
本記事は不要に不安を煽るものではありません。あくまでも参考程度にご覧頂ければ幸いです。
はじめに
外をぼんやり見ていたらせっかく晴れているのモヤがかかっているような状態になっているので大気中の PM2.5 等の汚染物質の飛散状況を見れるサイトを探していたら以下のようなサイトを発見。
少し懐かしさを感じるページの作りではあるが全国各地の大気中に飛散している汚染物質データをほぼリアルタイムに確認することが出来るようだ。実際に確認してみたところ 2 時間前のデータを確認することが出来た。
尚、残念ながら API 等では提供されておらず、他のアプリケーション等から利用することは想定されていないので、どうしても利用したい場合には Nokogiri 等でページを解析する必要がありそう。
ということで…
海外のデータは提供されている
上記のそらまめくんのページのリンクをたどってみると海外(アジア地域)の PM 2.5 測定値を CSV で提供しているようなので、このデータを利用させて頂いて Elasticsearch に放り込んでみたいと思う。
生データ
CSV をダウロードするとデータは以下のような状態になっていた。
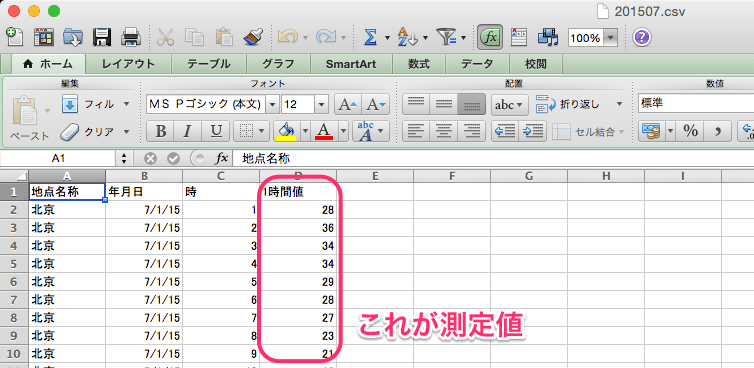
単位はこちらを参考にすると「マイクログラム per 1 立法メートル」となるようだ。尚、以下のようにフィールドを定義することにした。
| フィールド名 | Elasticsearch のキー名 | フィールドタイプ | 備考 |
|---|---|---|---|
| 地点名称 | CHECK_POINT | String | |
| 年月日 | DATE | String | CHECK_TIME を生成する為に利用するのみ |
| 時 | TIME | String | CHECK_TIME を生成する為に利用するのみ |
| 1 時間値 | VALUE | Long | 小数点はデータとして無かったので Long で |
| N/A | CHECK_TIME | Date | 年月日と時を利用して生成したがちょっと面倒だった |
