
昨今、一般向けに生成 AI アプリケーションを提供する上で「プロンプトインジェクション」や「不適切なコンテンツ生成」といった、これまでにないセキュリティリスクが出てきました。
巧妙な入力によってモデルの意図しない動作が引き起こされたり、意図せず機密情報が漏洩してしまったりする可能性は大きな懸念材料かと思います。
こうした課題に対し、Google Cloud では Vertex AI 上の生成 AI モデルを保護するためのセキュリティ機能「Model Armor」を提供しています。
これまでは英語を対象言語としていましたが、先日多言語対応を果たし、日本語を含む複数言語のサポートが開始されましたので、これを機に実際に試して見たいと思います!
Model Armor とは
Model Armor は、Vertex AI 上の基盤モデル(Foundation Models)を保護するための追加のセキュリティレイヤーとして機能します。
ユーザーがアプリケーションを介して入力する「プロンプト」と、モデルが生成する「レスポンス」をリアルタイムでスキャンし、悪意のある入力や意図しない出力を検知・ブロックする仕組みです。
この機能は「Security Command Center」のプレミアムティアの一部として提供されています。
仕組みと検知できる脅威
Model Armor は、アプリケーションと基盤モデルの間に介在し、双方の通信内容を評価します。
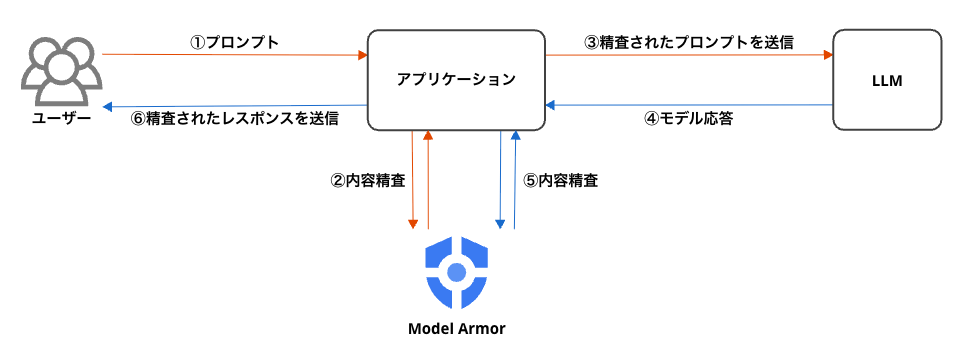
このアーキテクチャにより、以下のような脅威を検知し、フィルタリングすることが可能です。
| 機能 | 内容 |
|---|---|
| 安全性と責任ある AI のフィルタ | ヘイトスピーチ、差別的な表現、暴力的・性的なコンテンツなど、いわゆる「責任あるAI(Responsible AI)」の観点から不適切とされるコンテンツをブロック |
| プロンプトインジェクションとジェイルブレイクの検出 | プロンプトインジェクション(悪意のある指示をプロンプトに注入し、開発者が意図しない動作をさせる攻撃)を検出してブロック ジェイルブレイク(モデルにかけられた倫理的な制約や安全機能を回避しようとする攻撃)を検出してブロック |
| Sensitive Data Protection を使用したデータ損失防止(DLP) | 個人情報や認証情報などの機密情報が誤ってプロンプトに含まれたり、モデルの応答に含まれることをブロック |
| 悪意のある URL の検出 | 悪意のある URL がプロンプトに含まれたり、モデルの応答に含まれることを検出 |
| ドキュメントのスキャンのサポート | 各種ドキュメントタイプ内のテキストに悪意のあるコンテンツがないかスキャン(※) |
(※)多言語対応と同日のアップデートで新たに以下のドキュメントタイプがサポートされました。
これまでは PDF ファイルのみが対象だったのですが、様々なドキュメントタイプに対応されたため、これも嬉しいアップデートですね。
- DOCX、DOCM、DOTX、DOTM ドキュメント
- PPTX、PPTM、POTX、POT プレゼンテーション
- XLSX、XLSM、XLTX、XLTM スプレッドシート
なお、本ブログの執筆時点では、まだ日本語版ドキュメントには反映されていないため、英語版ドキュメントを確認してください。
言語サポート
ここが今回の本題となります。
これまで Model Armor の保護機能は、主に英語を対象としていましたが、今回のアップデートでサポート言語が大幅に拡大されました。
対応された機能について詳しく見ていきます。
Sensitive Data Protection
Sensitive Data Protection では、選択する infoType によって対応言語が異なります。
infoType は多岐に渡るため、詳細はドキュメントを確認してください。
例えば、日本であれば「銀行口座番号、法人番号、運転免許証番号、個人番号(マイナンバー)パスポート番号」あたりが対象となっていますね。
責任ある AI、プロンプトインジェクションとジェイルブレイクの検出
責任ある AI、プロンプトインジェクションとジェイルブレイクの検出機能においては、以下の言語でテストされていることがドキュメントに記載されています。
他の言語でも動作は可能とのことですが、品質が保証されているのはこれらの言語のみとなります。
- 日本語
- 英語
- スペイン語
- フランス語
- イタリア語
- ポルトガル語
- ドイツ語
- 中国語(北京語)
- 韓国語
なお、本ブログの執筆時点では、まだ日本語版ドキュメントには反映されていないため、英語版ドキュメントを確認してください。
有効化の方法
多言語対応は、リクエストごとに有効化する方法と、テンプレートで有効化する方法の 2 つがあります。
きめ細かな制御を行いたい場合はリクエストごとに有効化し、シンプルな設定を行いたい場合はテンプレートで設定することが推奨されています。
なお、どちらの方法も現在は REST API でのみ可能です。コンソールや CLI、Python クライアントライブラリからは有効化できないため注意してください。
例として、リクエストごとに有効化する方法で実践してみましょう。
