
はじめに
新卒2年目CI事業部ソリューション開発セクション所属の荒木がお伝えする、AWSサーバーレスサービスについてまとめた記事です!
今回このサービスを取り上げた経緯として、元々AWSサーバーレスサービスに興味がありぜひ使ってみたい!
と思ったため記事を利用してアウトプットしました。興味を持ったきっかけとして、AWSの試験勉強(DVA・DOP等)をしている最中にさまざまなサーバーレスサービスを学習してきましたが、その中でも「AppSync」というサーバーレスサービスについてまだ使用したことがなく、「GraphQLがどうたらって試験問題に書いてるけど、全然イメージできないなあ、便利なのかな?」と思い、「AppSync」について触ってみることにしました!
まずはサービスの概要について説明していきたいと思います。
AppSyncサービス概要
以下「AppSync」についてAWS公式ドキュメントからの引用です。
AWS AppSync を使用すると、開発者は安全でサーバーレスで高性能な GraphQL および Pub/Sub API を使用して、アプリケーションやサービスをデータやイベントに接続できます
これだけではわからないですね。。。
GraphQLって?アプリケーションやサービスを、データやイベントに接続できるのはAPIGateway+Lambdaでもできるのでは?となったので、「AppSync」を扱う上でおさえておきたい各ワードについて解説していきます!
AWS AppSyncについて用語解説
より具体的な解説や使用方法は後述しているので、ここでは用語解説のみに収めます!
GraphQL
APIのクエリ言語であり、APIを作成する過程でスキーマとリゾルバー(後述)を主に設定していきます。
スキーマ
以下はAWS公式ドキュメントから引用した「スキーマ」についての説明です。
GraphQL スキーマは GraphQL API の基盤です。データの形状を定義する設計図として機能します。
また、データの取得方法や変更方法を定義する、クライアントとサーバー間の契約でもあります。
プロジェクトで最初に作成するものの1つです。
スキーマを作成するには「type」「フィールド」という2つの書き方に沿って記述していく必要があります。
type
typeとはデータの形状や操作を記述する大枠です。
ここにDBにクエリをかけたいときや、データを入れたいとき、AppSyncに記述していきます。
ユーザー情報をDynamoDBに格納・参照するAPIを例のコードと合わせてイメージしましょう!
スキーマの中でtypeを利用すると以下の様に使用できます!
type Post {
user_id: ID!
user_address: String!
}
type Mutation {
addPost(user_id: ID!, user_address: String!): Post!
}
type Query {
getPost(user_id: ID): Post
}
schema {
query: Query
mutation: Mutation
}
type Post = type Postとはユーザー定義の名前です。ここでは後述するQueryやMutationで扱うオブジェクトの形状を定義しています
type Query = RESTfulのGETにあたる操作を記述する箇所です。データを参照したい際にこのtypeを記述します。
type Mutation = RESTfulのPUT,POSTにあたる操作を記述する箇所です。データの追加・更新・削除が必要な際にこのtypeを記述します。
フィールド
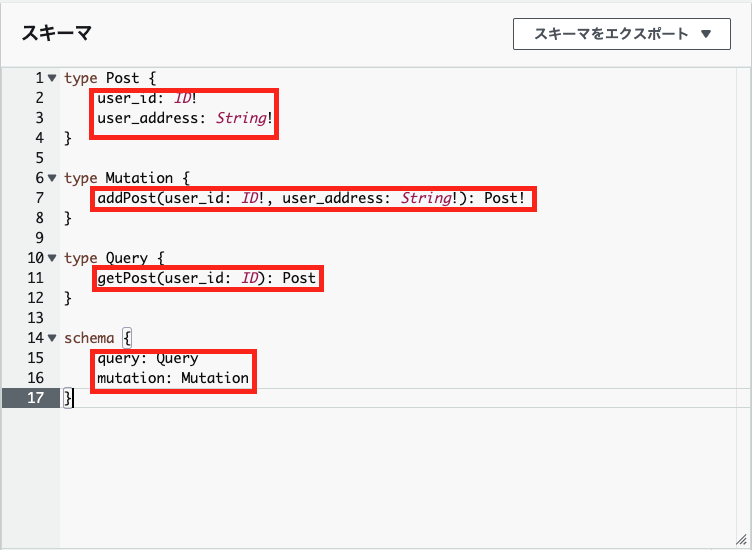
typeの中に記述される各行データのことです。
キャプチャの赤枠がフィールドに該当します。
色々なドキュメントを見ている中で「フィールドってどれだろう、、、」となってたので理解するまで苦戦していました。
リゾルバー
スキーマの各フィールドにリゾルバーという関数を割り当てます。
リゾルバーにはデータソースに対する具体的な処理内容を記述していきます。
データソース
DynamoDBなどクライアントからのデータの参照先のことです。
データソースって名前からも想像のつくように、AppSyncからみたデータの保存先です。
ここからは、従来のREST APIとAppSyncでAPIを実装する場合の違いを比較しながら理解していきましょう!
