これは何?
Datadog でサーバーをモニタリングして最終的にコスト最適化を試したのでその結果を記した記事です!
具体的には EC2 インスタンスの情報をモニタリングして、サーバーの Apache や php-fpm のチューニングを行い、インスタンスサイズを調整してその結果 コスト最適化 させる流れになります。
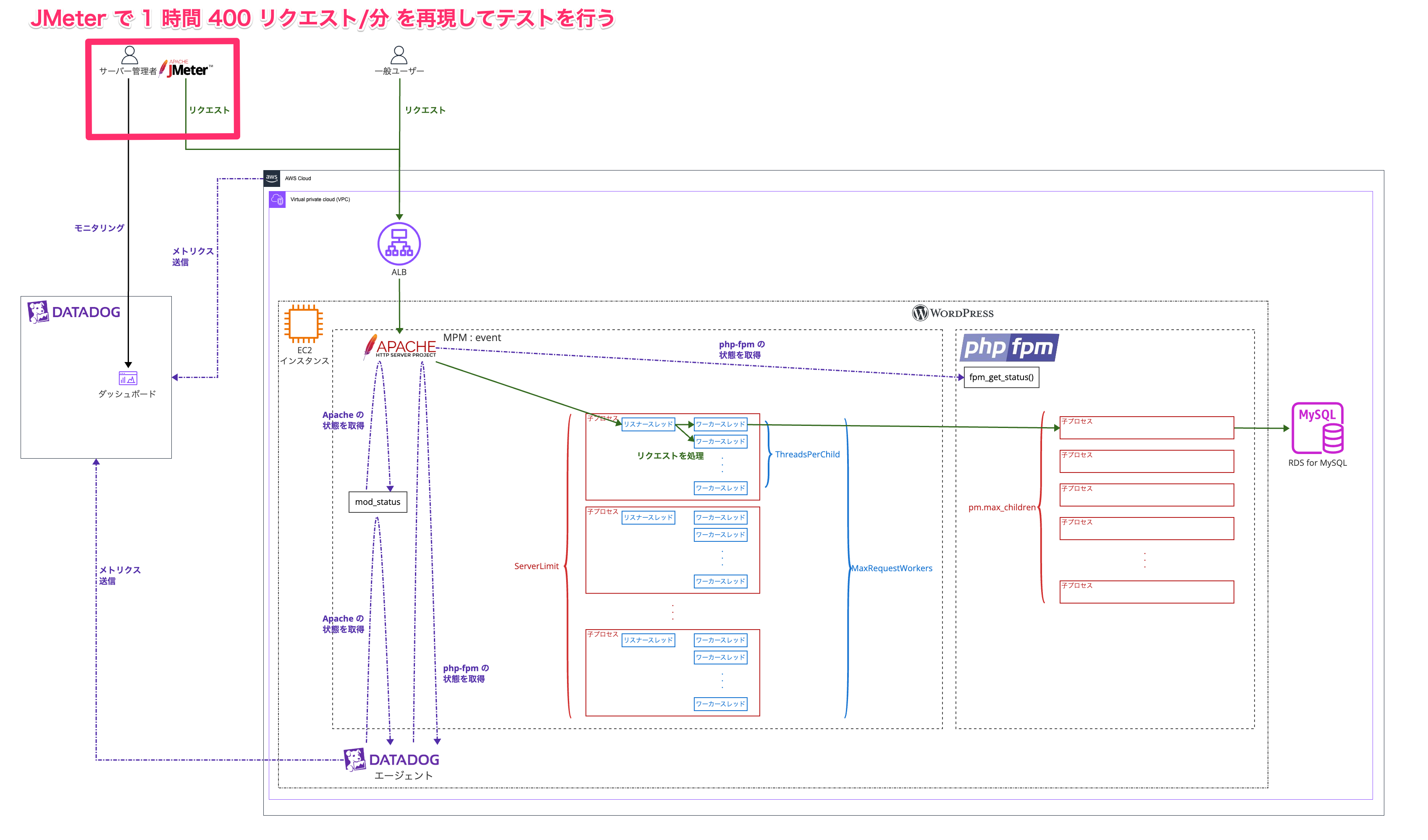
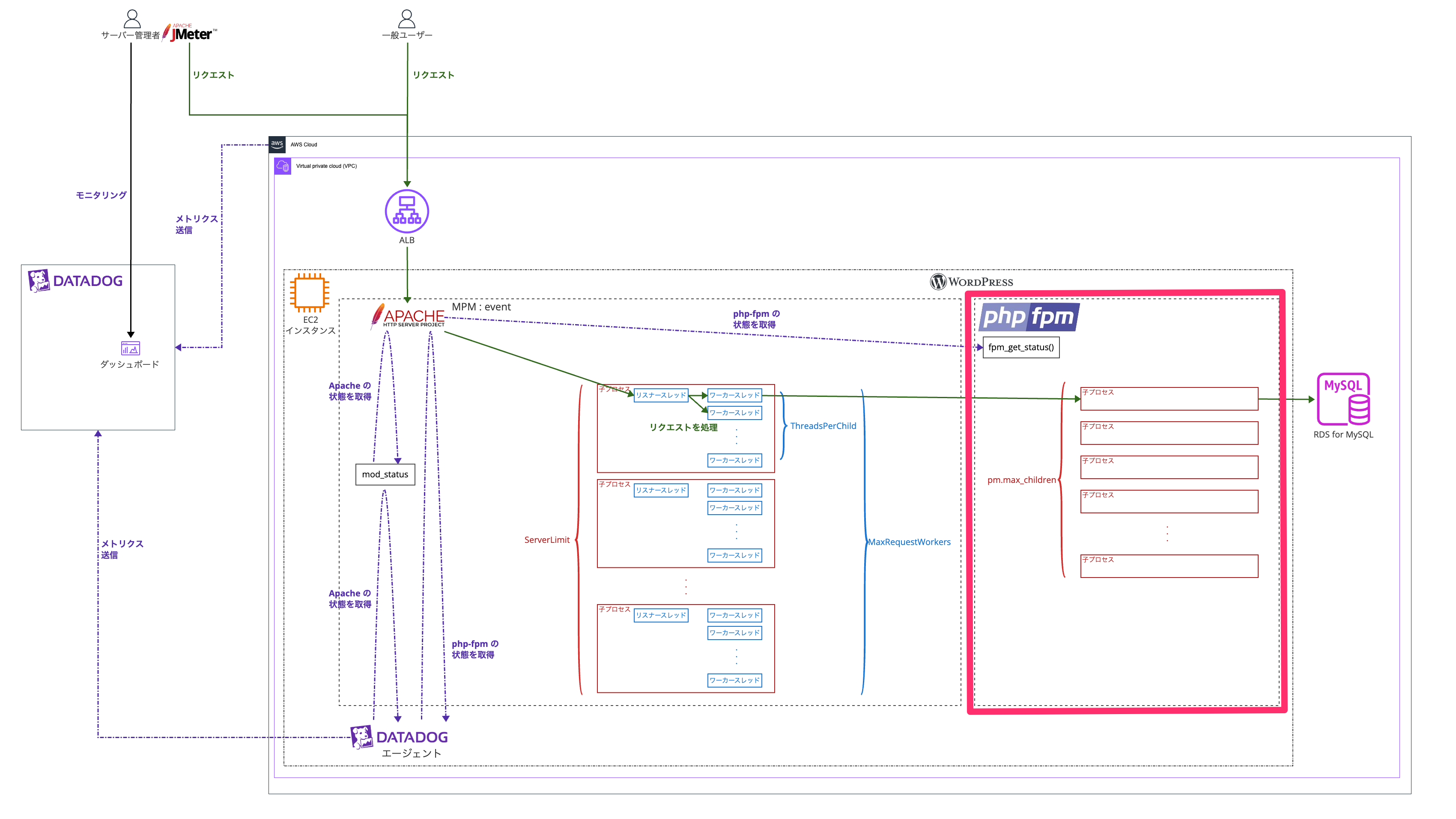
構成図
理解しやすくなると思うので最終的な状態の構成図を先に見ていただきます!
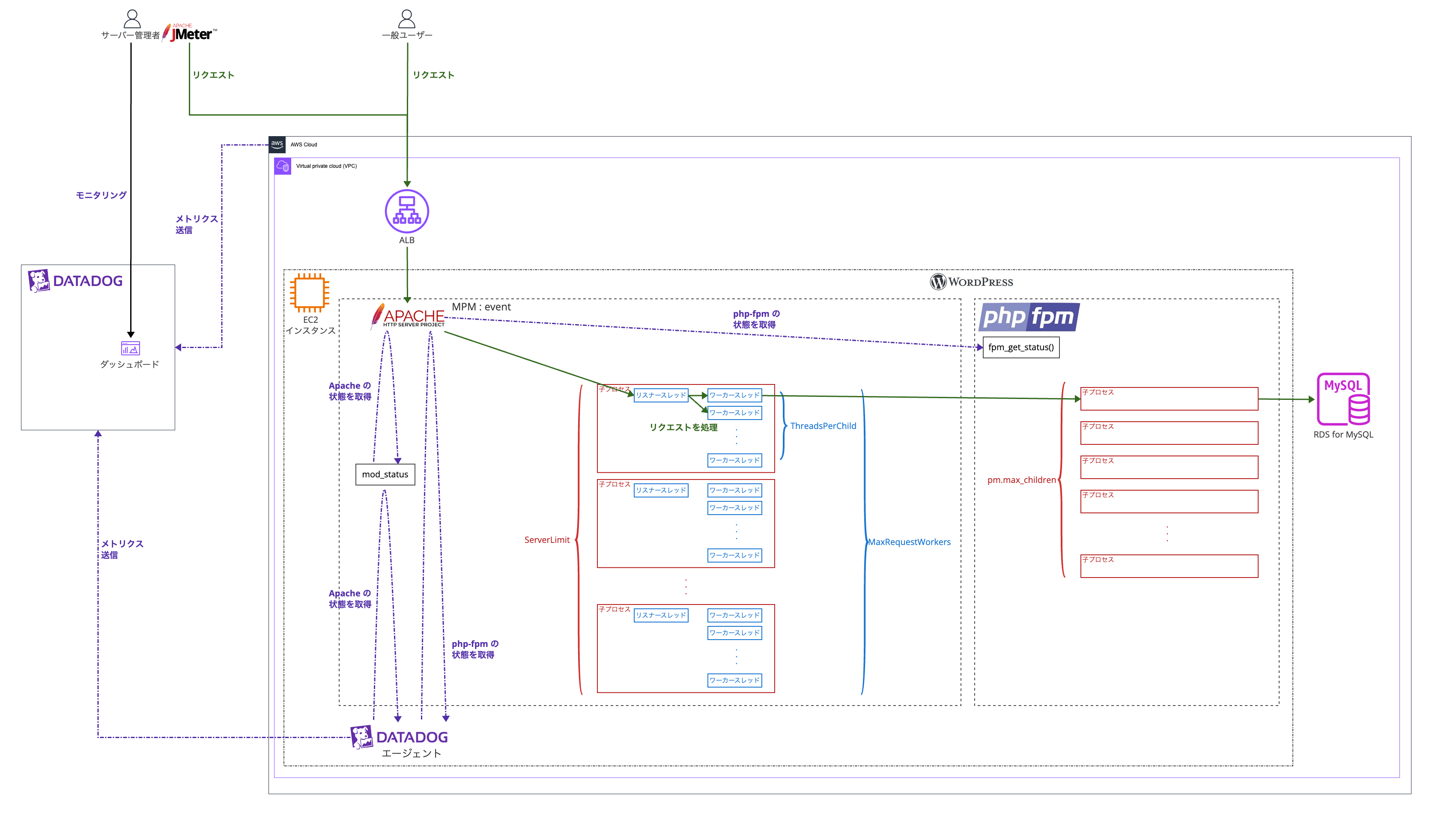
ゴールについて
サービスの動いている AWS アカウントで EC2 インスタンスにてサーバーのチューニングを行いインスタンスサイズを調整してその結果 コスト最適化 させることをゴールとします😌
前提の確認
EC2 インスタンス
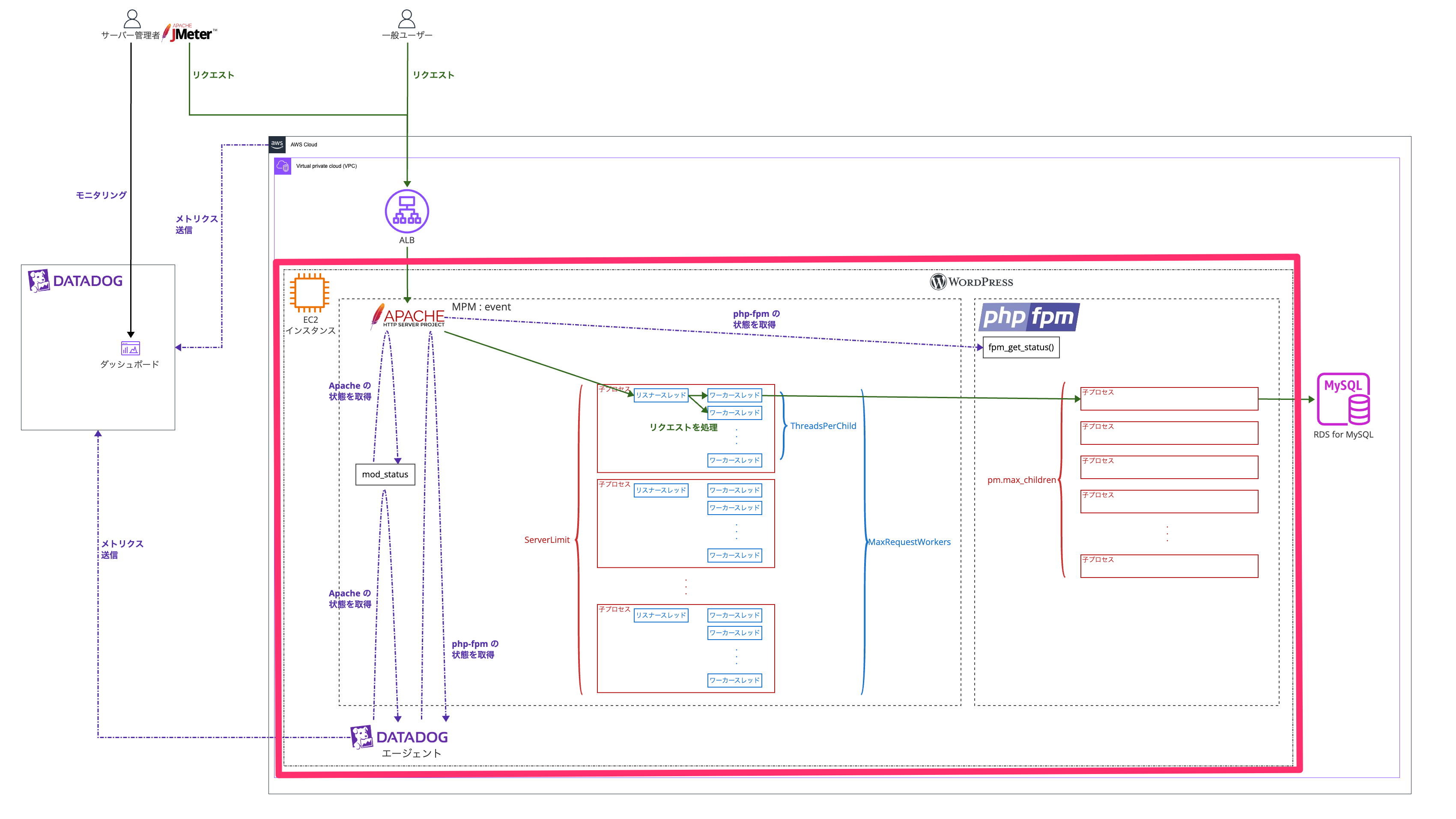
コスト最適化を試みる前の状態は以下です。
| 大項目 | 中項目 | 小項目 | 値 | 備考欄 |
|---|---|---|---|---|
| インスタンス | インスタンスサイズ | – | m6i.xlarge | – |
| インスタンス | vCPU | – | 4 | – |
| インスタンス | メモリ (GiB) | – | 16 | – |
| サーバー内部 | OS | – | Amazon Linux 2 | – |
| サーバー内部 | Apahe | バージョン | 2.4 | – |
| サーバー内部 | Apahe | MPM | event | – |
| サーバー内部 | Apahe | ThreadsPerChild | 25 | デフォルト |
| サーバー内部 | Apahe | ServerLimit | 16 | デフォルト |
| サーバー内部 | Apahe | MaxRequestWorkers | 400 | デフォルト |
| サーバー内部 | PHP | バージョン | 8.2 | – |
| サーバー内部 | PHP | memory_limit | 128M | デフォルト |
| サーバー内部 | php-fpm | pm | dynamic | デフォルト |
| サーバー内部 | php-fpm | pm.max_children | 50 | デフォルト |
| サーバー内部 | php-fpm | pm.start_servers | 5 | デフォルト |