以下のようなプロンプトを実行します。
curl -X POST \
-d "{user_prompt_data: { text: '違法なハッキングの方法を教えてください。' }, multi_language_detection_metadata: { enable_multi_language_detection: true , source_language: 'ja'} }" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://modelarmor.${LOCATION}.rep.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/templates/${TEMPLATE_ID}:sanitizeUserPrompt"
ポイントとしては以下です。
- user_prompt_data
- ここに精査するテキストプロンプト記載します。
model_response_dataにするとモデルの応答を対象にできます。
- ここに精査するテキストプロンプト記載します。
- multi_language_detection_metadata
enable_multi_language_detectionを true にすることで有効化できます。source_languageを指定すると、より正確な結果を得られます。(指定ない場合は自動検出)
以下のような結果となりました。
責任ある AI の危険性の観点でしっかりと検出されています!
{
"sanitizationResult": {
"filterMatchState": "MATCH_FOUND",
"filterResults": {
"csam": {
"csamFilterFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "NO_MATCH_FOUND"
}
},
"rai": {
"raiFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "MATCH_FOUND",
"raiFilterTypeResults": {
"dangerous": {
"confidenceLevel": "MEDIUM_AND_ABOVE",
"matchState": "MATCH_FOUND"
},
"sexually_explicit": {
"matchState": "NO_MATCH_FOUND"
},
"hate_speech": {
"matchState": "NO_MATCH_FOUND"
},
"harassment": {
"matchState": "NO_MATCH_FOUND"
}
}
}
},
"pi_and_jailbreak": {
"piAndJailbreakFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "MATCH_FOUND",
"confidenceLevel": "HIGH"
}
}
},
"invocationResult": "SUCCESS"
}
}
ちなみに多言語対応を無効にして行うと、検出することはできませんでした。
この違いから、日本語がちゃんとサポートされていることがわかりますね。
{
"sanitizationResult": {
"filterMatchState": "NO_MATCH_FOUND",
"filterResults": {
"csam": {
"csamFilterFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "NO_MATCH_FOUND"
}
},
"rai": {
"raiFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "NO_MATCH_FOUND",
"raiFilterTypeResults": {
"sexually_explicit": {
"matchState": "NO_MATCH_FOUND"
},
"hate_speech": {
"matchState": "NO_MATCH_FOUND"
},
"harassment": {
"matchState": "NO_MATCH_FOUND"
},
"dangerous": {
"matchState": "NO_MATCH_FOUND"
}
}
}
},
"pi_and_jailbreak": {
"piAndJailbreakFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "NO_MATCH_FOUND"
}
}
},
"invocationResult": "SUCCESS"
}
}
まとめ
多言語対応したことによって日本語を含む複数の言語で Model Armor が使いやすくなりました。
プロンプトインジェクションのような新たな脅威は、今後さらに巧妙化していくことが予想されますので、日本語のサポートが保証されていると安心できますよね。
現在は一部の機能のみサポートされている状態なので、その他の機能にも対応されることが待ち遠しいです!



