
概要:
Google Cloud環境にて監視運用を行うため、監視設計を検討いたしました。
監視設計の考え方の整理と、合わせてGoogle Cloudにて実現した記録について、今回題材として扱わせていただきます。
環境
Google Cloud
使用サービス
Google Compute Engine
Cloud Run
Cloud SQL
Cloud Storage
Cloud Load Balancing
Serverless VPC Access connector
システム概要
Webサービス提供
アプリサービス提供
構成図は以下のようなイメージです。かなりシンプルな構成に仕上がっています。
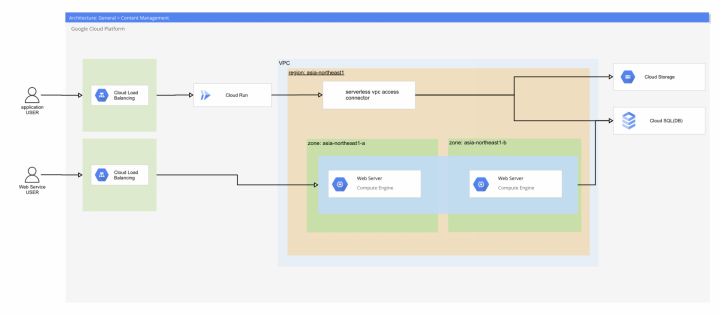
Google CloudサービスをAWSサービスで表現する場合、以下のサービスと同等の立ち位置といえます。提供されている機能が若干異なるサービスもありますので、あくまで比較対象として記載します。
Google Compute Engine → Amazon EC2 (Elastic Compute Cloud)
Cloud SQL → Amazon RDS (Relational Database Service)
Cloud Storage → Amazon S3 (Simple Storage Service)
Cloud Load Balancing → Amazon ELB (Elastic Load Balancing)
Cloud Run → AWS Fargate
Serverless VPC Access connector → AWS PrivateLink
監視設計
続いて、監視設計にあたって、メトリクスとして必要な監視を記載します。
運用を行う上で必要となってくるのは、ユーザーからサービス(今回の場合Web/アプリ)の間のうち、どこまで通信が届いているかを切り分けることです。
どこまで届いているか切り分けポイントとする箇所は、各Google Cloudのサービスとなります。
したがって、各サービスについての監視をどこまで設定するか検討する必要があります。(全てのメトリクスを監視しても、切り分けポイントにならなければ意味がありませんので、あくまで必要な監視の検討です。)
・Google Compute Engine
リソース
・CPU
・メモリ
・ディスク
プロセス監視
・SSHD、Nginx等
考え方:
Google Compute EngineではOS以上はユーザーの責任境界部分になるため、ハードウェア箇所以外は監視が必要です。
監視メトリクスには、リソース状況とプロセス起動状況を監視します。
・Cloud SQL
リソース
・CPU
・メモリ
・ディスク
・フェイルオーバー状況
考え方:
マネージドサービスのため、障害発生時には自動的な復旧(フェイルオーバー)が機能します。
監視メトリクスは、リソース状況と合わせてフェイルオーバー発生について監視を設定します。
・Cloud Load Balancing
リソース
・レイテンシー
・ターゲットグループ登録状況
考え方:
サービスを提供するGoogle Compute EngineやCloud Runの手前に、ロードバランシングを機能させます。
そのため、ターゲット宛先が正しく宛先として設定されているかをターゲットグループ登録状況の監視を行います。
また、ターゲットへの遅延が想定範囲内かを確認するレイテンシー監視を行います。
・Cloud Run
リソース
・CPU
・メモリ
・レイテンシー
・コンテナ稼働状況
考え方:
マネージドサービスになります。コンテナをデプロイし、アプリケーションを起動させることが可能となりますので、対象のコンテナが起動しているかコンテナ稼働状況を監視します。(起動数が0でないことを監視して、異常終了していない状態を監視設定としました)
また、CPU使用率を監視していますが、Cloud Runでは自動スケーリング設定を行うと、必要インスタンスを自動で判断し調整します。
Google Compute EngineでのCPU使用率監視とは異なりますので、メトリクス上でもその点を考慮して見なければいけません。
参考: https://cloud.google.com/run/docs/about-instance-autoscaling?hl=ja
・外形監視
リクエスト対象URL
考え方:
提供しているサービスのログインURL等を監視します。
DatadogやNew Relicでの外形監視を想定した場合、外部からアクセス可能なURLである必要があります。
おわりに
今回はGoogle Cloudでの監視設計の考え方を記載させていただきました。
具体的な監視設定については機会があれば記載させていただきます。