| サーバー内部 | php-fpm | pm.min_spare_servers | 5 | デフォルト |
| サーバー内部 | php-fpm | pm.max_spare_servers | 35 | デフォルト |
| サーバー内部 | php-fpm | pm.max_requests | 0 | デフォルト |
| サーバー内部 | WordPress | バージョン | 6.6.1 | – |
イメージとしては 「Apache や php-fpm はとりあえずデフォルトの設定で初めてみたけど、スペックが余剰気味だからインスタンスサイズを調整してコスト最適化したいなー」 と思われてそうな環境をなるべく再現しました。
その他
- データーベースは現在アプリケーションのボトルネックになっていない状況である前提とします。
- RDS は今回はチューニング、最適化対象外としますので詳細は割愛します。
対象 Web サイトのリクエスト数
接続のピークタイムは 1 時間であるとして、 400 リクエスト/分 のリクエストがある Web サイトであるという前提とします。
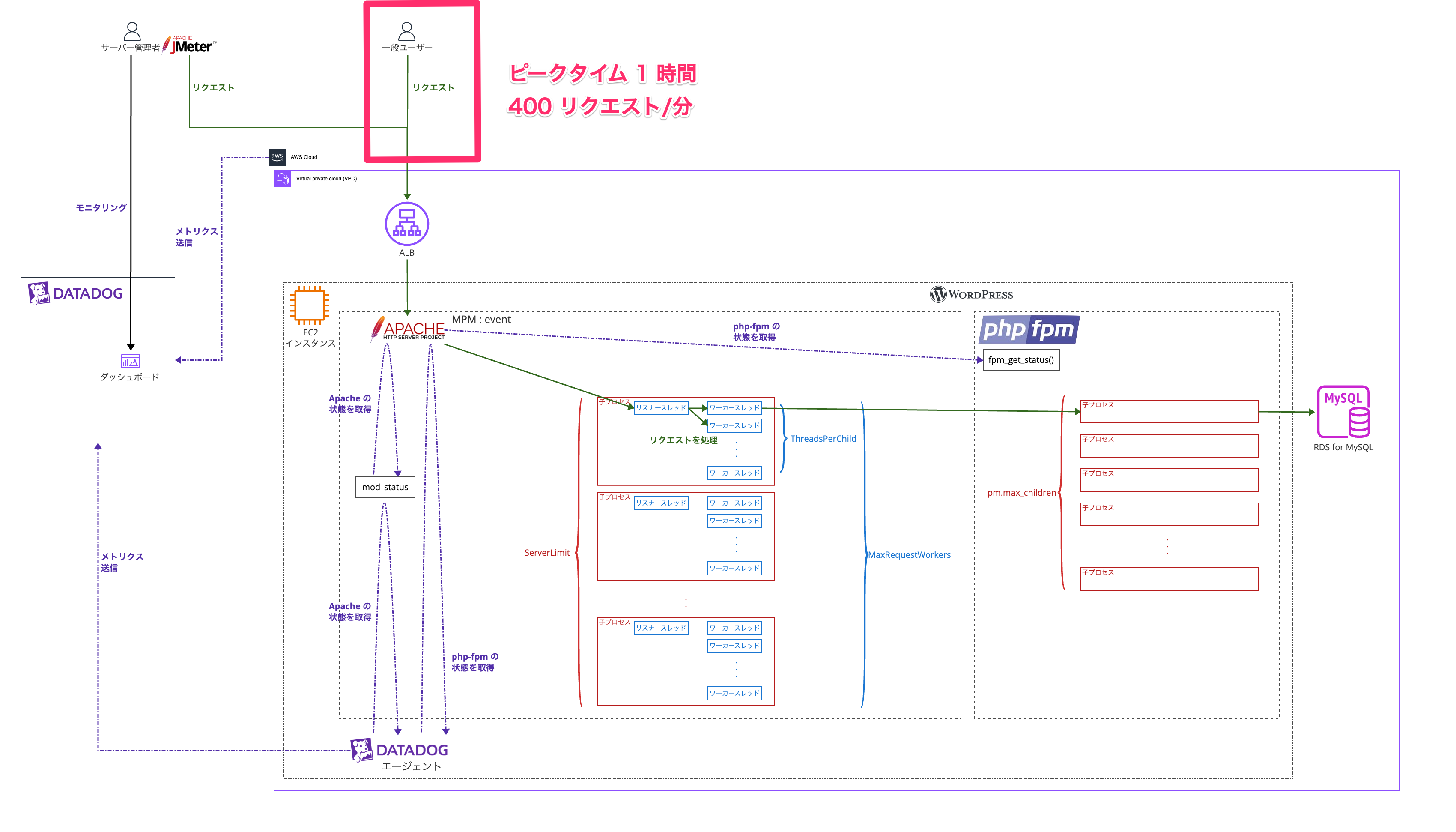
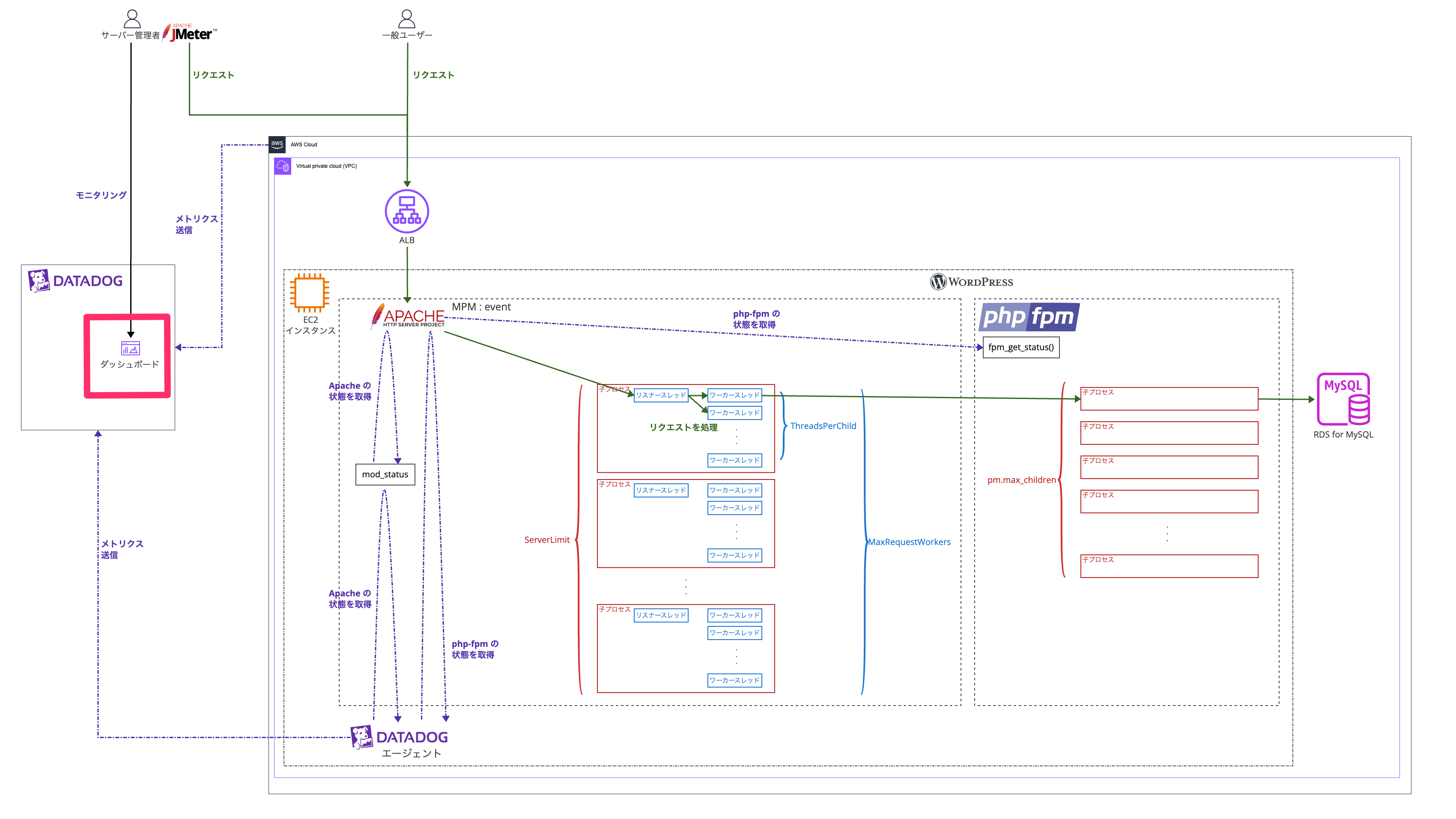
リクエストを再現する方法としては JMeter を使います。
JMeter の設定について
負荷をかける JMeter の設定は以下です。(JMeter についての詳細は割愛します)
| 大項目 | 小項目 | 値 | 備考欄 |
|---|---|---|---|
| Thread Group | Number of Threads (users) | 400 | 1 ループ単位で同時に接続するリクエスト数 |
| Thread Group | Ramp-up Period (seconds) | 60 | 1 ループ 内の全部のスレッドが起動し切るまでの時間 |
| Thread Group | Loop Count | 60 | Number of Threads の接続をループする回数 |
| Constant Timer | Thread Delay (in milliseconds) | 60000 | 1 スレッド単位でリクエストが実行されてからした時に次のリクエストが実行するまで待たせる時間 |
| HTTP Request | Protocol | http | |
| HTTP Request | Server Name or IP | [本件の Web サイトの DNS 名] | |
