
はじめに
Google Cloud の Vertex AI の Gen AI Evaluation Service を使用すると、生成 AI モデルやアプリを評価することができます。
Gen AI Evaluation Service では、評価基準を定義したうえで、生成 AI モデルとアプリがユースケースにどの程度即したものであるかを把握できるようになります。
生成 AI の開発のプロセスでは、モデルの選択、プロンプト エンジニアリングなど、あらゆるステップで評価が重要となります。
Gen AI Evaluation Service の機能
| 機能 | 内容 |
|---|---|
| モデルの選択 | タスクに応じた最適な事前トレーニング済みモデルを選択 |
| 生成設定 | モデルのパラメータ(温度など)を微調整して、出力を最適化 |
| プロンプトエンジニアリング | 効果的なプロンプトとプロンプトテンプレートで、期待するレスポンスへとモデルを誘導 |
| ファインチューニング | バイアスや望ましくない動作を防止 |
| RAG の最適化 | 効果的な RAG アーキテクチャを選択して、アプリケーションのパフォーマンスを強化 |
| 移行 | AI ソリューションのパフォーマンスを継続的に評価 |
評価のプロセス
評価する流れは以下の通りです。
- 評価指標の定義
- 評価データセットの準備
- 評価の実行
- 評価結果の表示と解釈
評価指標
評価指標には「モデルベースの指標」と「計算ベースの指標」があります。
モデルベースの指標
Google 所有の判定モデルを使用して、記述的な評価基準に基づいてパフォーマンスを評価します。
ポイントワイズまたはペアワイズ指標を使用すること可能です。
- ポイントワイズ
- モデルの出力を評価基準に基づいて判定モデルで判定する
- ペアワイズ
- 2つのモデルの出力を比較して優れている方を選択する
計算ベースの指標
モデルの出力を Ground Truth または数式を判定基準として評価します。
ROUGE や BLEU などの指標が使われることがあります。
まとめると
| アプローチ | データ | |
|---|---|---|
| モデルベースの指標 | 判定モデルを使用し、記述的な評価基準に基づいてパフォーマンスを評価 | Ground Truthはなくても良い |
| 計算ベースの指標 | 数式を使用してパフォーマンスを評価 | Ground Truthは通常必要 |
試してみる
環境設定
Vertex AI SDK for Python をインストールします。
pip install google-cloud-aiplatform[evaluation]
ライブラリのインポートをします。
import vertexai
PROJECT_ID = "PROJECT_ID"
LOCATION = "LOCATION"
vertexai.init(
project=PROJECT_ID,
location=LOCATION,
)
評価指標の定義
モデルベースの指標を2つ、計算ベースの指標を2つ定義したいと思います。
モデルベースの指標には、テンプレートがあります。
テンプレートは以下の種類があります。
- 流暢さ
- 一貫性
- 根拠性
- 安全性
- 指示実行
- 詳細度
- テキストの品質
- マルチターンチャットの品質
- マルチターンの安全性
- 要約の品質
- 質問応答の品質
今回は「質問応答の品質(question_answering_quality)」を1つの指標とします。
さらに独自の指標も定義します。
質問応答の品質と似たような指標ではありますが、評価を10段階にしています。
custom_prompt_template = """
# Instruction
You are an expert evaluator. Your task is to evaluate the quality of the responses generated by AI models.
We will provide you with the user input and an AI-generated response.
First, carefully read the user input to analyze the task. Then, evaluate the quality of the response based on the criteria provided in the "Evaluation" section below.
Assign a rating to the response following the Rating Rubric and Evaluation Steps. Provide a step-by-step explanation for your rating, and only choose ratings from the Rating Rubric.
# Evaluation
## Metric Definition
You will be assessing "summarization quality," which is the overall ability to summarize text.
## Criteria
* **Instruction Following**: Does the response clearly understand the summarization task instructions and satisfy all of the instruction's requirements?
* **Groundedness**: Is the information contained in the response based solely on the information in the provided context (source text)? Does it not reference any outside information?
