
はじめに
今回毎年サンフランシスコで行われる
Databricks Data + AI Summit 2025
に参加しましたので、サービスの紹介を行います
Data + AI Summitについて
Data + AI Summitは、Databricks が主催する、データ・機械学習・生成AIに関する世界最大級のカンファレンスです
日時:2025年6月9日〜12日
場所:米・サンフランシスコ Moscone Center(オンライン参加もあり)
規模:22,000人以上の参加者、700以上のセッションを予定
主な目的
データエンジニア、データサイエンティスト、分析担当者、経営者らが最新技術と実践を学び、ネットワーキングする場
ハンズオン・ワークショップ、基調講演、実践セッションを通じて、ビジネスへのデータ/AI活用を支援
記事の流れ
実際のプレゼンテーションスライドを用いて、日本語での簡易解説を行います。
📖 記事の目次
- はじめに
- Databricks Appsの紹介
- Databricks「Agent Bricks」の紹介
- Databricksの新サービス「Lakeflow」の紹介
- Databricks SQL 概要と最新アップデート
- Databricksの新機能「Genie」の紹介
Databricks Appsの紹介

Databricks Appsは、Databricksのプラットフォーム上で安全でガバナンスが効いたデータインテリジェンスアプリケーションを容易に構築・デプロイできるサービスです。
📌 特徴
1. シンプルで迅速なWebアプリ構築が可能となるサービスです
- 使い慣れたPythonフレームワークを活用可能(Streamlit, Gradio, Dash, Shiny, FastAPI, Flaskなど)
- 直感的で素早いアプリ開発・実行が可能
2. 高速な普及
- すでに20,000以上のアプリが作成済み
- 2,000以上のアクティブ顧客が存在(DAIS 2025発表時点)
3. 強力なデータインテリジェンス
- すべての開発をDatabricks環境内で完結
- シングルサインオン(SSO)を標準搭載し、すぐに利用可能
- 新たに「Lakebase」とのワンクリック統合をサポート
4. セキュアかつガバナンスの整った環境
- 複数リージョンと3つの主要クラウドにまたがるDatabricks管理コンテナとインフラ
- Unity Catalogを通じたリソースレベルのガバナンス
- 企業監査向けの認証・アクセスログ提供
5. オープンなエコシステム
- 幅広いPythonフレームワークに対応
- JavaScript(Node.js、React)のサポートを新たに追加
- プリインストールされたマネージドOSSパッケージを活用可能
Databricks Appsは、データとAIを駆使したアプリケーション構築を効率的かつセキュアに推進するための理想的なプラットフォームです。
Databricks「Agent Bricks」の紹介

Databricksの新サービス「Agent Bricks」は、エージェントの構築・運用に関する課題を解決するためのマネージドプラットフォームです。
🔹 Agent Bricksの開発の背景:エージェントの実用化を妨げる主な課題
エージェントの実用化を実際にする企業は以下のような課題に直面したことがあると思います
- 評価が困難
- 85%のユーザーが手動でエージェントを評価している。
- 調整要素の膨大化
- モデルやツール、各種パラメータ設定の選択肢が多く調整が煩雑。
- コストと品質のトレードオフ
- 品質を上げるためにはコストが増大する傾向にある。
🔹 Agent Bricksのポジショニング
Agent Bricksは、「高品質かつ構築容易」なエージェント構築環境を提供します。
これは、品質と実装難易度で起こりがちなトレードオフにおいて、両方のいいところどりを狙っています
* DIY型(高品質だが複雑)とノーコード型(簡単だが品質保証なし)の間を埋める存在。
🔹 提供されるエージェントの例
Agent Bricksが提供する種類は以下のようなものがあります
- 情報抽出エージェント
- 構造化されていないテキストを、名前、日付、エンティティなど構造化データに変換。
- カスタムLLMエージェント
- 分類やリライトなど、特定のドメイン向けにテキストを最適化。
- ナレッジアシスタントエージェント(RAG)
- 企業データを用いて迅速で正確な回答を提供。
- マルチエージェント・スーパーバイザー
- マルチエージェントはそれぞれのスペシャリストAIをたて、複雑なタスクを複数のエージェントで分担し、デバッグや再トレーニングの労力を削減する仕組みであり、この実装を強力にサポートします
🔹 使用例:情報抽出エージェント
- 法的文書・契約書
- 詳細情報(当事者、条件、日付)抽出と重要な不一致の定期検証。
- カスタマーレビュー
- 商品トレンドや顧客センチメント分析のため、カテゴリ別に分類・監視。
🔹 操作フロー例
情報抽出エージェント
- ラベルなしデータ提供と抽出スキーマ定義
- サンプルデータで品質検証
- コスト最適化を検討し結果比較
- Agent Bricksのエンドポイントで大量データを処理
マルチエージェント・スーパーバイザー
- 名前と説明を指定
- エージェント・ツール追加(Endpoint/Genie、UC機能、MCPサーバなど)
- ルーティング最適化(良い/悪いQ\&A例で精度を向上)
🔹 フィードバックを活用した自動調整
- LLMプロンプト調整
- Vector Index更新
- 新規LLMジャッジの追加
- 評価データセット再生成
- MCPサーバのガイドライン追加
- エージェント設定の最適化
🔹 利用可能なリージョン
現在以下のリージョンで利用可能であり、順次、拡大予定です。
- AWS: us-east-1、us-west-2
- Azure: eastus、eastus2、westus
Databricksの新サービス「Lakeflow」の紹介