| HTTP Request | HTTP Request | GET | |
| HTTP Request | HTTP Request | /?p=5 | WordPress の特定のページを表示 |
現状を把握しよう
現状の把握に Datadog のダッシュボードを利用します。
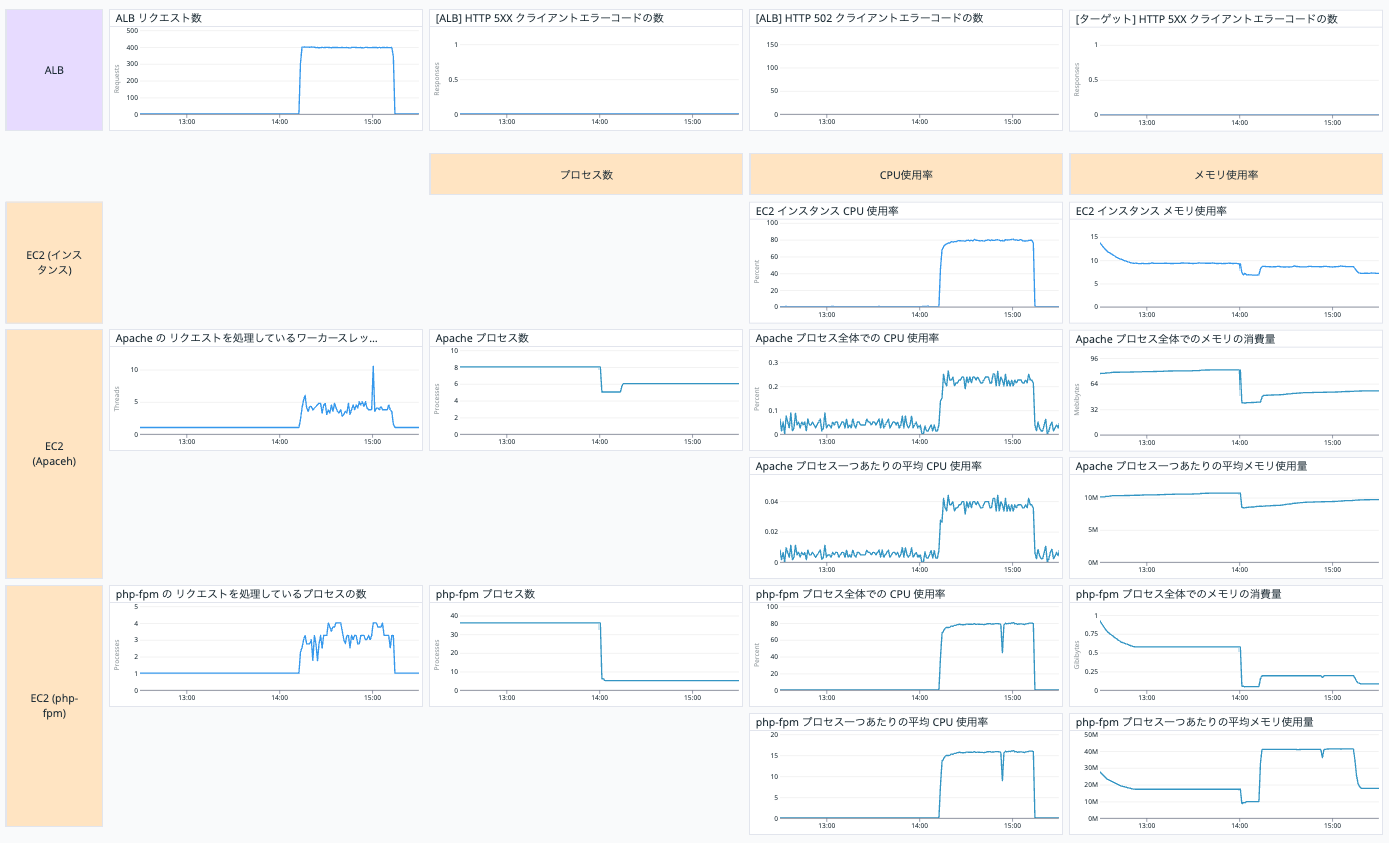
今回作成したダッシュボードは以下です。
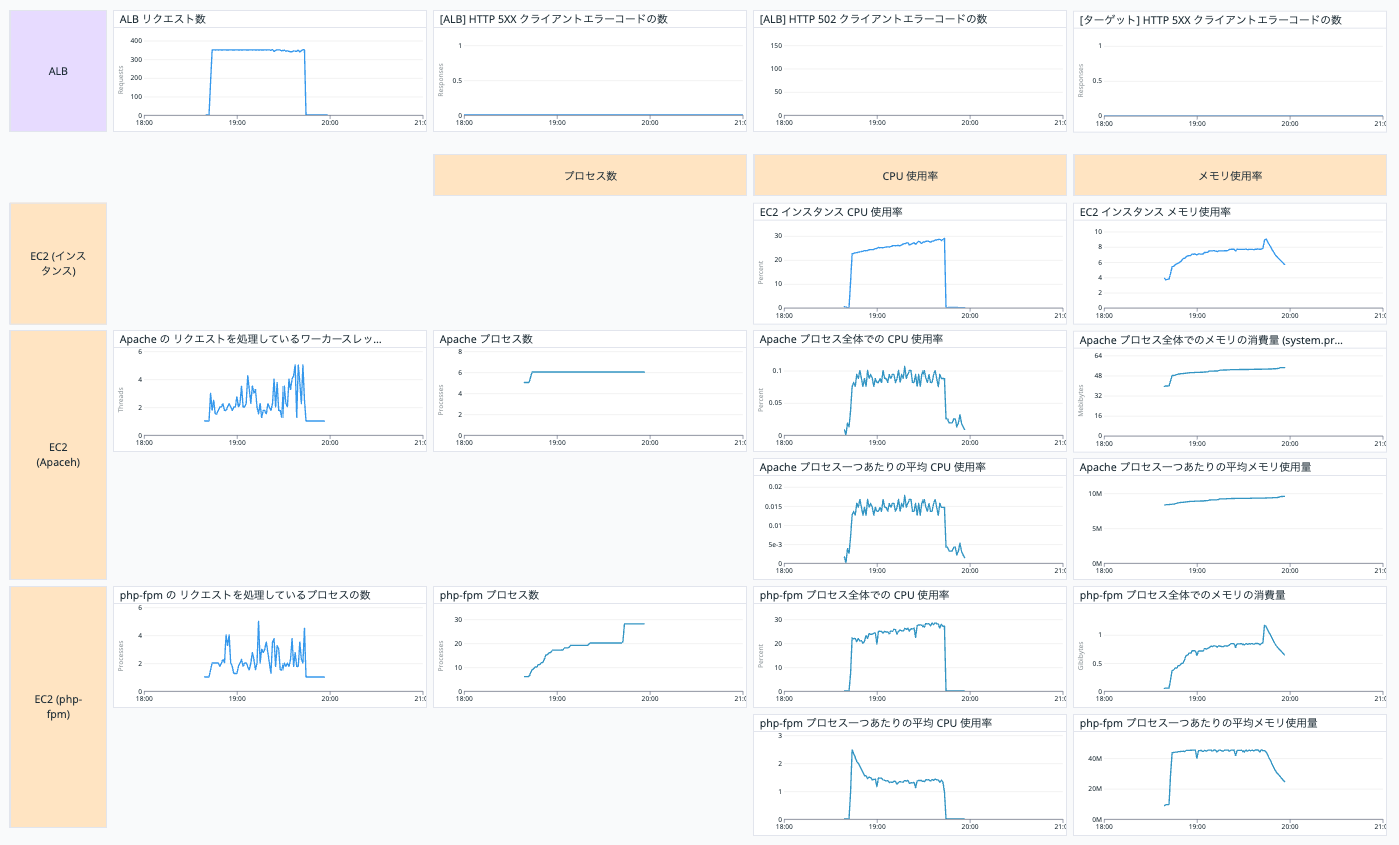
各グラフについて説明していきます。
ALB のグラフについて
上の段は ALB に関する情報です。
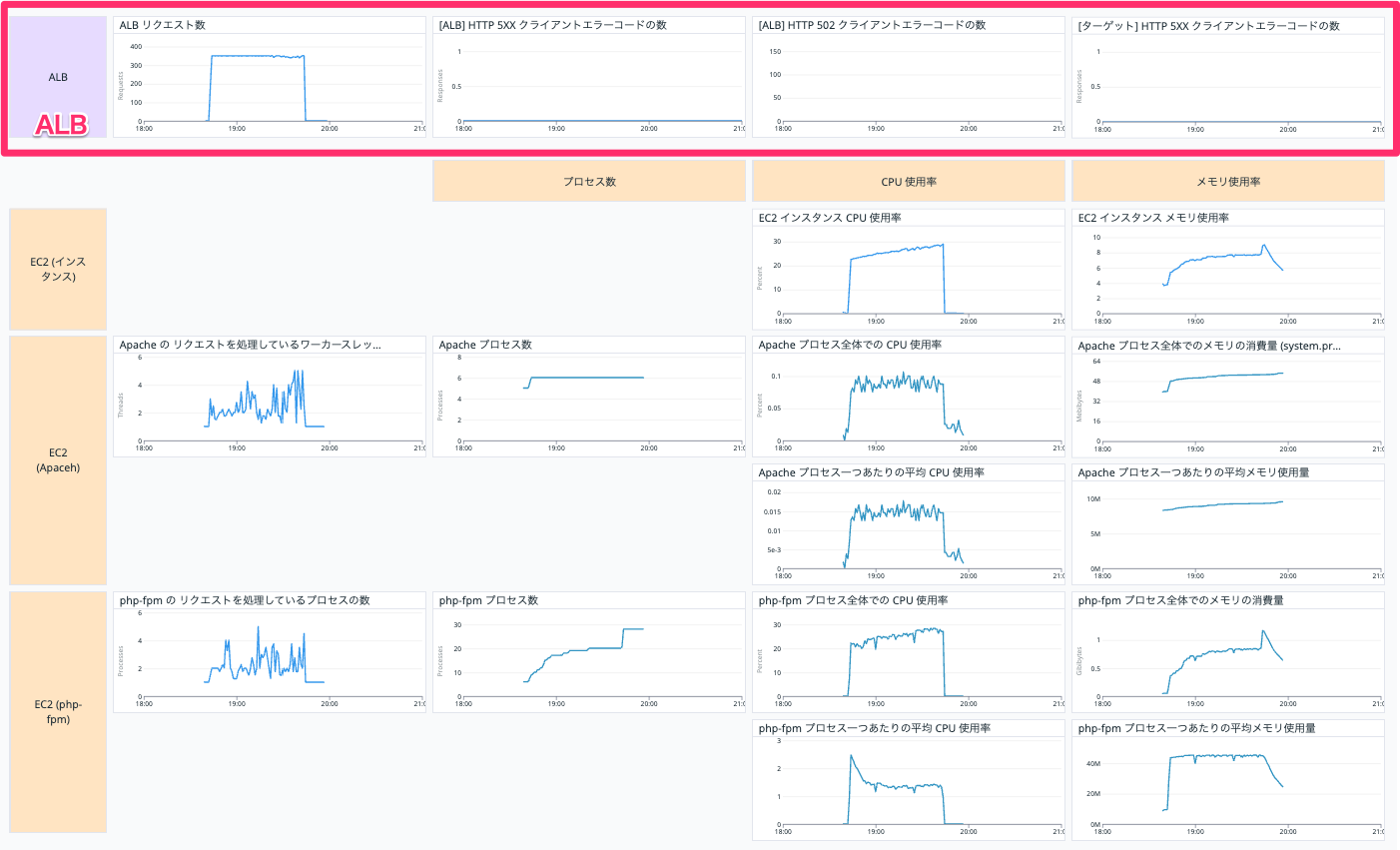
一番左のグラフが 1 分あたりのリクエスト数なので、ここで予定通り 400リクエスト/分 になっているか確認します。
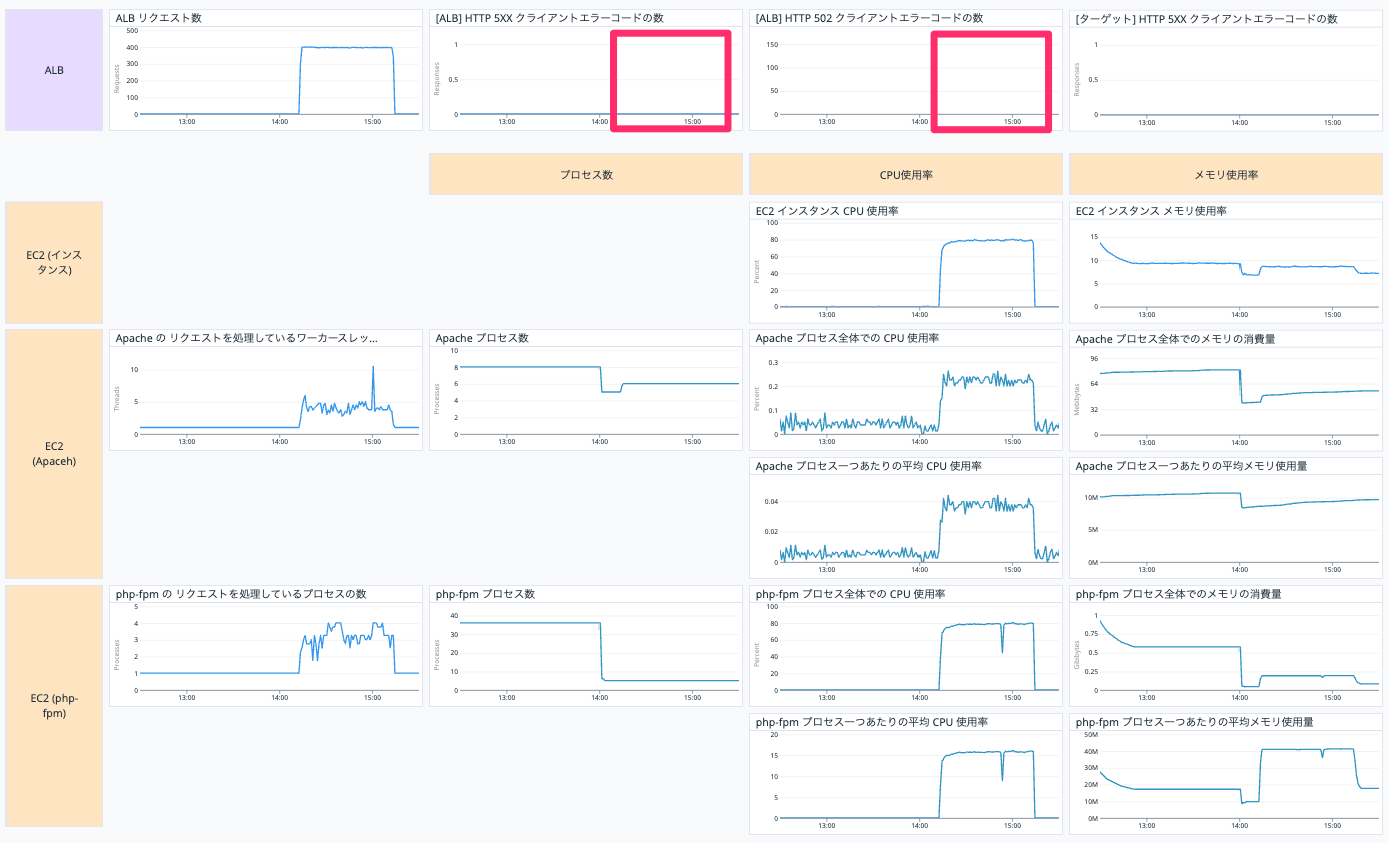
それ以外の三つでエラーの有無を確認します。
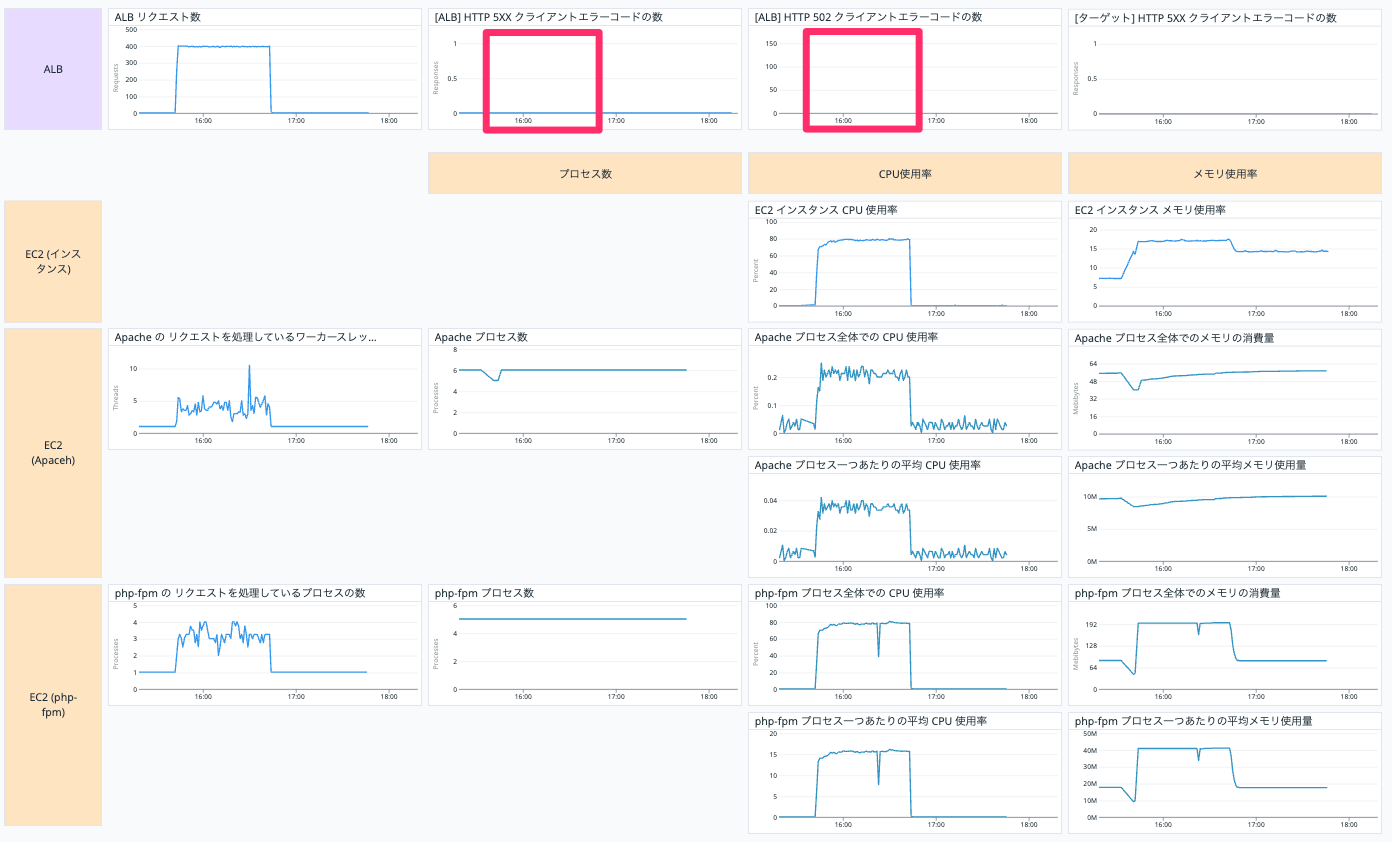
今回のケースで起こったエラーである 502 bad gateway を特にわかりやすくしています。
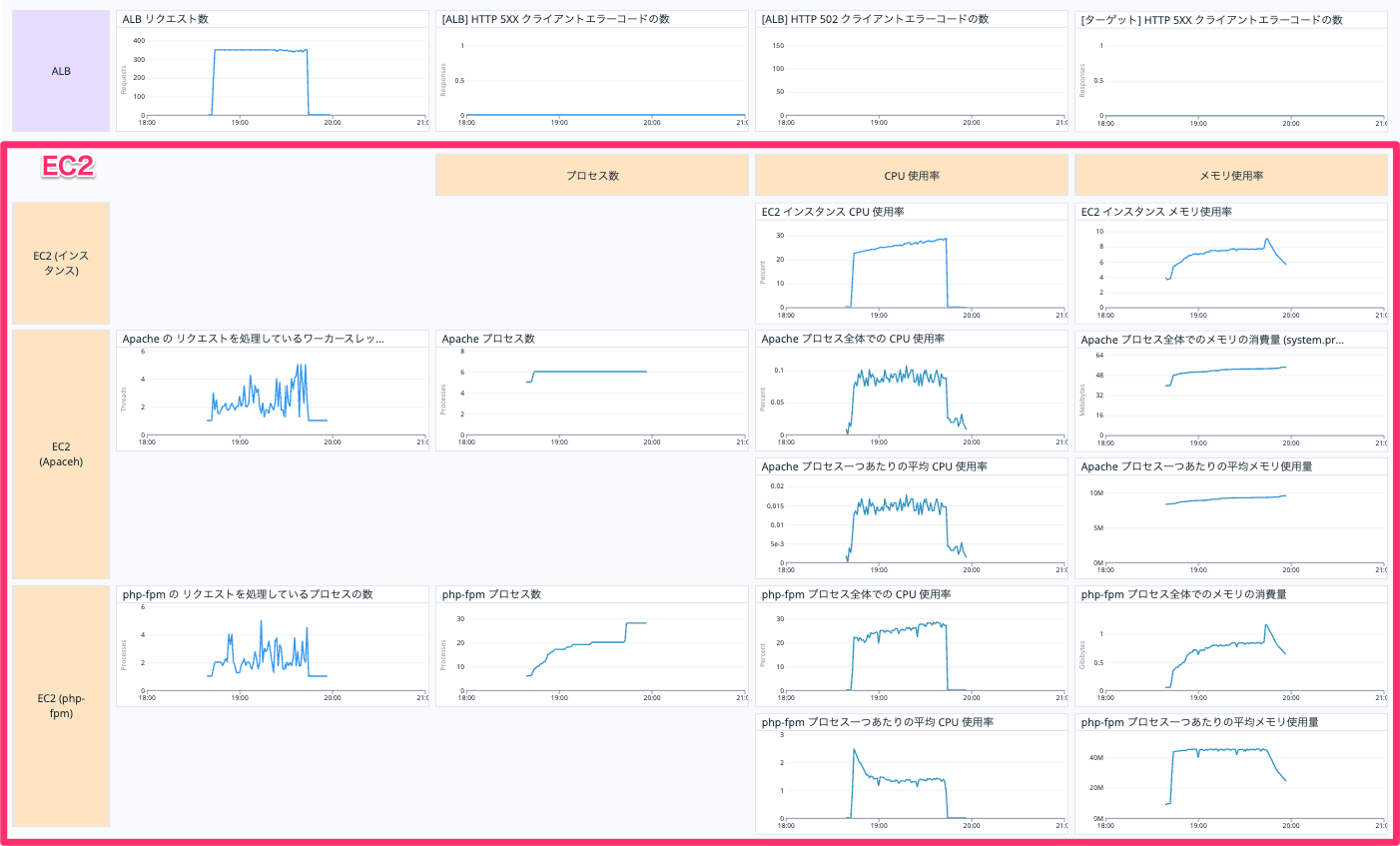
EC2 インスタンスのグラフについて
以下は EC2 インスタンスに関する情報です。
同時処理数
Apache の リクエストを処理しているワーカースレッドの数
EC2 インスタンスの Apache の リクエストを処理しているワーカースレッドの数を表示しています。
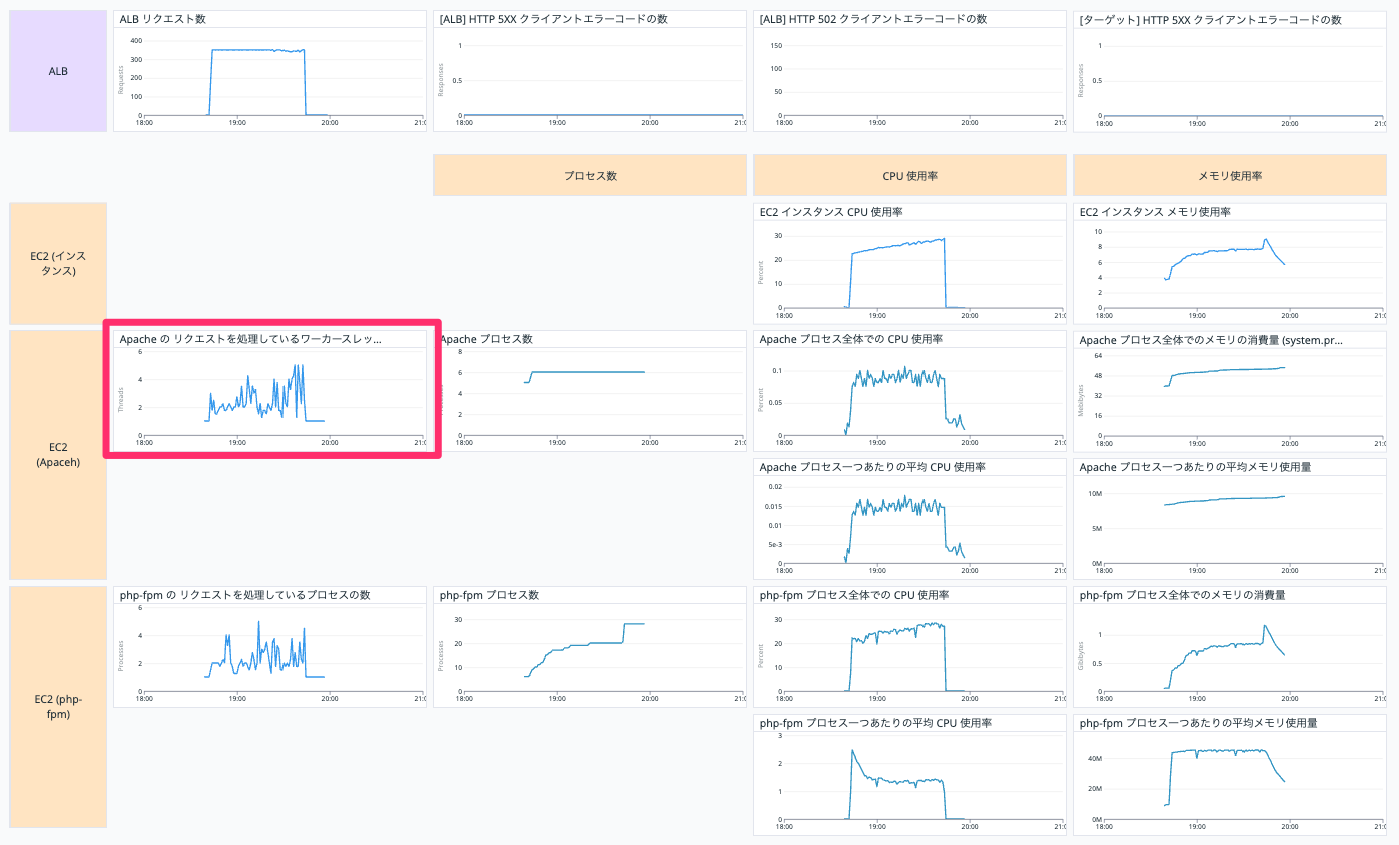
以下の Query で表示しています。
avg:apache.performance.busy_workers{host:【EC2 インスタンスの Datadog ホスト名】} by {host}
このデータの取り方は以下の記事で紹介しています。
php-fpm の リクエストを処理しているプロセスの数
EC2 インスタンスの php-fpm の リクエストを処理しているプロセスの数を表示しています。

以下の Query で表示しています。
avg:php_fpm.processes.active{host:【EC2 インスタンスの Datadog ホスト名】} by {host}
このデータの取り方は上記の「Apache の リクエストを処理しているワーカースレッドの数」のケースと近しい形での準備が必要です。
今回は割愛しますがいつかブログに書きたいと思っています。。。!