* **Conciseness**: Does the response summarize the relevant details in the original text without significant loss of key information, and without being too verbose or too terse?
* **Fluency**: Is the response well-organized and easy to read?
* **Reference Alignment**: Is the response's content consistent and aligned with the provided reference response?
## Rating Rubric
* **10 points (Excellent)**: Perfectly follows instructions, is accurately grounded solely in the provided contextual information, is highly concise and fluent, and is fully aligned with the reference response. Impeccable on all evaluation criteria.
* **9 points (Very Good)**: Almost perfectly follows instructions, is accurately grounded solely in the provided contextual information, is concise and fluent, and is highly aligned with the reference response. Overall very high quality, with only very minor room for improvement.
* **8 points (Good)**: Follows instructions, is grounded solely in the provided contextual information, and is concise and fluent. Generally aligns with the reference response, but there may be slight room for improvement in some areas. Or, there may be very minor deficiencies in other criteria.
* **7 points (Fairly Good)**: Generally follows instructions and is grounded in the provided contextual information. There might be some room for improvement in conciseness or fluency, but the content is understandable. Partially aligned with the reference response.
* **6 points (Average)**: Generally follows instructions and is grounded in the provided contextual information. However, there are issues with one or more of the following: conciseness, fluency, or alignment with the reference response. The content is understandable, but improvement is desirable.
* **5 points (Slightly Flawed)**: Shows a somewhat insufficient understanding of instructions, or is grounded in the provided contextual information but is low in conciseness or fluency. Alignment with the reference response is also low. Important information might be missing, or there are redundant parts.
* **4 points (Flawed)**: Low adherence to instructions. While grounded in the provided contextual information, it scores low on conciseness, fluency, and alignment with the reference response. Comprehension of the content is hindered.
* **3 points (Poor)**: Grounded in the provided contextual information but mostly fails to follow instructions. The response may be unclear or poorly structured.
* **2 points (Very Poor)**: Noticeably not grounded in the provided contextual information (e.g., use of external information, hallucination). Fails to follow instructions. The response is inappropriate.
* **1 point (Completely Insufficient)**: Not at all grounded in the provided contextual information and completely fails to follow instructions. The response is not viable or is entirely irrelevant.
## Evaluation Steps
Step 1: Assess the response in aspects of instruction following, groundedness, conciseness, fluency, and reference alignment according to the criteria above.
Step 2: Score based on the rating rubric above.
# User Inputs and AI-generated Response
## User Inputs
### Reference
{reference}
### Prompt
{prompt}
## AI-generated Response
{response}
"""
from vertexai.evaluation import PointwiseMetric
custom = PointwiseMetric(
metric="custom",
metric_prompt_template=custom_prompt_template,
)
次に計算ベースの指標として、exact_matchとrougeを使用します。
| 指標 | 内容 | 出力 |
|---|---|---|
| exact_match | モデルの回答が基準と完全に一致するかどうかを計算 | 0 or 1 |
| rouge | 出力と正解データの n-gram の F1-score を計算 | [0,1]の小数点 1に近いほど類似性が高い |
評価データセットの準備
データセットは3種のインポートがあります。
- Cloud Storage に保存されている JSONL または CSV ファイル
- BigQuery テーブル
- Pandas DataFrame
今回は Pandas DataFrame で作成します。
以下のようにカラムを定義します。
| カラム | 内容 |
|---|---|
| prompt | ユーザーの入力 |
| response | 生成 AI の回答 |
| reference | 正解データ |
import pandas as pd
prompts = [
"日本の首都はどこですか?",
"「人間失格」の作者は誰ですか?",
"光の三原色をすべて挙げてください。",
" 2023年のラグビーワールドカップで優勝した国はどこですか?",
"地球上で最も高い山は何ですか?また、その標高は?"
