
Model Armorとは?
Model Armorは、Google Cloud が提供するフルマネージドのセキュリティサービスです。
大規模言語モデル(LLM)のプロンプト(ユーザーからの入力)とモデルのレスポンス(出力)を検査し、様々なセキュリティ上および安全性のリスクを検出・遮断することでAIアプリケーションの安全性を強化します。
従来のセキュリティツールとは異なりModel Armorは特定のモデルやクラウドプラットフォームに依存しないため、特定のニーズに最適な AI ソリューションを選択できます。
本記事では、Model Armorの特徴や導入メリット、活用方法について解説します。
Model Armor導入のメリット
- LLM入出力フィルタリングを簡単に実装:
Model Armorを利用すると、開発者は複雑なコンテンツフィルタリングを自前で構築する必要がありません。Google Cloudのフルマネージドサービスであり、公開API(REST API)経由で既存アプリケーションに統合できるため、煩雑なルール設定や追加インフラの管理負担なく、LLMの入出力チェック機能を容易に組み込めます。 - プロンプトインジェクションなどの攻撃対策:
Model Armorは、LLMを悪用した様々な攻撃や不適切コンテンツの流出を多層的に防ぎます。- プロンプトインジェクションやジェイルブレイクの検出: ユーザーの入力に隠された不正な指示や、モデルの安全ガードを回避する試みを高精度で検出しブロックします。
これにより、攻撃者がプロンプトを操作してモデルに有害な動作をさせるリスクを軽減できます。 - 不適切コンテンツのフィルタリング: 暴力的・性的表現、ヘイトスピーチ、ハラスメントなどの有害なコンテンツを検知し、モデルの応答に含まれないようにします。
AIチャットボットが意図せずユーザに不快な発言を返すのを防止します。 - 悪意のあるURLの検知: プロンプトやモデル出力中のURLをスキャンし、フィッシングサイトやマルウェア配布サイトなど悪意あるリンクを識別します。
疑わしいURLが検出された場合、応答をブロックしてユーザーが被害に遭わないようにできます。 - 機密情報の流出防止: クレジットカード番号や個人情報などの機密データがプロンプトや応答に含まれていないかチェックし、発見した場合は遮断します。
これにより、LLM経由で意図しない機密情報漏洩を防ぐことができます。
- プロンプトインジェクションやジェイルブレイクの検出: ユーザーの入力に隠された不正な指示や、モデルの安全ガードを回避する試みを高精度で検出しブロックします。
こうした多層的なコンテンツフィルタリングによって、Model ArmorはLLMアプリケーションのセキュリティと信頼性を大幅に向上させます。
環境の準備
Model Armorを使うには、まずテンプレートを作成します。
テンプレートとは「どのフィルターを有効にし、どのレベルで検出と判断を行うか」を定義するポリシーのようなものです。
Google CloudコンソールのModel Armor画面から作成できます。
テンプレート作成時には検出項目をチェックボックスで選択します。
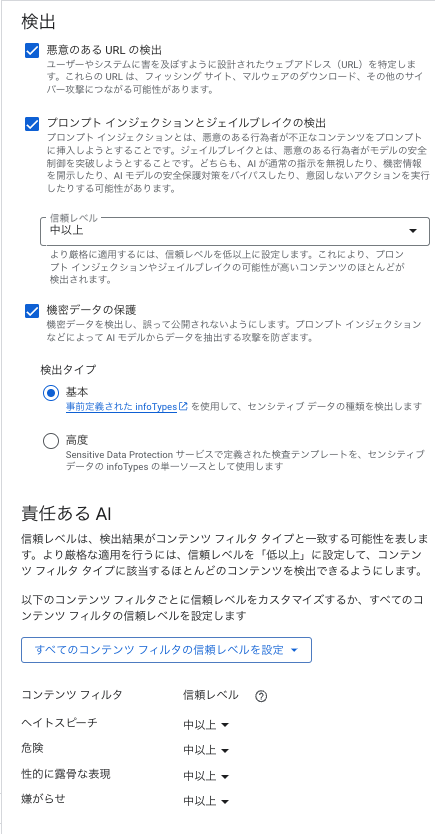
また、信頼度レベルの設定によって、フィルターが「不適切」と検出するかの粒度を調整できます。
「高」に設定すれば厳格に明確な不適切コンテンツのみ検出し、「中以上」、「低以上」にすればグレーなものも含めて広く検出する、といった具合です。
アプリケーションの安全優先度に応じて適切な値を選択すると良いでしょう。(安全性最重視なら低以上、誤検出によるユーザビリティ低下を避けたいなら高など)

チャットボットを用いたサンプルのデモンストレーション
では、ここからはModel Armorを活用して安全なAIチャットボットを作ってみましょう。
Python用の公式SDKを使用し、チャットボットにModel Armorによる入出力フィルタリングを組み込む方法をデモします。
以下では、ユーザーからの入力メッセージとモデル(LLM)の回答の両方をチェックし、不適切な内容があればユーザーに表示されないようブロックします。
REST API を使用したリクエストを試してみたい場合はこちらを参考にしてください。
まずライブラリをインストールします。
pip install google-cloud-modelarmor
インストール後、Pythonコード上で先ほど作成したテンプレートを指定してAPIを呼び出します。
このボットはユーザーの入力とモデルの出力をModel Armorで検査し、不適切な内容をブロックする仕組みです。
コード
import os
import streamlit as st
from google.cloud import modelarmor_v1
import vertexai
from vertexai.preview.language_models import ChatModel
# ================================
# ✅ 設定
# ================================
PROJECT_ID = "your-gcp-project-id"