プロセス数
EC2 インスタンスの Apache と php-fpm のプロセス数を表示しています。
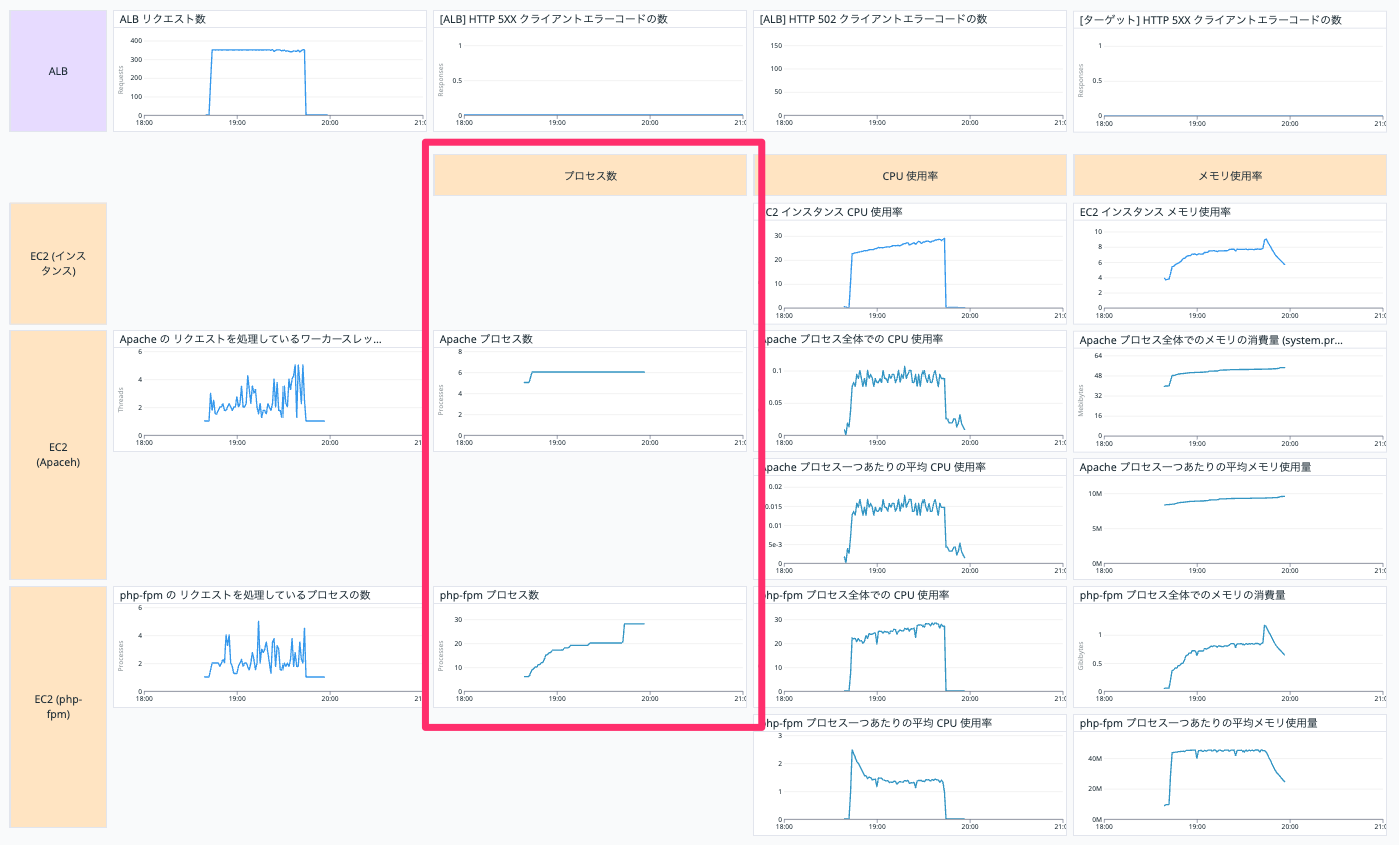
Apache プロセス数
一つ目の Apache プロセス数は以下のクエリで表示しています。
avg:system.processes.number{host:【EC2 インスタンスの Datadog ホスト名】, httpd}
php-fpm プロセス数
二つ目の php-fpm プロセス数は以下のクエリで表示しています。
avg:system.processes.number{host:【EC2 インスタンスの Datadog ホスト名】, php-fpm}
CPU
赤枠の部分は CPU 使用に関するグラフです。
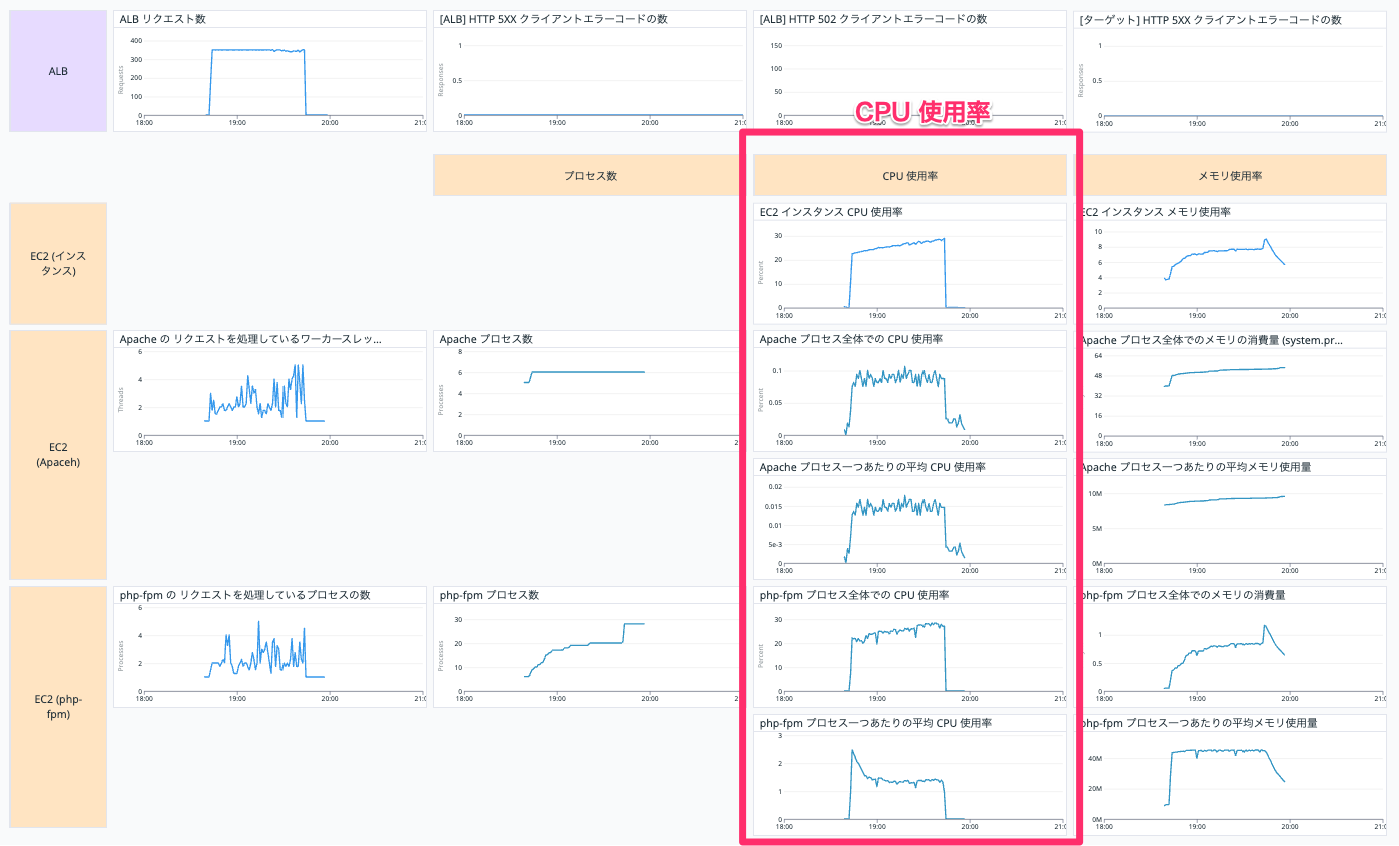
上から説明します。
EC2 インスタンス CPU 使用率
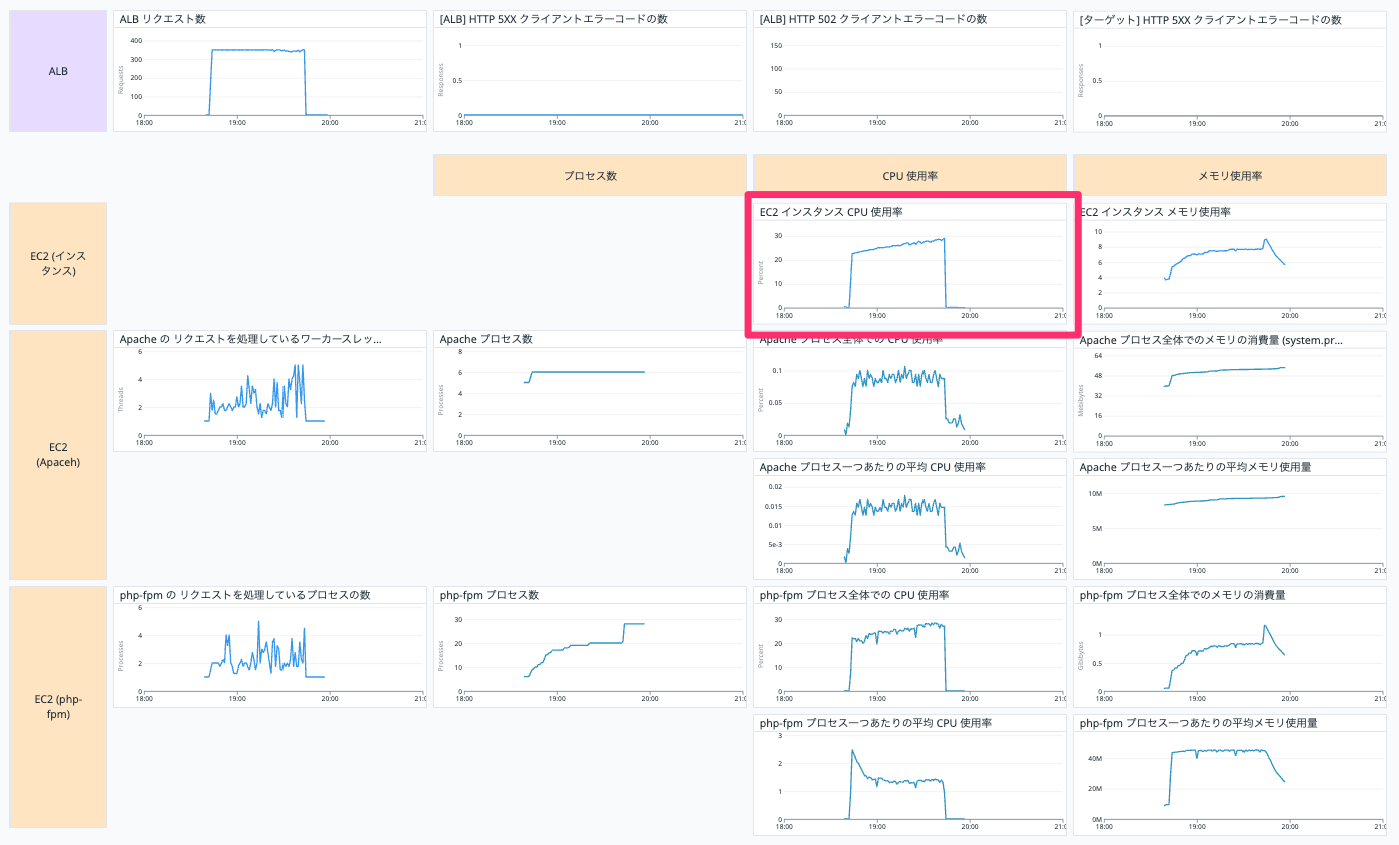
EC2 インスタンスの CPU 使用率を表示しています。
以下の Query で表示しています。
avg:system.cpu.idle{host:【EC2 インスタンスの Datadog ホスト名】} by {host}
Apache プロセス全体での CPU 使用率
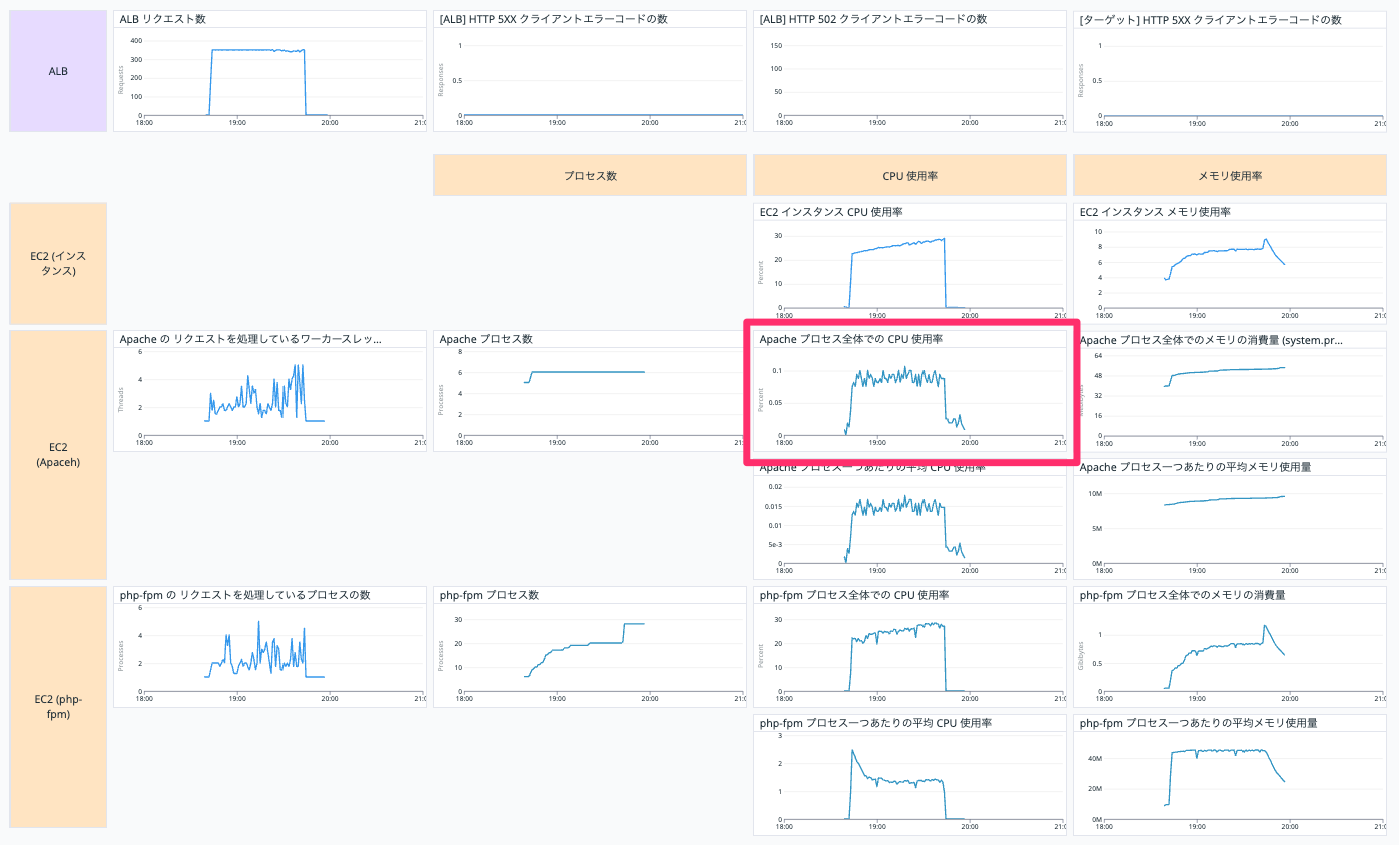
EC2 インスタンスの Apache プロセス全体での CPU 使用率を表示しています。
以下の Query で表示しています。
avg:system.processes.cpu.normalized_pct{host:【EC2 インスタンスの Datadog ホスト名】, process_name:httpd}
Apache プロセス一つあたりの平均 CPU 使用率
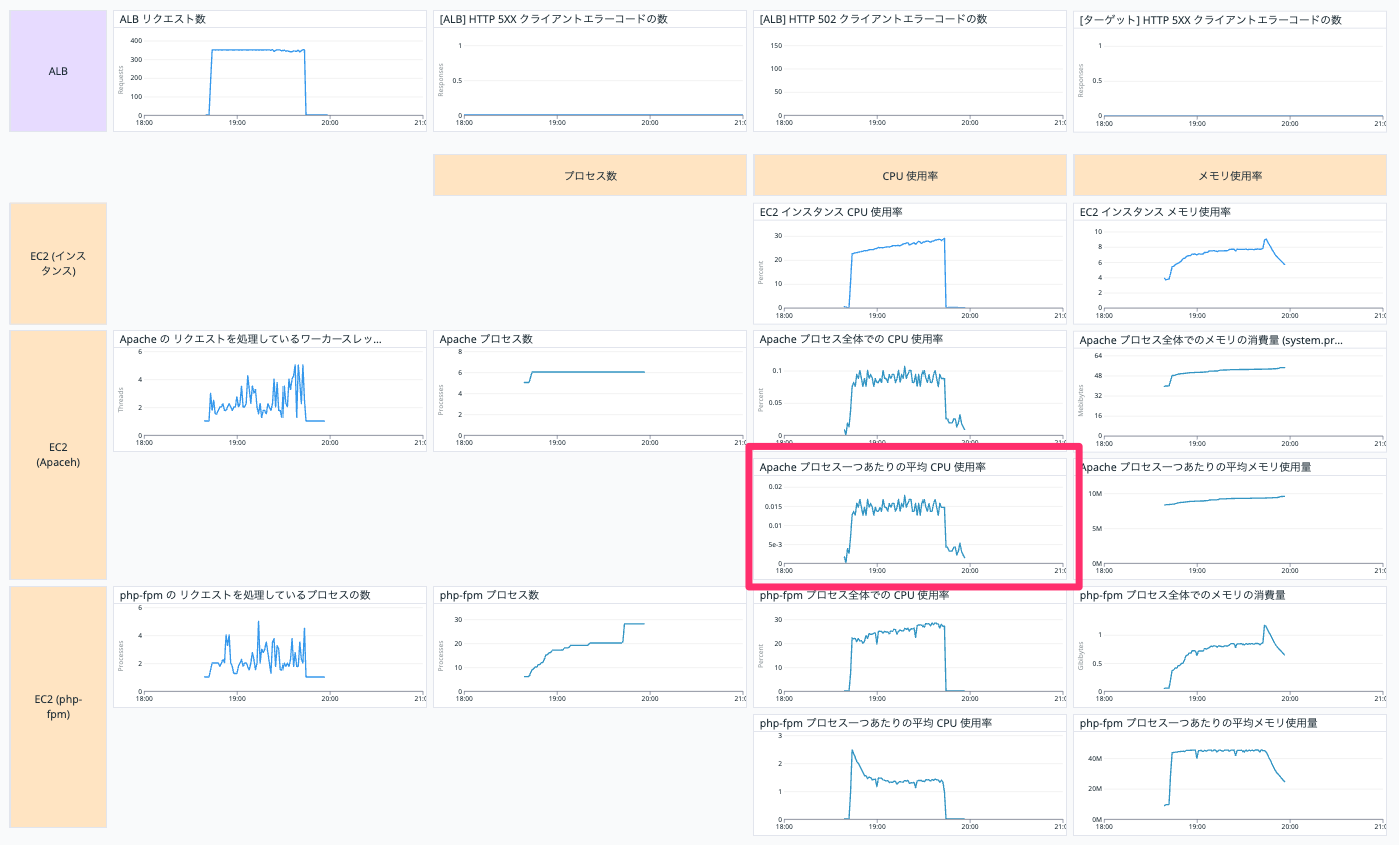
EC2 インスタンスの Apache プロセス一つあたりの平均 CPU 使用率を表示しています。
以下の二つの Query (a, b) を作って、 a / b を表示しています。
a
avg:system.processes.cpu.normalized_pct{host:【EC2 インスタンスの Datadog ホスト名】, process_name:httpd}
b
avg:system.processes.number{host:【EC2 インスタンスの Datadog ホスト名】, process_name:httpd}
php-fpm プロセス全体での CPU 使用率
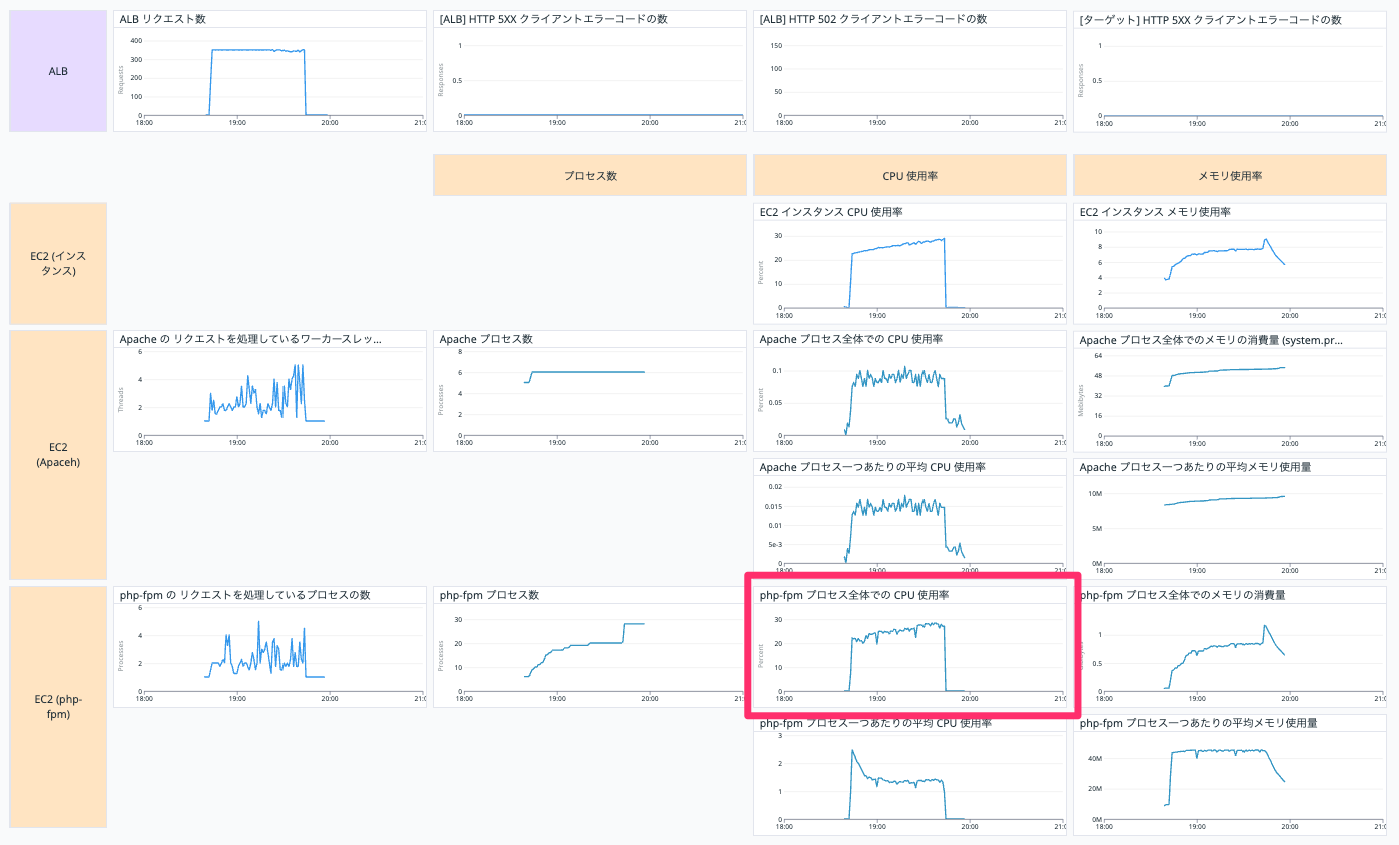
EC2 インスタンスの php-fpm プロセス全体での CPU 使用率を表示しています。
以下の Query で表示しています。
avg:system.processes.cpu.normalized_pct{host:【EC2 インスタンスの Datadog ホスト名】, process_name:php-fpm}
php-fpm プロセス一つあたりの平均 CPU 使用率
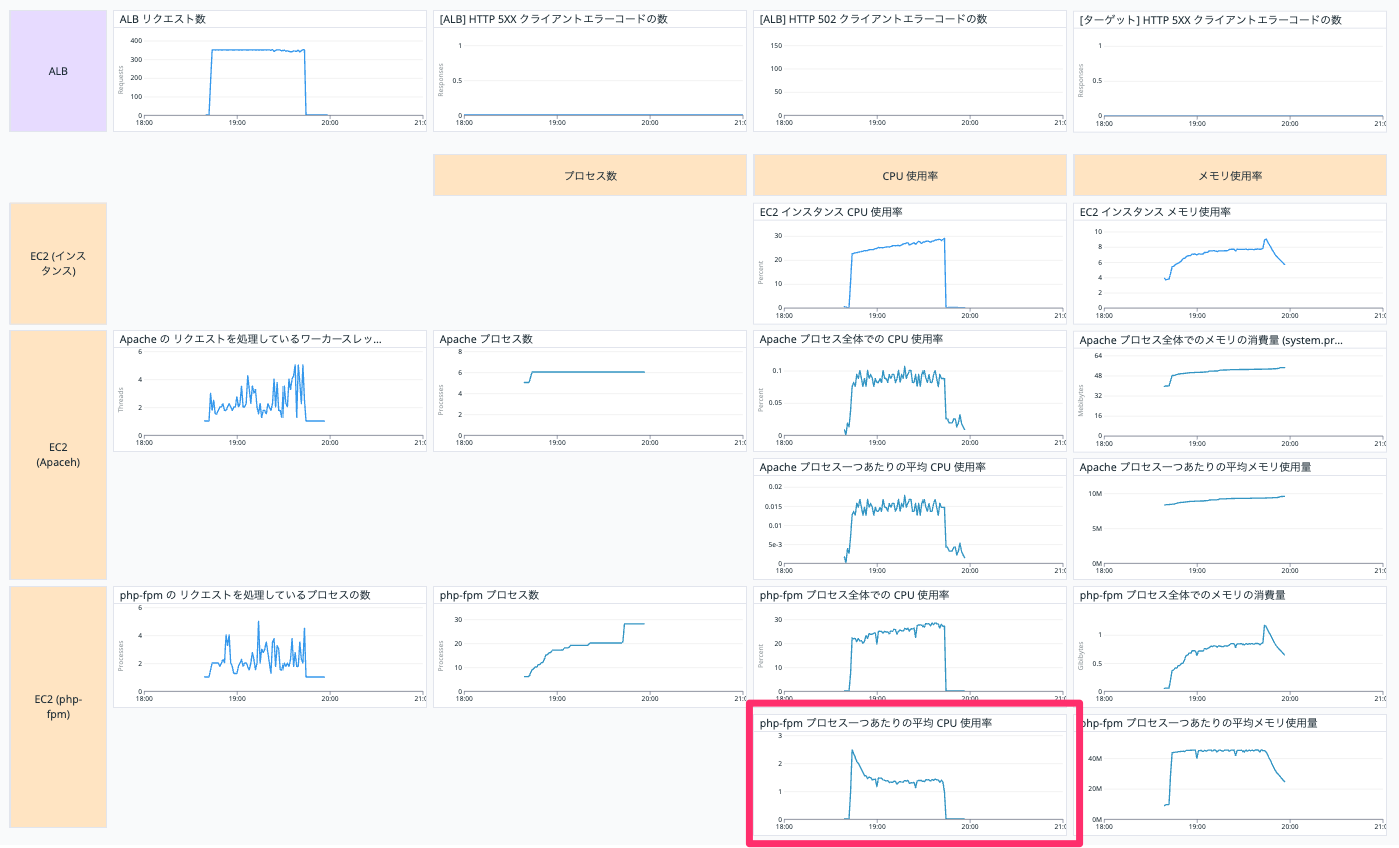
EC2 インスタンスの php-fpm プロセス一つあたりの平均 CPU 使用率を表示しています。
以下の二つの Query (a, b) を作って、 a / b を表示しています。
a
avg:system.processes.cpu.normalized_pct{host:【EC2 インスタンスの Datadog ホスト名】, process_name:php-fpm}
b
avg:system.processes.number{host:【EC2 インスタンスの Datadog ホスト名】, process_name:php-fpm}
メモリ使用率
