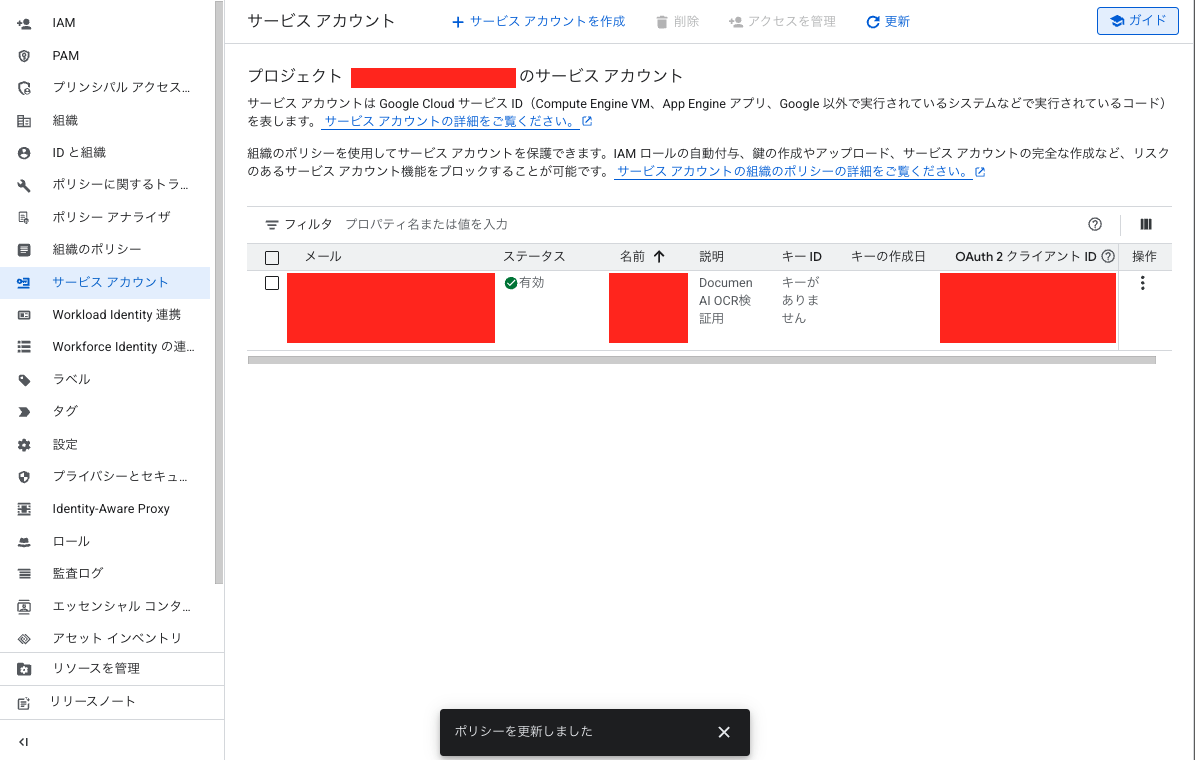
2.サービスアカウント作成、権限付与
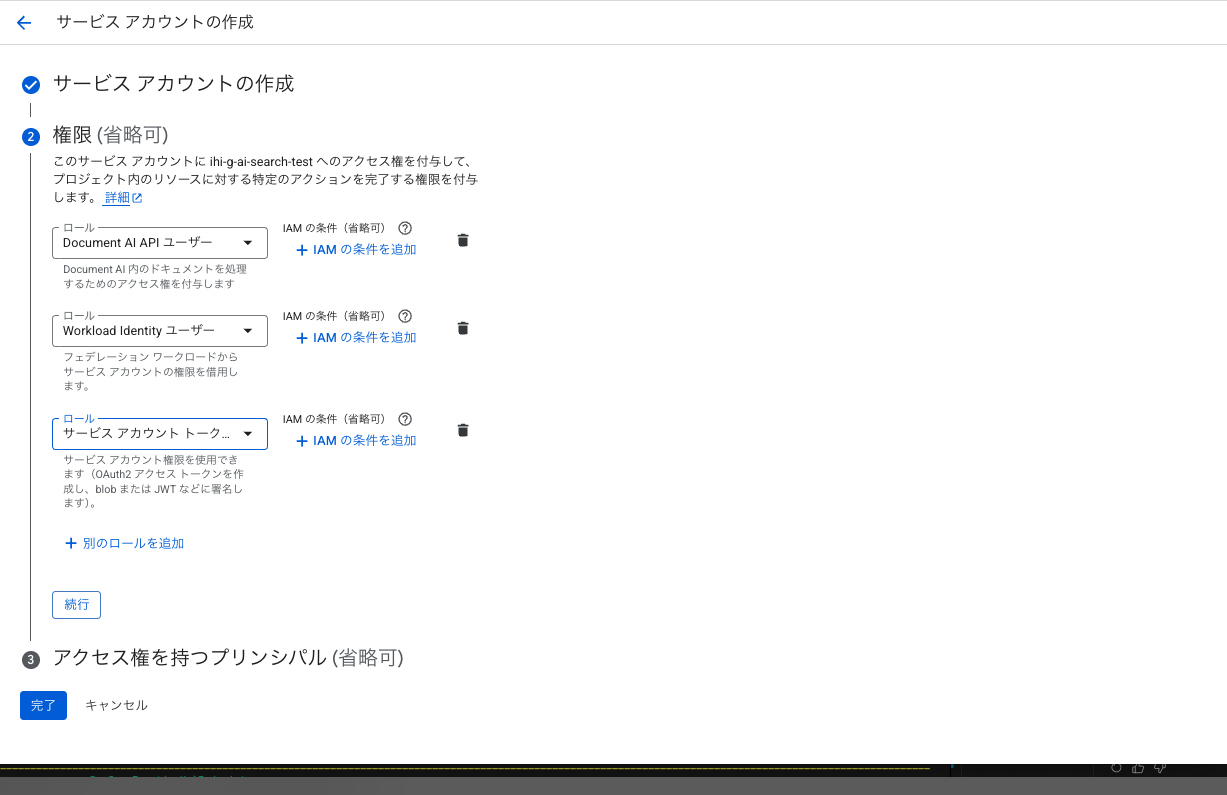
サービスアカウントを作成し、以下3つのロールを付与します。
- Document AI API ユーザー
- Workload Identity ユーザー
- サービスアカウントトークン作成者
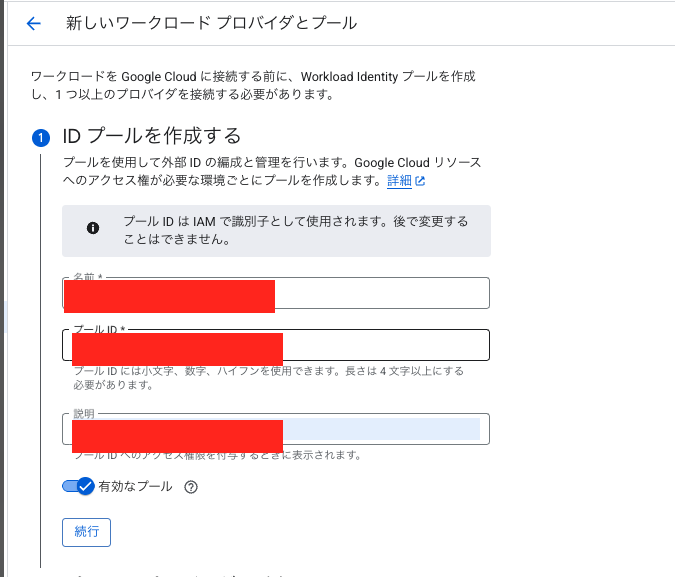
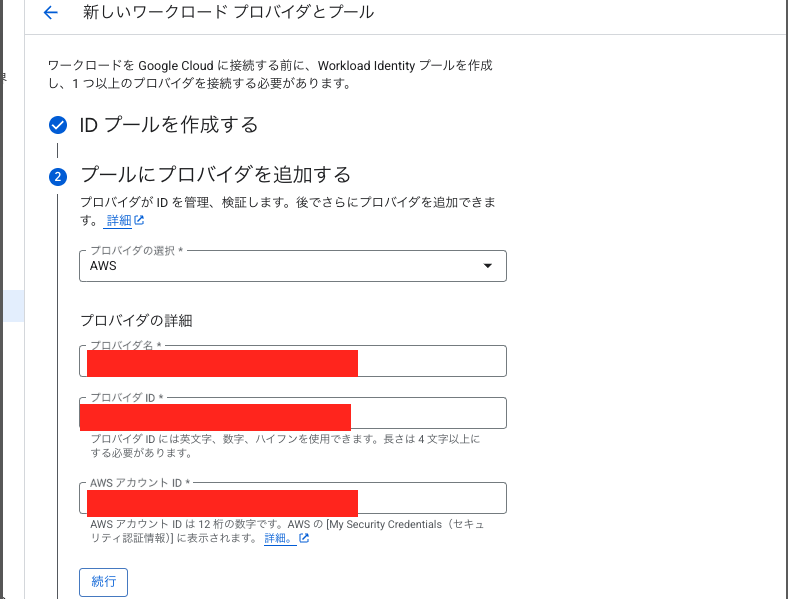
3.Workload Identity連携の設定
まず、Workload Identity プールを作成します。プロバイダの部分をAWSにし、AWSアカウントIDを入力するのがポイントです。
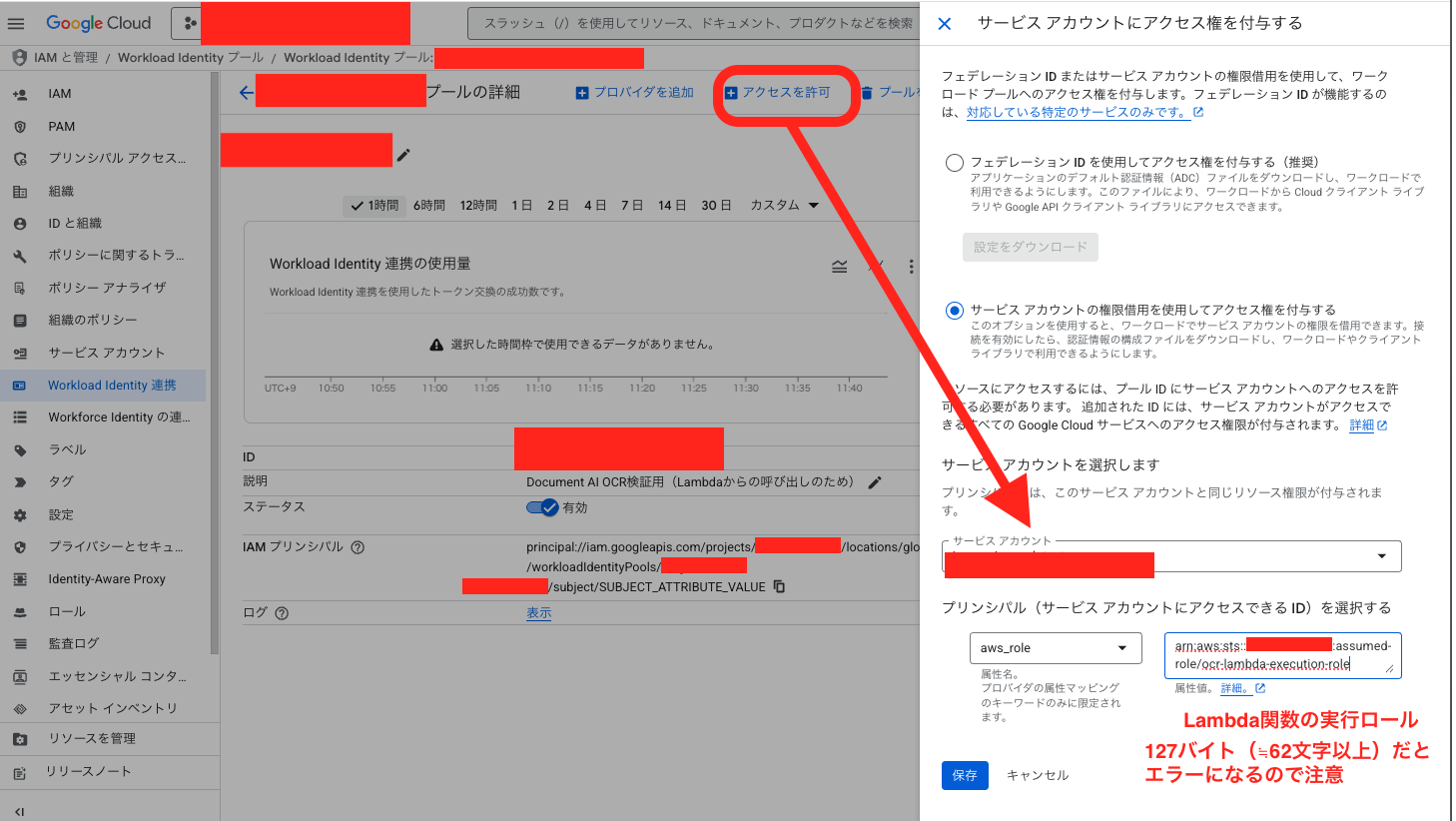
次に、作成したWorkload Identityプール内で、サービスアカウントにアクセス権の付与を行います。プリンシパル(サービスアカウントにアクセスできるID)はaws_roleを選択し、値にはDocument AIを呼び出したいLambdaの実行ロール名を指定してあげて、設定を保存します。
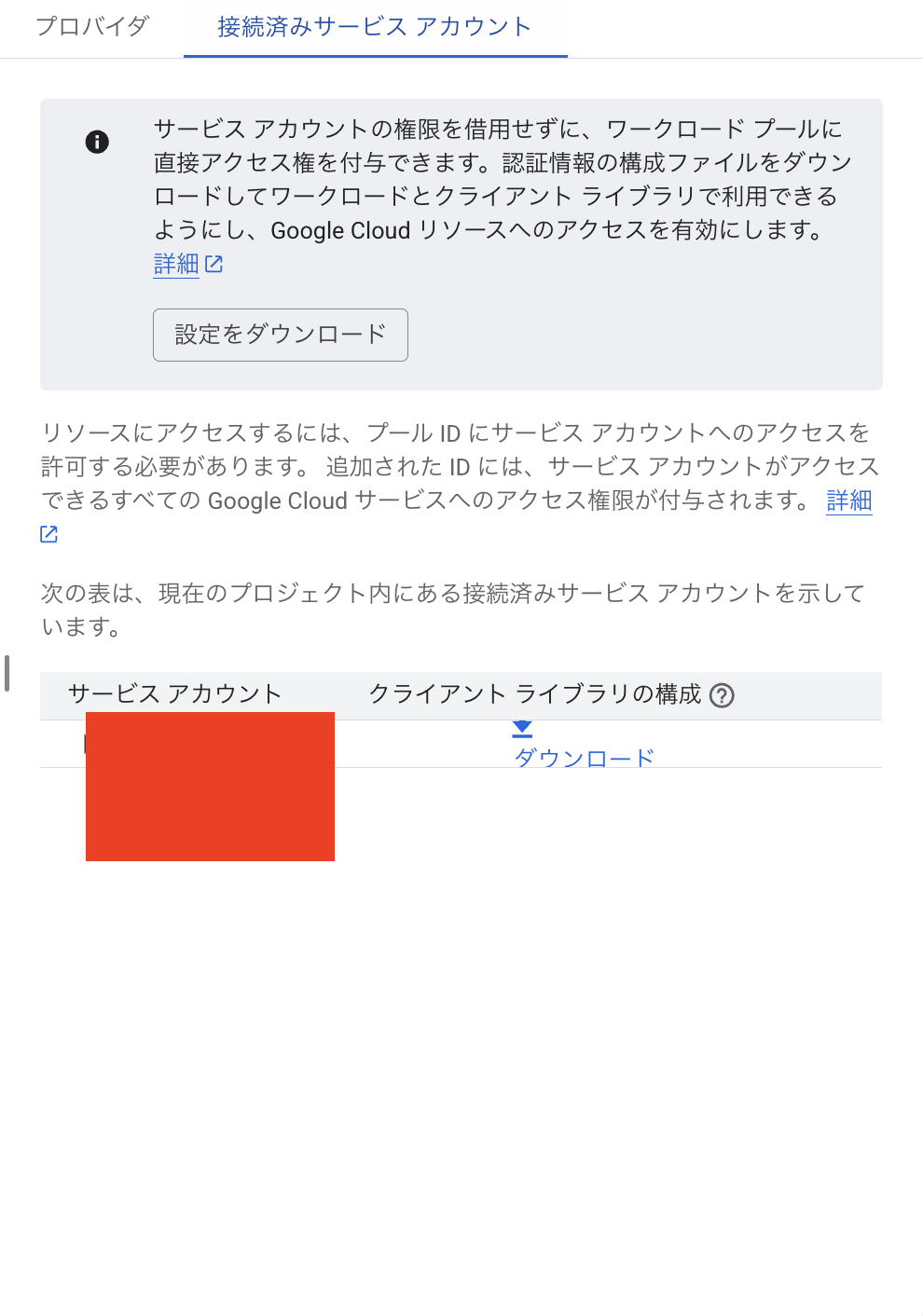
設定を保存後、Workload Identityプールから構成ファイル(clientLibraryConfig-<…>.json)をダウンロードします。このファイルをLambdaのデプロイパッケージに含め、GOOGLE_APPLICATION_CREDENTIALS環境変数でそのパスを指定することで、google-cloud-sdkが自動的に認証情報を読み込みます。
主要なロジック解説
Boxイベントを処理しS3に同期 (box_s3_sync/main.py)
Boxのファイル・フォルダイベントを検知し、そのイベントごとに処理分岐を行い、ファイル同期処理を行います。
実際の実装では、削除イベント、ファイル変更イベント・フォルダ削除イベントなど他のBoxのファイル/フォルダイベントに応じてS3の中身も合わせて同期する、という実装を行っていますが今回は単純化のためにファイルアップロード時の処理部分のみ以下にサンプルとして記載しています。