「Lakeflow」は、Databricksが提供する統合ETLソリューションです。あらゆるデータに対して、高い信頼性を持つデータパイプラインを迅速に構築可能にします。
📌 Lakeflowとは?
Lakeflowには3つの概念があり、
- データ取り込み(Connect)
- データ加工(Declarative Pipelines)
- オーケストレーション(Jobs)
これらを統合した一元的なデータエンジニアリング基盤です。
📌 主な新リリース
Lakeflowには3つの概念を各自細かく説明します
- Lakeflow Connect
- 多様なデータソースとのコネクタを拡大
- Lakeflow Connect Zerobus
- イベントデータを直接Databricksに行レベルで取り込む機能
- Lakeflow Declarative Pipelines
- 新たなパイプラインエディタの導入
- コンピュートタイプの拡充
- オープンソース化
- Lakeflow Designer
- ノーコードETLを実現する新機能
📌 Lakeflow Connect コネクタ拡充
- Applications: Salesforce, Workday, ServiceNow, Google Analytics, Oracle NetSuite, Dynamics 365
- File sources: Amazon S3, Azure Data Lake Storage, SharePoint, SFTP
- Databases: SQL Server, PostgreSQL, MySQL, Oracle Database, IBM DB2, MongoDB
📌 Lakeflow Connect Zerobus
主なメリットはストリーミングエンジンのメンテナンス、チューニングが不要なニアリアルタイムのインターフェースです。
この2画像がその差となり、明確なメンテコストの減少が認識できます。

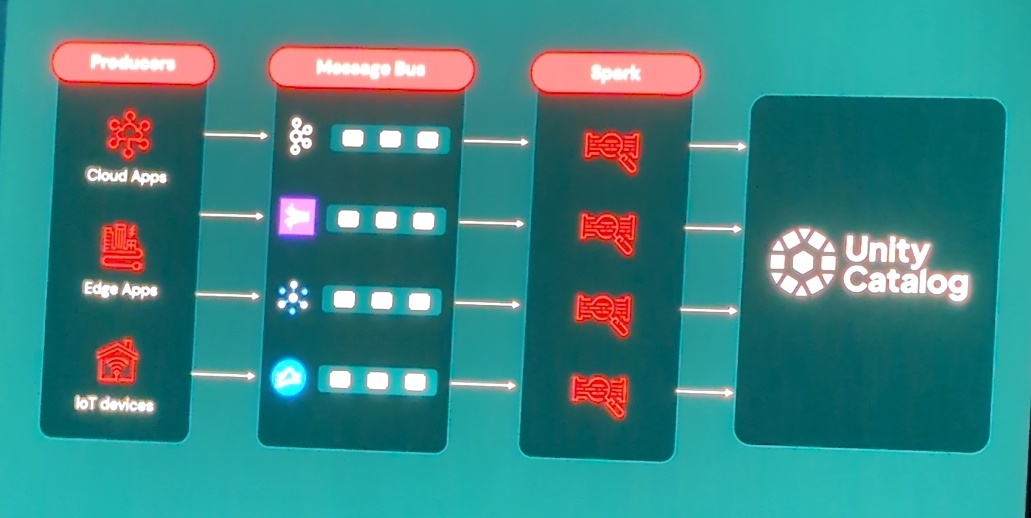
- 特徴とメリット:
- 取り込みのレイテンシーは約5秒
- コネクションごとに最大100MB/秒のスループット
- 数千クライアントの高い同時実行性
- インフラの簡素化(データホップ削減、データコピー不要)
- Unity Catalogによる統一されたガバナンスとDatabricks分析ツールとの統合
📌 Lakeflow Declarative Pipelines
かつてDLTと呼ばれていたものが刷新しました。以下拡張が行われています
- 新パイプラインエディタの機能:
- 複数ファイルのタブ切替
- パイプライン設定と実行
- 自動テーブル可視化
- コードファイル管理
- テーブルのデータプレビュー
- パフォーマンスとメトリクスの確認
- エラー調査
- 部分的な実行による効率的な開発とデバッグ
Lakeflowは、迅速で柔軟性の高いデータ処理を実現する、Databricksの最新ソリューションです。
📌 Serverlessコストパフォーマンス向上
ServerlessコストパフォーマンスがEnzymeの技術を採用することで達成できました。
- Enzyme:
- 自動で最適な増分更新テクニックを適用
- インクリメンタル処理の高速化
- サポートする操作が拡大(Left outer join, Inner join, Window Function等)
- Standard Mode:
- サーバレスエンジンの改善により、TCOを最大50%削減
- 既存パフォーマンスモードとの組み合わせで柔軟な選択肢を提供
Databricks SQL 概要と最新アップデート
Databricks SQLでは、ETL処理のシンプル化や移行支援のための新機能が多数提供されています。ここではDAIS2025で紹介された主要な新機能をまとめます。
1. ETL用のSQLシンプル化
Databricks SQLでは、SQLスクリプトおよびストアドプロシージャ、テンポラリーテーブル、マルチステートメントトランザクションなどの機能が提供され、純粋なSQLによる複雑なデータパイプラインの構築・移行を支援します。
かつて煩わされていた難解なSparkやMapReduceの処理をSQLで統一して記載することが可能です