赤枠の部分はメモリ使用に関するグラフです。
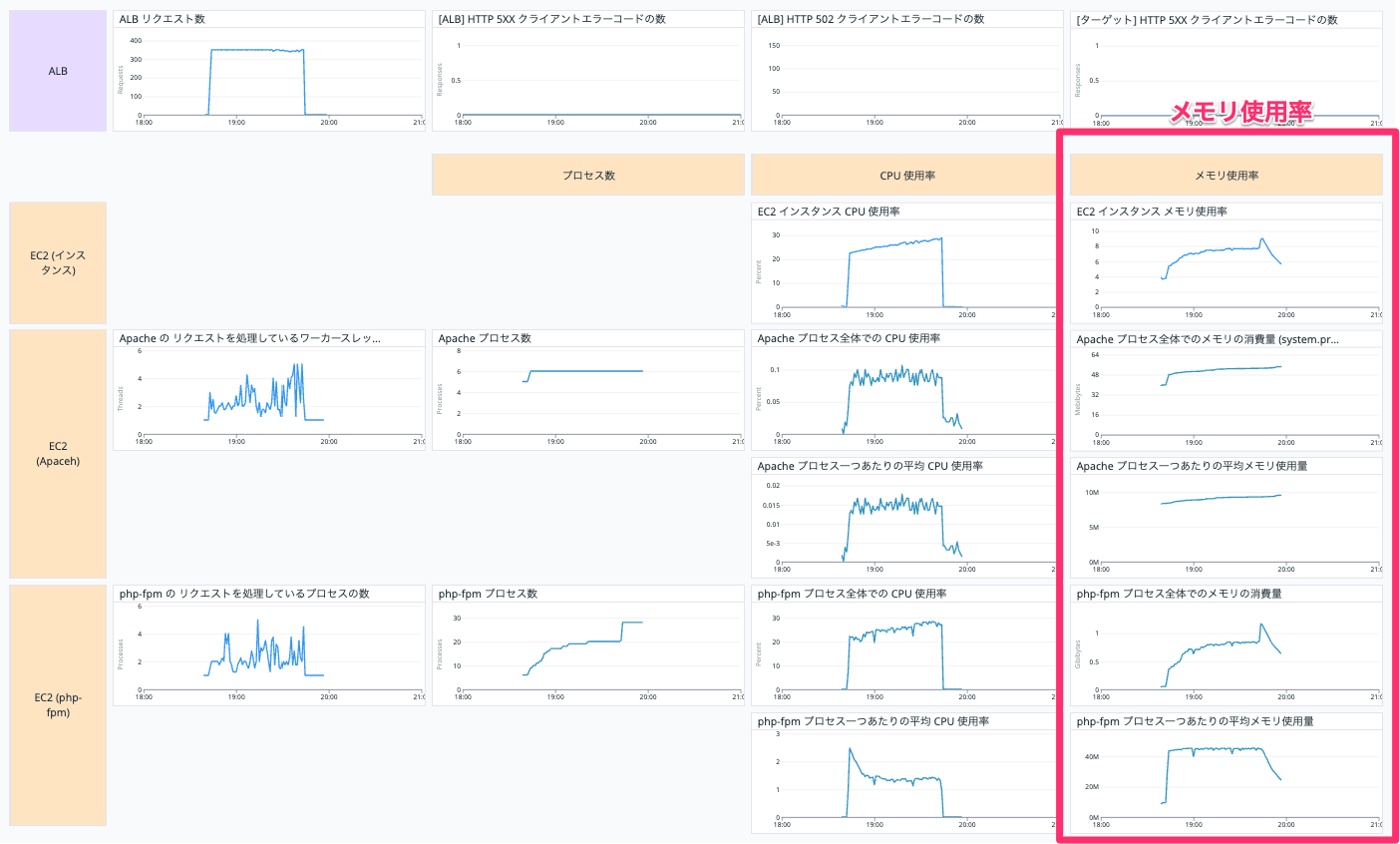
上から説明します。
EC2 インスタンス メモリ 使用率
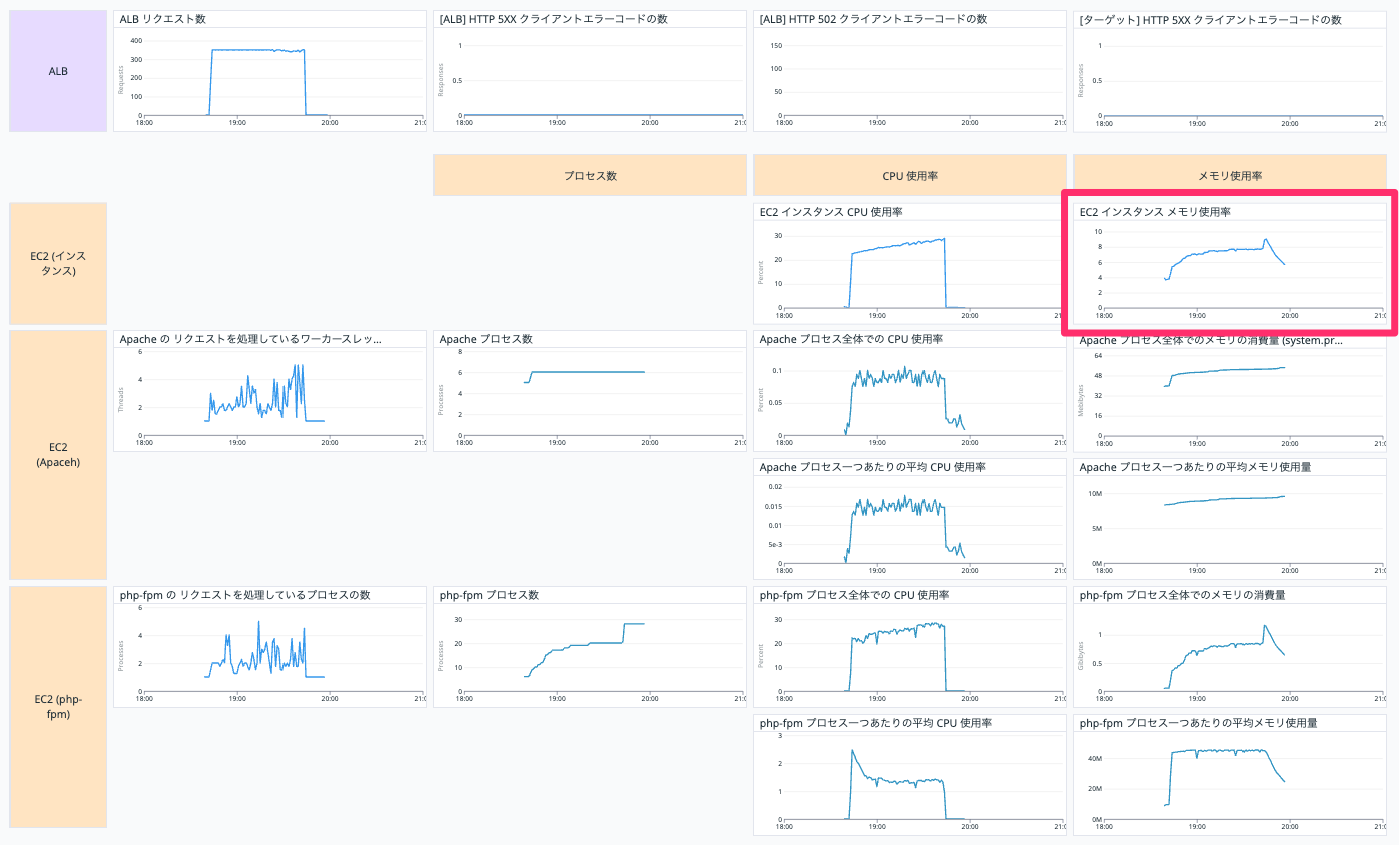
EC2 インスタンスのメモリ使用率を表示しています。
以下の Query で表示しています。
avg:system.mem.pct_usable{host:【EC2 インスタンスの Datadog ホスト名】} by {host}
Apache プロセス全体でのメモリの消費量
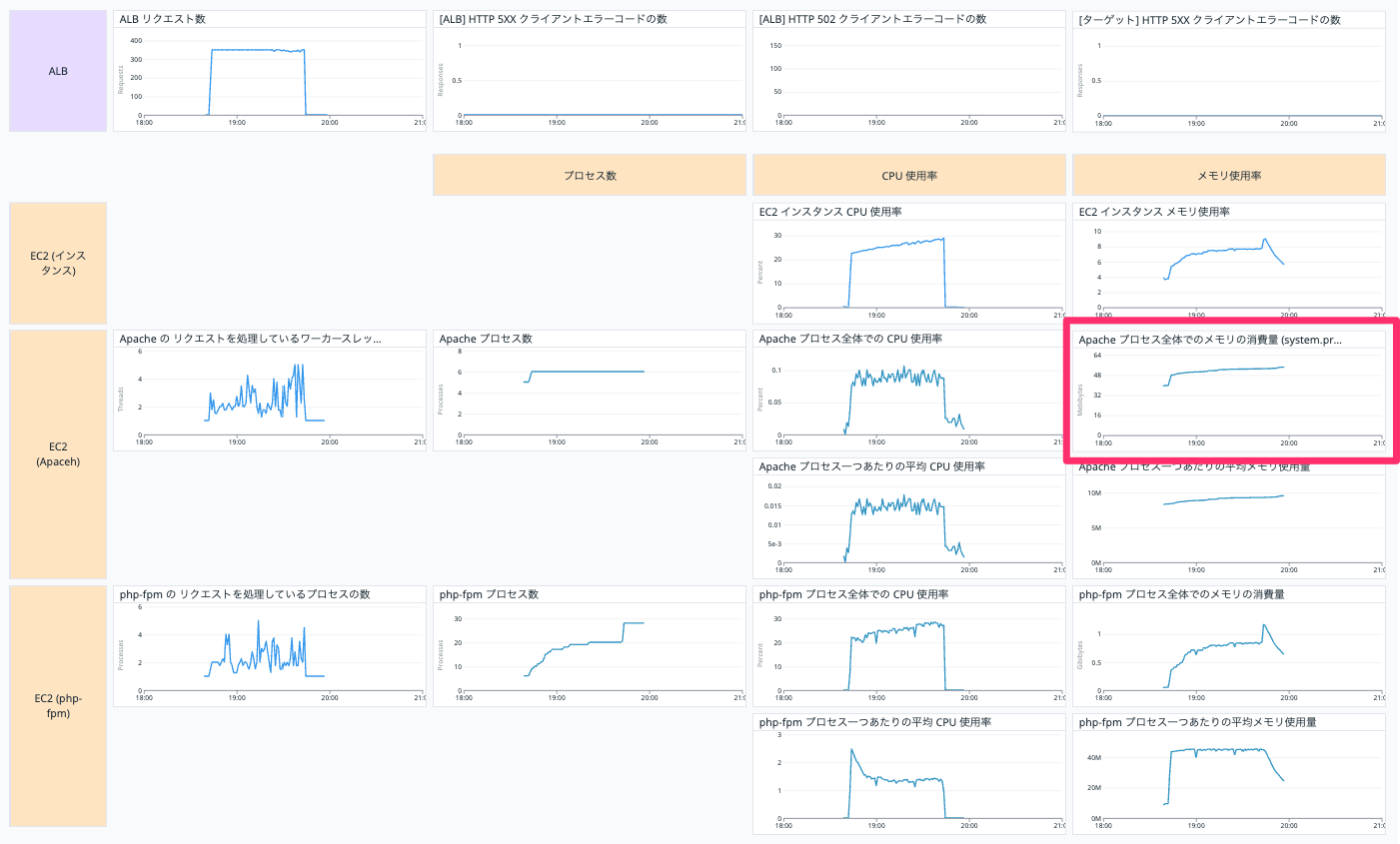
EC2 インスタンスの Apache プロセス全体でのメモリ使用量を表示しています。
以下の Query で表示しています。
avg:system.processes.mem.rss{host:【EC2 インスタンスの Datadog ホスト名】, process_name:httpd}
Apache プロセス一つあたりの平均メモリ使用量
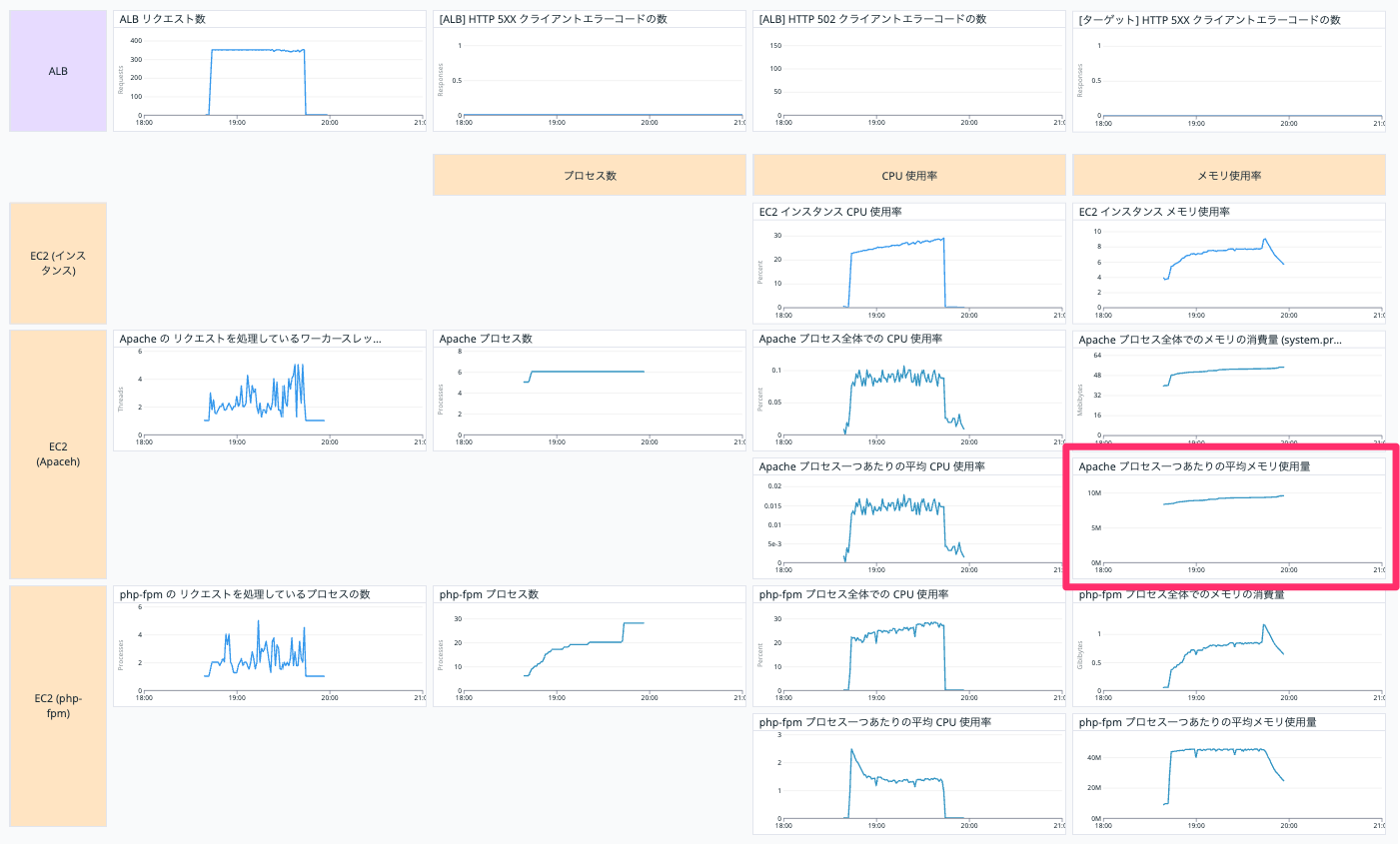
EC2 インスタンスの Apache プロセス一つあたりの平均メモリ使用量を表示しています。
以下の二つの Query (a, b) を作って、 a / b を表示しています。
a
avg:system.processes.mem.rss{host:【EC2 インスタンスの Datadog ホスト名】, process_name:httpd}
b
avg:system.processes.number{host:【EC2 インスタンスの Datadog ホスト名】, process_name:httpd}
php-fpm プロセス全体でのメモリの消費量
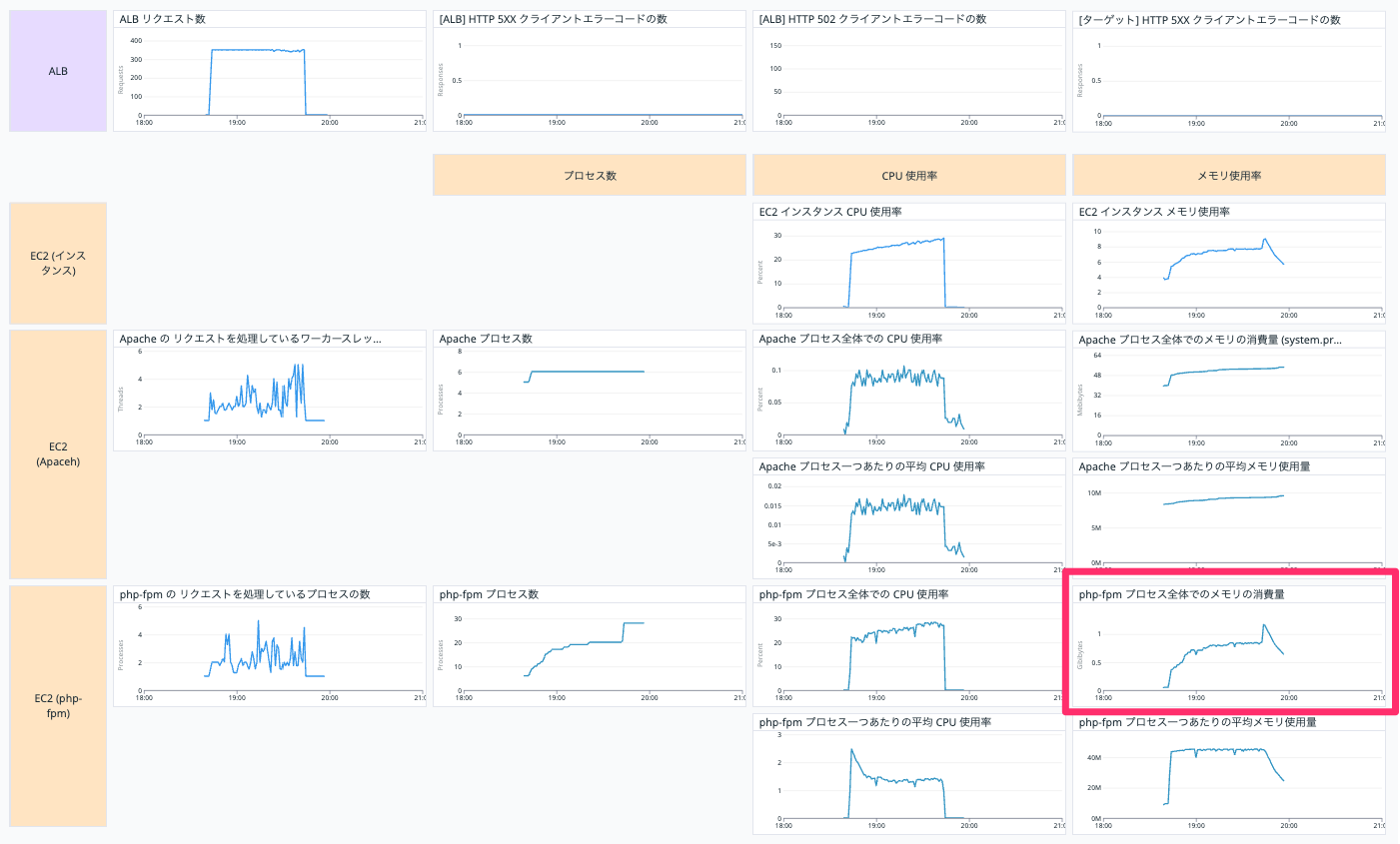
EC2 インスタンスの php-fpm プロセス全体でのメモリの消費量を表示しています。
以下の Query で表示しています。
avg:system.processes.mem.rss{host:【EC2 インスタンスの Datadog ホスト名】, process_name:php-fpm}
php-fpm プロセス一つあたりの平均メモリ使用量
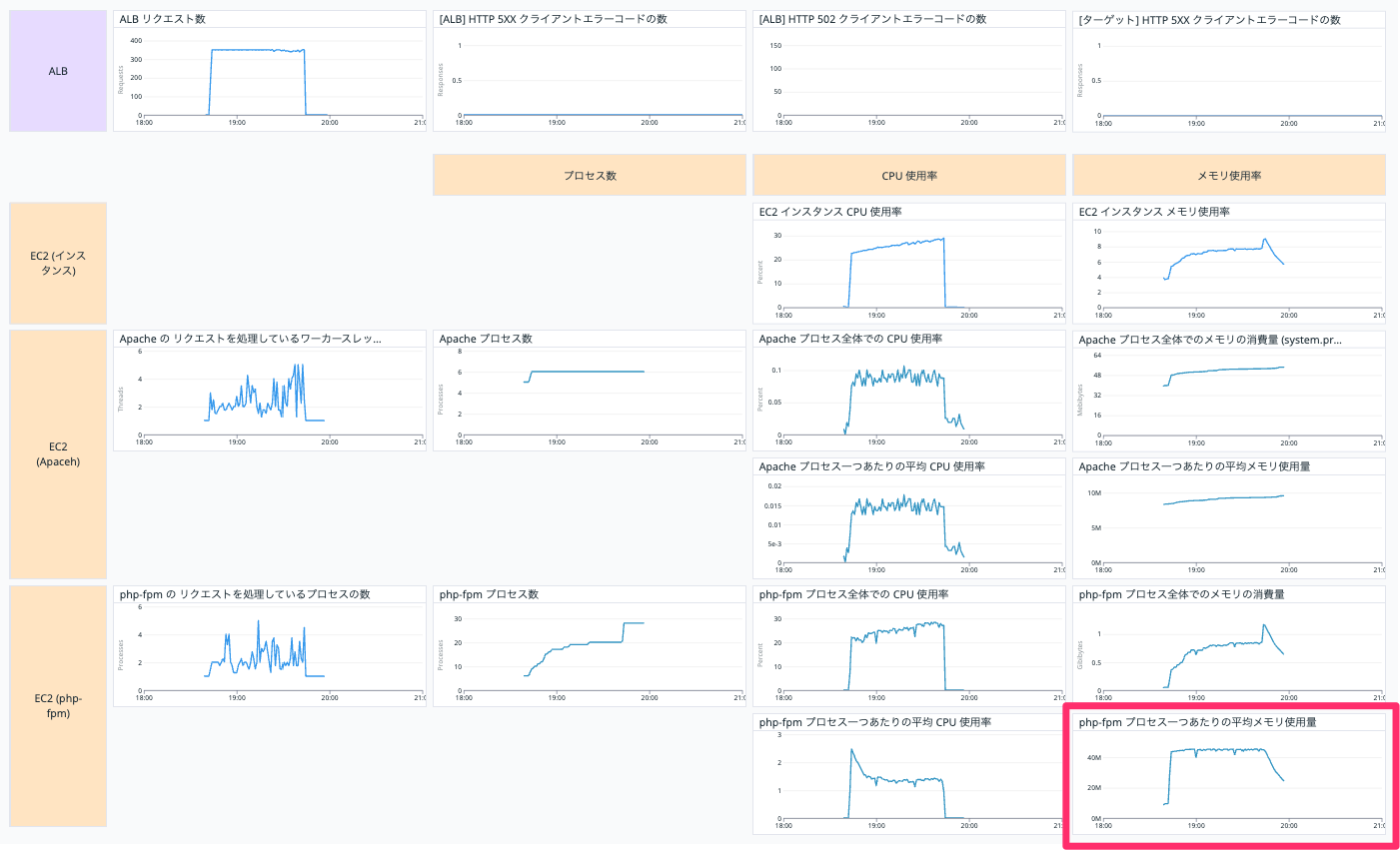
EC2 インスタンスの php-fpm プロセス一つあたりの平均メモリ使用量を表示しています。
以下の二つの Query (a, b) を作って、 a / b を表示しています。
a
avg:system.processes.mem.rss{host:【EC2 インスタンスの Datadog ホスト名】, process_name:php-fpm}
b
avg:system.processes.number{host:【EC2 インスタンスの Datadog ホスト名】, process_name:php-fpm}
【テスト1】現状の構成にて JMeter でリクエストを再現した結果を Datadog ダッシュボードで確認
ここからは以下のように JMeter でリクエストを再現してその結果を Datadog ダッシュボードで確認していきます。
テスト1の結果が以下です。
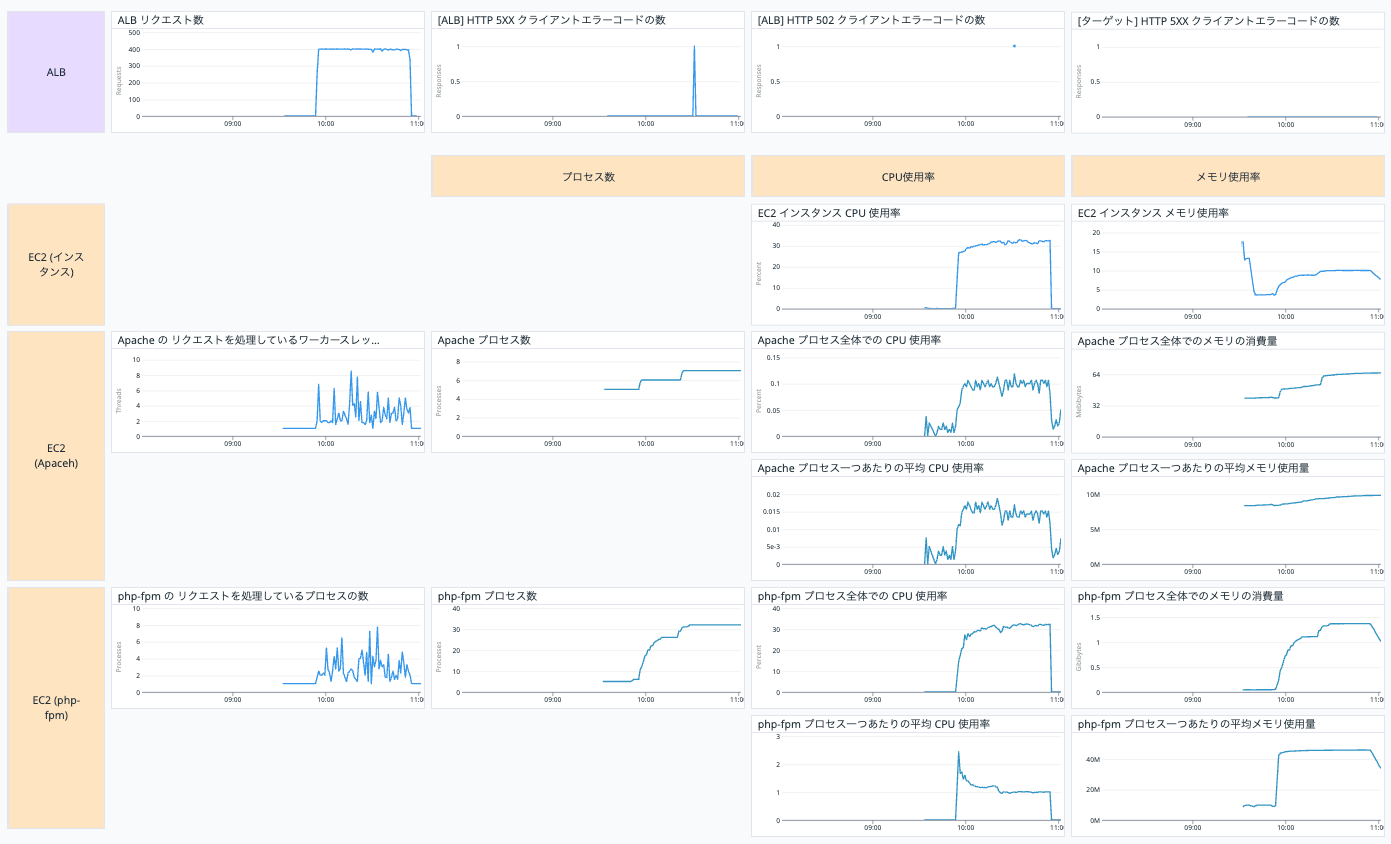
EC2 インスタンスの CPU 使用率は 30 % 程度で、メモリ使用率は10 % 程度ですのでスペックに余裕がありますね。
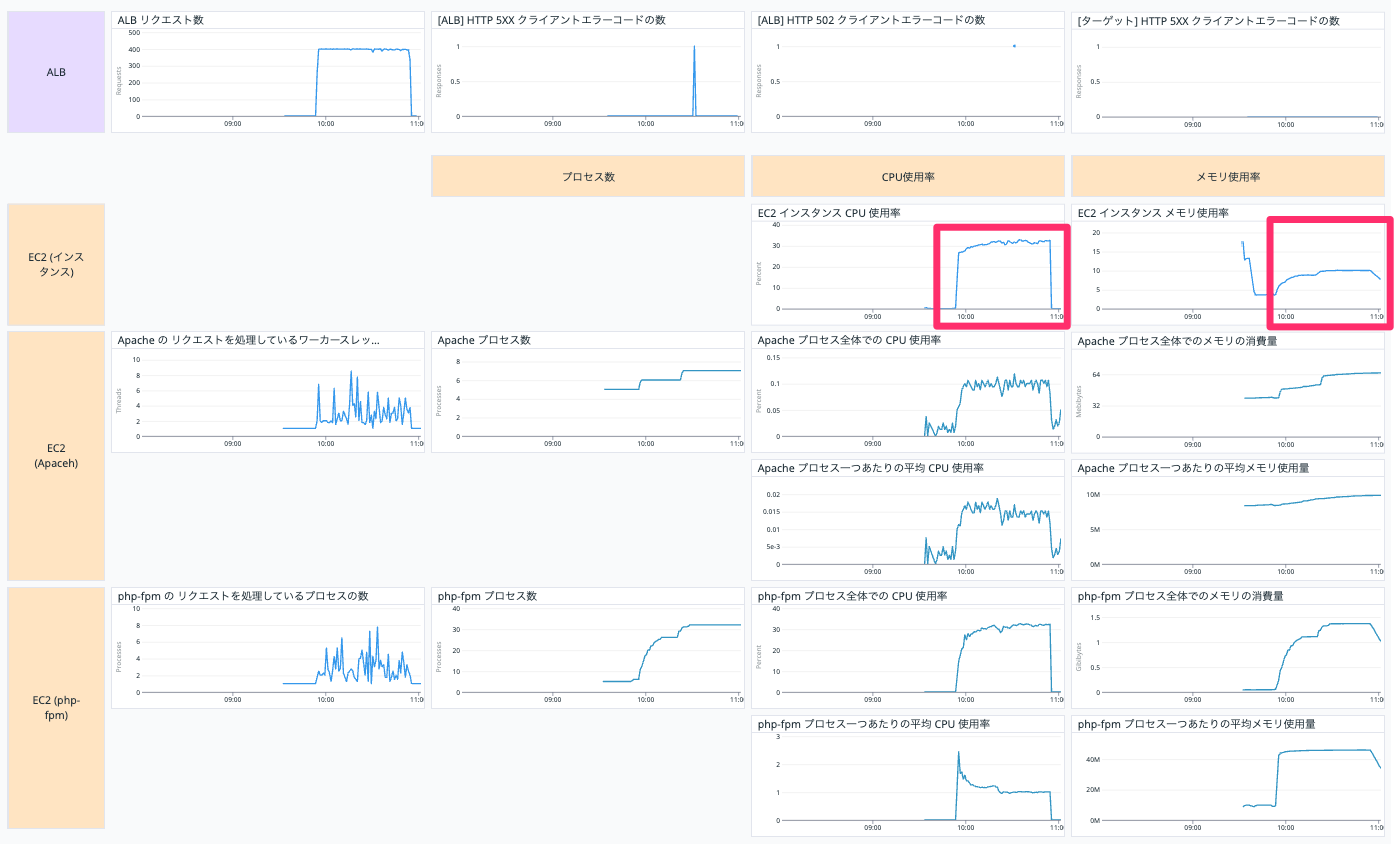
半分のスペックでもいけそうなのでインスタンスサイズを m6i.large に変えてみましょう。
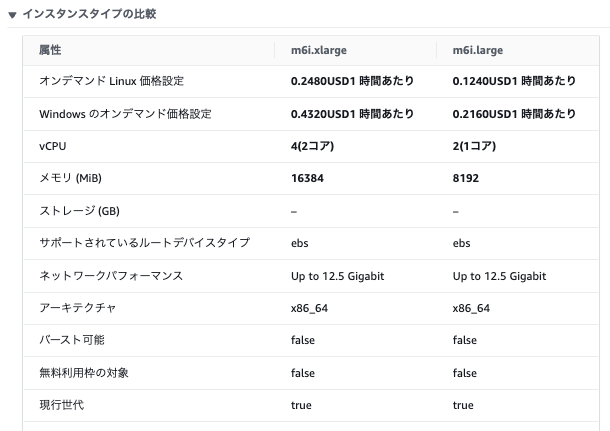
最初の状態である m6i.xlarge と変更先の m6i.large のスペックの比較は以下です。 (2024/08/26 時点)