S3にファイル保存を行う際は、Boxの親フォルダの情報を取得しながら、Boxのフォルダ構造をそのまま維持したまま、S3に同期します。
Webhookイベントで取得できる情報については、Webhookペイロードに例が記載されているので、それを参考にします。具体的には、construct_s3_key関数の以下部分でアップロード先のS3キーを構築しています。path_collection.entries[]の中に親フォルダの情報が取れます。
path_collection = source_dict.get("path_collection", {})
entries = path_collection.get("entries", [])
# folderの場合のみfolder_ids[]に追加
folder_ids = [e["id"] for e in entries if e["type"] == "folder"]
# s3キーを構築
# NOTE folder_ids[]の中のidを/で連結し、s3キーを構築している
# 例folder_ids = ["123","456"] → 123/456
s3_key = f"{'/'.join(folder_ids)}/{source_dict['id']}"
if source_dict["type"] == "folder":
s3_key += "/"
return s3_key
S3にファイルが同期されたのち、EventBridgeで”Upload Completed”イベントを発行し、後続のLambdaを呼び出します。
※補足)メタデータファイルも合わせて同期しているのは、Kendra(検索サービス)のAttributeFilterを使用するためです。ここでは詳細の解説は割愛します。
main.py
import json
import boto3
from dateutil import parser
from datetime import timezone
from box_operation import download_box_file
from get_content_type import get_content_type
import config
import logger_util
