
はじめに
こんにちは!開発エンジニアのクリスです!
先日開催された Google Cloud Next Tokyo 2025 に参加してきました。数あるセッションの中でも、特にMLOpsの観点で興味深かった「BigQuery 継続的クエリと Vertex AI を活用したリアルタイム レコメンド システムの構築」について、個人的な学びや気づきをレポートします。
MLOpsの観点で、データ処理の継続性とリアルタイム性がいかにビジネス価値を左右するか、そして開発組織のあり方まで言及した、非常に示唆に富んだセッションでした!
セッション概要
タイトル: BigQuery 継続的クエリと Vertex AI を活用したリアルタイム レコメンド システムの構築
登壇者:
- 河西 隼太郎 氏(合同会社DMM.com データ基盤開発部 データアプリケーショングループ ML基盤チーム チームリーダー)
- 上田 亮 氏(合同会社DMM.com データ基盤開発部 データアプリケーショングループ ML基盤チーム)

本セッションでは、合同会社DMM様がどのようにして従来のバッチ処理によるレコメンドシステムから脱却し、BigQueryの継続的クエリを活用してリアルタイムなレコメンドを実現したのか、その背景、アーキテクチャ、そして得られた知見が語られました。
背景と課題:1日のラグがもたらす機会損失

合同会社DMM.com 様(以降 DMM 様)では、DMM TVをはじめとする多様なエンターテイメントコンテンツを提供しており、ユーザーに異なる作品を薦める「レコメンド機能」は非常に重要です。
セッションは、同社のMLOpsチームとMLエンジニアチームが、それぞれ独立して業務を遂行できる体制を構築しているという紹介から始まりました。
従来のレコメンドが抱えていた課題

従来のレコメンドシステムは、1日ごとのバッチ処理で運用されていました。この方式は安定的である一方、大きな課題を抱えていました。

- 行動反映のタイムラグ: ユーザーの視聴履歴などがレコメンドに反映されるまで、最大で1日のラグが発生。
- 機会損失: ユーザーが「今」興味を持っているコンテンツをタイムリーに提供できず、ビジネスチャンスを逃していた。
- 新規ユーザーへの対応: 視聴履歴のないユーザーに対して、効果的なレコメンドが難しい。
これらの課題は、単にユーザー体験に直結するだけでなく、「MLエンジニアとMLOpsエンジニアの責任分界点が曖昧で開発のボトルネックになる」といった組織的な課題にも繋がっていました。効果検証に時間がかかるため、改善サイクルをいかに速く回すかが求められていたのです。

アーキテクチャ解説:SQLだけでリアルタイム処理を実現
(ここから上田氏にバトンタッチ)
この課題を解決するために構築された新しいリアルタイムレコメンド基盤。その心臓部となるのが BigQuery です。
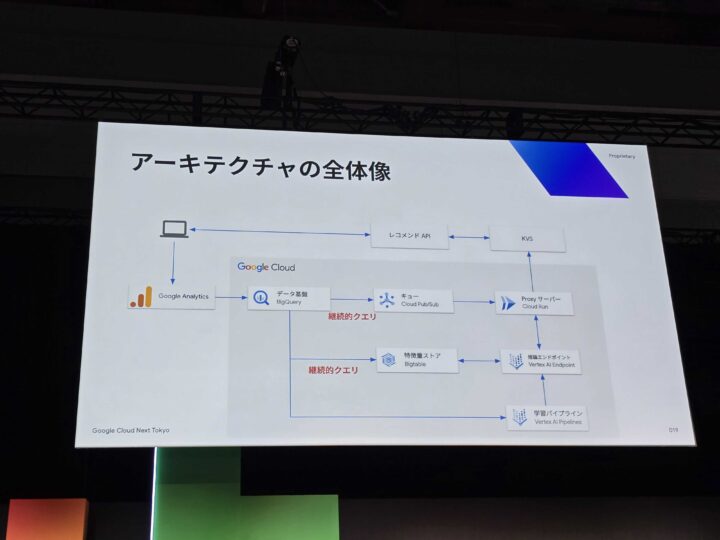
特に重要な役割を担うのが BigQuery 継続的クエリ (Continuous Queries) です。これは、SQLをBigQuery上で継続的に実行し、リアルタイムでデータをストリーム処理して、Pub/Sub、BigQuery tables、Bigtable、Spannerといった他のサービスへエクスポートできる機能です。