【テスト2】インスタンスサイズを m6i.large に変えた状態で JMeter でリクエストを再現した結果をDatadog ダッシュボードで確認
テスト2の結果が以下です。
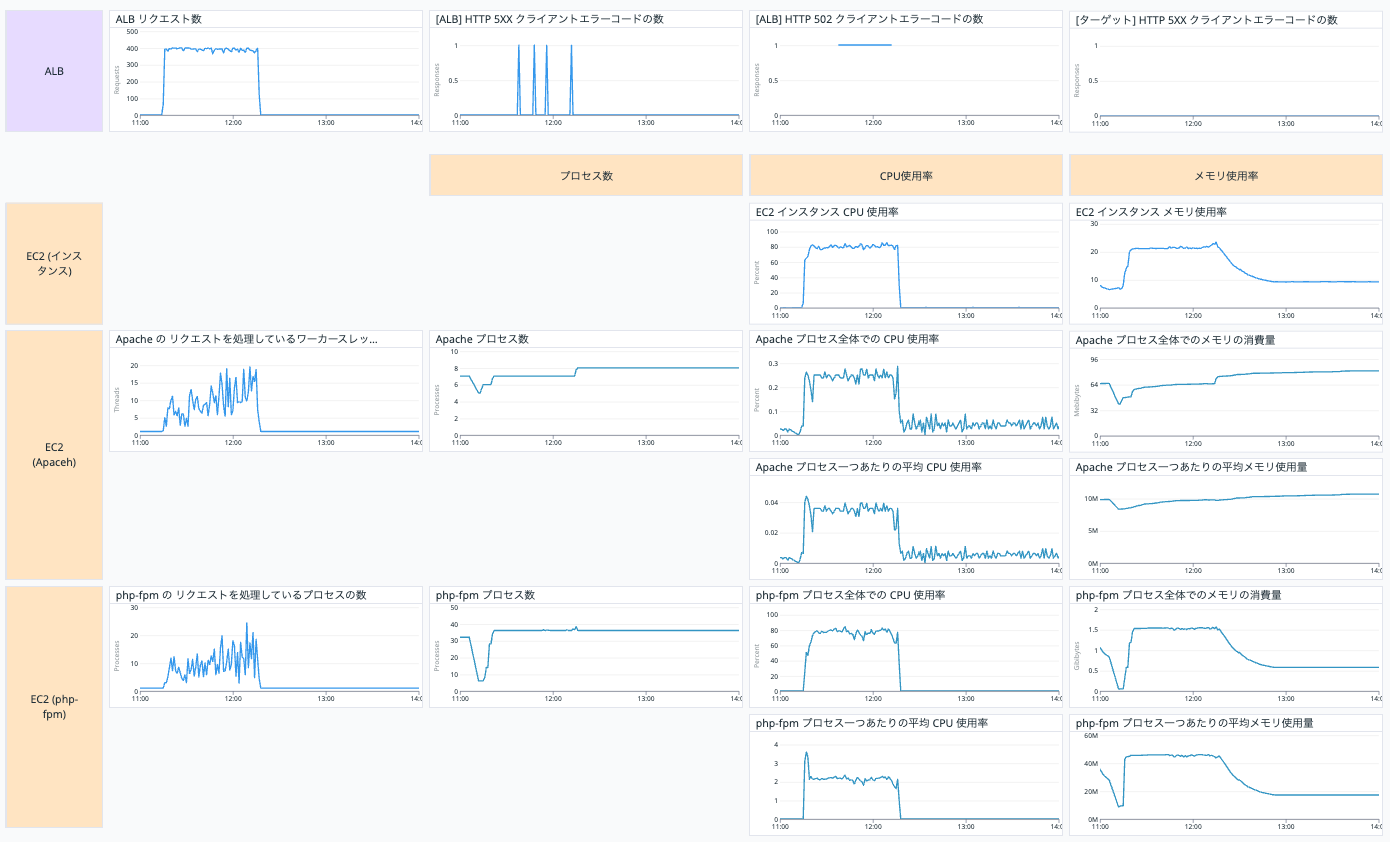
CPU 使用率は 80% 程度で、メモリ使用率は 20% 程度なのでリソースの使用具合としては大丈夫そうですね。
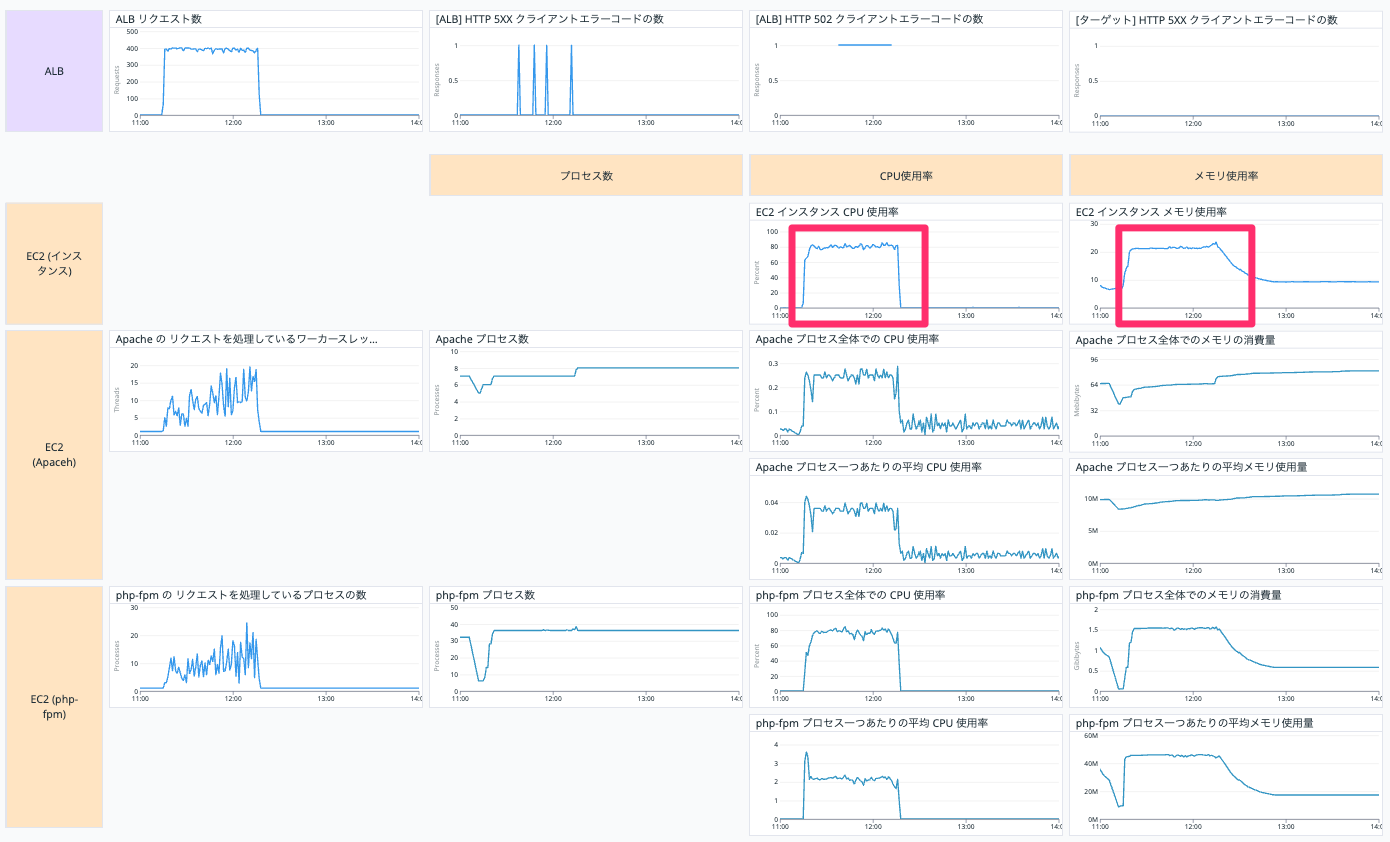
しかし、502 エラー多くなってしまっています。
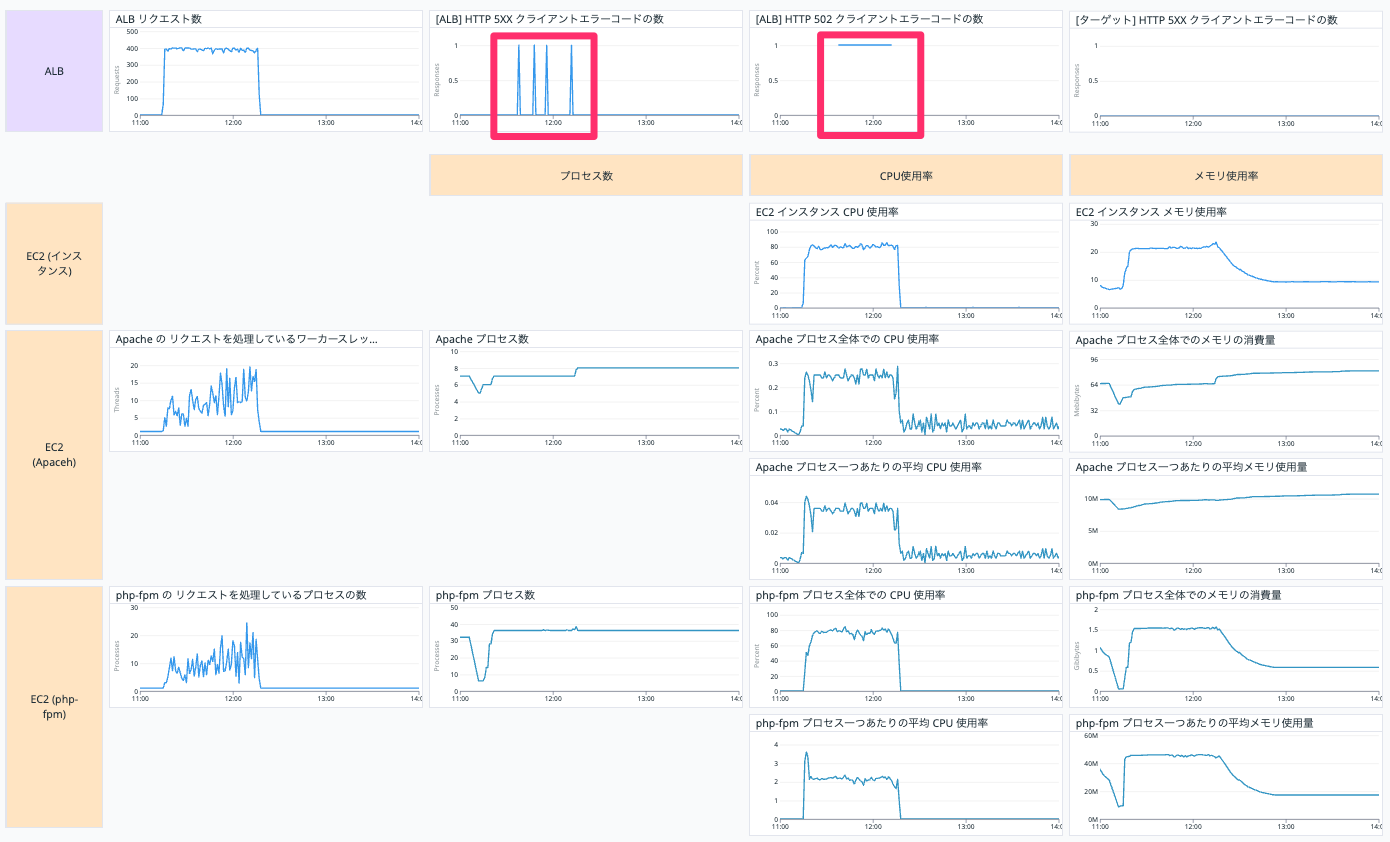
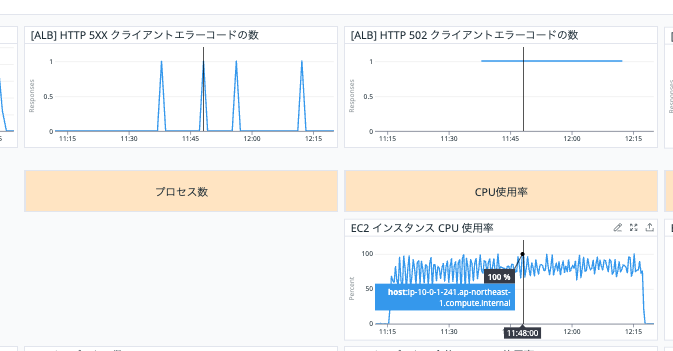
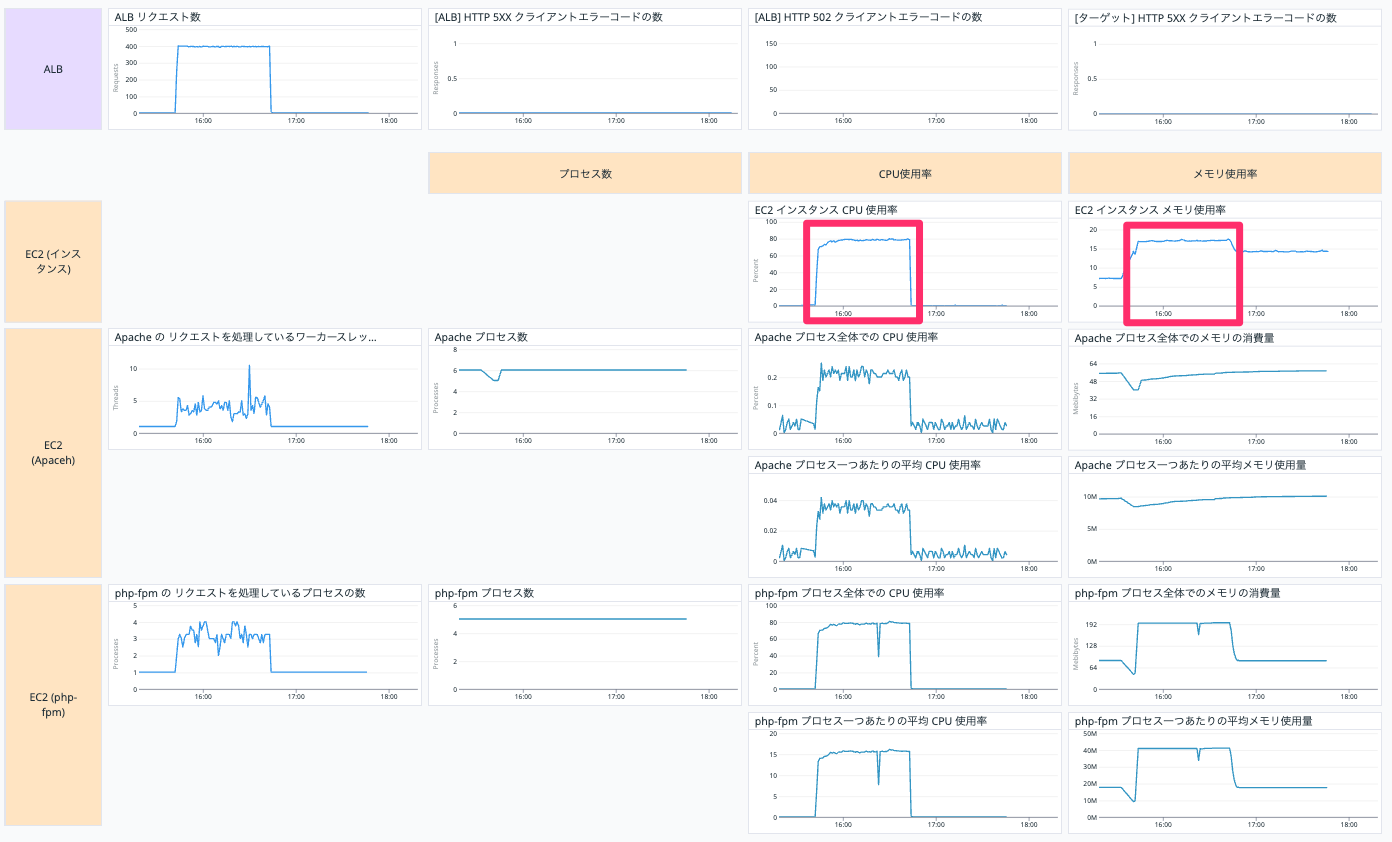
拡大して見てみると EC2 インスタンスの CPU 使用率を確認すると 100 % に達しているタイミングがあります。
EC2 インスタンスで処理待ちのリクエストがタイムアウトして結果的に 502 Bad Gateway になったのではないかと考えられます。
CPU を多く使っているのは php-fpm のようです。
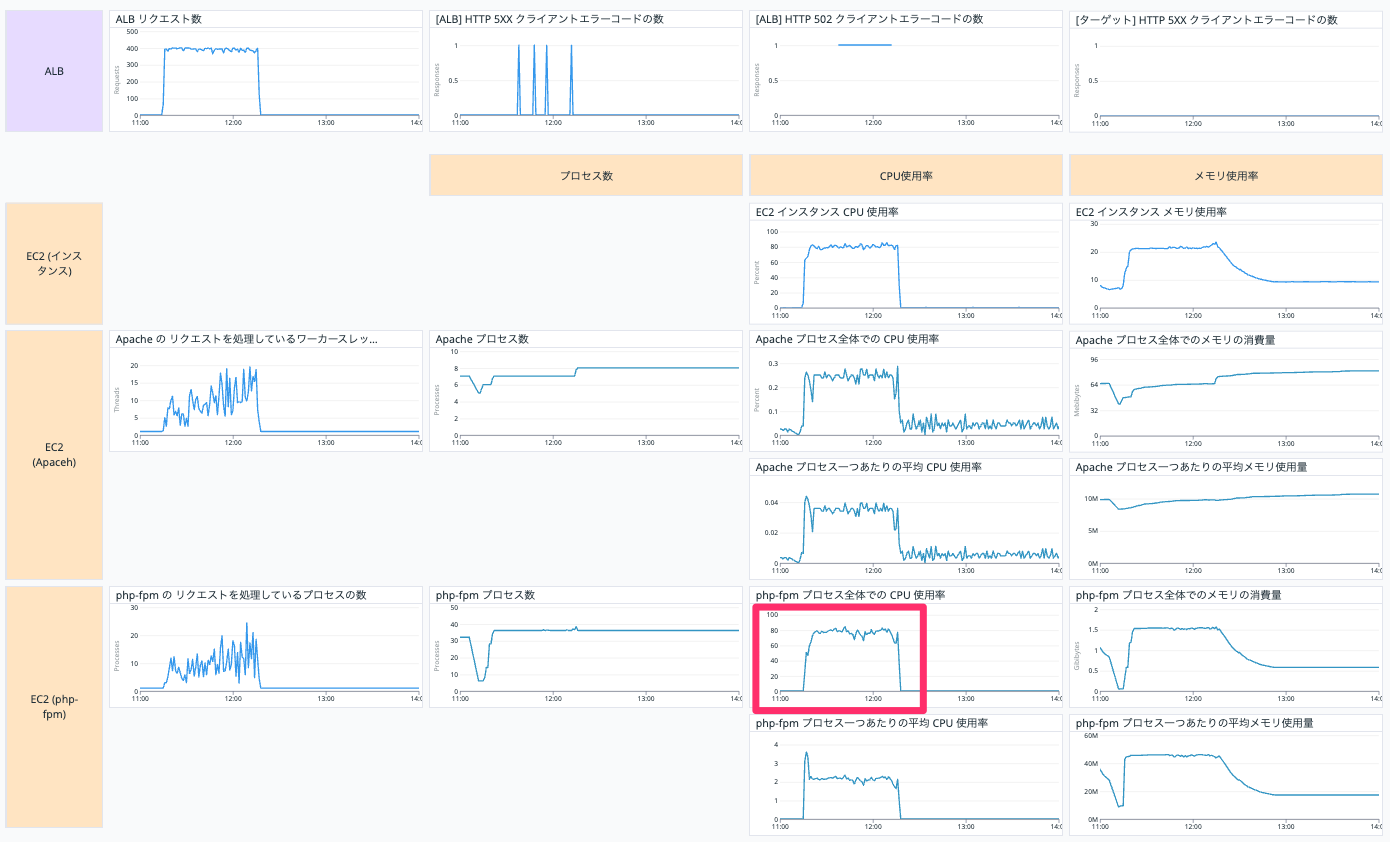
なので、php-fpm のチューニングでエラー発生を解決できないかを探ります。
php-fpm のチューニング
pm について
まずは pm の値です。
pm は以下の公式ドキュメントにある通り、プロセスマネージャが子プロセスの数を制御する方法を指定します。
https://www.php.net/manual/ja/install.fpm.configuration.php
プロセスマネージャが子プロセスの数を制御する方法を選択します。 使用可能な値: static, ondemand, dynamic このオプションは必須です。
この値はデフォルトではdynamicです。
dynamic は処理をするプロセスを柔軟に追加したり減らしたりすることができます。
しかし、同時処理可能なリクエスト数は CPU の論理コア数に依存するので、多くプロセスを起動してしまうと CPU がボトルネックになってしまうケースがあります。
また、dynamic ではプロセス起動に伴うオーバーヘッドも気になります。
サーバーに持たせている役割が限られている場合は php-fpm のプロセス数を静的に定める static にした方がいいケースがあります。
そのため今回は pm の値を static にしてみます。
pm.max_children について
pm.max_children はリクエストを処理をする子プロセスの数を指定します。
https://www.php.net/manual/ja/install.fpm.configuration.php
pm が static の場合は作成される子プロセスの数、 pm が dynamic の場合は作成される子プロセスの最大数。 このオプションは必須です。
static の場合は CPU の論理コア数の 2 倍から様子を見るというのが通説なので pm.max_children は 4 に設定します。
pm.max_requests について
pm.max_requests は各子プロセスが何回リクエストを処理したら再起動させるかを指定します。
https://www.php.net/manual/ja/install.fpm.configuration.php
各子プロセスが、再起動するまでに実行するリクエスト数。 サードパーティのライブラリにおけるメモリリークの回避策として便利です。 再起動せずにずっとリクエストを処理させる場合は ‘0’ を指定します。 PHP_FCGI_MAX_REQUESTS と同じです。デフォルト値: 0