従来のREST API
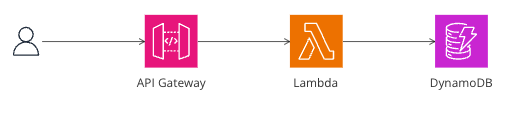 画像のような構成が一般的ですよね。作成にはこちらの手順を参照しました!
画像のような構成が一般的ですよね。作成にはこちらの手順を参照しました!
DynamoDBでテーブルを作成し、Lambdaを実装、APIGatewayでAPI化するといったいつもの手順です。
DynamoDBにputitemするだけのLambdaコードはさんざん書かれ尽くしていますが、添付しておきます。
今回はこの構成に関しての説明はメインコンテンツではないので割愛します。
import json
import boto3
from decimal import Decimal
client = boto3.client('dynamodb')
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table('user')
tableName = 'user'
def lambda_handler(event, context):
#print(event)
body = {}
statusCode = 200
headers = {
"Content-Type": "application/json"
}
try:
if event['routeKey'] == "PUT /users":
requestJSON = json.loads(event['body'])
table.put_item(
Item={
'user_id': requestJSON['user_id'],
'user_address': requestJSON['user_address']
})
body = 'Put item ' + requestJSON['id']
except KeyError:
statusCode = 400
body = 'Unsupported route: ' + event['routeKey']
body = json.dumps(body)
res = {
"statusCode": statusCode,
"headers": {
"Content-Type": "application/json"
},
"body": body
}
return res
GraphQLを利用したAPI
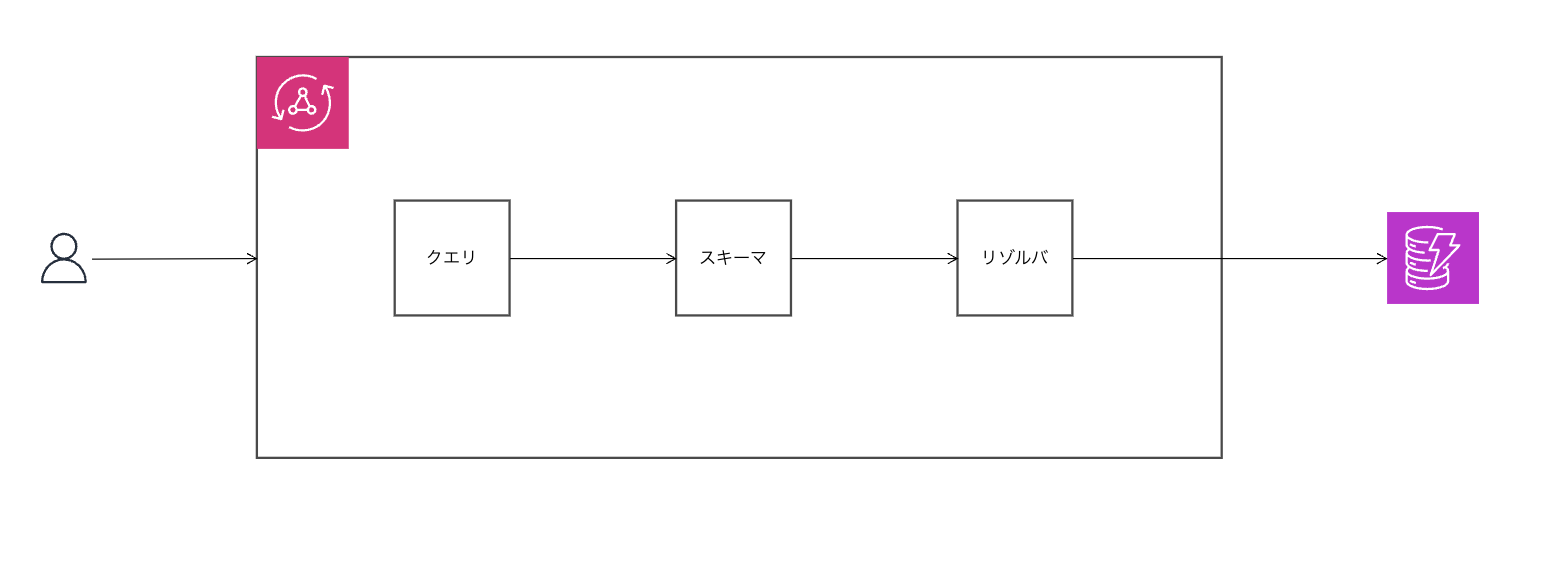 AWS上でGraphQLを利用したAPIを実装すると、ざっくりとは上記のような構成となります。
AWS上でGraphQLを利用したAPIを実装すると、ざっくりとは上記のような構成となります。
ユーザーがDynamoDBに格納したい値をクエリに投げ、スキーマ内でデータ格納用のMutation処理を定義しておき、定義済みのMutation処理にリゾルバを関連付けることでデータ格納までのフローが成立します。
DynamoDBにputitemするだけの処理ですが、参考にしたドキュメントはこちらです。
ドキュメントを参考に実装していったのですが、図解するまでどのように処理されていくのかまったくイメージできず処理順を理解できても今度は各工程の役割も整理できず大変でしたが、1つ1つ処理順を追って解説していきます!
