
はじめに
AWS BackupはAWSのストレージ系のリソースのバックアップを管理・保存できる便利なサービスです。
AWS Backupを使用している方は多いと思いますが、保存しているバックアップからの復元が問題なくできるかどうかの確認まで、定期的にテストしている方はどれくらいいらっしゃるでしょうか?
この記事で紹介する「復元テスト」はAWS Backupの機能の一つで、バックアップからの復元を定期実行できる便利な機能です。
復元をスケジューリングして自動化できるだけではなく、作成されたリソースの削除まで自動で行なってくれる優れものです。
今回は、実際に復元テスト機能を使用してFSx for Windows File Serverの復元作業の自動化を試みたので、それについて記載しています。
また、検証をしたところ復元テストにもサービス的な制約があることがわかりました。
その制約についても触れ、どのように解決したのかをご紹介します。
※この記事では2024年8月現在の状態を元にしています。サービス仕様が変更される可能性もありますので、最新情報は公式ドキュメントを確認ください。
https://docs.aws.amazon.com/ja_jp/aws-backup/latest/devguide/restore-testing.html
補足
本記事は弊社にて開催している勉強会「雲勉」で登壇した際の内容を元にしております。
動画をご覧になりたい方は、以下のリンクよりご確認ください!
資料は以下に保存しております。
AWS Backupの復元テストについて