尚、元データの年月日、時が 1 桁、2 桁と不揃いだったので 2 桁に穴埋めする処理を追加した。また、時が 1 〜 24 という数値だったが、Elasticsearch 側で時間を表す場合には 0 〜 23 を使う必要があったので 24 を 00 に変換する処理を加えている。
Elasticsearch インデックスのマッピング
以下のようなマッピングを事前に登録しておく。
{
"mappings" : {
"abroad" : {
"properties" : {
"DATE" : {
"type" : "string"
},
"TIME" : {
"type" : "string"
},
"VALUE" : {
"type" : "long"
},
"CHECK_POINT" : {
"type" : "string"
},
"CHECK_TIME" : {
"format" : "YYYY-MM-dd HH:mm:ss","type" : "date"
}
}
}
}
}
インデックス名等は適当に。
データを投入するスクリプト
データを投入するスクリプトはこちらに。ポイントとしては…
- 元のデータは Shift-JIS で保存されている為に Kernel モジュールの open メソッドを利用してファイルを開いて文字コードを変換している
- 年月日と時間が 1 桁、2 桁と不揃いだったので 2 桁に揃えた(1 桁の数値を 0 で穴埋めした)
- CHECK_TIME を年月日と時間から生成して配列の頭に持ってきている
- transpose メソッドを利用して Elasticsearch のフィールドをヘッダとしてデータとがっちゃんこ
- がっちゃんこした配列データを flatten で平坦化してハッシュ→JSON 化
データの投入
以下のようにスクリプトの第一引数に年、第二引数に月を指定してスクリプトを実行する。
./script.rb ${年} ${月}
実行すると以下のようにレスポンスが表示されれば Elasticsearch へのデータ登録は OK。
body -> {"_index":"pm25","_type":"abroad","_id":"AU52mngGLVLBLrS9pzmI","_version":1,"created":true}