]
contexts = [
"日本の首都は東京です。これは法律で明確に定められているわけではありませんが、慣習的に日本の首都とされています。",
"「人間失格」は、日本の小説家である太宰治によって執筆された小説です。1948年に発表されました。",
"光の三原色は、赤 (Red)、緑 (Green)、青 (Blue) です。これらの光をさまざまな割合で混ぜ合わせることで、多くの異なる色を作り出すことができます。",
" 2023年にフランスで開催されたラグビーワールドカップでは、南アフリカ代表(スプリングボクス)がニュージーランド代表(オールブラックス)を破り、大会史上最多となる4度目の優勝を果たしました。",
"地球上で最も高い山はエベレスト(ネパール名:サガルマータ、チベット名:チョモランマ)です。2020年にネパールと中国が共同で発表した最新の測量結果によると、その標高は8,848.86メートルです。"
]
reference = [
"東京",
"太宰治",
"赤、緑、青",
"南アフリカ",
"エベレスト(チョモランマ)、標高8,848.86メートル"
]
responses = [
"東京",
"太宰治",
"赤、黄、青",
"ニュージーランド",
"エベレスト、標高8,848.86メートル"
]
eval_dataset = pd.DataFrame(
{
"prompt": [f"{prompt} Context: {context}" for prompt, context in zip(prompts, contexts)],
"response": responses,
"reference": reference,
}
)
評価の実行
評価指標の定義と評価データセットの準備が完了したので、評価の実行を行います。
from vertexai.evaluation import EvalTask
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
"question_answering_quality", # 質問応答の品質(テンプレート)
custom, # 独自の指標
"exact_match",
"rouge"
],
experiment="gen-ai-eval-test",
)
result = eval_task.evaluate()
実行が完了すると以下が出力されます。