クエリ
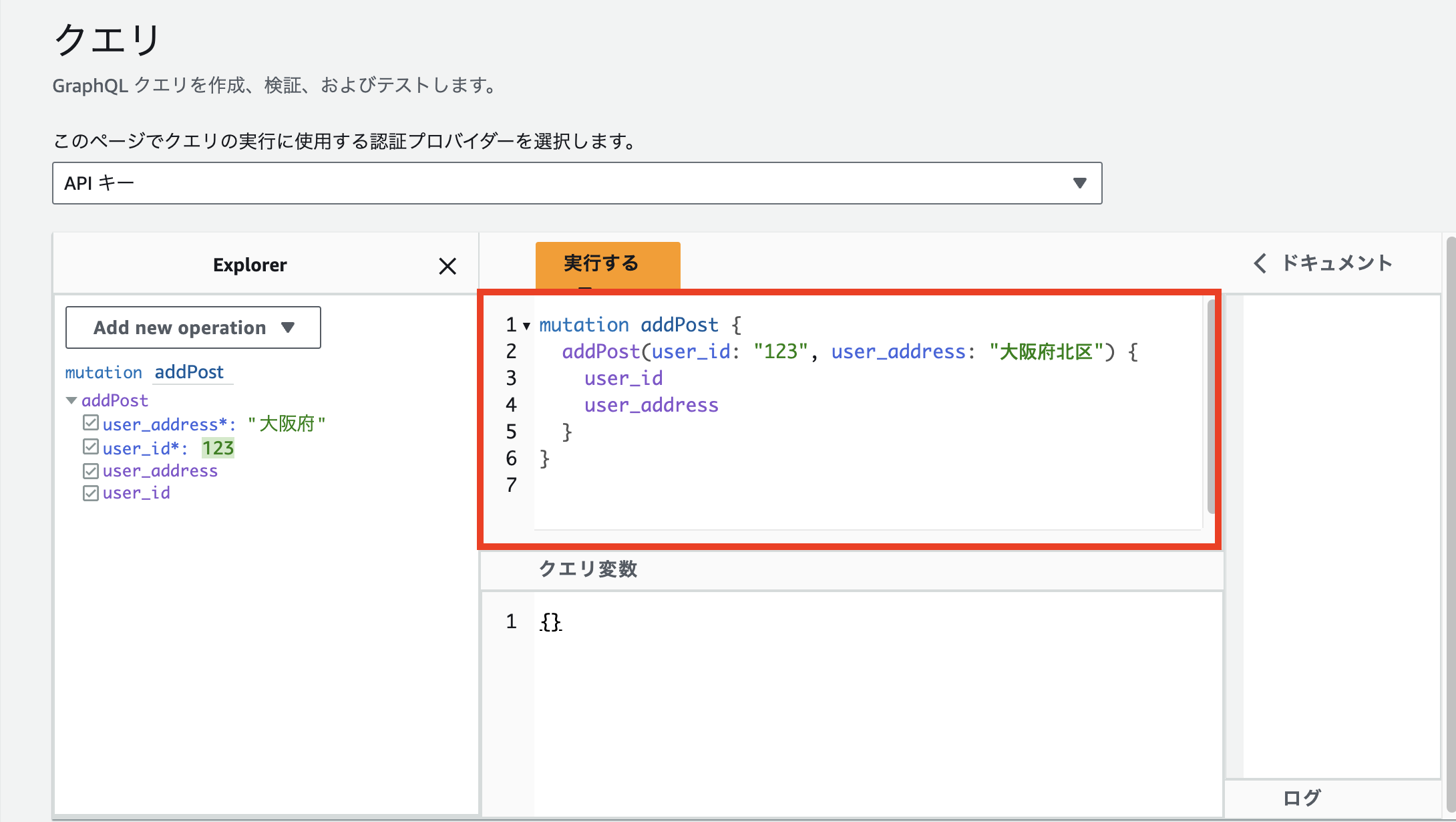
先ずクエリでどのような値をスキーマに投げるかを記述します。
キャプチャ赤枠はスキーマに記述されたMutation処理である「addPost」にクエリを投げる例です。
Mutation処理は、データの追加・更新・削除が必要な際に記述する必要があります。
スキーマ
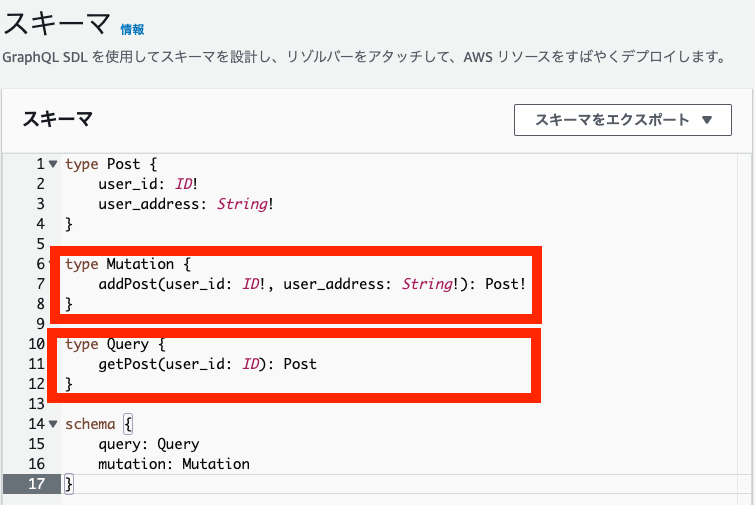
スキーマではスキーマ定義言語(SDL(Schema Definition Language))を用いてAPIの仕様を定義していきます。
スキーマ内には作成するAPIのクエリ内容を実際に記述していくため、API仕様書のようになります。
注目してほしいのは赤枠の内容で、スキーマ全体を通してQueryとMutationが利用可能なことを宣言しており、「type Mutation」オブジェクトではフィールド内でMutation処理「addPost」を定義しています。
スキーマ内でMutation処理のようなデータ操作処理があることを明記しておくことで、API仕様書を確認せず、APIの仕様について理解できるようなメリットがあります。
リゾルバー

次に、リゾルバーからデータソース(DynamoDB)に対しての具体的な処理を記述します。
リゾルバーを個々のMutationにリンクすることで、データソースに対してオペレーションを実行して GraphQL リクエストに応答できるようにしています!