検証の具体的な内容に移る前に、AWS Backupの復元テストについて簡単に説明を記載しておきます。
概要
前述の通り、AWS Backupで取得したバックアップからのリストアを自動化し、定期的なリストアテストの自動化を実現できるのが「復元テスト」という機能です。
https://docs.aws.amazon.com/ja_jp/aws-backup/latest/devguide/restore-testing.html
復元テストのセットアップ内容は以下の2つに分けられます。
- 復元テストプランの設定
- 復元テストプランに対するリソースの割り当て
さらにこの復元テストによって作成されたリソースは自動的に削除されます。
削除するかどうかの判定は、復元テスト機能によって自動的に付与されるタグを参考にしているとのことです。
また、復元テストの成功/失敗とリソース削除の成功/失敗は「復元ジョブ」の中で確認ができます。
なので、もし失敗したとしてもEventBridgeなどを使うことで通知することも可能です。
オンデマンド復元との違い
AWS Backupには、自動的にバックアップからのリストアをしてくれる復元テストとは違い、手動でアドボックにリストアを実行する機能もあります。
この機能を、ドキュメントの中では「オンデマンド復元」と呼んでいます。
オンデマンド復元と復元テストの違いについてはドキュメントに記載されています。
簡単にまとめると以下のような違いがあります。
- リストアするタイミング・頻度
- 復元テストは定期実行される
- オンデマンド復元は一時的なリストア
- リージョン