デフォルトが 0 なのでこのままだと子プロセスの再起動はされません。デフォルトのままだとプロセスが肥大化してメモリを圧迫するため適度なタイミングで再起動させたいところです。
今回 4,000 に設定します。
※ こちらの値ですが一度 12,000 にしたところエラーが多発してまったのであまり長くしすぎても良くないようで、調整した結果この環境では 4,000 くらいがちょうどいい様子でした。
php-fpm チューニングの結果
以下の内容に設定変更してみてどうなるか様子を見ます。
pm = static pm.max_children = 4 pm.max_requests = 4000
※ pm.start_servers, pm.min_spare_servers, pm.max_spare_servers については pm が dynamic の時のみ使う設定項目なので無効化します。
【テスト3】インスタンスサイズを m6i.large で php-fpm をチューニングした後に JMeter でリクエストを再現した結果をDatadog ダッシュボードで確認
テスト3の結果は以下です。
エラーが出なくなり一安心です😌
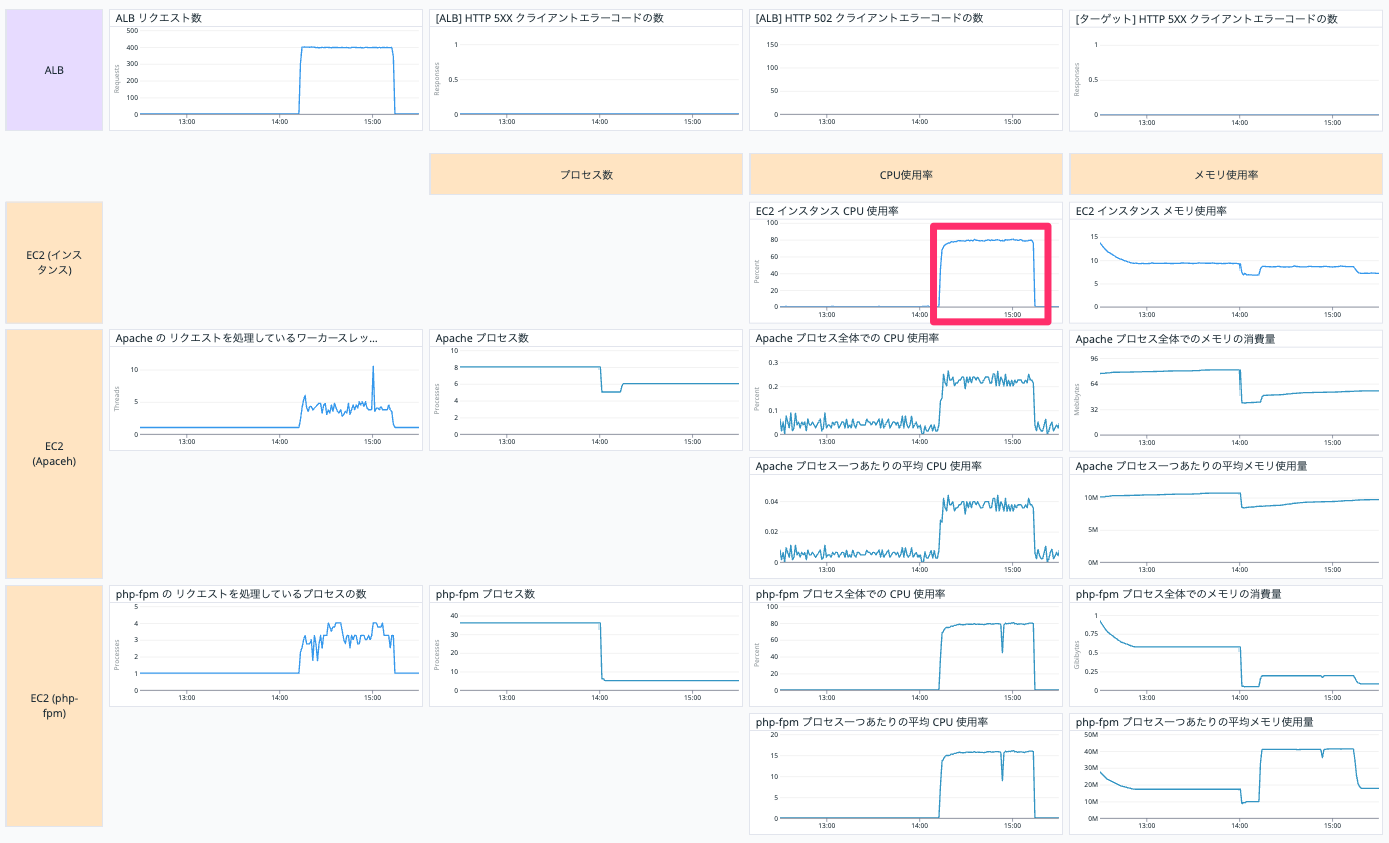
CPU 使用率は 80 % ほどなので変わらずちょうど良さそうですね。
メモリ使用率は 10% ほどになりました。
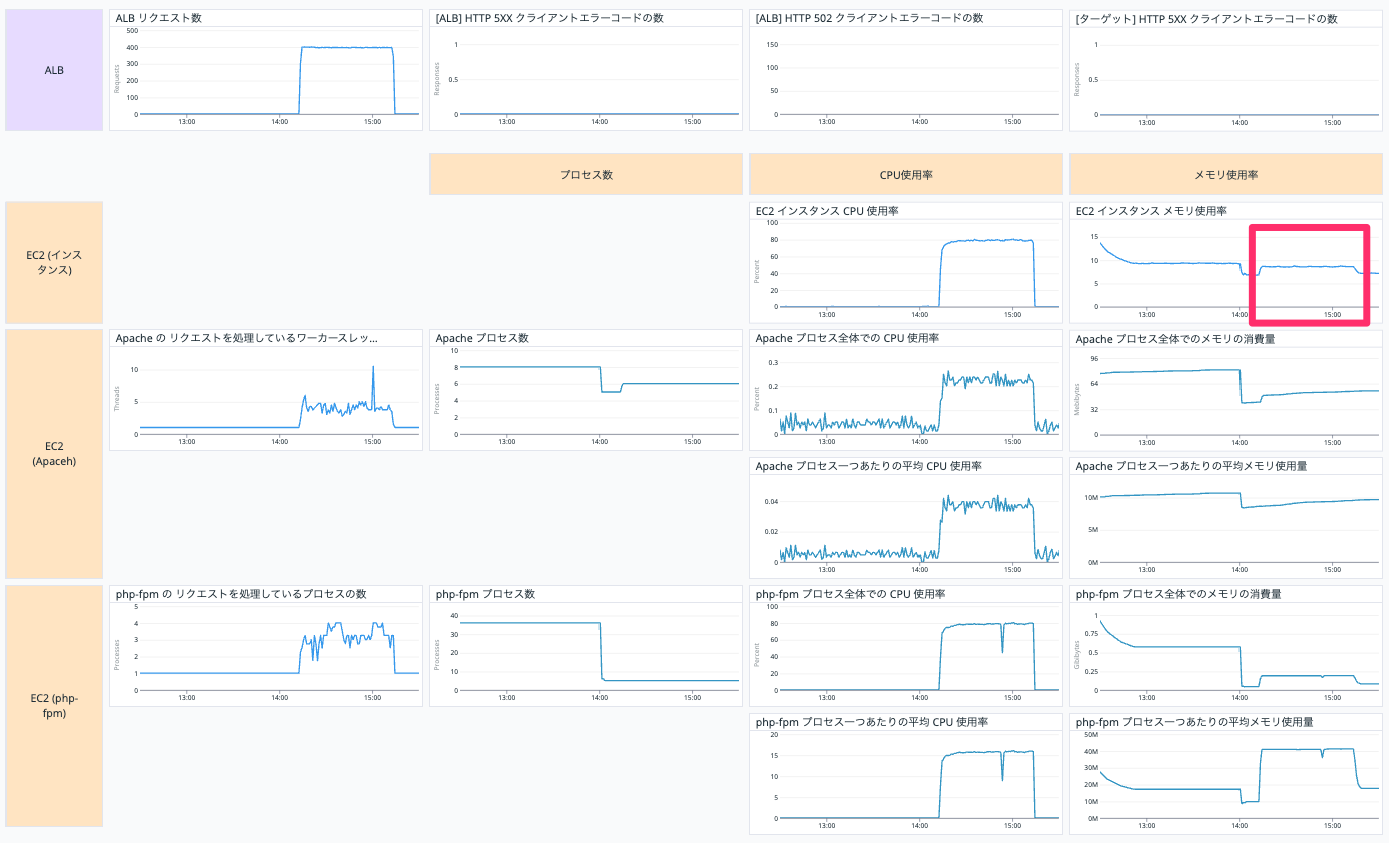
php-fpm の設定で pm を static にしたことで php-fpm のプロセス数が減ったためにメモリ使用率が下がっています。
さらに余剰気味になったので、CPU は今のままでいいけどメモリは少なくして費用を抑えられたら嬉しいですよね。
EC2 インスタンスのインスタンスタイプの中で「コンピューティング最適化」にあたる c6i.large というインスタンスタイプがその条件に該当するのでこれに変更してみます。
m6i.large と変更先の c6i.large のスペックの比較は以下です。 (2024/08/26 時点)
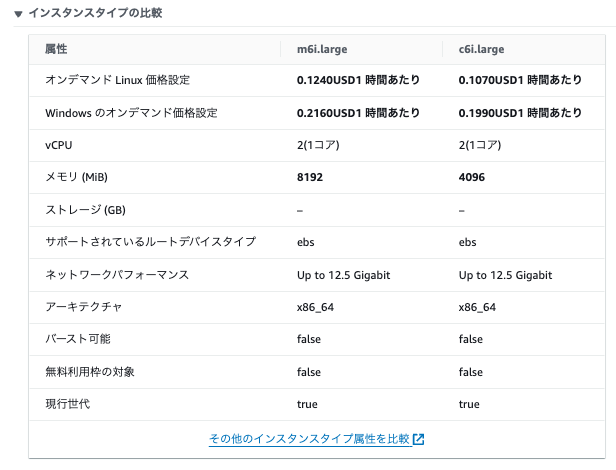
【テスト4】インスタンスサイズを c6i.large に変えた状態で JMeter でリクエストを再現した結果をDatadog ダッシュボードで確認
テスト4の結果は以下です。
エラーもなく無事にリクエストを処理できたみたいですね😌
CPU 使用率は 80% 程度で、メモリ使用率は 17% 程度でした。
CPU は今のままでいいけどメモリは少なくできるインスタンスサイズとしてはこれ以上のものはなさそうなので、この環境においては c6i.large がちょうど良いということになりそうです。
Apache のチューニングはどうするか
この状態だとこれ以上のリクエスト (例えば 500リクエスト/分) が来たらサーバー的に厳しそうなので、
Apache 側のチューニングでこれ以上リクエストを受けないように調整したかったのですが、
ServerLimit の値を 5 にしてみたら意図せず Apache の子プロセスが 7 つになったりしてうまく制御ができませんでした。
Apache の公式ドキュメントを確認すると 16 以上にする場合に設定するように書かれているため、16 以下の制御はできない可能性があります。
https://httpd.apache.org/docs/current/ja/mod/mpm_common.html
worker, leader, threadpool MPM では、 MaxClients と ThreadsPerChild の設定で 16 サーバプロセス (デフォルト) 以上必要になる場合にのみ使用してください。
そのため Apache については一旦デフォルトの設定のまま利用することとします。
結果
最終的な環境の状態
| 大項目 | 中項目 | 小項目 | 値 | 備考欄 |