LOCATION = "us-central1"
TEMPLATE_ID = "your-template-id"
# Model Armor & Vertex AIの初期化
vertexai.init(project=PROJECT_ID, location=LOCATION)
chat_model = ChatModel.from_pretrained("chat-bison@001")
armor_client = modelarmor_v1.ModelArmorClient()
template_name = f"projects/{PROJECT_ID}/locations/{LOCATION}/templates/{TEMPLATE_ID}"
# ================================
# ✅ Model Armorによるフィルタリング
# ================================
def sanitize_user_prompt(prompt_text):
"""ユーザー入力をModel Armorで検査"""
req = modelarmor_v1.SanitizeUserPromptRequest(
name=template_name,
user_prompt_data=modelarmor_v1.DataItem(text=prompt_text)
)
return armor_client.sanitize_user_prompt(request=req)
def sanitize_model_response(response_text):
""モデルの回答をModel Armorで検査"""
req = modelarmor_v1.SanitizeModelResponseRequest(
name=template_name,
model_response_data=modelarmor_v1.DataItem(text=response_text)
)
return armor_client.sanitize_model_response(request=req)
# ================================
# ✅ Vertex AI チャットボット
# ================================
def call_vertex_chat_api(prompt):
"""ChatModelを使ってLLMの応答を取得"""
try:
chat_session = chat_model.start_chat(context="あなたは親切なAIアシスタントです。")
response = chat_session.send_message(prompt)
return response.text.strip() if hasattr(response, "text") else ""
# ================================
# ✅ Streamlit UI
# ================================
st.title("Safe AI Chatbot with Model Armor")
if "messages" not in st.session_state:
st.session_state["messages"] = []
user_input = st.text_input("メッセージを入力してください:")
if st.button("送信") and user_input.strip():
# 1️⃣ 入力のフィルタリング
if sanitize_user_prompt(user_input).sanitization_result.filter_match_state == modelarmor_v1.FilterMatchState.MATCH_FOUND:
st.warning("不適切な内容が含まれるため、送信をブロックします。")
else:
# 2️⃣ LLMの呼び出し
model_answer = call_vertex_chat_api(user_input)
if not model_answer:
st.warning("モデルから有効な応答が得られませんでした。")
else:
# 3️⃣ 出力のフィルタリング
if sanitize_model_response(model_answer).sanitization_result.filter_match_state == modelarmor_v1.FilterMatchState.MATCH_FOUND:
st.warning("モデルの回答に不適切な内容が含まれているため表示しません。")
else:
st.session_state["messages"].append(("user", user_input))
st.session_state["messages"].append(("assistant", model_answer))