- 復元テストは一部リージョン(アメリカのGovCloudリージョンや中国リージョン)で利用不可
- オンデマンド復元はAWS Backupが提供されているリージョンなら使用可能
- リストア実行後の挙動
- 復元テストでは、リストアが完了すると復元されたリソースは削除される
- オンデマンド復元では、復元されたリソースはそのまま残る
- タグ
- 復元テストでは、復元されたリソースに管理用のタグが自動的に付与される
- オンデマンド復元ではタグをつけずに復元することが可能
検証を行うにあたっての前提
検証環境の状態
今回は実際の案件での要件に合わせ、FSxのWindows認証に「自己管理型 Microsoft Active Directory」を選択しています。
なお、この記事中では「自己管理型 Microsoft Active Directory」のことを「セルフマネージドAD」と呼びます。
セルフマネージドADはAD環境を自前で用意されていることが前提となっていますので、ADDC(Active Directory Domain Controller)の機能を持つWindows Serverが必要になります。
そのため、ADDCの機能を有効化しセットアップしたEC2を別途作成しています。
ADDCで検証用にフォレストを新しく作成し、「test」というユーザーを作成しています。
そのユーザーを使って、FSxをAD参加させています。
全体構成
上記に記載した内容も含め、今回の検証時に作成した環境を記載しておきます。