code -> 201
msg -> Created
body -> {"_index":"pm25","_type":"abroad","_id":"AU52mngJLVLBLrS9pzmJ","_version":1,"created":true}
code -> 201
msg -> Created
body -> {"_index":"pm25","_type":"abroad","_id":"AU52mngLLVLBLrS9pzmK","_version":1,"created":true}
code -> 201
msg -> Created
body -> {"_index":"pm25","_type":"abroad","_id":"AU52mngNLVLBLrS9pzmL","_version":1,"created":true}
code -> 201
msg -> Created
body -> {"_index":"pm25","_type":"abroad","_id":"AU52mngQLVLBLrS9pzmM","_version":1,"created":true}
過去 7.5 年分なのでデータ登録は地道な作業。
Kibana で可視化
Kibana4 が不慣れ過ぎでしたが…
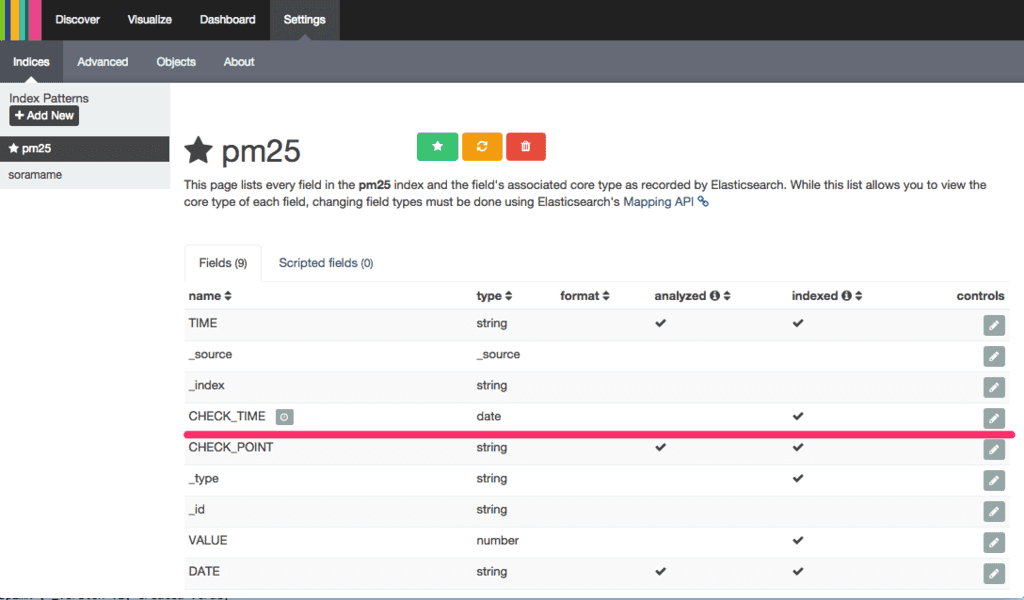
タイムフィールドを CHECK_TIME に指定すると以下のようにインデックスを登録することが出来た。
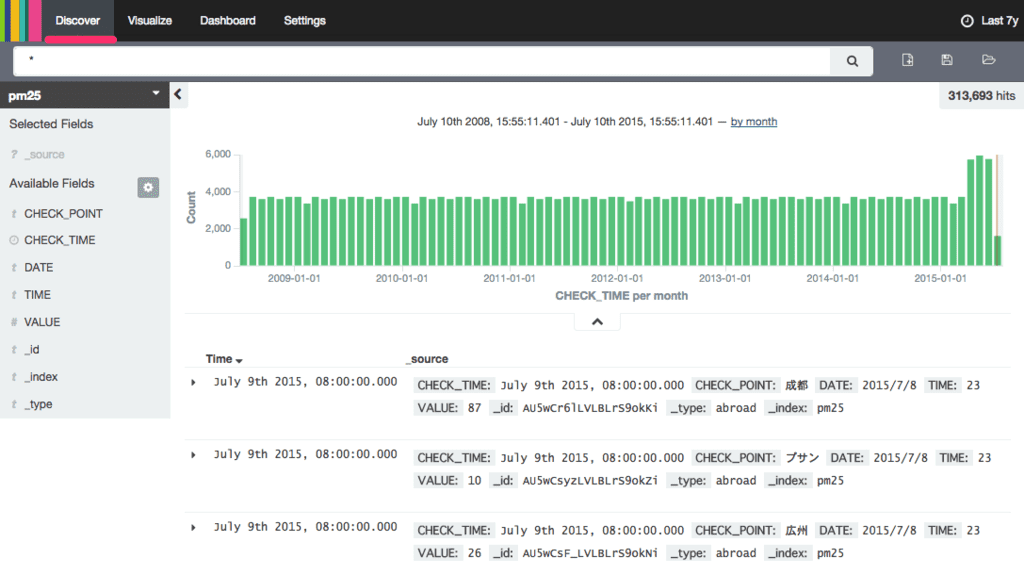
Discover タブをクリックすると以下のように登録されているデータ件数がグラフで表示された。
例えば、北京だけのデータを
検索フィールドに CHECK_POINT: "北京" を入力すると以下のように CHECK_POINT が「北京」のデータのみが抽出される。
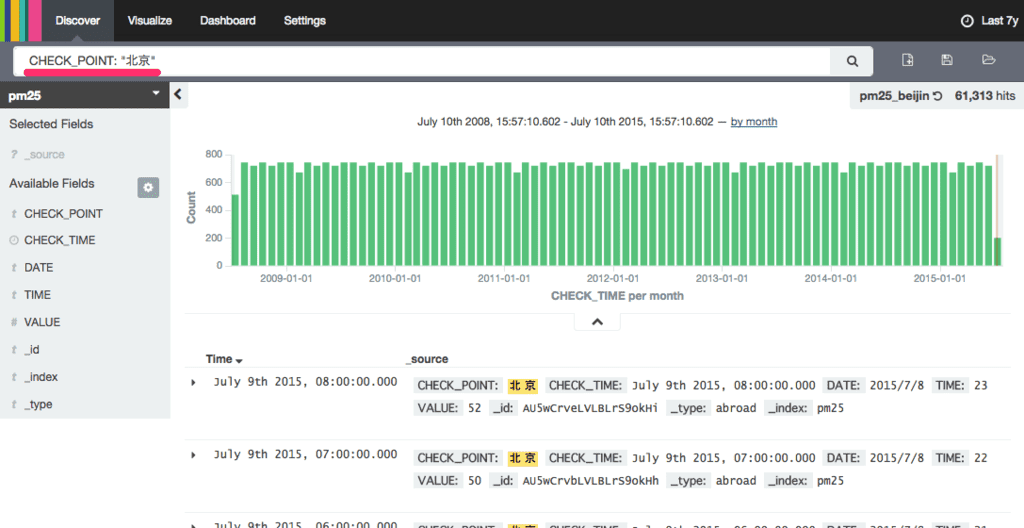
右上のフロッピーアイコンをクリックして検索結果を保存する。
過去 7.5 年分の北京における PM 2.5 濃度の変化を可視化