# S3クライアント 初期化
s3_client = boto3.client("s3")
# EventBridge クライアント初期化
event_bridge_client = boto3.client('events')
# ロガーの設定
logger = logger_util.setup_logger()
def lambda_handler(event, context):
"""
Box Webhook通知を受け取り、以下イベントに応じて処理を行う関数
1.ファイルアップロード/フォルダ作成イベント(FILE.UPLOADED/FOLDER.CREATED)
2.ファイル更新イベント(FILE.UPLOADEDの中でさらに処理分岐)
3.ファイル削除イベント(FILE.TRASHED/FOLDER.TRASHED)
4.ファイル名変更・フォルダ名変更イベント(FILE.RENAMED/FOLDER.RENAMED)
:param Box webhookイベント
:return: None
"""
# Boxのファイル・フォルダ操作イベントを検知
logger.info("Lambda function started processing.")
logger.info(
f"Received event:\n{json.dumps(event, indent=2, ensure_ascii=False)}")
try:
# Boxのイベントによって、処理を振り分ける
# Box Webhookのペイロードを取得し、
# ファイルイベントかフォルダイベントで処理を分岐
payload = None
payload = json.loads(event["body"])
event_group, _ = payload["trigger"].split(".")
if event_group == "FILE":
process_file_events(payload)
elif event_group == "FOLDER":
process_folder_events(payload)
except Exception as e:
logger.error(f"Error processing webhook: {e}")
finally:
logger.info("BoxSyncFunction finished processing.")