なお今回は、復元テストを使って復旧したFSxは別VPCに配置するという要件があったため、VPCを分けています。
本番VPCにあるFSxのバックアップをAWS Backupで定期的に取得し、そのバックアップを使用して復元テスト用VPCにリストアする復元テストを設定する、というのがゴールです。
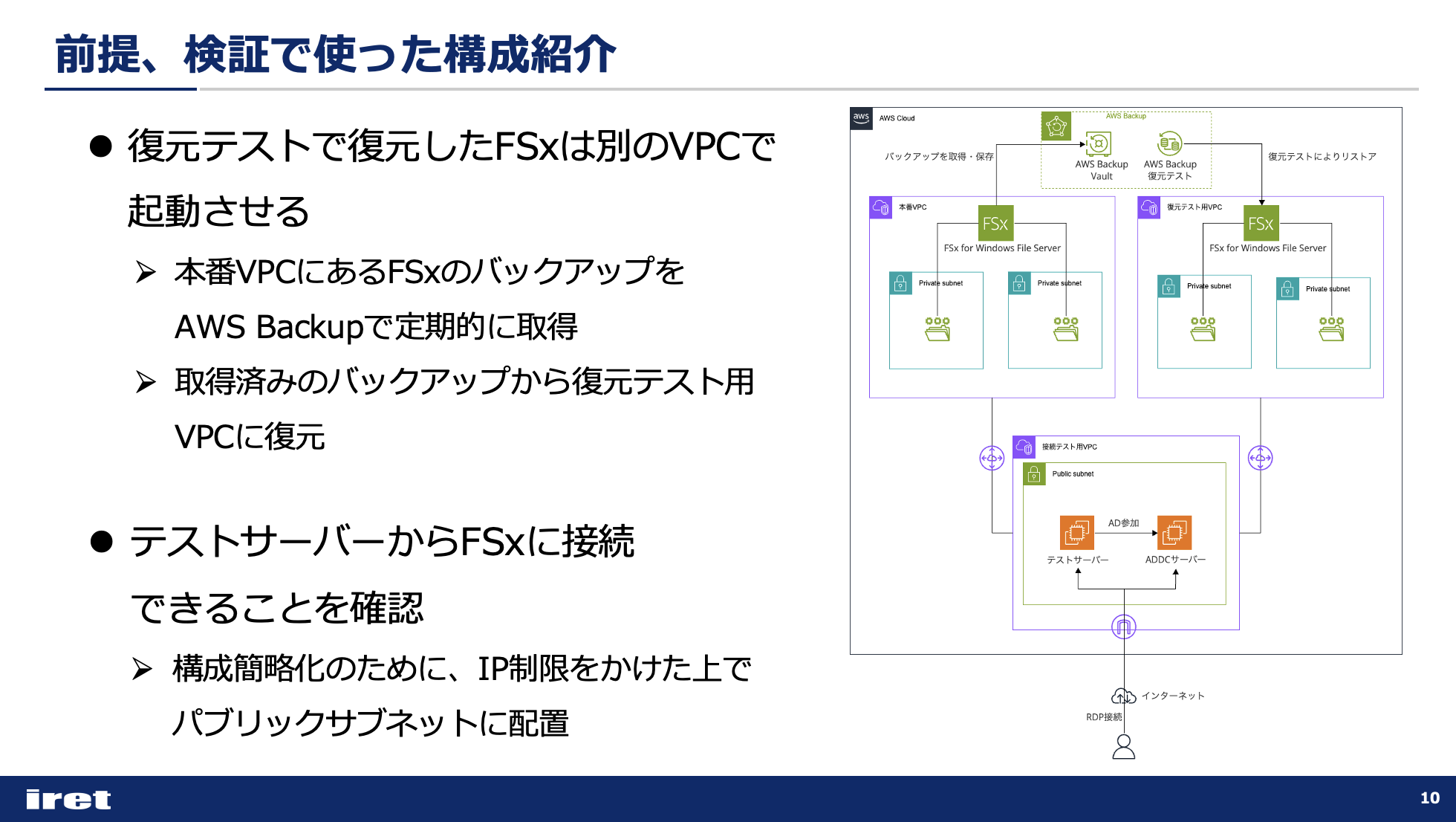
FSxに加えて、テストサーバーもADに参加させています。
復元テストを実装してみた
AWS Backupのバックアッププランやルール、ボールトの設定手順、およびManaged ADの設定手順は割愛します。
AWS Backupのプラン、ルール、ボールトの作成方法について確認したい方は以下のドキュメントなどを参考にしてみてください。
https://docs.aws.amazon.com/ja_jp/aws-backup/latest/devguide/create-a-scheduled-backup.html
Managed ADのセットアップ手順については以下のドキュメントが参考になると思います。
https://docs.aws.amazon.com/ja_jp/directoryservice/latest/admin-guide/ms_ad_getting_started.html
復元テストの初期設定
まずは復元テストプランを作成していきます。
AWS Backupの画面の左に[復元テスト]がありますのでこれをクリックし、[復元テストプランを作成]をクリックします。
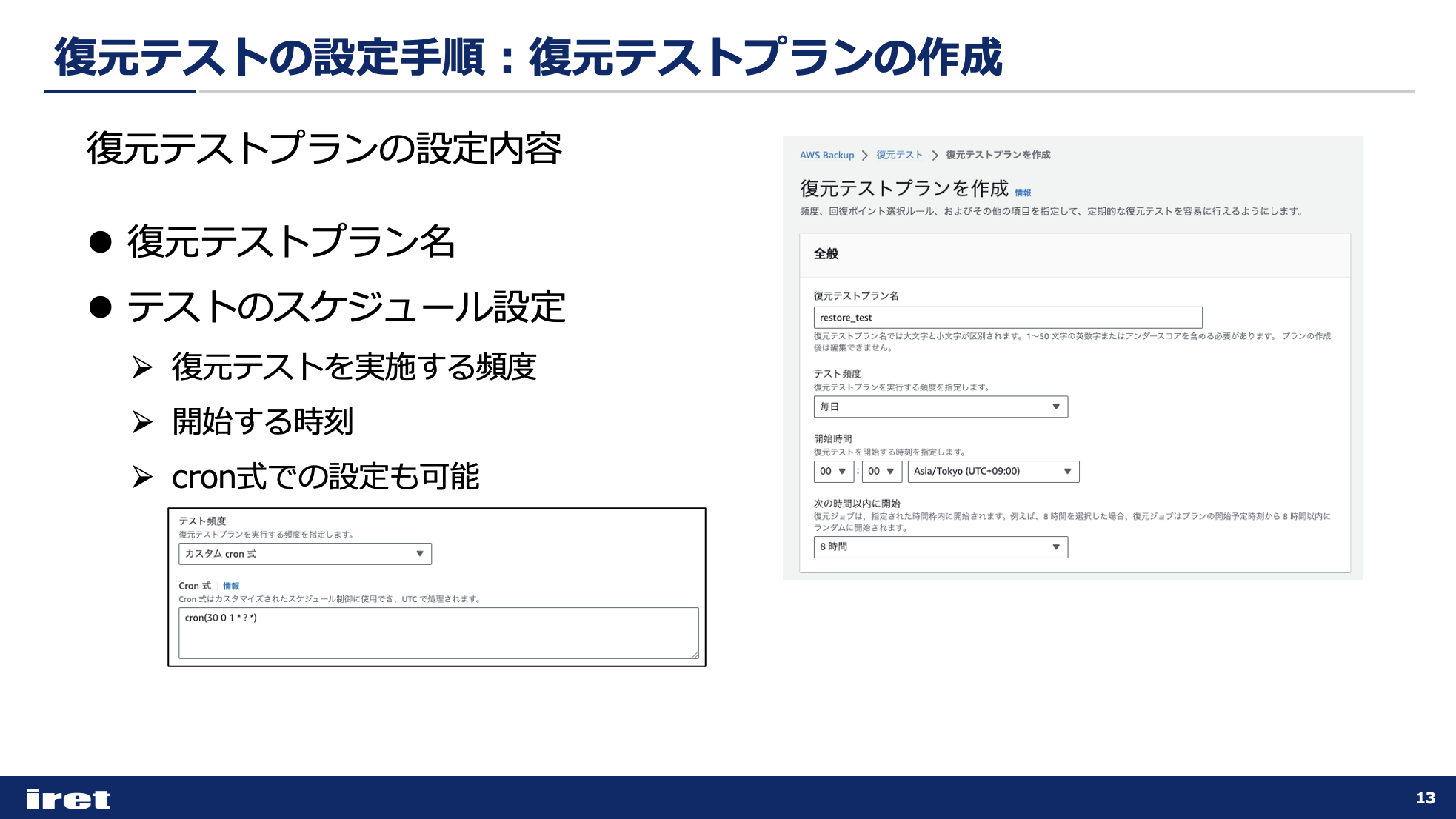