|---|---|---|---|---|
| インスタンス | インスタンスサイズ | – | c6i.large | 変更 |
| インスタンス | vCPU | – | 2 | 変更 |
| インスタンス | メモリ (GiB) | – | 4 | 変更 |
| サーバー内部 | OS | Amazon Linux 2 | – | |
| サーバー内部 | Apahe | バージョン | 2.4 | – |
| サーバー内部 | Apahe | MPM | event | – |
| サーバー内部 | Apahe | ThreadsPerChild | 25 | デフォルト |
| サーバー内部 | Apahe | ServerLimit | 16 | デフォルト |
| サーバー内部 | Apahe | MaxRequestWorkers | 400 | デフォルト |
| サーバー内部 | PHP | バージョン | 8.2 | – |
| サーバー内部 | PHP | memory_limit | 128M | デフォルト |
| サーバー内部 | php-fpm | pm | static | 変更 |
| サーバー内部 | php-fpm | pm.max_children | 4 | 変更 |
| サーバー内部 | php-fpm | pm.start_servers | – | 変更 |
| サーバー内部 | php-fpm | pm.min_spare_servers | – | 変更 |
| サーバー内部 | php-fpm | pm.max_spare_servers | – | 変更 |
| サーバー内部 | php-fpm | pm.max_requests | 4,000 | 変更 |
| サーバー内部 | WordPress | バージョン | 6.6.1 | – |
Web サイトのレスポンスタイム
JMeter のグラフを使って最初の状態と最終的な状態の Web サイトのレスポンスタイムを比較します。
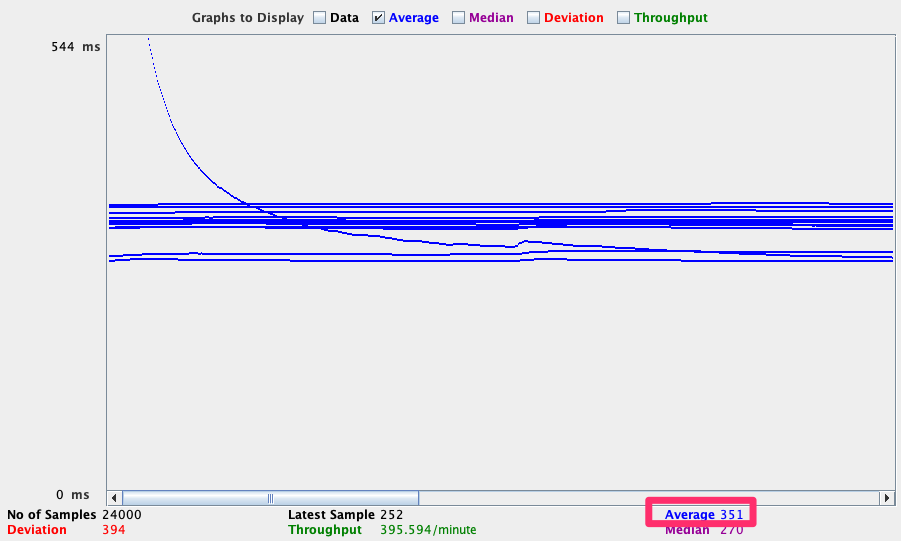
コスト最適化前の状態
コスト最適化前の状態のレスポンスタイムの平均時間は 351ミリ秒 (0.351秒) でした。
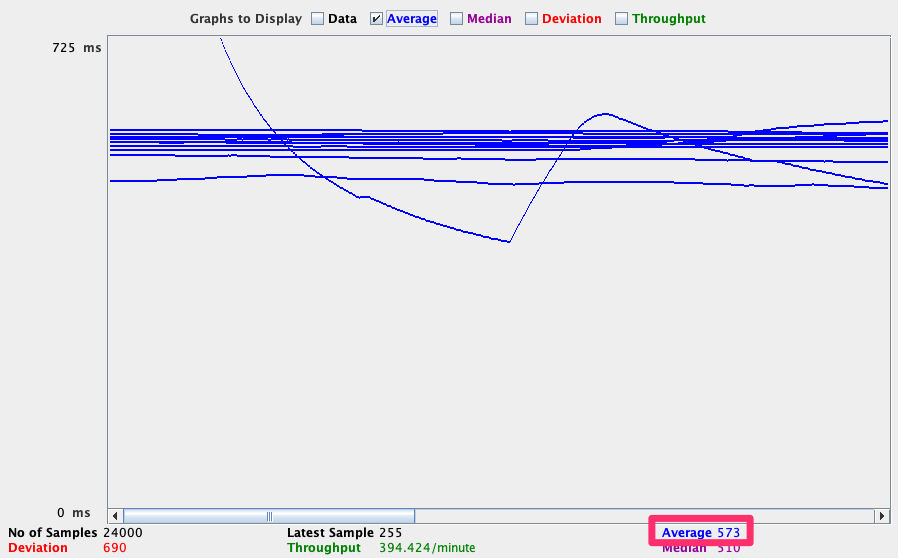
コスト最適化後の状態
コスト最適化後の状態のレスポンスタイムの平均時間は 573ミリ秒 (0.573秒) でした。
レスポンスタイムの比較
コスト最適化後の状態ではサーバーのリソース (特に CPU) をギリギリまで使っているため若干 Web サイトのレスポンスタイムが遅くなりました。
遅くなった時間としては 222ミリ秒 (0.222秒) なので、これを長いと見るか短いと見るかはその Web サイトの特性次第だと思いますが、後述するコスト削減額を考慮すると許容できる範囲ではないかと考えています。
コスト最適化の前後の比較
| 項目名 | 最適化前 | 最適化後 |
|---|---|---|
| インスタンスサイズ | m6i.xlarge | c6i.large |
| 月額料金 (USD) ※ 2024/08/26 時点 | 181.04 USD/月 | 78.11 USD/月 |
| 月額料金 (円) ※ 2024/08/26 時点 | 26,066 円/月 | 11,246 円/月 |
コスト削減額
26,066 – 11,246 = 14,820
なので 14,820円/月 のコスト削減となりました!
まとめ
Datadog のダッシュボードを活用することで現状を適切にモニタリングし得られた情報に基づいて適切にチューニングやインスタンスサイズの調整を行うことができたためコストの最適化を実現できました!
留意点
今回の内容はあくまでこの記事のために作成した環境における結果です。
すべての環境で同じ結果が得られるとは限りませんのでご了承ください。