def process_file_events(payload: dict) -> None:
"""
Box Webhookから取得したファイルイベントに基き、S3に対する同期処理を実施する関数
:param payload Box Webhookに設定したアドレスに向けて送信されるBoxイベント
:return None
"""
logger.info(
f"Processing file event: {payload['trigger']} for file {payload['source']['id']}")
# 発生したイベント種別を取得
trigger = payload["trigger"]
# 削除イベントかどうかの判定フラグ
is_delete_event = trigger == "FILE.TRASHED"
# s3キーの構築
s3_key = construct_s3_key(
payload["source"], is_delete_event=is_delete_event)
try:
if trigger == "FILE.UPLOADED":
# 更新/作成イベントの判定
created_at = parser.parse(payload["source"]["created_at"]).astimezone(
timezone.utc).isoformat()
last_updated_at = parser.parse(
payload["source"]["modified_at"]).astimezone(timezone.utc).isoformat(),
# ファイル作成イベントか、更新イベント(上書きアップロード)かを判定
# 作成時刻=更新時刻の場合は新規作成イベントとみなす
if created_at == last_updated_at:
logger.info("No existing file found. Treating as new upload.")
file_content = download_box_file(
payload['source']['id'])
content_type = get_content_type(payload['source']['name'])
upload_file(file_content, s3_key, content_type)
save_metadata(payload["source"], s3_key)
# それ以外はファイル更新(上書きアップロード)イベントとみなす
else:
logger.info(
"File version changed.Treating as version update.")
file_content = download_box_file(
payload['source']['id'])
content_type = get_content_type(payload['source']['name'])
upload_file(file_content, s3_key, content_type)
update_metadata(payload["source"], new_s3_key=None)
# ファイルアップロード完了タイミングで、"UploadCompleted"イベント発行
try:
logger.info("Publishing 'UploadCompleted'event.")
event_bridge_client.put_events(
Entries=[
{
'Source': 'custom.box',
'DetailType': 'UploadCompleted',
'Detail': json.dumps({
'box_file_id': payload['source']['id'],
'box_file_name': payload['source']['name'],
'category': get_parent_folder_name(payload['source']),
'created_at': created_at,
'last_updated_at': last_updated_at,
's3_key': s3_key
})
}
]
)
logger.info("Successfully Finished publishing 'UploadCompleted'event.")
except Exception as e:
logger.error(
f"An Error occurred when publishing 'UploadCompleted' event : {e}")
elif trigger == "FILE.TRASHED":
# S3ファイル削除・メタデータファイル削除処理が続くがここでは割愛
.....
elif trigger == "FILE.MOVED":
・・・・
# S3ファイル移動・メタデータファイル移動処理が続くがここでは割愛
# 他にも、実際の実装ではフォルダ移動イベントや、フォルダ削除イベントなどにも対応した処理を実装している
def construct_s3_key(source_dict: dict, is_delete_event: bool = False):
"""
S3キーを構築する関数
:param source_dict: Box APIから取得したファイルまたはフォルダのメタデータの辞書
- "id": ファイルまたはフォルダのID
- "type": "file" または "folder"
- "path_collection": 親フォルダの情報: (dict)
- "entries": 各フォルダの辞書リスト("id" と "type" を含む)
:param is_delete_event: 削除イベント(`FILE.TRASHED`, `FOLDER.TRASHED`) の場合は True
:return: S3のオブジェクトキー(フォルダの場合は末尾に "/" がつく)
"""
# 削除イベントでは、S3ドキュメントのメタデータから削除対象のs3ファイルのパスを取得する
if is_delete_event:
s3_key = get_original_s3_key_from_metadata(source_dict["id"])
return s3_key
path_collection = source_dict.get("path_collection", {})
entries = path_collection.get("entries", [])
# folderの場合のみfolder_ids[]に追加
folder_ids = [e["id"] for e in entries if e["type"] == "folder"]
# s3キーを構築
# NOTE folder_ids[]の中のidを/で連結し、s3キーを構築している
# 例folder_ids = ["123","456"] → 123/456
s3_key = f"{'/'.join(folder_ids)}/{source_dict['id']}"
if source_dict["type"] == "folder":
s3_key += "/"
return s3_key
def get_original_s3_key_from_metadata(box_id: str) -> str:
"""
Box の file_id/folder_idを元に、S3 メタデータから元の S3 キーを取得する関数
:param box_id: Box のファイル IDまたはフォルダID
:return: S3 の元のファイルパス (str) または None
"""
try:
# S3 内のメタデータ一覧を取得(ページネーション対応)
paginator = s3_client.get_paginator('list_objects_v2')
page_iterator = paginator.paginate(
Bucket=config.BUCKET_NAME,
Prefix=config.METADATA_FILE_PREFIX
)
# 各ページを処理
for page in page_iterator:
if "Contents" not in page:
continue
for obj in page["Contents"]:
if not obj["Key"].endswith(config.METADATA_FILE_SUFFIX): # メタデータファイルのみ対象
continue
metadata_obj = s3_client.get_object(
Bucket=config.BUCKET_NAME, Key=obj["Key"])
metadata = json.loads(
metadata_obj["Body"].read().decode("utf-8"))
# DocumentId に Box の file_id が含まれているかチェック
document_id = metadata.get("DocumentId", "")
# logger.info(f"document_id: {document_id}")
# ファイルIDで一致する場合
if document_id.endswith(f"/{box_id}"):
logger.info(f"Found file match for BoxId: {box_id}")
return document_id
# フォルダIDで一致する場合
if f"/{box_id}/" in document_id:
base_path = document_id.split(f"/{box_id}/")[0]
folder_path = f"{base_path}/{box_id}/"
logger.info(f"Found folder match for BoxId: {box_id}")
return folder_path
logger.warning(f"No DocumentId found for BoxId: {box_id}")
return None
except Exception as e:
logger.error(f"Error finding DocumentId for BoxId {box_id}: {e}")
return None
def save_metadata(source: dict, s3_key) -> None:
"""
Boxのファイルまたはフォルダのメタデータを保存する関数
:param source: BoxからのWebhookイベントペイロード
:return None
# NOTE _categoryは、Kendra検索で検索結果の絞り込みに使うフォルダ名となる。
# NOTE metadata/フォルダ配下に、Boxと同じ階層構造で保存する
# NOTE "TARGET_BOX_FOLDER_NAME"配下のフォルダ名を設定するようにしている
"""
logger.info(f"Saving metadata for {source['name']} to S3.")
try:
data = {
"DocumentId": f"s3://{config.BUCKET_NAME}/{s3_key}",
"Attributes": {
"_source_uri": f"{config.SOURCE_URI_PREFIX}file/{source['id']}",
"_category": get_parent_folder_name(source)
},
"Title": source["name"],
"created_at": parser.parse(source["created_at"]).astimezone(timezone.utc).isoformat(),
"last_updated_at": parser.parse(source["modified_at"]).astimezone(timezone.utc).isoformat(),
}
s3_client.put_object(
Bucket=config.BUCKET_NAME,
Key=construct_metadata_key(s3_key),
Body=json.dumps(data, ensure_ascii=False,
indent=2).encode("utf-8"),
)
logger.info(f"Metadata for {source['name']} saved successfully.")