復元テストプランの作成画面に移るので、各パラメータを入力していきます。

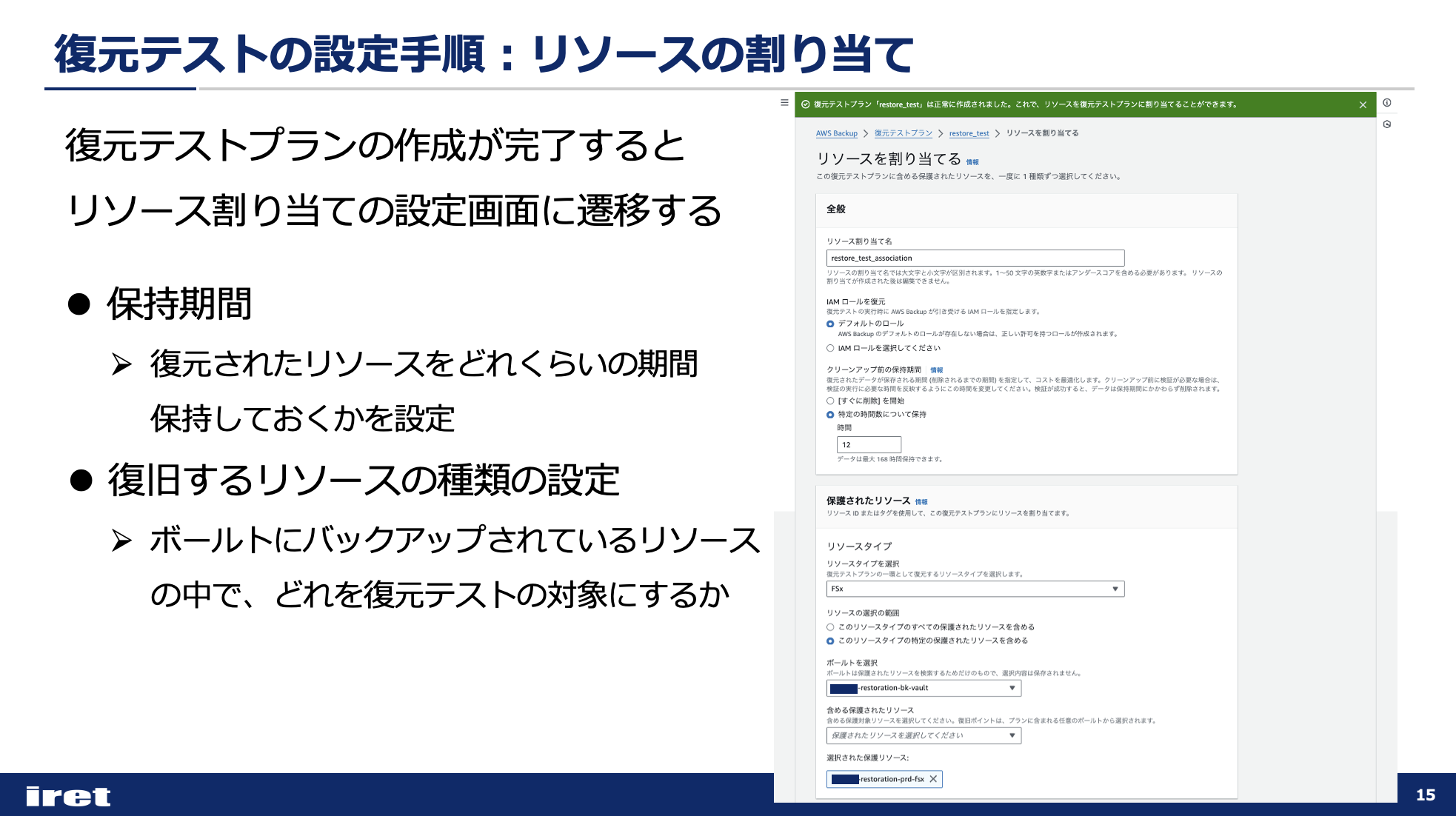
復元テストプランが作成できるとリソースの割り当ての設定画面に遷移するので、必要なパラメータを入力していきます。

作成が完了したことを確認します。
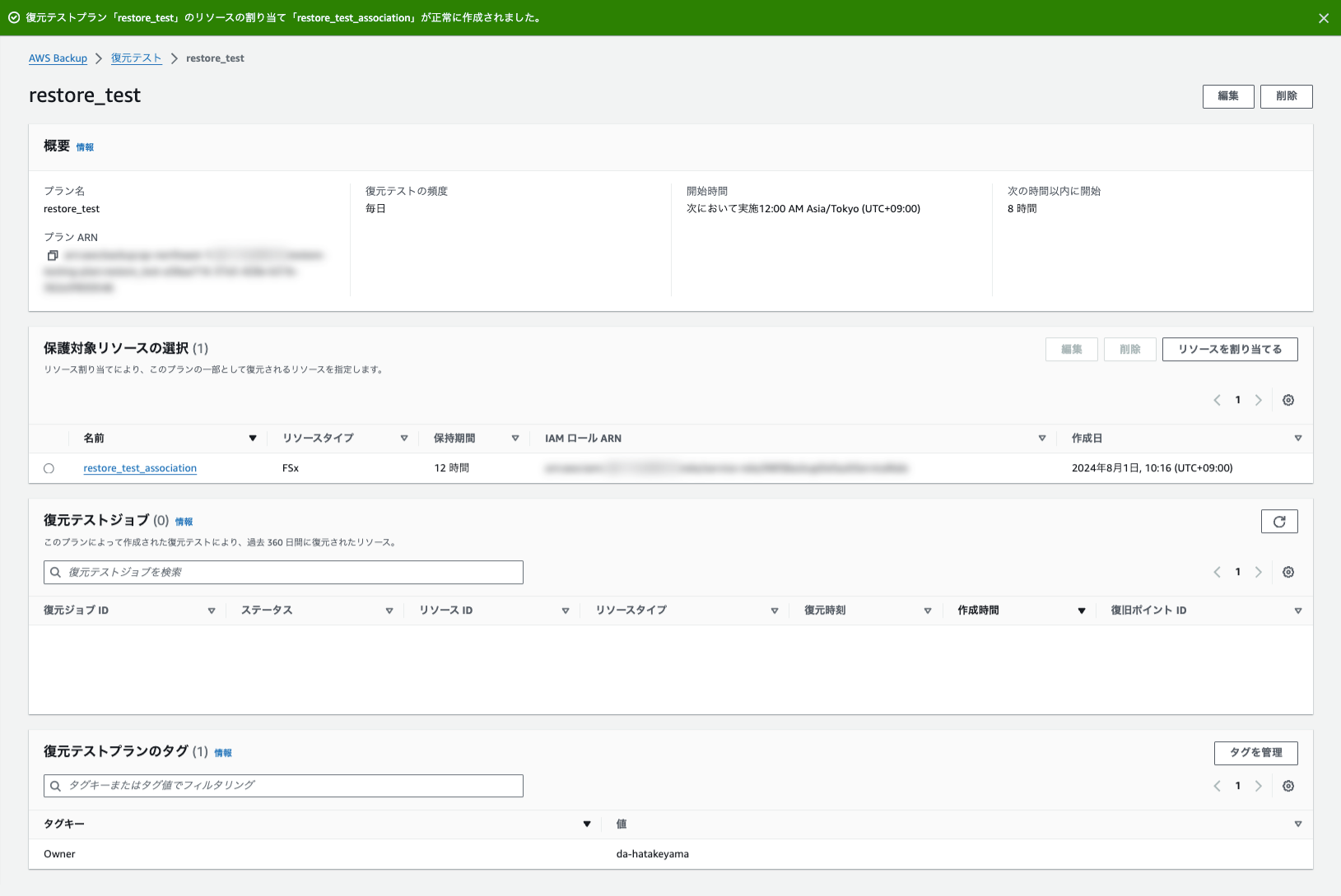
これで復元テストの設定は完了ですので、あとはスケジュール設定したタイミングまで待機すればOKです。
復元テストの実行
実際に復元テストが実行されると、AWS Backupの画面で「ジョブ」として詳細を確認することができます。
なので今回もジョブを確認したところ、復元ジョブが失敗していました。
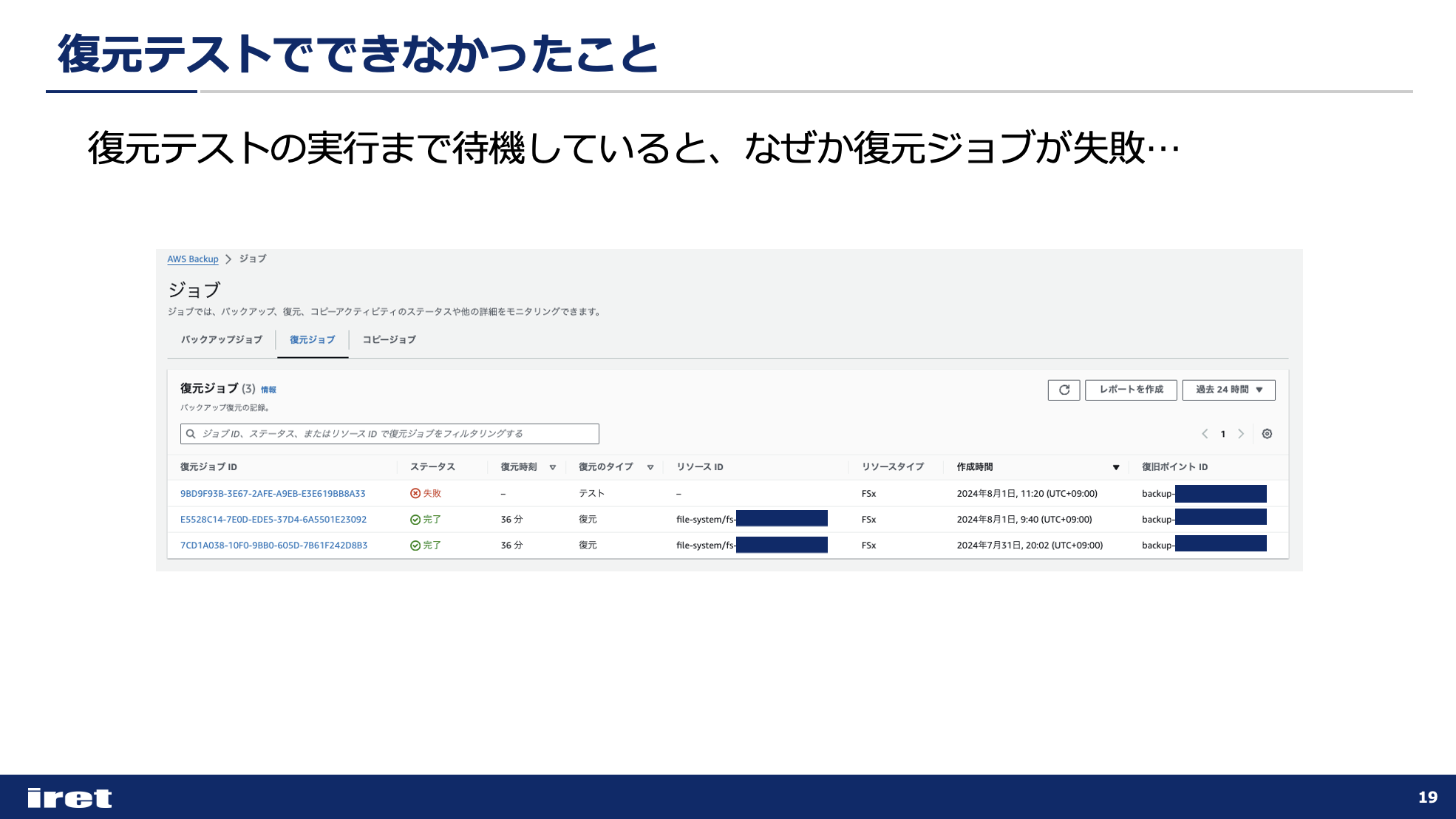
ジョブIDをクリックして詳細を確認すると、パラメータが不足しているという旨のエラーが出ていました。
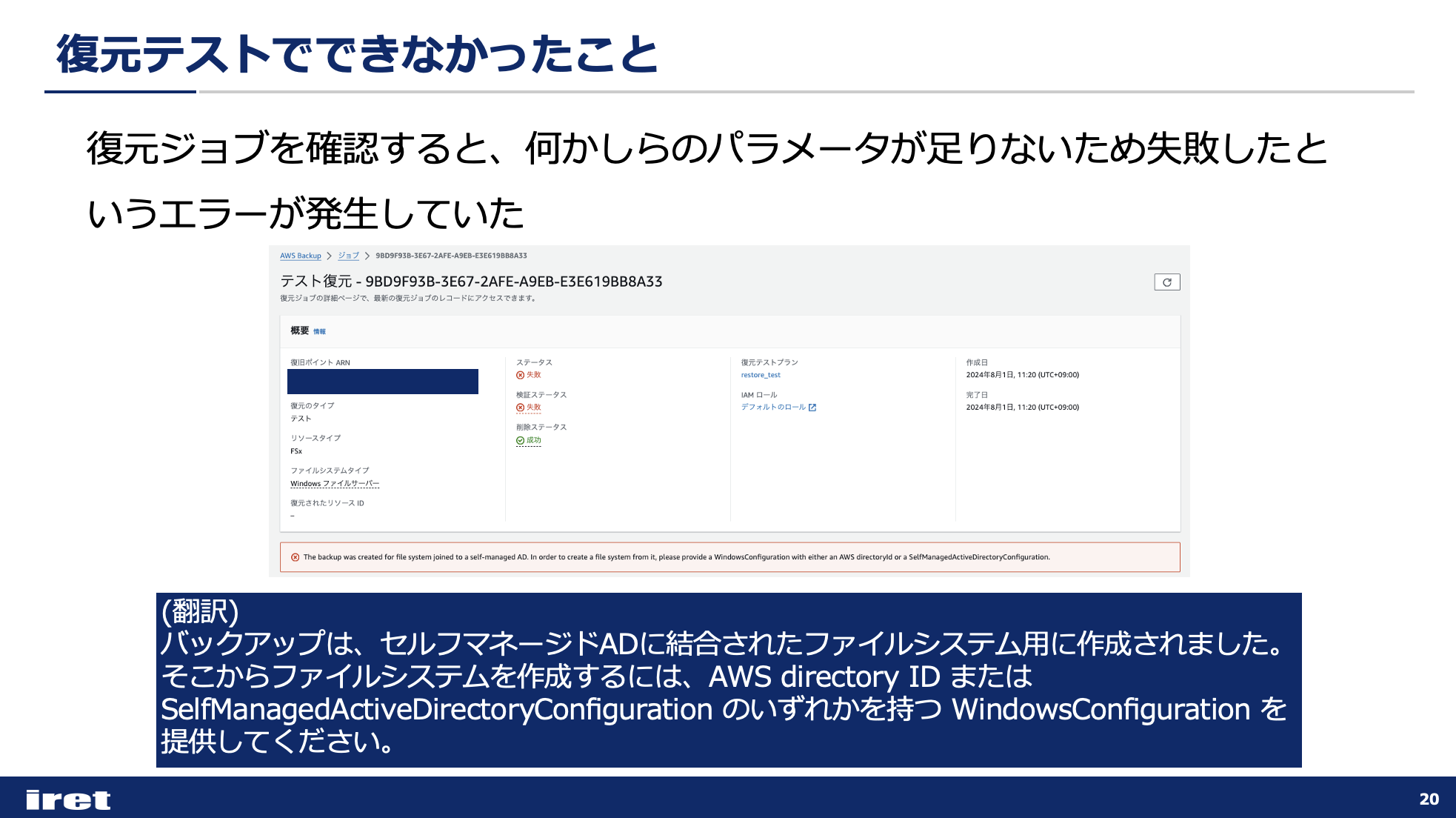
The backup was created for file system joined to a self-managed AD. In order to create a file system from it, please provide a WindowsConfiguration with either an AWS directoryId or a SelfManagedActiveDirectoryConfiguration.
