
Cloud Storage FUSE を利用することで、Cloud Runジョブ内でCloud Storageバケットをローカルファイルシステムとして扱うことができます。
本記事では、Cloud RunジョブにCloud Storage FUSEを統合する方法について説明します。
Cloud Storage FUSEとは
Cloud Storage FUSEは、Cloud Storageのバケットをローカルのファイルシステムのように操作できるツールです。
通常、Cloud Storageにファイルをアップロードしたりダウンロードする際は、APIやコマンドを使う必要がありますが、Cloud Storage FUSEを使えば、バケットをマウントして、ローカルディレクトリのようにファイルを読み書きできます。
Cloud Run ジョブとCloud Storage FUSEの連携
Cloud Run ジョブとCloud Storage FUSEを連携させると、ジョブ内でCloud Storageバケットをローカルディレクトリとして扱うことができます。Cloud Run ジョブのコンテナ内にCloud Storageバケットをマウントすることで、バケット内のファイルに直接アクセスしたり、新しいファイルを作成したりできます。
これにより、ファイルの処理やデータの操作が容易になり、既存のアプリケーションをほとんど変更せずにCloud Storageを活用できます。
実装の流れ
前提条件:Cloud Run ジョブとCloud Storageの作成が完了している状態
バケットのマウント
- Cloud Run ジョブの「編集」ボタン→「コンテナ、ボリューム、接続、セキュリティ」セクション→「ボリューム」タブ→「ボリュームを追加」をクリック
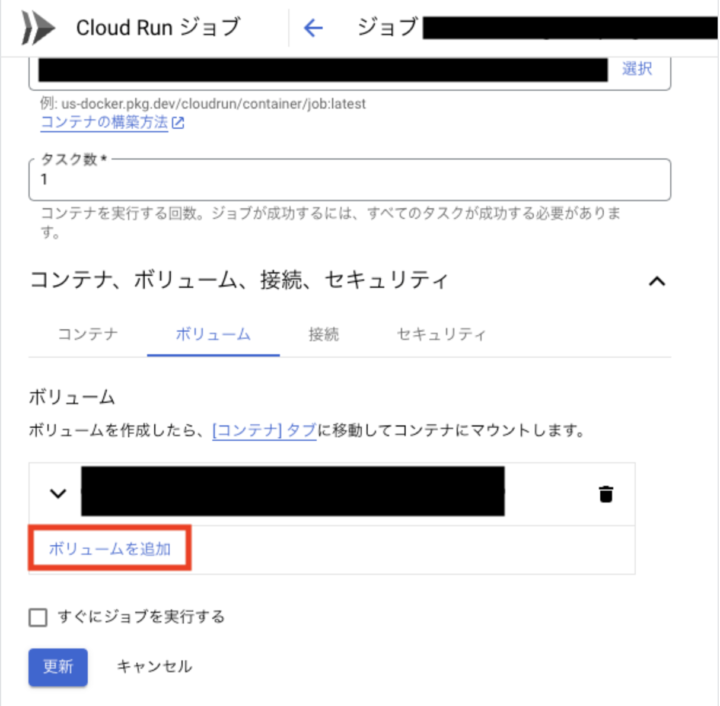
- 新しいボリュームを設定し「完了」ボタンをクリック
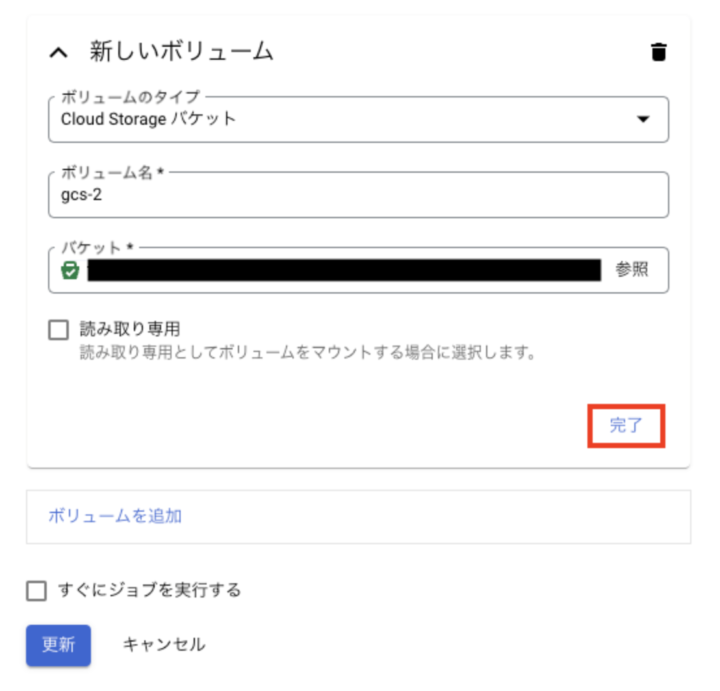
- コンテナタブに移動
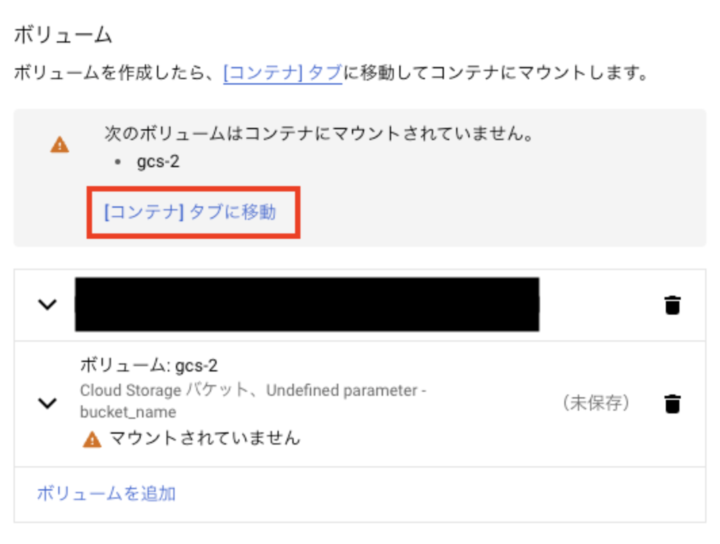
- ボリュームをマウント
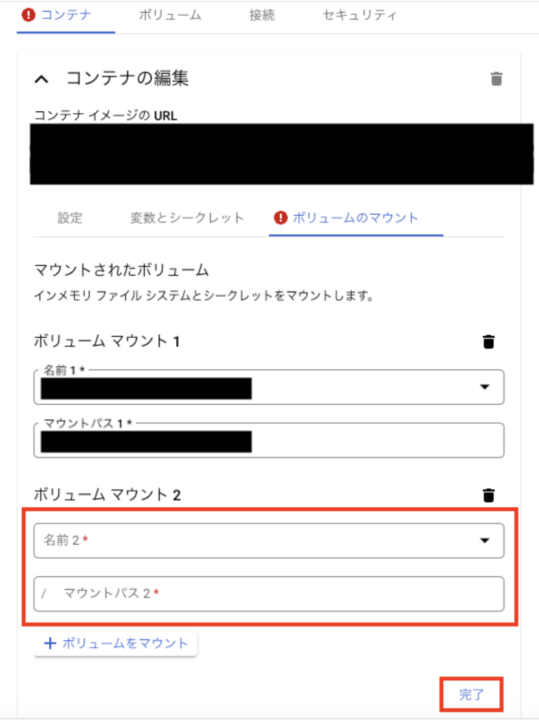
以上でバケットのマウントは完了です。
マウントされたディレクトリを通じてのファイル操作
以下のファイルを作成します。
- Dockerfile
- main.py
- Dockerfileは以下の内容で、Pythonスクリプトを実行するためのシンプルなものです。
FROM python:3.9-slim WORKDIR /app RUN pip install requests google-cloud-secret-manager COPY . . CMD ["python", "main.py"]
- main.pyはBacklogのAPIを実行し、特定のページの内容を取得し、ローカルディレクトリに保存(Cloud Storageにアップロード)する処理を行います。
import json
import os
import requests
from google.cloud import secretmanager
# 定数
BASE_URL = "https://example.backlog.jp/api/v2/wikis/"
PROJECT_ID = "your_project_id"
SECRET_ID = "your_secret_id"
VERSION = "latest"
MOUNT_POINT = "/mnt/backlog_wiki"