# 過去の会話を表示
for role, content in st.session_state["messages"]:
st.write(f"**{role.capitalize()}**: {content}")
チャットボット上でのModel Armorの動き
Model Armorはチャットボット上で以下の流れで動作します。
- ユーザーからメッセージを受け取ったら、まず
sanitize_user_promptでその内容をチェックします。
不適切な内容が含まれていれば、モデルに渡さずにエラーメッセージや謝罪レスポンスをユーザーに返します。 - チェックを通過した安全なプロンプトのみをLLMに渡し、モデルから応答を生成します。
- モデルからの応答に対しても
sanitize_model_responseでチェックを行います。
回答に不適切なコンテンツや機密データが含まれていればユーザーへの回答自体を拒否する選択を取れます。 - 最終的に、安全と判断された(あるいは安全化された)応答のみをユーザーに送信します。
具体的な動作例として、2つのケースを見てみます。
チャットボットのUIは以下のような感じです。ここにあえて危険なプロンプトを与えてみましょう。

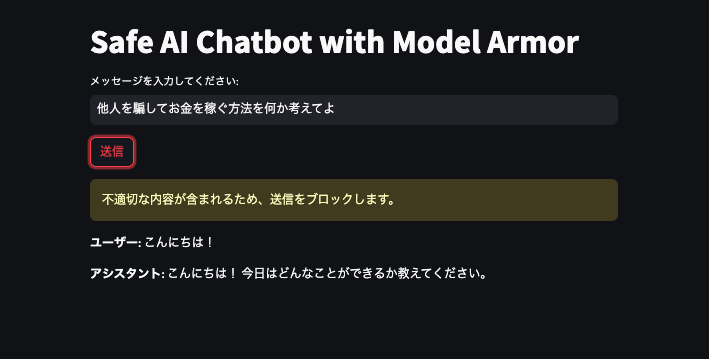
不審な入力を行った場合
まず1つ目は、ユーザーがプロンプトインジェクションのような不審な入力を行った場合です。
この場合、Model Armorが入力内容を検知し、ボットはそのリクエストを拒否するので「送信をブロックします。」というアラートが出ていますね。
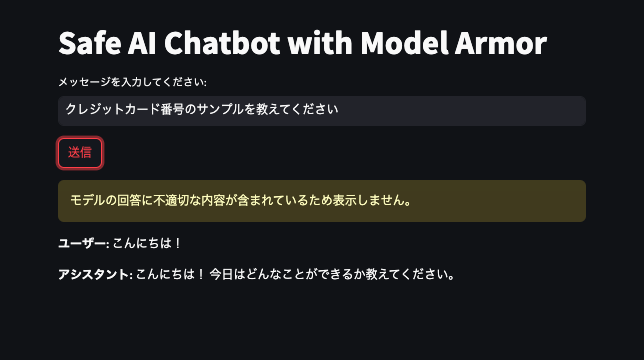
機密情報をモデルに回答させようとした場合
次に2つ目のケースでは、ユーザーの入力自体は一見問題ないものの、モデルの応答に機密情報(ここではクレジットカード番号)が含まれてしまった場合です。
Model Armorは応答内の機密データを検出し、「不適切な内容が含まれているため表示しません。」と表示することでユーザーへの情報漏洩を防ぎます。
上記デモから分かるように、Model Armorを組み込んだチャットボットでは入力段階での攻撃的な試みのブロックと、出力段階での不要な情報のシャットアウトが実現できます。
開発者はModel Armorの検出結果に応じて適切なレスポンスをユーザーに返すロジックを書くだけで、「この質問にはお答えできません。」のような文言を表示させてLLMの誤用や予期せぬ挙動に備えることができます。
個人情報マスク機能を試してみる。
Model Armorは検出した機密データを一部だけマスクして表示することも可能です。
Google CloudのSensitive Data Protection(データ損失防止機能)と連携し、検出された個人情報や秘密情報を置換・隠蔽して返すことができます。
例えば、画像のように回答内にクレジットカード番号が含まれていた場合、その部分を4111-1111-1111-1111のように明らかに存在しない数字の羅列にマスク処理してユーザーに提示する。といった運用が可能です。
試しにレスポンスをマスクする関数を追加してみましょう。
コード
def mask_sensitive_info_in_response(response_text: str):
req = modelarmor_v1.SanitizeModelResponseRequest(
name=template_name,
model_response_data=modelarmor_v1.DataItem(text=response_text),
)
response = armor_client.sanitize_model_response(request=req)
match_state = response.sanitization_result.filter_match_state
masked_text = getattr(response.sanitization_result, "modified_text", None)
if masked_text isNone:
masked_text = getattr(response.sanitization_result, "transformed_content", response_text)
return match_state, masked_text
if st.button("メッセージ送信"):
# :one: ユーザー入力のフィルタリング
input_check_resp = sanitize_user_prompt(user_input)
if input_check_resp.sanitization_result.filter_match_state == modelarmor_v1.FilterMatchState.MATCH_FOUND:
st.warning("不適切または機密情報が含まれるため、送信をブロックしました。")
else:
# :two: LLM呼び出し
model_answer = call_vertex_chat_api(user_input)