except Exception as e:
logger.error(f"Error saving metadata for {source['name']}: {e}")
def get_parent_folder_name(source: dict) -> str:
"""
Boxのファイルやフォルダの親フォルダ名を取得する関数
:param source: BoxからのWebhookイベントペイロード
:return: "TARGET_BOX_FOLDER_NAME"フォルダ直下のフォルダ名(メタデータとして付与するカテゴリ名)
"""
try:
# path_collectionからフォルダ情報を取得
path_entries = source.get("path_collection", {}).get("entries", [])
logger.info(f"path_entries:{path_entries}")
# フォルダ情報が存在する場合
if path_entries:
# "TARGET_BOX_FOLDER_NAME"フォルダの直下のフォルダ名を取得
# そのために、"TARGET_BOX_FOLDER_NAME"フォルダのインデックスを見つける
sample_folder_index = None
for i, entry in enumerate(path_entries):
if entry["name"] == config.TARGET_BOX_FOLDER_NAME:
sample_folder_index = i
break
# TARGET_BOX_FOLDER_NAME直下のフォルダ名を取得
if sample_folder_index is not None and sample_folder_index + 1 < len(path_entries):
next_folder = path_entries[sample_folder_index + 1]
return next_folder.get("name", "Uncategorized")
# 存在しない場合、フォルダ名は"Uncategorized"とする
return "Uncategorized"
except KeyError:
return "Uncategorized"
initialize_box_client.py
from box_sdk_gen import BoxClient, BoxCCGAuth, CCGConfig
import os
import logger_util
# ロガーの設定
logger = logger_util.setup_logger()
def initialize_box_client():
"""
Boxクライアントを初期化する関数。
環境変数から認証情報を取得。
:param: None
:return: client Boxクライアント
"""
try:
ccg_config = CCGConfig(
client_id=os.getenv("BOX_CLIENT_ID"),
client_secret=os.getenv("BOX_CLIENT_SECRET"),
enterprise_id=os.getenv("BOX_ENTERPRISE_ID"),
)
auth = BoxCCGAuth(config=ccg_config)
client = BoxClient(auth=auth)
return client
except Exception as e:
logger.error(f"Failed to initialize box_client:{e}")
box_operation.py
import logger_util
from initialize_box_client import initialize_box_client
# ロガーの設定
logger = logger_util.setup_logger()
# Boxクライアントの初期化
client = initialize_box_client()
def download_box_file(box_file_id: str) -> dict:
"""
Boxのfile_idを元に、boxドキュメントの内容を取得する関数
:param: box_file_id Boxのfile_id
:return: None
"""
# Boxファイルをダウンロード
file_content = client.downloads.download_file(box_file_id).read()
return file_content
Document AIによるOCR処理 (transcription_by_document_ai.py)
Document AIによるOCR処理を実装するファイルです。
処理は以下のようなイメージです。全ての処理の解説は割愛しますが、以下が処理概要です。
- 0.”Upload Completed”イベントを受信。
check_pdf_text_extractionで、PDFに文字情報が存在しないと判定されたら、make_searchable_pdfを呼び出す- 文字情報が存在するPDF・PDF以外のファイルは処理の対象外
- 1.PDFをページごとに分割(
split_pdf_by_page)- Document AIによるOCR実行時、ファイルサイズに制約があるためページ分割してOCRを実施
- 2.各ページをDocument AI でOCR(
process_document_by_document_ai)- レスポンスはJSON形式で帰ってくる
- 3.Document AIのレスポンス(JSON)をhOCR形式に変換(
convert_docai_response_to_hocr)- Document AIからのDocument オブジェクトをhocr XML文字列に変換してくれる
document-ai-toolboxのツールボックス – ドキュメントを hOCR に変換するのサンプルを参照しました。
- Document AIからのDocument オブジェクトをhocr XML文字列に変換してくれる
- 4.OCRmyPDFの
hocrtransformメソッドを使い、hOCRからPDFに変換(convert_hocr_to_pdf)- 3.でhocrに変換されたOCR済のドキュメントを、
ocrmypdfのhocrtransformのなかに、PDF変換を行ってくれるメソッドがあるので、それを使います。(to_pdfメソッド参照)
- 3.でhocrに変換されたOCR済のドキュメントを、
- 5.処理済みのPDFを結合して(元のPDFに重ねて)検索可能なPDFを生成 (
merge_pdfs_with_pymupdf)- PDFの向きが横向きになっている場合は、ここで補正を入れる
main.py
import json
import os
from datetime import datetime, timezone
import boto3
import fitz
from transcription_by_document_ai import make_searchable_pdf
from common import config, logger_util
# S3クライアント 初期化
s3_client = boto3.client("s3")
# ロガーの設定
logger = logger_util.setup_logger()
def lambda_handler(event, context):
"""
ファイルの文字情報の有無を判定し、文字情報がないデータに対してはOCR処理を行い、S3に結果を再配置する関数
(前提)
BoxSyncFunctionの、FILE.UPLOADイベントの処理が完了し、S3にファイルを同期した時点で"Upload Completed"イベントをEventBridgeに通知
OCRFunctionは、そのEventを元に起動
"""
# EventBridgeからの"Upload Completedイベントで送信された"Detail"の情報を取得
detail = event["detail"]
logger.info(f"detail: {detail}")
box_file_id = detail["box_file_id"]
box_file_name = detail["box_file_name"]
category = detail["category"]
created_at = detail["created_at"]
last_updated_at = detail["last_updated_at"]
s3_key = detail["s3_key"]
logger.info(
f"Processing uploaded file: {box_file_name} (ID: {box_file_id}) at {s3_key}"
)
# 当該S3ファイルが、文字情報を持つか持たないかを判定する処理
# 処理対象はPDFに限定
head_response = s3_client.head_object(Bucket=config.BUCKET_NAME, Key=s3_key)
content_type = head_response.get("ContentType", "")
logger.info(f"content_type: {content_type}")
# `application/pdf` 以外ののファイル形式は判定処理の対象外
if content_type != "application/pdf":
logger.info("Skipping non-PDF file.")
return
# PDFの場合、S3から/tmp/にファイルをダウンロードする
local_file_path = f"/tmp/{os.path.basename(s3_key)}"
try:
s3_client.download_file(config.BUCKET_NAME, s3_key, local_file_path)
except Exception as e:
logger.error(f"Failed to download file from S3: {str(e)}")
# PDF内のテキスト情報の有無を判定
text_found = check_pdf_text_extraction(local_file_path)
# テキスト情報が存在する場合は処理終了
if text_found:
logger.info("Transcription is not required.")
return
# テキスト情報が存在しない場合はOCR処理に移行する
else:
logger.info("Transcription is required. Transcription started.")