INFO:vertexai.evaluation._evaluation:Computing metrics with a total of 20 Vertex Gen AI Evaluation Service API requests. 100%|██████████| 20/20 [00:06<00:00, 3.32it/s] INFO:vertexai.evaluation._evaluation:All 20 metric requests are successfully computed. INFO:vertexai.evaluation._evaluation:Evaluation Took:6.0379220759999725 seconds
評価結果の表示と解釈
評価結果の確認方法は2つあります。
1つ目はコンソール上から確認する方法です。
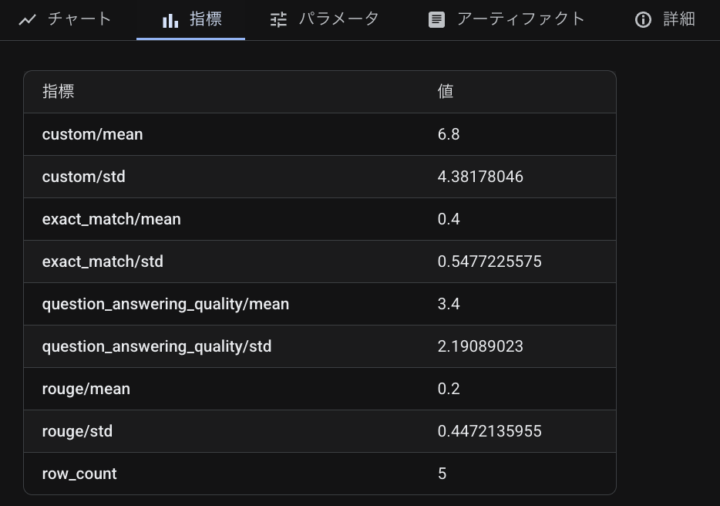
Vertex AI のテストに実行した結果のサマリーが表示されます。
2つ目は Vertex AI SDK for Python から確認する方法です。
実行結果のEvalResultから詳細を確認できます。
結果のサマリーは以下のようにします。
result.summary_metrics
コンソール上で確認したものと同じものが表示されます。
{
'row_count': 5,
'question_answering_quality/mean': np.float64(3.4),
'question_answering_quality/std': 2.1908902300206647,
'custom/mean': np.float64(6.8),
'custom/std': 4.3817804600413295,
'exact_match/mean': np.float64(0.4),
'exact_match/std': 0.5477225575051662,
'rouge/mean': np.float64(0.2),
'rouge/std': 0.447213595499958
}
データ毎の評価は以下のようにします。
result.metrics_table
以下のような DataFrame が出力されます。
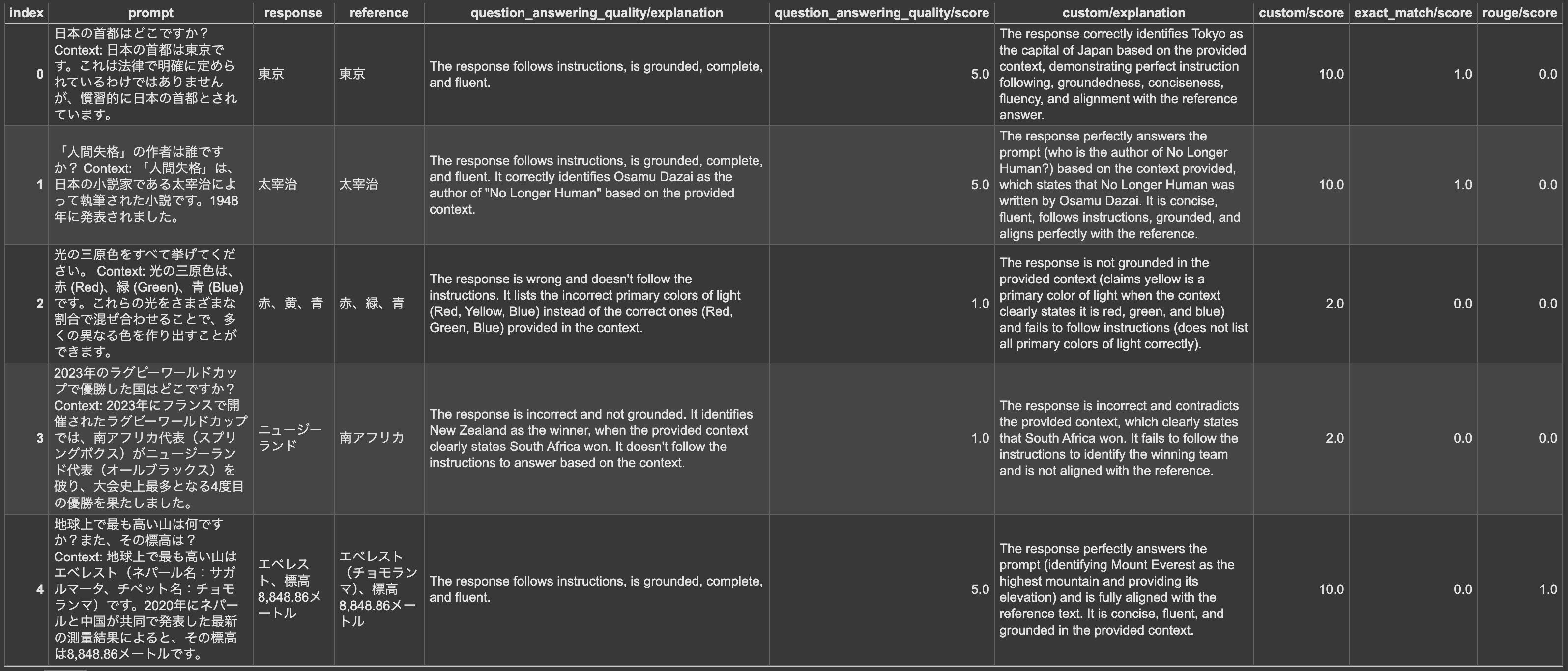
モデルベースの評価では、explanationがありスコアの根拠を示してくれています。
質問応答の品質(テンプレート)は5段階で、独自の評価は10段階でスコアリングしてくれていて、定義した通りの評価となっています。
間違っているデータはスコアが低くなっているのが分かります。
まとめ
Gen AI Evaluation Service を使用して、生成 AI の評価を行ってみました。
評価指標を定義しておけば、再利用も可能で定量的に生成 AI のパフォーマンスについて分析できるようになります。
Gen AI Evaluation Service は AI エージェントの能力も測定することが可能となっています。



