この記事のポイント
- Vibe AnalyticsとVibe Intelligenceの概要を説明しているよ
- Looker 会話分析の概要と利点を説明しているよ
- Looker 会話分析を使った運用分析の例を紹介しているよ
はじめに
この記事はLookerの会話分析を使って運用分析を行う方法について説明します。
また、雰囲気で分析をする。つまり「Vibe Analytics」あるいは「Vibe Intelligence」と呼ばれる手法を紹介します。
誤りなどがありましたら随時、修正していく予定です。
俺たちは厳密にデータを分析する
従来、BIによる分析はデータの収集、加工、集計、可視化、そして分析といった一連のプロセスを経て行われてきました。
とくにデータアナリティクスの工程(集計と可視化)では専門的な知識とスキルが必要とされ、多くの時間と労力がかかっており、
データの解釈や洞察の抽出には高度な分析能力が求められ、これが分析のボトルネックとなっていました。
具体例: 店舗の売上データ分析における課題
ここで、厳密なデータ分析について具体的な例を挙げてみましょう。
たとえば、ある店舗の売上データを格納したデータセットがあるとします。
このデータセットには、日付、店舗名、売上金額、商品カテゴリ、ユーザー属性の情報が含まれています。
このデータセットに対して「1ヶ月の売上の傾向を分析し、売上が高い商品カテゴリをどんなユーザーが購入しているかを5つピックアップしたい」という分析課題があったとき、さまざまな疑問が生じます。具体的には以下のとおりです。
- 1ヶ月とは直近30日のことか、それとも特定の月(前月)のことか?
- 売上の傾向とは、売上金額の増減を指すのか、それとも売上件数の増減を指すのか?
- 売上が高い商品カテゴリとは、売上金額が最も高いカテゴリを指すのか、それとも売上件数が最も多いカテゴリを指すのか?
- どんなユーザーとは、年齢層や性別、地域などの属性を指すのか?
これらの疑問に対する明確な定義や基準がない場合、分析者は自分の解釈や経験に基づいて分析を行うことになります。
その結果、分析の結果が一貫性に欠けたり、誤った結論に至ったりする可能性があります。
また、チームでの分析では分析者間での解釈の違いやコミュニケーションの齟齬が生じることもあり、これが意思決定の遅延や誤った分析につながります。
雰囲気でデータを分析したい
厳密なデータ分析には多くの時間と労力がかかり、専門的な知識とスキルが必要とされることは前述のとおりです。
しかし、スピードが重要なビジネスにおいてはすぐに結果を得たい場合も多いです。
いわゆる、「本当にざっくりで良いのでどういう傾向があるのかを知りたい」というニーズも存在します。
そこで、厳密な分析ではなく、雰囲気でデータを分析する「Vibe Analytics」という手法が注目されています。
Vibe Analyticsとは