# Document AI を使用してPDFを検索可能なPDFに変換する場合
logger.info("Proceeding with Document AI transcription for searchable PDF.")
try:
base_name = os.path.basename(s3_key)
file_name_without_ext = os.path.splitext(base_name)[0]
output_local_searchable_pdf_path = (
f"/tmp/{file_name_without_ext}_searchable.pdf"
)
logger.info(f"Generating searchable PDF for: {local_file_path}")
# make_searchable_pdf 関数を呼び出す
make_searchable_pdf(
input_path=local_file_path,
output_path=output_local_searchable_pdf_path,
)
logger.info(
f"Searchable PDF created locally: {output_local_searchable_pdf_path}"
)
# 生成された検索可能PDFをS3にアップロード
# 元々のS3キーと同じ名前で保存する
output_s3_key_searchable_pdf = s3_key
# S3に検索可能PDFをアップロード
s3_client.upload_file(
output_local_searchable_pdf_path,
config.BUCKET_NAME,
output_s3_key_searchable_pdf,
ExtraArgs={"ContentType": "application/pdf"},
)
logger.info(
f"Searchable PDF uploaded to S3: s3://{config.BUCKET_NAME}/{output_s3_key_searchable_pdf}"
)
# PDFのメタデータをアップロード
try:
data = {
"DocumentId": f"s3://{config.BUCKET_NAME}/{output_s3_key_searchable_pdf}",
"Attributes": {
"_source_uri": f"{config.SOURCE_URI_PREFIX}file/{box_file_id}",
"_category": category,
},
"Title": box_file_name,
"created_at": created_at,
"last_updated_at": datetime.now()
.astimezone(timezone.utc)
.isoformat(),
}
metadata_key = (
config.METADATA_FILE_PREFIX
+ output_s3_key_searchable_pdf
+ config.METADATA_FILE_SUFFIX
)
s3_client.put_object(
Bucket=config.BUCKET_NAME,
Key=metadata_key,
Body=json.dumps(data, ensure_ascii=False, indent=2).encode(
"utf-8"
),
)
logger.info(f"Metadata for {box_file_name} saved successfully.")
except Exception as e:
logger.error(f"Error saving metadata for {box_file_name}: {e}")
# 処理完了後、一時ファイルを削除
if os.path.exists(output_local_searchable_pdf_path):
os.remove(output_local_searchable_pdf_path)
logger.info(
f"Temporary searchable PDF deleted: {output_local_searchable_pdf_path}"
)
except Exception as e:
logger.error(f"Error during Document AI transcription: {str(e)}")
# 最後に、元のダウンロードファイルを削除
if os.path.exists(local_file_path):
os.remove(local_file_path)
logger.info(f"Temporary file {local_file_path} has been deleted.")
logger.info("OcrFunction finished processing.")
# 書き起こしを行うかの判定処理
def check_pdf_text_extraction(local_file_path: str) -> bool:
# 初期化
text_found = False
# PDFを開く
pdf_document = fitz.open(local_file_path)
for page_number in range(len(pdf_document)):
page = pdf_document[page_number]
# テキストを抽出
text = page.get_text()
if text.strip(): # 空でないテキストが見つかった場合
text_found = True
break # 文字が見つかったらループを終了
pdf_document.close()
logger.info(
f"{local_file_path} {'has' if text_found else 'does not have'} text data."
)
return text_found
document_ai_utils.py
"""
Document AIによるOCRで使用する関数
"""
import os
from pathlib import Path
from typing import List
import fitz
from google.cloud import documentai_v1 as documentai
from google.cloud.documentai_toolbox import document
from ocrmypdf import hocrtransform
from common import logger_util
# ロガーの設定
logger = logger_util.setup_logger()
# プロジェクトID・ロケーション・プロセッサIDを設定
project_id = os.getenv("GOOGLE_CLOUD_PROJECT")
location = "us"
processor_id = os.getenv("DOCUMENT_AI_PROCESSOR_ID")
# 環境変数の検証
if not project_id:
logger.error("GOOGLE_CLOUD_PROJECT environment variable is not set")
raise ValueError("GOOGLE_CLOUD_PROJECT environment variable is required")
if not processor_id:
logger.error("DOCUMENT_AI_PROCESSOR_ID environment variable is not set")
raise ValueError("DOCUMENT_AI_PROCESSOR_ID environment variable is required")
def detect_page_orientation(pdf_path: str, page_num: int = 0) -> dict:
"""
PDFページの向きと実際のコンテンツの向きを検出
Args:
pdf_path (str): PDFファイルのパス
page_num (int): 対象ページ番号(デフォルトは0、最初のページ)
Returns:
dict: {
'page_orientation': 'portrait' or 'landscape',
'rotation': 0, 90, 180, or 270,
'actual_orientation': 'portrait' or 'landscape' (回転を考慮した実際の向き)
}
"""
pdf = fitz.open(pdf_path)
page = pdf[page_num]
width = page.rect.width
height = page.rect.height
rotation = page.rotation
# ページの向き(回転前)
page_orientation = "landscape" if width > height else "portrait"
# 実際の向き(回転を考慮)
if rotation in [90, 270]:
# 90度または270度回転の場合、縦横が入れ替わる
actual_orientation = (
"portrait" if page_orientation == "landscape" else "landscape"
)
else:
actual_orientation = page_orientation
pdf.close()
return {
"page_orientation": page_orientation,
"rotation": rotation,
"actual_orientation": actual_orientation,
"width": width,
"height": height,
}
def process_document_by_document_ai(file_path: str) -> documentai.Document:
"""
Document AI によるOCR処理を行い、画像PDFをテキスト情報が埋め込まれたPDFに変換する関数
Args:
file_path (str): 処理対象のPDFファイルパス
Returns:
documentai.Document: Document AIの処理結果を含むDocumentオブジェクト
"""
# ページの向きを検出
orientation_info = detect_page_orientation(file_path)
logger.info(f"Document orientation: {orientation_info}")
client = documentai.DocumentProcessorServiceClient()
name = f"projects/{project_id}/locations/{location}/processors/{processor_id}"
with open(file_path, "rb") as f:
content = f.read()
request = documentai.ProcessRequest(
name=name,
raw_document=documentai.RawDocument(
content=content, mime_type="application/pdf"
),
)
result = client.process_document(request=request)
return result.document
def save_docai_response_to_json(
document_obj: documentai.Document, output_path: str
) -> None:
"""
Document AIレスポンスをJSONファイルとして保存する
Args:
document_obj (documentai.Document): Document AIの処理結果を含むDocumentオブジェクト
output_path (str): 出力するJSONファイルのパス
Returns:
None
"""
json_obj = documentai.Document.to_json(document_obj)
with open(output_path, "w", encoding="utf-8") as f:
f.write(json_obj)
def convert_docai_response_to_hocr(title: str, document_path: str) -> str:
"""
Document AI JSONからhOCR形式に変換する
Args:
title (str): ドキュメントのタイトル
document_path (str): Document AIの処理結果を含むJSONファイルのパス
Returns:
str: hOCR形式の文字列
"""
wrapped_doc = document.Document.from_document_path(document_path=document_path)
return wrapped_doc.export_hocr_str(title=title)
def split_pdf_page_by_page(input_path: str) -> List[str]:
"""
PDFファイルを1ページずつ分割し、個別ファイルとして/tmp/に保存する関数。
元々のPDFが回転しているかどうかの情報も保持する。
Args:
input_path (str): 入力PDFファイルパス。
Returns:
List[str]: 分割されたPDFファイルパスのリスト。
"""
logger.info(f"Splitting PDF page by page: {input_path}")
pdf = fitz.open(input_path)
chunk_files = []
base_file_name = Path(input_path).name.removesuffix(Path(input_path).suffix)
for i in range(len(pdf)):
chunk_path = str(Path("/tmp") / f"{base_file_name}_page{i + 1}.pdf")
page = pdf[i]
rotation = page.rotation
# ページの向きを判定(幅と高さから)
width = page.rect.width
height = page.rect.height
if width > height:
orientation = "landscape"
else:
orientation = "portrait"
logger.info(
f"Page {i + 1}: {width:.1f}x{height:.1f} pts, rotation={rotation}°, orientation={orientation}"
)
chunk_pdf = fitz.open()
chunk_pdf.insert_pdf(pdf, from_page=i, to_page=i)
# 回転情報を保持
if rotation != 0:
chunk_page = chunk_pdf[0]
chunk_page.set_rotation(rotation)
chunk_pdf.save(chunk_path)
chunk_pdf.close()
chunk_files.append(chunk_path)
pdf.close()
logger.info(f"PDF split into {len(chunk_files)} pages.")