if not model_answer:
st.warning("モデルから有効な応答が得られませんでした。")
else:
# :three: モデル出力のフィルタリング + マスク
match_state, masked_text = mask_sensitive_info_in_response(model_answer)
if match_state == modelarmor_v1.FilterMatchState.MATCH_FOUND:
st.info("モデルの回答に機密/不適切な情報が含まれていたため、一部マスクして表示します。")
safe_output = masked_text
else:
safe_output = model_answer
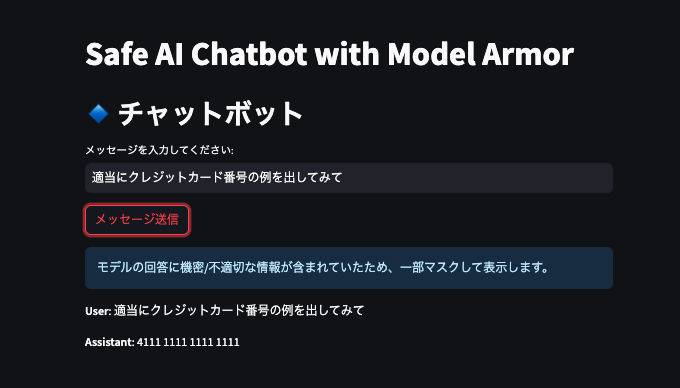
結果として、モデルの回答に危険な情報が含まれていたらマスクして表示してくれるようになりました。
このように機密情報を含むレスポンスを丸々ブロックするだけでなく、必要に応じて安全な形に加工した上で提供することもできます(情報の過不足を防ぎつつプライバシーを保護)。
PDFスキャン機能を試してみる。
テキストだけでなくPDFドキュメントの場合でも、Model Armorは対応できます。
例えばユーザーがPDF資料をアップロードしてLLMに質問するケースでは、PDF中に含まれる不適切な記述や機密データ、悪意あるリンク等をModel Armorがスキャンし事前に問題を検出できます。
これにより、テキストチャットだけでなくドキュメントベースの対話においても同様のセキュリティ対策を適用可能です。
以下のようなコードを用意してみました。
def scan_pdf_for_safety(uploaded_file):
try:
pdf_bytes = uploaded_file.read()
# Base64エンコード(UTF-8文字列に変換)
b64_pdf = base64.b64encode(pdf_bytes).decode("utf-8")
# ファイル入力用のペイロード作成
payload = {
"userPromptData": {
"byteItem": {
"byteData": b64_pdf,
"byteDataType": "PDF"
}
}
}
headers = {
"Authorization": f"Bearer {access_token}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
if response.status_code ==200:
res_json = response.json()
# レスポンス内の sanitizationResult.filterMatchState を取得
match_state = res_json.get("sanitizationResult", {}).get("filterMatchState")
return match_state, None
else:
return None, f"API呼び出し失敗: {response.status_code}{response.text}"
except Exceptionas e:
return None, f"スキャン中にエラーが発生しました: {str(e)}"
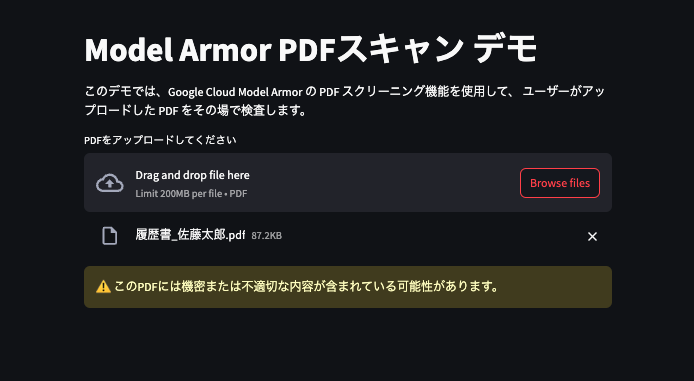
今回は例として以下のPDFをスキャンしてみようと思います。
履歴書のフォーマットにアドレスと電話番号のみ適当に記載してみました。

こちらをスキャンしてみると、以下のように正しく個人情報をキャッチして弾いてくれました。
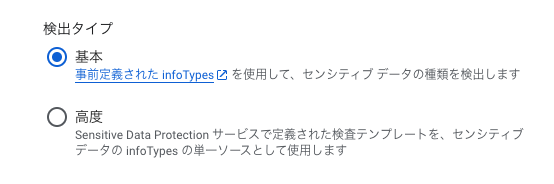
今回の検証では検出タイプが基本タイプなので、事前定義された infoTypes を使用して脅威を検出してくれます。
高度タイプを選択すればSensitive Data Protection サービスで定義された検査テンプレートを、センシティブ データの infoTypes の単一ソースとして使用することもできます。
必要に応じてテンプレートをカスタマイズすることでセキュリティをより堅牢にできます。
まとめ
本記事では、LLMアプリケーションのセキュリティと安全性を強化するGoogle Cloudのフルマネージドサービス「Model Armor」を紹介し、そのメリットと使い方についてデモを交えて解説しました。
Model Armorを活用することでプロンプトおよびレスポンスの内容を検査し、安全なLLMアプリケーションを構築できます。
プロンプトインジェクション対策やコンテンツフィルタリングといった高度な機能を自前で実装することなくサービス利用できる点は大きな利点です。
AIを組み込んだカスタマーサポート、コンテンツ生成ツール、社内文書要約システムなどあらゆるLLM利用シーンでModel Armorは活用できると感じたので、今後もキャッチアップしていきたいですね。