Vibe AnalyticsとはLLMを駆使したAI駆動型のデータ分析手法です。自然言語でデータに質問を投げかけることで、迅速にデータの傾向や洞察を得ることができます。BIに対してVI(Vibe Intelligence)によって実現できます。
具体的には、以下のようなプロンプトでデータに質問を投げかけます。
前月の売上傾向を分析し、売上が高い商品カテゴリをどんなユーザーが購入しているかを5つピックアップしてください。
ここで重要となるのが、質問の解釈や分析の基準をAIが自動的に行う点です。
自然言語の質問は曖昧さを含むため、ここにはプロンプトエンジニアリングの技術が必要となりますが
Vibe Analyticsではそれに加えて質問の元となるデータのデータモデリングが重要となります。
※データモデリング:データの構造や関係性を定義し、データの意味や利用方法を明確にするプロセス
データモデリングをするにあたってはセマンティックレイヤーを活用します。
セマンティックレイヤーとは
セマンティックレイヤーとは、データの意味や関係性を定義し、ユーザーがデータを理解しやすくするための抽象化された層です。
参考:セマンティックレイヤー:データ活用を加速する意味付けの仕組み – Databricks
セマンティックレイヤーを活用することで、ユーザーはデータの技術的な詳細を気にすることなく、データを理解して分析することができます。
実際にどのようなものなのかは「Looker 会話分析とは」のセクションをとおして説明します。
Lookerにおけるセマンティックレイヤー
LookerではLookMLという独自のモデリング言語を使用してデータをモデリングし、セマンティックレイヤーを構築します。
※LookMLの基本的な概念について説明を省略します。以下の記事を参照してください。
※LookMLについては以下の動画でも解説していますので参考にしてください。
Looker 会話分析とは
Looker 会話分析は、Lookerのセマンティックレイヤー(LookML)を活用して、自然言語でデータに質問を投げかけることができる機能です。
※英語ドキュメントではConversational Analytics in Lookerと呼ばれています。
参考:Conversational Analytics in Looker
ドキュメントではGemini for Google Cloudのひとつとして説明されています。
ドキュメントでは以下のように説明されています。
会話分析を使用すると、ビジネス インテリジェンスの専門知識を持たないユーザーでも、通常の自然言語(会話)でデータ関連の質問を行い、静的なダッシュボードでは得られないデータを入手できます。
題材:クラウドの運用分析を自然言語で行う
今回はLooker 会話分析を使ってクラウド運用の分析を行います。
弊社の環境では運用分析プラットフォームというプラットフォームを長年に渡って社内に提供しており、「いつどこでだれがどのような案件に関わったのか」という情報を一元的に管理しています。ニアリアルタイムで分析できるようにしており、もちろんLookerで分析できるようにしています。