return chunk_files
def merge_pdfs_with_pymupdf(pdf_files: List[str], output_path: str) -> None:
"""
複数のPDFファイルを結合する関数。
Args:
pdf_files (List[str]): 結合するPDFファイルのパスリスト。
output_path (str): 出力PDFファイルパス。
Returns:
None
"""
merger = fitz.open()
try:
for pdf_file in pdf_files:
pdf_doc = fitz.open(pdf_file)
try:
merger.insert_pdf(pdf_doc)
finally:
pdf_doc.close()
merger.save(output_path)
finally:
merger.close()
def convert_hocr_to_pdf(
hocr_path: str, background_pdf_path: str, output_pdf_path: str, dpi: int = 300
) -> None:
"""
hOCRファイルから透明テキストレイヤーを作成し、背景PDFと合成する
Args:
hocr_path (str): hOCRファイルパス
background_pdf_path (str): 背景PDFファイルパス
output_pdf_path (str): 出力PDFファイルパス
dpi (int, optional): 解像度(デフォルト300)
"""
ocr_only_pdf_path = str(Path(output_pdf_path).with_suffix(".ocr_only.pdf"))
# 背景PDFのサイズを取得
bg_doc = fitz.open(background_pdf_path)
bg_page = bg_doc[0]
bg_width = bg_page.rect.width
bg_height = bg_page.rect.height
bg_rotation = bg_page.rotation
bg_doc.close()
logger.info(
f"Background PDF: {bg_width:.2f}x{bg_height:.2f} pts, rotation={bg_rotation}°"
)
logger.info(f"Using DPI: {dpi}")
# hOCRをPDFに変換
transformer = hocrtransform.HocrTransform(hocr_filename=Path(hocr_path), dpi=dpi)
transformer.to_pdf(out_filename=Path(ocr_only_pdf_path))
# 生成されたOCR PDFのサイズを確認し、必要に応じて調整
ocr_doc = fitz.open(ocr_only_pdf_path)
ocr_page = ocr_doc[0]
ocr_width = ocr_page.rect.width
ocr_height = ocr_page.rect.height
logger.info(f"Generated OCR PDF: {ocr_width:.2f}x{ocr_height:.2f} pts")
# サイズが異なる場合は、新しいPDFを作成して正確なサイズに調整
if abs(ocr_width - bg_width) > 0.1 or abs(ocr_height - bg_height) > 0.1:
logger.info("Adjusting OCR PDF size to match background")
adjusted_doc = fitz.open()
adjusted_page = adjusted_doc.new_page(width=bg_width, height=bg_height)
# OCRページを新しいページに配置(サイズを合わせる)
adjusted_page.show_pdf_page(adjusted_page.rect, ocr_doc, 0)
# 調整されたPDFを保存
adjusted_path = str(Path(ocr_only_pdf_path).with_suffix(".adjusted.pdf"))
adjusted_doc.save(adjusted_path)
adjusted_doc.close()
ocr_doc.close()
# 元のOCR PDFを削除して調整済みのものに置き換え
Path(ocr_only_pdf_path).unlink()
Path(adjusted_path).rename(ocr_only_pdf_path)
logger.info(f"OCR PDF size adjusted to: {bg_width:.2f}x{bg_height:.2f} pts")
else:
ocr_doc.close()
merge_background_and_ocr(background_pdf_path, ocr_only_pdf_path, output_pdf_path)
logger.info(f"背景と透明テキストを合成完了: {output_pdf_path}")
Path(ocr_only_pdf_path).unlink(missing_ok=True)
def merge_background_and_ocr(
background_pdf_path: str, ocr_text_pdf_path: str, output_pdf_path: str
) -> None:
"""
背景PDFと透明テキストレイヤーPDFを合成する
Args:
background_pdf_path (str): 背景PDFパス
ocr_text_pdf_path (str): 透明テキストPDFパス
output_pdf_path (str): 出力PDFパス
"""
bg_doc = fitz.open(background_pdf_path)
ocr_doc = fitz.open(ocr_text_pdf_path)
for page_num in range(len(bg_doc)):
bg_page = bg_doc[page_num]
ocr_page = ocr_doc[page_num]
# 回転情報をログ出力
logger.info(
f"Page {page_num + 1} - BG rotation: {bg_page.rotation}°, OCR rotation: {ocr_page.rotation}°"
)
# ページサイズ情報をログ出力
logger.info(f"BG page size: {bg_page.rect.width}x{bg_page.rect.height}")
logger.info(f"OCR page size: {ocr_page.rect.width}x{ocr_page.rect.height}")
# ページの向きを判定
bg_width = bg_page.rect.width
bg_height = bg_page.rect.height
is_landscape = bg_width > bg_height
# 背景ページに回転がある場合の処理
if bg_page.rotation == 270:
# 270度回転の場合:OCRページを270度回転させて配置
logger.info(
f"270° rotation page - {'landscape' if is_landscape else 'portrait'} orientation"
)
# サイズが同じになっているはずなので、そのまま配置
bg_page.show_pdf_page(
bg_page.rect, ocr_doc, page_num, rotate=270, overlay=True
)
elif bg_page.rotation == 90:
# 90度回転の場合
logger.info(
f"90° rotation page - {'landscape' if is_landscape else 'portrait'} orientation"
)
bg_page.show_pdf_page(
bg_page.rect, ocr_doc, page_num, rotate=90, overlay=True
)
elif bg_page.rotation == 180:
# 180度回転の場合
logger.info(
f"180° rotation page - {'landscape' if is_landscape else 'portrait'} orientation"
)
bg_page.show_pdf_page(
bg_page.rect, ocr_doc, page_num, rotate=180, overlay=True
)
else:
# 回転がない場合は通常通り合成
logger.info(
f"No rotation - {'landscape' if is_landscape else 'portrait'} orientation"
)
bg_page.show_pdf_page(bg_page.rect, ocr_doc, page_num, overlay=True)
bg_doc.save(output_pdf_path, garbage=4, deflate=True)
bg_doc.close()
ocr_doc.close()
実装で苦戦したポイントとその解決策
上記実装時、苦戦した点について以下に記載します。
- Box-S3同期
- Boxのwebhookイベントで取得できる情報から、S3と同じパスを構築して同期するのに少し頭を捻りました。
- イベントごとにwebhookで取得できる情報に差異があり、実装時少し工夫が必要でした。
- 例えば、FILE.UPLOADイベントでは、アップロードされたファイルの親フォルダの情報が取れてくるのですが、FILE.TRASHEDイベントでは、親フォルダのIDが取得できませんでした。
- →そのため、S3に別途保存しておいたメタデータファイルを活用しました。BoxのファイルIDをキーにS3上のメタデータを検索し、そこからS3オブジェクトキーを特定して削除するロジックを実装しました。
- Workload Identity連携
The size of mapped attribute google.subject exceeds the 127 bytes limit. Either modify your attribute mapping or the incoming assertion to produce a mapped attribute that is less than 127 bytes.