(翻訳)バックアップは、セルフマネージドADに結合されたファイルシステム用に作成されました。 そこからファイルシステムを作成するには、AWS directoryId または SelfManagedActiveDirectoryConfiguration のいずれかを持つ WindowsConfiguration を提供してください。
ここで一度、ほぼ同じ条件で実施したオンデマンド復元のジョブを見てみます(この復元は問題なく成功しているものです)

成功したオンデマンド復元では、windowsconfiguration配下のSelfManagedActiveDirectoryConfigurationという部分にWindows認証で使用するパラメータが格納されています。
この部分が復元テストのジョブではごっそり欠落していました。
ここで公式ドキュメントを調べてみると、リソースのタイプによっては上書きが必要なメタデータがあるとのことでした。
また、自動的に保管してくれるメタデータもあるがFSxの場合は補完が不十分とも書かれていました。
さらに、上書きができない場合もあるとも書かれています。
https://docs.aws.amazon.com/ja_jp/aws-backup/latest/devguide/restore-testing-inferred-metadata.html

コンソールをいくら調べてみても、SelfManagedActiveDirectoryConfigurationを設定する部分が見つかりませんでした。
ということは、今回上書きする必要があるメタデータは上書きできないメタデータに該当するようです。
「コンソールでだめなら。。。!」ということで、AWS CLIを使ってみましたがこれもうまくいかず。。。
$ aws backup create-restore-testing-selection \
--restore-testing-plan-name restore_test \
--restore-testing-selection \
'{"IamRoleArn": "arn:aws:iam::xxxxxxxxxxxx:role/service-role/AWSBackupDefaultServiceRole", \
"ProtectedResourceType": "FSx", \
"RestoreTestingSelectionName": "restore_test_association", \
"RestoreMetadataOverrides": \
{"WindowsConfiguration": \
"{\"SelfManagedActiveDirectoryConfiguration\": \
{\"DomainName\": \"xxxxxxxxxxxx.local\", \
\"FileSystemAdministratorsGroup\": \"Domain Admins\", \
\"UserName\": \"test\", \
\"Password\": \"xxxxx\", \
\"DnsIps\": [\"xx.xx.xx.xx\"]}}"}}'
An error occurred (InvalidParameterValueException) when calling the CreateRestoreTestingSelection operation: Restore metadata overrides are invalid: Restore metadata overrides contain an invalid or non-overridable nested key. Overridable nested keys: [deploymenttype, junctionpath, ontapvolumetype, logconfiguration, throughputcapacity, securitystyle, diskiopsconfiguration, activedirectoryid, sizeinmegabytes, storageefficiencyenabled, storagevirtualmachineid, tieringpolicy, preferredsubnetid].
エラー文をみると、以下のキーしか上書きできないと記載されています。
- deploymenttype
- junctionpath
- ontapvolumetype
- logconfiguration
- throughputcapacity
- securitystyle
- diskiopsconfiguration
- activedirectoryid
- sizeinmegabytes
- storageefficiencyenabled
- storagevirtualmachineid
- tieringpolicy
- preferredsubnetid
残念ながらSelfManagedActiveDirectoryConfigurationは上書きできないようです。。。
つまり、Windows認証にセルフマネージドADを選択しているFSxは、復元テストが使用できないということになります。
代替手段を考えて実装
復元テストに類似する機能は他にないと思いますので、同等のことをしたいのであればスクラッチでの実装が必要となります。
処理が複雑になることが予想されましたので、今回はAWS Step Functionsを使用してスクラッチでの実装を行いました。
なお、Lambdaだけでも実装は可能かと思いますが、色々考えた末にStep Functionsを主軸に実装することにしました。
この実装において考えたことについて、別の記事でまとめていますので興味があればぜひご覧ください。
全体の流れ
Step Functionsはステートマシンという単位で処理をまとめることができますが、今回はステートマシンを3つ作成しました。

オンデマンド復元の実行と復元されたFSxへのタグ付けの処理をまとめて定期実行させるようにしています。
ここでは、FSxの起動には30分ほど時間がかかるため、復元と復元後のタグ付けはステートマシンを分けています。
復元ジョブのステータスが成功に変わったことをEventBridgeルールで検知し、タグ付けを行うステートマシンが起動されるようにしています。
その後、しばらく時間を空けた後でFSxを削除するステートマシンを定期実行させるという流れになります。
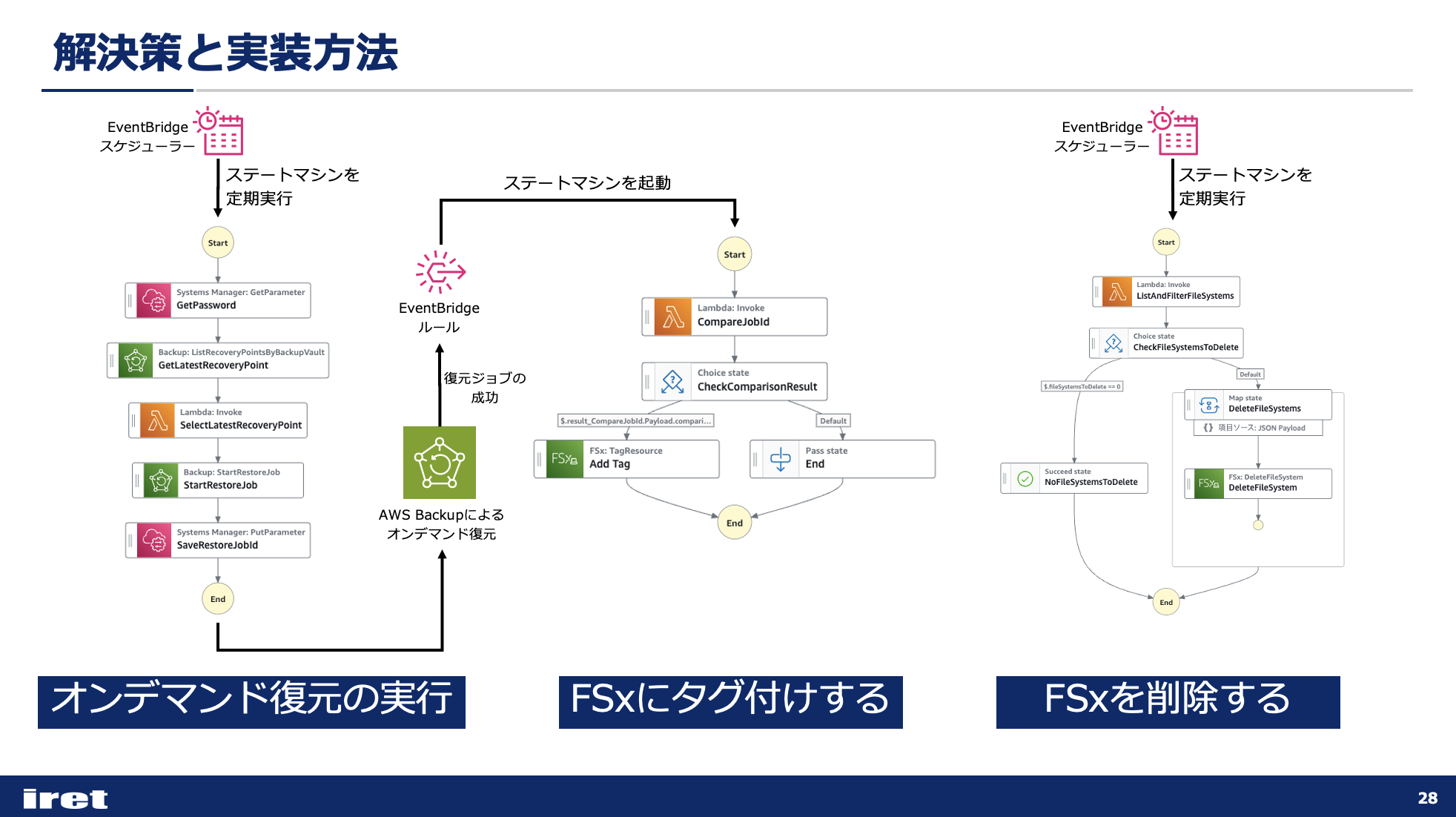
以降、それぞれの処理について詳細を紹介していきます。
オンデマンド復元の実行
まず、SSM Parameter StoreにADのログイン情報(今回はパスワードのみ)をあらかじめ暗号化して保存しておきます。
その上で以下のようなステートマシンを定義します。
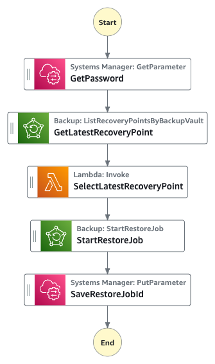
- GetPassword
- SSM Parameter Storeに暗号化して保存してあるADの認証情報を取得
- GetLatestRecoveryPoint
- 対象のバックアップボールトに存在する復旧ポイント一覧を取得
- SelectLatestRecoveryPoint
- 取得したリカバリポイント一覧の中で、一番最近取得されたものをピックアップするLambda関数を呼び出す
- StartRestoreJob
- ピックアップされた最新の復旧ポイントからの復元を実行
- メタデータを挿入した上でStartRestoreJobアクションを実行