PAGE_ID = "0000000000"
FILENAME = "page.txt"
# Secret ManagerからAPIキーを取得する
def get_api_key() -> str:
client = secretmanager.SecretManagerServiceClient()
secret_name = f"projects/{PROJECT_ID}/secrets/{SECRET_ID}/versions/{VERSION}"
response = client.access_secret_version(request={"name": secret_name})
return response.payload.data.decode("UTF-8")
# Backlogから特定のページを取得してローカルディレクトリ(Cloud Storage)に保存
def download_backlog_page(api_key: str):
url = f"{BASE_URL}{PAGE_ID}?apiKey={api_key}"
response = requests.get(url)
if not os.path.exists(MOUNT_POINT):
os.makedirs(MOUNT_POINT)
output_path = os.path.join(MOUNT_POINT, FILENAME)
with open(output_path, "w") as file:
file.write(response.text)
def main():
try:
api_key = get_api_key()
download_backlog_page(api_key)
except Exception as e:
error_message = json.dumps({"message": f"エラーが発生: {str(e)}", "severity": "ERROR"})
print(error_message)
if __name__ == "__main__":
main()
ジョブの作成と実行
1.まずはジョブを作成します。
gcloud run jobs deploy JOB_NAME \ --source . \ --tasks 1 \ --max-retries 5 \ --region REGION \ --project=PROJECT
- 次にジョブを実行します。
gcloud run jobs create JOB_NAME --execute-now --region=REGION
結果を確認する
Cloud Storageバケットを確認すると、取得したデータがアップロードされていることを確認できます。
終わりに
Cloud Storage FUSEをCloud Run ジョブに導入することで、Cloud StorageのAPI実行をする処理を実装しなくてもよくなるため、クラウド上のファイルストレージの扱いが簡単になったと思います。
Cloud Storage FUSEは、クラウドストレージをローカルファイルシステムとしてマウントする機能を提供します。これにより、ファイルの読み書きが簡素化され、従来のファイルシステムと同じ感覚で操作できるようになります。
参考文献
https://cloud.google.com/storage/docs/gcs-fuse?hl=ja
https://cloud.google.com/run/docs/create-jobs?hl=ja
https://cloud.google.com/run/docs/execute/jobs?hl=ja