今回はJavascriptでリゾルバーを記述しています。概要については以下のドキュメントから。
(JavaScript リゾルバーの概要)
APIをLambda実装とAppSync実装メリデメ比較
ここまで、APIの実装方法として従来のREST APIとAppSyncを比較して紹介してきましたが、比較して来たうえで両者のメリット・デメリットについてもまとめてみようと思います。
| APIGW+Lambda | AppSync | |
| メリット |
|
|
| デメリット |
|
|
両者のユースケースについて
メリデメについて比較を終えたうえで、両者のメリデメを活かしたユースケースについてもまとめておきます。
| APIGateway+Lambda | AppSync | |
| ユースケースについて |
|
|
感想など
学習時間が短かったとはいえ、AppSyncがリアルタイム処理に適しているのでチャットの実装などに使用してみるのもいいと思いました!AWS AppSyncの公式事例を見てみても、リアルタイム性を問われる要件に対してAppSyncが使用されている印象です。サーバレスなのでアクセス数が多い場合にもスケールして処理できるのがカーナビや、ストリーミング系のサービスに向いてると思いました。ただ、それだったらわざわざマネージドサービスを使用する意味がわからないので、開発エンジニアですが将来的にはインフラの知見もある程度理解できるように今後はインフラ系のサービスも意識して学習していきたいです。