- SaveRestoreJobId
- オンデマンド復元が開始したら、復元ジョブのIDをパラメータストアに保存
- 保存したIDは次に起動するステートマシンで使用
実際のステートマシンの定義は以下のようになっています。
{
"Comment": "FSx Restore Workflow",
"StartAt": "GetPassword",
"States": {
"GetPassword": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:ssm:getParameter",
"Parameters": {
"Name": "restore_test_selfmanaged_ad_test_user_password",
"WithDecryption": true
},
"ResultPath": "$.password",
"Next": "GetLatestRecoveryPoint"
},
"GetLatestRecoveryPoint": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:backup:listRecoveryPointsByBackupVault",
"Parameters": {
"BackupVaultName": "xxxx-fsx-restoration-bk-vault",
"ByResourceType": "FSx",
"MaxResults": 100
},
"ResultPath": "$.recoveryPoints",
"Next": "SelectLatestRecoveryPoint"
},
"SelectLatestRecoveryPoint": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "restore_test_SelectLatestRecoveryPointFunction",
"Payload.$": "$"
},
"ResultPath": "$.result_SelectLatestRecoveryPointFunction",
"Next": "StartRestoreJob"
},
"StartRestoreJob": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:backup:startRestoreJob",
"InputPath": "$",
"Parameters": {
"CopySourceTagsToRestoredResource": true,
"IamRoleArn": "arn:aws:iam::xxxxxxxxxxxx:role/service-role/AWSBackupDefaultServiceRole",
"Metadata": {
"kmskeyid": "arn:aws:kms:ap-northeast-1:xxxxxxxxxxxx:key/xxxxxxxxxxxx",
"securitygroupids": [
"sg-xxxxxxxxxxxx"
],
"storagetype": "SSD",
"subnetids": [
"subnet-xxxxxxxxxxxx",
"subnet-xxxxxxxxxxxx"
],
"WindowsConfiguration": {
"DeploymentType": "MULTI_AZ_1",
"ThroughputCapacity": 16,
"PreferredSubnetId": "subnet-xxxxxxxxxxxx",
"SelfManagedActiveDirectoryConfiguration": {
"DomainName": "xxxxxxxxxxxx.local",
"FileSystemAdministratorsGroup": "Domain Admins",
"UserName": "test",
"Password.$": "$.password.Parameter.Value",
"DnsIps": [
"xx.xx.xx.xx"
]
},
"AutomaticBackupRetentionDays": "0"
}
},
"RecoveryPointArn.$": "$.result_SelectLatestRecoveryPointFunction.Payload.latestRecoveryPointArn",
"ResourceType": "FSx"
},
"ResultPath": "$.restoreJob",
"Next": "SaveRestoreJobId"
},
"SaveRestoreJobId": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:ssm:putParameter",
"Parameters": {
"Name": "restore_test_restore_job_id",
"Value.$": "$.restoreJob.RestoreJobId",
"Type": "String",
"Overwrite": true
},
"End": true
}
}
}
SelectLatestRecoveryPointで使用しているLambda関数では以下のようなコードを書いています。
import json
def lambda_handler(event, context):
recovery_points = event['recoveryPoints']['RecoveryPoints']
# 復旧ポイントを作成日時でソート
sorted_points = sorted(recovery_points, key=lambda x: x['CreationDate'], reverse=True)
# 最新の復旧ポイントのARNを取得
latest_recovery_point_arn = sorted_points[0]['RecoveryPointArn']
return {
'latestRecoveryPointArn': latest_recovery_point_arn
}
FSxにタグ付けをする
「オンデマンド復元の実行」のステートマシンが正常に完了してから30分ほど待機すると、FSxが使えるようになり復元ジョブが「成功」に変わります。
この復元ジョブの成功をEventBridgeで検知することで、FSxにタグ付けをするステートマシンを起動させます。
https://docs.aws.amazon.com/ja_jp/aws-backup/latest/devguide/eventbridge.html#aws-backup-events-restore-job
ターゲットとするステートマシンは以下のようなものを用意しました。
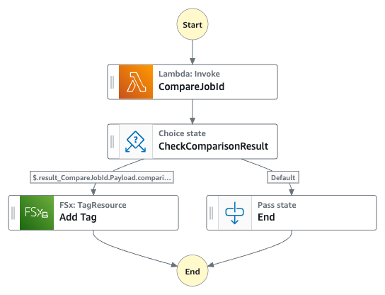
- CompareJobId
- EventBridgeルールから渡されたジョブIDを、前の処理でParameter Storeに保存したジョブIDと比較
- CheckComparisonResult
- 比較の結果によって処理を分岐
- 一致すれば次の処理(Add Tag)を実行
- 一致しなければ何もせず処理を終了
- Add Tag
- 復元されたFSxに対してタグをつける
実際のステートマシンの定義は以下のようになりました。
{
"Comment": "AWS Backup Restore Completion Workflow",