なぜBigQueryだったのか?
DMM様がBigQueryを選択した理由は明確でした。
- GA4との連携: 既に社内でGA4を利用しており、リアルタイムなイベント収集基盤が存在したこと。
- SQLだけで完結: ドメイン知識が必要な複雑なストリーミング処理も、使い慣れたSQLだけで記述できるため、学習コストを抑え、迅速な開発が可能だったこと。


アーキテクチャの詳細
データの流れは以下のようになっています。
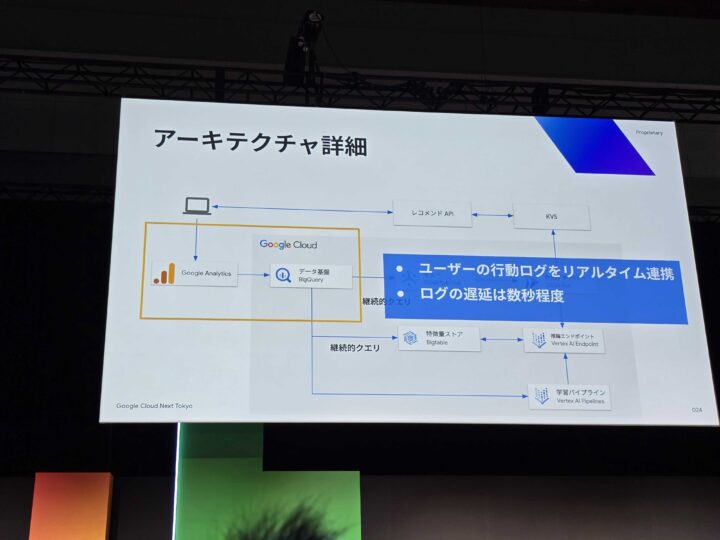
- GA4: ユーザーイベントを低ラグで収集し、BigQueryへ連携。
- BigQuery 継続的クエリ: リアルタイムでイベントを処理し、特徴量を生成。
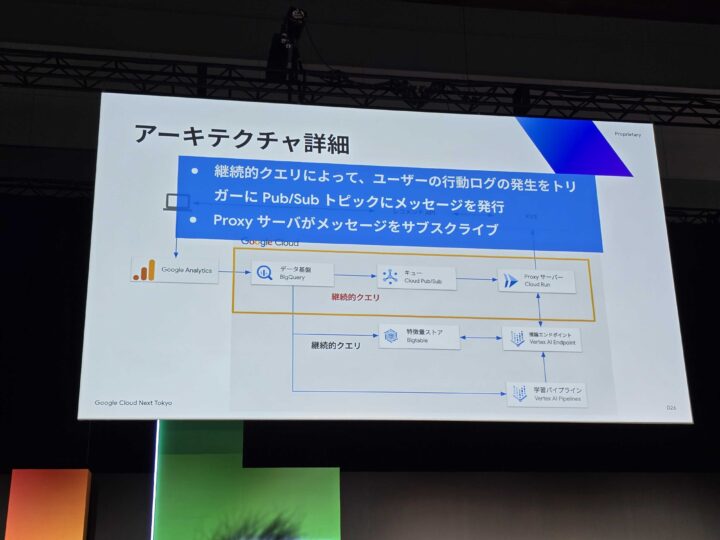
- Pub/Sub & Cloud Run: Cloud Runで構築されたプロキシサーバーがPub/Sub経由でメッセージを受け取り、推論リクエストをVertex AIのエンドポイントへ送信。
- Vertex AI: 受け取ったリクエストを基に推論を行い、レコメンド結果を返す。
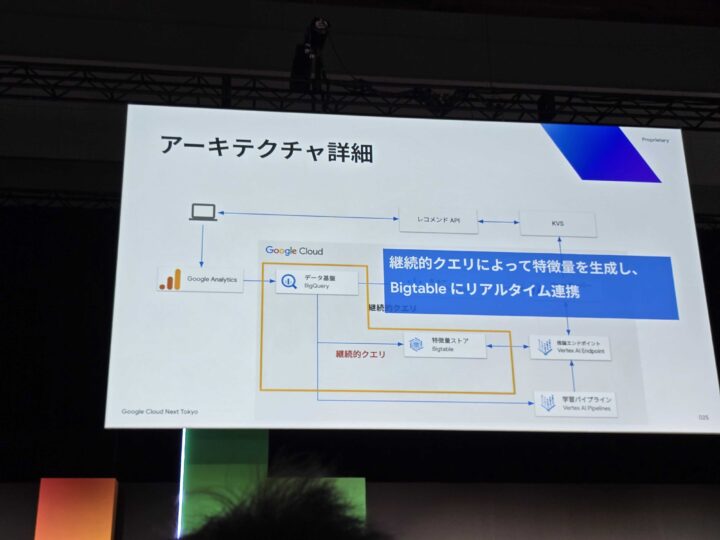