参考:クラウド監視・運用保守の品質がさらに進化。AMS 適用やインシデント対応品質を高める「運用分析プラットフォーム」を短期間で構築
Lookerの会話分析を使って、クラウドの運用分析を自然言語で行う例を紹介します。
今回やることは以下のとおりです。
- 運用分析エージェントの作成
- 会話
なお、今回は実際に運用しているAMS(次世代監視基盤)とPagerDutyの運用データを扱いますので一部のデータはマスクしています。
運用分析エージェントの作成
まずは Looker 会話分析の画面を開きます。メニューから会話をクリックします。
エージェントの管理をクリックします。
エージェントの管理からエージェントを作成します。
エージェントの設定は以下のとおりです。
エージェント名:運用分析プラットフォームくん 説明:AMSとPagerDutyのデータを可視化するエージェントです。 データ:運用分析プラットフォームのデータ 手順:どんな検索でも[JST年月日]を使って期間を計算するようにしてください。
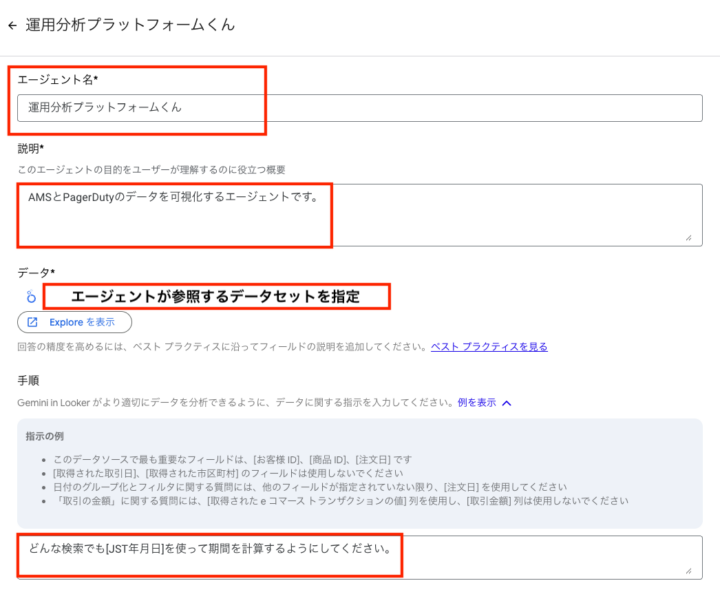
最後に保存をクリックします。
自然言語でクラウド運用と対話する
エージェントができたら、会話を開始します。右側のテキストエリアに質問を入力します。
※今のところ、日本語の場合はコピーアンドペーストで入力しないとうまく認識しません。
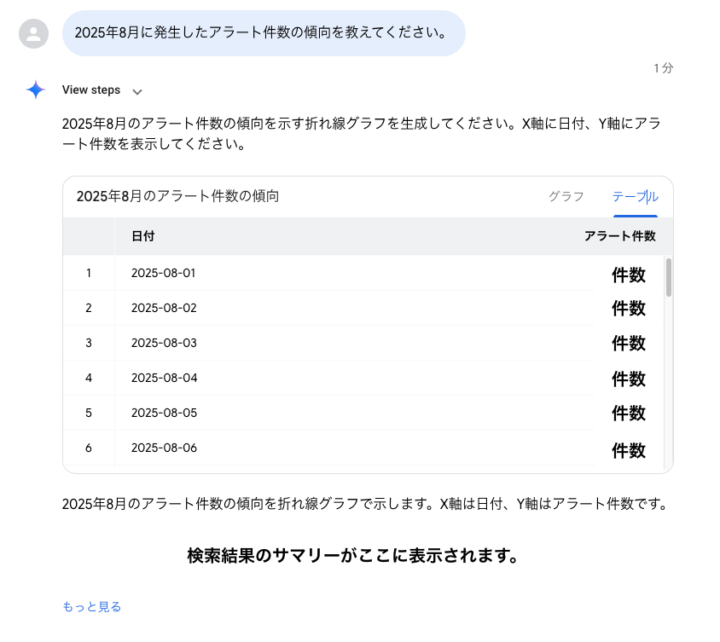
試しに以下の質問を入力してみます。
2025年8月に発生したアラート件数の傾向を教えてください。
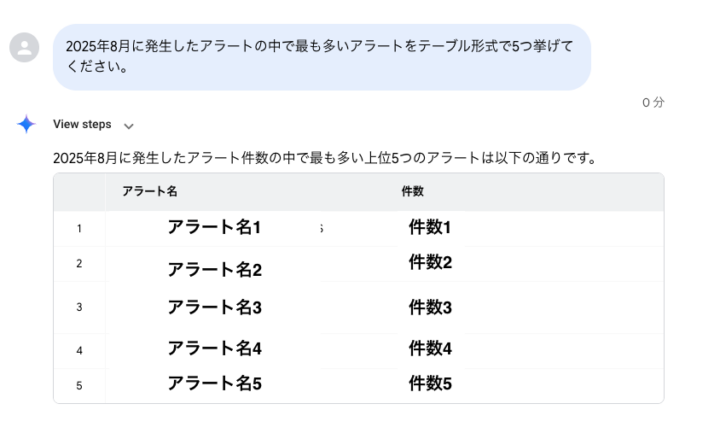
今度は以下の質問を入力してみます。アラート件数の上位5つを挙げるように指示をしてみます。
2025年8月に発生したアラートの中で最も多いアラートをテーブル形式で5つ挙げてください。
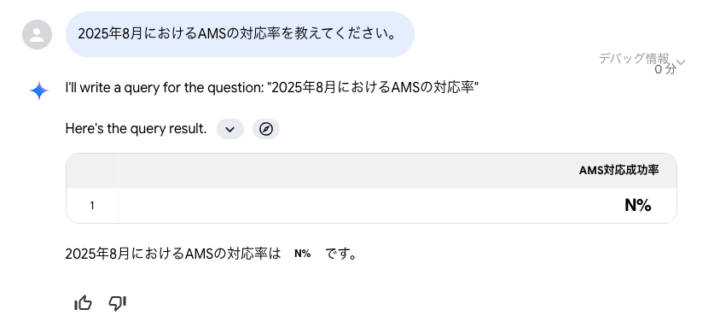
今度はAMSに関する質問をしてみます。
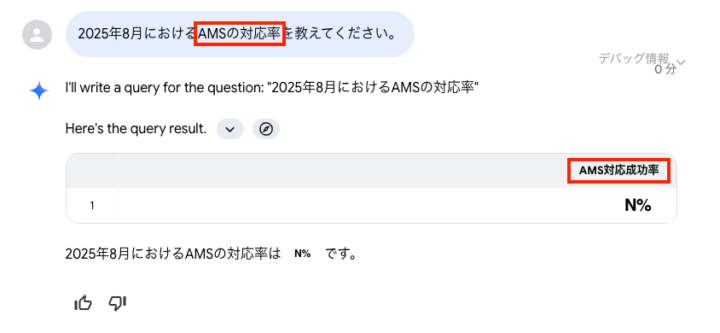
2025年8月におけるAMSの対応率を教えてください。
最後に以下の質問を入力してみます。
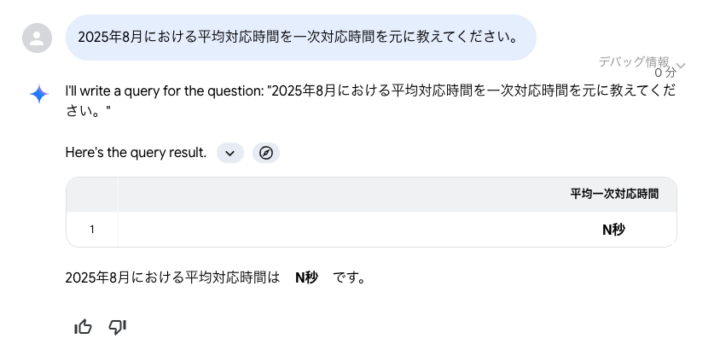
2025年8月における平均対応時間を一次対応時間を元に教えてください。
Looker 会話分析の利点
Looker 会話分析を使うことで、以下のような利点があります。
- 自然言語で質問ができるため、SQLなどの専門的な知識やスキルが不要
- セマンティックレイヤーを活用するため、データの技術的な詳細を気にする必要がない
- 質問の解釈や分析の基準をGeminiが自動的に行うため、迅速に結果を得られる
- チームでの分析においても、解釈の違いやコミュニケーションの齟齬を減らせる
前述の具体例のように、厳密な定義や基準がない場合でも、Geminiが解釈して分析を行うため、分析の結果が一貫性に欠けたり、誤った結論に至ったりする可能性が低くなります。