- 上記のエラーの解決に苦戦しました。
- 結論、AWSロール名のarnが127bytes以上(≒62文字)であるとエラーが出てしまうことが分かりました。そのため、template.yamlで作成するLambdaの実行ロール名を短くすることで解決しました。(参照) -
デプロイパッケージが大きすぎてそのままでは
sam buildに失敗してしまう(下記エラー)resource handler returned message: “Unzipped size must be smaller than 262144000 bytes (Service: Lambda, Status Code: 400, Request ID: XXXXXXX)
ocrmypdfのような巨大なパッケージを使用する場合、ECR経由でのビルド・デプロイをする必要がありました。- 理由:デプロイパッケージはZip形式の場合展開前50MB、展開後は250MB以下にする必要がある、という制限があるため。
- コンテナを利用してデプロイする場合は、上限が10GBまで緩和されます。そのため、ECR経由でのデプロイを利用しました。(参照)
この場合、samconfig.tomlのimage_repositoriesの配列に、Lambda関数と、パッケージを格納するリポジトリを指定してあげてsam deployをする必要があります。また、template.yamlで、対象の関数のPackageType: Imageを指定する必要があります。※指定しない場合は(Zip形式が選択される)
- コンテナを利用してデプロイする場合は、上限が10GBまで緩和されます。そのため、ECR経由でのデプロイを利用しました。(参照)
- 理由:デプロイパッケージはZip形式の場合展開前50MB、展開後は250MB以下にする必要がある、という制限があるため。
samconfig.toml
[default.deploy.parameters]
image_repositories = [
"
]
(参考)template.yaml
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
box-s3-sync
Sample SAM Template for box-s3-sync
# More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst
Globals:
Function:
Timeout: 30
MemorySize: 128
Resources:
LambdaLayer:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: layer
ContentUri: layers/common_layer/python
CompatibleRuntimes:
- python3.12
Metadata:
BuildMethod: python3.12
BoxSyncLambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
RoleName: box-sync-lambda-execution-role
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: BoxSyncLambdaPolicy
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- "logs:CreateLogGroup"
- "logs:CreateLogStream"
- "logs:PutLogEvents"
- "logs:DescribeLogStreams"
Resource: "arn:aws:logs:*:*"
- Effect: Allow
Action:
- "s3:GetObject"
- "s3:PutObject"
- "s3:DeleteObject"
Resource:
- "arn:aws:s3:::your-s3-bucket-name/*"
- Effect: Allow
Action:
- "s3:ListBucket"
Resource:
- "arn:aws:s3:::your-s3-bucket-name"
- Effect: Allow
Action:
- events:PutEvents
Resource: !Sub "arn:aws:events:${AWS::Region}:${AWS::AccountId}:event-bus/default"
OcrLambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
RoleName: ocr-lambda-execution-role
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: OcrLambdaPolicy
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- "logs:CreateLogGroup"
- "logs:CreateLogStream"
- "logs:PutLogEvents"
- "logs:DescribeLogStreams"
Resource: "arn:aws:logs:*:*"
- Effect: Allow
Action:
- "s3:GetObject"
- "s3:PutObject"
- "s3:DeleteObject"
Resource:
- "arn:aws:s3:::your-s3-bucket-name/*"
- Effect: Allow
Action:
- "s3:ListBucket"
Resource:
- "arn:aws:s3:::your-s3-bucket-name"
LambdaInvokePermission:
Type: AWS::Lambda::Permission
Properties:
Action: "lambda:InvokeFunction"
FunctionName: !Ref OcrFunction
Principal: "events.amazonaws.com"
SourceArn: !GetAtt EventBridgeTrigger.Arn
BoxSyncFunction:
Type: AWS::Serverless::Function
Properties:
Handler: main.lambda_handler
Runtime: python3.12
CodeUri: src/box_s3_sync/
Timeout: 900 # 15 minutes
MemorySize: 1024
FunctionUrlConfig:
AuthType: NONE
Role: !GetAtt BoxSyncLambdaExecutionRole.Arn
Layers:
- !Ref LambdaLayer
Environment:
Variables:
S3_BUCKET_NAME: "your-bucket-name"
BOX_CLIENT_ID: "your-box-client-id"
BOX_CLIENT_SECRET: "your-box-client-secret"
BOX_ENTERPRISE_ID: "your-box-enterprise-id"
BOX_FOLDER_ID: "your-box-folder-id"
OcrFunction:
Type: AWS::Serverless::Function
Properties:
PackageType: Image
ImageConfig:
Command: ["main.lambda_handler"]
Timeout: 900 # 15 minutes
MemorySize: 2048
Role: !GetAtt OcrLambdaExecutionRole.Arn
Environment:
Variables:
GOOGLE_APPLICATION_CREDENTIALS: "./clientLibraryConfig-<your-google-cloud-project-name>.json"
GOOGLE_CLOUD_PROJECT: "your-google-cloud-project-id"
DOCUMENT_AI_PROCESSOR_ID: "your-document-ai-ocr-processor-id"
Metadata:
Dockerfile: src/validate_file/Dockerfile
DockerContext: .
DockerTag: latest
EventBridgeTrigger:
Type: AWS::Events::Rule
Properties:
EventPattern:
source:
- "custom.box"
detail-type:
- "UploadCompleted"
Targets:
- Arn: !GetAtt OcrFunction.Arn
Id: "TriggerOfOcrFunction"
Outputs:
BoxSyncFunctionUrlEndpoint:
Description: "BoxSyncFunction URL endpoint"
Value: !GetAtt BoxSyncFunctionUrl.FunctionUrl
- PDF内のページ回転への対応
- OCR対象のPDFには、途中のページが横向きに回転しているものが存在しました。これを考慮しないと、OCR結果のテキスト位置がずれてしまいます。(画像のように、縦向きにテキストが入ってしまう※都合上、PDFの中身は隠しています)
- 暫定的な解決策として、PyMuPDF (fitz) を使ってPDFをページ単位に分割する際に、各ページの回転角度(page.rotation)を検出し、保持するようにしました。OCR後のPDFを再構築する際も、この回転情報を反映させることで、向きが正しい検索可能PDFを生成できました。
おわりに
Box、AWS Lambda、Google Cloud Document AIを組み合わせ、Boxにアップロードされた画像PDFを自動でOCR処理し、S3に同期する方法について、具体的な実装にフォーカスして解説しました。実装はやや複雑ですが、「画像PDFであるがためにPDFがRAGのデータソースとして使えない」問題の解消にはつながりそうです。