また、Vertex AI Pipeline を活用して推論エンドポイントのデプロイを自動化し、MLOpsの効率化も図られていました。

得られた知見と成果
このプロジェクトを通じて、技術的な側面だけでなく、組織運営においても多くの知見が得られたと語られました。

- 責任分界点の明確化: 事前にコンポーネントごとの担当を明文化したことで、ボトルネックが解消され、MLエンジニアはビジネスロジックの開発に集中できるようになった。
- 拡張性を意識した基盤整備: CI/CDパイプラインや共通ライブラリを整備し、将来的な機能追加を容易にした。
- データ品質の監視: Dataplexの自動データ品質チェック機能を活用し、入力されるログデータの品質を担保。
- SLOの設定: 推論APIのレスポンスタイムなどを監視し、サービスの信頼性を確保。


苦労した点
一方で、開発では苦労した点もあったそうです。

- 継続的クエリのジョブ管理: 日時で継続的なクエリが参照するテーブルを毎日切り替えること。
- Vertex AI エンドポイントの日次更新: Private Endpointの採用で、同時に2つのモデルをデプロイし、トラフィックの切り替えが不可能だった。

それらを克服するために、独自で設計した自動化のワークアラウンドによって解消されました。
まとめ:3つの大きな成果
本セッションで語られた取り組みの成果は、以下の3点に集約されます。
- 最短1分への改善: ユーザーの行動がレコメンドに反映されるまでの時間を、従来の最大1日から最短1分へと劇的に短縮。
- 協業体制の確立: MLOpsチームとMLエンジニアチームの役割を明確化し、生産性の高い開発体制を整えた。
- 継続的クエリの活用: BigQuery継続的クエリという新しい技術を活用し、リアルタイムなML基盤をスピーディに構築した。

さいごに
今回のセッションは、単なる技術紹介に留まらず、「技術」と「組織」の両輪でいかにしてビジネス課題を解決していくかという、非常に実践的な内容でした。
特に印象的だったのは、新しい技術を導入するだけでなく、それを使うエンジニアが最大限のパフォーマンスを発揮できるよう、責任分界点の明確化や基盤整備といった組織的な取り組みを同時に進めていた点です。これにより、MLエンジニアが本来注力すべきビジネスロジックに集中できる環境が生まれるのだと、改めて感じました。
このセッションで得た学びを、今後のプロジェクトにも活かしていきたいと思います!