Visualize にて Discover で保存した検索結果を利用して可視化の準備をしていく。
以下のように X 軸と Y 軸で集計の対象となるフィールドと集計方法等選択する。
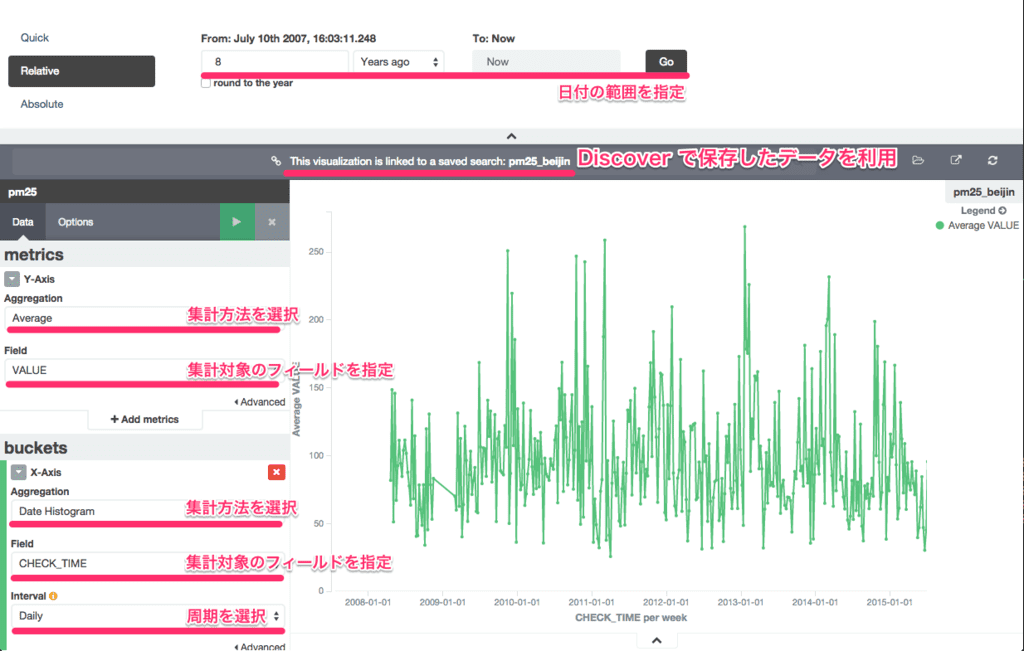
作成した Visualize データも Discover と同様に保存して Dashoboard にて貼り付けると以下のように表示した。
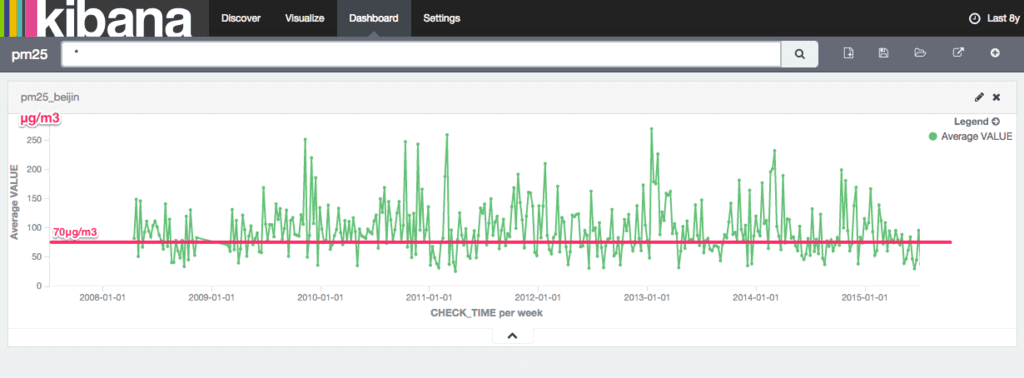
週間の平均値だが、以下の福岡県の基準と比較すると高い値を推移している。
福岡県では、環境省の「PM2.5に関する専門家会合」報告に従い、平成25年3月9日より、PM2.5の濃度が、暫定的な指針値である日平均値70µg/m3を超えると予測される場合に注意喚起を行うこととしました。微小粒子状物質(PM2.5)に関する注意喚起について
尚、上記のように福岡県では以下のように 70µg/m3 を超えると注意喚起が行われる。
ということで
Kibana 4 はも少しちゃんと勉強しよう
Kibana 4 は Kibana 3 と比較すると大幅に機能が追加されていて、ちゃんと使うにはも少しちゃんと触っていく必要がありそう。
CSV から Elasticsearch へのデータの取り込み
シンプルなフィールドのデータであれば簡単に取り込むことが出来たが、事前にデータの状態は生データで確認しておく必要がある。
参考
ElasticsearchのインストールとCSVからのデータ挿入 | EasyRamble
CSV データから Elasticsearch インデックスへの投入について参考にさせて頂いた。
Ruby – CSV を文字コード変換しつつロード – Qiita
CSV ファイルの文字コードを変換しつつ Ruby で処理する方法について参考にさせて頂いた。
PM 2.5 を含む大気中の汚染物質の正しい情報については…
そらまめくんや…
上記のような環境省が提供するサイトを確認するようにしましょう。
元記事はこちら
「ふと思い立って Elasticsearch と Kibana4 で過去 7.5 年分の PM 2.5 濃度を可視化してみた – ようへいの日々精進XP」