つまりは細かいことを気にすることなく雰囲気(Vibe)で、データ分析(Analytics)ができるようになります。(Vibe Analytics!!)
Looker 会話分析の注意点
実際に使ってみてLooker 会話分析には以下のような注意点があると思いました。
- 質問の解釈や分析の基準がGeminiに依存するため、必ずしも正確な結果が得られるとは限らない
- データモデリングの設計やセマンティックレイヤー、プロンプトエンジニアリングの技術が必要となる
たとえば、今回示した運用分析を題材にした例においては「AMS対応率」が「AMS対応成功率」として解釈されてしまい、正しい結果が得られませんでした。
※再掲:2025年8月におけるAMSの対応率を教えてください。
AMS対応率はすべてのアラート対応においてAMSが対応した割合を指しますが、AMS対応成功率はAMSが対応したアラートの中でもAMSの対応によってアラートが解決した割合を指します。
計算式で表現すると以下のとおりです。
AMS対応率 = (AMSが対応したアラート件数) / (全アラート件数) AMS対応成功率 = (AMSが対応して解決したアラート件数) / (AMSが対応したアラート件数)
少しの言葉の違いで大きな違いが生じるため、Looker 会話分析を使う際には、データモデリングとセマンティックレイヤーの設計が重要となります。(重要なことなので2度)
LookMLを活用してデータモデリングをきちんと行うには
会話分析を活用するには、LookMLを活用してデータモデリングをきちんと行うことが重要です。しかし、実際にやろうと思うとかなり大変です。
そこでLookMLを活用してデータモデリングをきちんと行うためのサービスとしてLookML Assistantがありますが、今回は名前とドキュメントだけ紹介します。
なお、今回紹介した会話分析以外にもさまざまなアップデートが紹介されています。詳細は以下のレポートを参照してください。
【Google Cloud Next Tokyo 2025】AI for BI – データ活用の未来を拓く Looker 最新アップデート
まとめ
今回はLookerを使って、弊社で稼働中の運用分析プラットフォームにGeminiを導入し、Vibe Analyticsをやってみました。
まだまだ課題はあるものの、分析のための準備をほとんど行うことなく、自然言語だけで分析できるのはとても良いと感じました。
具体的には「〜のアラートがどれくらいあるかすぐに分析に対応できる?」といったカジュアルでアドホックな分析をする際にはプロンプトを考えるだけ良くなります。
ただし、その一方で分析を行うデータセットのモデリングをきちんとしていないと誤ったデータが算出されてしまうため、より厳密なセマンティックレイヤーの構築が必要になります。
何のために誰のためにデータモデリングをするのかをよく考える必要がありそうです。今回は以上です。