"StartAt": "CompareJobId",
"States": {
"CompareJobId": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:restore_test_hatakeyama_after_task_completion",
"Payload.$": "$"
},
"ResultPath": "$.result_CompareJobId",
"Next": "CheckComparisonResult"
},
"CheckComparisonResult": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.result_CompareJobId.Payload.comparisonResult",
"BooleanEquals": true,
"Next": "Add Tag"
}
],
"Default": "End"
},
"Add Tag": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:fsx:tagResource",
"Parameters": {
"ResourceARN.$": "$.detail.createdResourceArn",
"Tags": [
{
"Key": "RestoreTest",
"Value": "true"
}
]
},
"End": true
},
"End": {
"Type": "Pass",
"End": true
}
}
}
CompareJobIdで使用しているLambda関数では以下のようなコードを書いています。
import boto3
from botocore.exceptions import ClientError
ssm_client = boto3.client('ssm')
def lambda_handler(event, context):
# イベント入力から復元ジョブ ID を取得
restore_job_id = event['detail']['restoreJobId']
# 「オンデマンド復元の実行」ステートマシンの最後処理`SaveRestoreJobId`で、Parameter Storeに保存した復元ジョブのIDを取得
parameter_name = 'restore_test_restore_job_id'
try:
parameter_value = ssm_client.get_parameter(Name=parameter_name)['Parameter']['Value']
except ClientError as e:
return {
'statusCode': 500,
'body': f'Error retrieving parameter {parameter_name}: {e.response["Error"]["Message"]}'
}
# 復元ジョブ ID とパラメータ値を比較
comparison_result = restore_job_id == parameter_value
return {
'statusCode': 200,
'comparisonResult': comparison_result
}
FSxを削除する
「オンデマンド復元の実行」のステートマシンが実行された後、数時間後に起動するEventBridgeスケジューラーを作成しておきます。
そのスケジューラーによって、以下のようなステートマシンを起動させます。
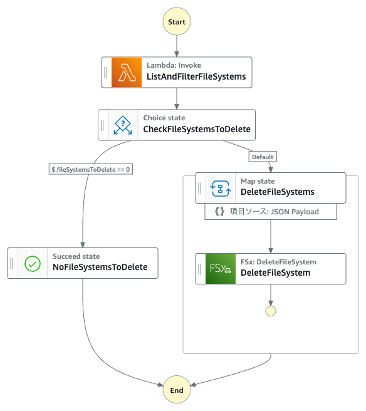
- ListAndFilterFileSystems
- FSx一覧を取得し、特定のタグがついてるファイルシステムの名前を抽出するLambda関数を作成
- CheckFileSystemsToDelete
- 抽出した結果によって処理を分岐
- 一つでも該当のリソースがあればDeleteFileSystemsを実行
- 一つもなければ何も処理せず処理を終了
- DeleteFileSystems
- 該当リソースを削除する
- 該当リソースが複数あることを想定してMapステートを利用
実際のステートマシンの定義は以下のようになりました。
{
"Comment": "FSx File System Delete",
"StartAt": "ListAndFilterFileSystems",
"States": {
"ListAndFilterFileSystems": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:restore_test_hatakeyama_after_delete_task_ListAndFilterFSx",
"Next": "CheckFileSystemsToDelete"
},
"CheckFileSystemsToDelete": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.fileSystemsToDelete",
"NumericEquals": 0,
"Next": "NoFileSystemsToDelete"
}
],
"Default": "DeleteFileSystems"
},
"NoFileSystemsToDelete": {
"Type": "Succeed"
},
"DeleteFileSystems": {
"Type": "Map",
"ItemsPath": "$.fileSystemsToDelete",
"Iterator": {
"StartAt": "DeleteFileSystem",
"States": {
"DeleteFileSystem": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:fsx:deleteFileSystem",
"Parameters": {
"FileSystemId.$": "$"
},
"End": true
}
}
},
"End": true
}
}
}
ListAndFilterFileSystemsで使用しているLambda関数では以下のようなコードを書いています。
import boto3
def lambda_handler(event, context):
fsx = boto3.client('fsx')
file_systems = fsx.describe_file_systems()['FileSystems']
systems_to_delete = [
fs['FileSystemId'] for fs in file_systems
if any(tag['Key'] == 'RestoreTest' and tag['Value'] == 'true' for tag in fs.get('Tags', []))
]
return {
'fileSystemsToDelete': systems_to_delete
}
このような実装で、無事に復元テストと同等の機能をスクラッチで実装することができました!
最後に
実は今回初めてStep Functionsをがっつり触ったのですが、EventBridgeとLambdaを組み合わせることでかなり柔軟な実装ができることがわかりました。
今後困ったときには、Step Functionsを積極的に使っていこうと思います!
また、今回の実装はあくまで一例です。もし「他にこんな方法もあるのでは無いか」など意見があればぜひ教えて欲しいです!