SQL Scripting + Stored Procedures
- ANSI SQL/PSM規格に準拠
- Apache Sparkベースでオープンソース化
- 条件分岐、ループ処理、例外処理などの複雑なロジックをSQLで実現
- ベンダーロックインなし、Unity Catalogでの管理が可能
- 現在パブリックプレビュー
Temp Tables
一時テーブルが利用可能となりました。今までの一時ビューとの違いとしては、
よくある定義後のデータ変更が可能という点をフォローしています。
- ETLやアドホックなデータサイエンス用途の中間ステップとして活用可能
- セッションスコープで自動クリーンアップされるため、管理が容易
- レガシーDWHからの移行を容易にする
- プライベートプレビュー中
Multi-Statement Transactions
複数sqlのall or nothing処理が可能となりました。
- 複数のSQLステートメントをオールオアナッシングの操作としてアトミックに実行
- 同時並列DMLステートメントの実行時のレイテンシーが従来比で最大5倍高速
- プライベートプレビュー中
新機能と機能強化の概要
Databricks SQLには、以下の領域で新機能や機能強化が行われています。
ETL・移行機能
- SQL Scripting
- SQL Stored Procedures
- Temp Tables
- Multi-Statement Transactions
- Recursive CTE
- Collations
地理・時間・半構造化データの強化
- Spatial SQL
- Spatial Joinのパフォーマンス改善
- Geometry / Geography型
- Timeデータ型の強化
- Variant型およびShreddingの改善
- Variant型 + XML/CSVのサポート
AI関連機能の強化
- AI Functions Performance at Scale
- Multi-Modal AI Functions (AI_Parse, AI_Query)
- ClaudeやGPTを利用したAI_Query
- Vector_Search、AI_Forecast、AI_Extract
- 構造化出力 (JSON, テーブル形式)
これらの新機能と機能改善により、Databricks SQLはより高度で複雑なデータ処理・分析に柔軟に対応できるようになっています。
2. Databricksへの包括的な移行ツール
Lakebridge (GA)
LakebridgeがGAとなりました。
Databricksへの移行を簡素化する包括的な移行ツールで、レガシーシステムからのデータおよび処理の移行を容易にする機能です。
Databricksの新機能「Genie」の紹介
Databricksの新機能である「Genie」は、自然言語でデータに問いかけることができる対話型アナリティクスツールです。
Genieとは?
- 会話型アナリティクス: 自然言語で質問をするだけで、迅速にデータから答えを取得できます。
- ビジネス最適化AI: 顧客固有のデータや文脈を理解し、的確な回答を提供します。
- ガバナンスとセキュリティ: Unity Catalogによるデータガバナンスとセキュアな結果表示が可能です。
- 柔軟なアクセス性: APIを利用したカスタムアプリへの組み込みや、AI・BI・ダッシュボードとの連携が容易です。
新機能:Knowledge Storeの導入
従来の課題
従来のGenieでは、必要な権限がないとテーブル情報の編集やビュー作成が困難でした。また、Genieへの指示文作成も複雑で、設定が難しいことが課題でした。
解決策:Knowledge Store
Knowledge Storeはデータに「意味付け」(文脈)を簡単に追加できる新たな仕組みです。
これはGenieへテーブルデータの解釈をフォローすることができます。
- カラムの別名や、カラムの意味、頻繁に使用されるSQL定義をフォーム入力で設定可能
- プログラミングの知識不要
Knowledge Storeの詳細機能
- 不要なカラムの非表示化: 新たなデータセットを作成せずに不要なカラムを隠し、Genieの精度を向上できます。
- ローカルでの説明文編集: Unity Catalogの権限がなくても、ローカルスペースでテーブルやカラムの説明を編集可能。これにより、より正確な回答を得るための調整・改善が容易になります。
- カラム別名の追加: 難解なカラム名を自然言語に近い別名に変更し、Genieが理解しやすくします(例:「cryptic_name」を「売上日」に変更)。
