はじめに
Lookerを使ってみて1年くらい経過したので今回はLookMLを使ってViewを作成するコツについて書いてみようと思います。
なお、この記事ではサンプルデータを使ってLookerにおけるViewの作り方について解説しています。
前提のおさらい
まず、LookerにおいてViewは可視化に利用する仮想のテーブルです。Lookerそのものはデータベースを管理しません。
Lookerはデータベースに対してクエリを発行してテーブルを作成、作成したテーブルをViewとして扱います。
つまり、View=テーブルという関係が成り立ちます。
Viewとテーブルの関係について深掘り
Lookerはデータベースあるいはデータソースを持たない関係上、接続先にあるデータベースからテーブルを参照してViewを作成します。
Viewを作成する過程でクエリを発行するため、厳密にはクエリ→テーブル→Viewという関係です。
LookerではViewが参照可能であり、Viewはderived tableです。derived tableは日本語で派生テーブルと呼びます。
下記のように派生テーブルには種類があります。
- ネイティブ派生テーブル
- SQLベースの派生テーブル
これらはLookMLによって定義されます。
ネイティブ派生テーブルとSQLベースの派生テーブルの違い
LookMLで各種テーブルをどのように定義するかを確認するまえに大前提として派生テーブルはLookMLによって定義されます。
ここでは2つの派生テーブルの違いについて説明すると、以下のようになります。
| 項目 | ネイティブ派生テーブル | SQLベースの派生テーブル |
|---|---|---|
| 定義方法 | LookML | SQL |
| 作りやすさ | 比較的にむずかしい | 比較的にやさしい |
| 良さ | SQL不要のスキルなくてもデータ分析が可能 | すでにあるSQL資産を活用できる |
SQLベースの派生テーブルはSQLで定義するとありますが、厳密にはLookML内にSQLで定義することによって作成します。
なお、既存のSQLが存在する場合はLookerのSQL Runnerを使うことでView構築に必要なLookMLを機械的に生成できます。
また、SQLを一切書かずにViewを作成できる反面、LookMLを知らないユーザーにとってはややむずかしいと言えます。
LookMLのコンセプトについては以下に示す公式ドキュメントもしくはiret.mediaで説明していますので参考にしていただけたらと思います。
参考:LookMLの紹介 – cloud.google.com
参考:Lookerを使い始めてから浮かぶ疑問点を整理してみた – iret.media
補足:LookMLのすみ分けや作り方
ネイティブ派生テーブルとSQLベースの派生テーブルを組み合わせることは可能ですが、
Lookerのベストプラクティス、開発ガイドラインを作成するには
「LookML ファイルを明確に整理して、一貫性を保ち、操作しやすくする」
ということが推奨されているため、ネイティブ派生テーブルとSQLベースの派生テーブルを混在させることは避けるべきだと個人的には考えます。
とくに、異なる派生テーブルで同じ処理を実行している場合はどちらかの派生テーブルに統一することが望ましいです。
作り方について説明するとキリがないため、細かい説明は別の機会にしますが、一例を挙げるとすると
「明確にモデルを分離しておいて、モデル毎に作成する派生テーブルを変更する」などの対応がとれれば、両者の派生テーブルは混在させても問題ないかもしれません。
たとえば、SQLの派生テーブルを作るタスクはモデルAで対応、ネイティブ派生テーブルを作るタスクはモデルBで対応するといった具合です。
ただし、異なるモデルで同じ処理、厳密には同じ意味を持つ処理を書くことは避けるべきです。
LookMLでの派生テーブルを定義する
ではどのようにして派生テーブルを定義すれば良いのでしょうか。
LookMLでViewを定義するには、viewキーワードを使います。viewキーワードの後にView名を記述します。
view: view_name {
# Viewの定義
}
以下の例はSQLベースの派生テーブル(View)を定義する例です。
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
上記のSQLベースの派生テーブルではcustomer_order_summaryというViewを定義しています。
なお、SQLベースの派生テーブルはネイティブ派生テーブルで書き直すことも可能です。
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: time {
field: orders.time
}
column: amount {
field: orders.amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension: time {
type: time
sql: ${TABLE}.time ;;
}
measure: first_order {
type: min
sql: ${TABLE}.time ;;
}
dimention: amount{
type: number
sql: ${TABLE}.amount ;;
}
measure: total_amount {
type: sum
value_format: "0"
sql: ${TABLE}.amount ;;
}
}
ExploreでViewを利用することを前提にしたViewの作り方
ここまででViewの基本的な作り方を説明しました。しかし、Viewを実際にLookerで利用する際には補足が必要です。
簡単に説明すると、LookerにはExploreというViewを利用してデータを取得するための機能があります。
Exploreを使うことでダッシュボードに配置するLookを作成できますが、下記のような作業がLookを作成する場合には必要です。
ExploreからViewを参照するにあたり、うまく管理や運用するため以下の3つの設定を強く推奨します
- ExploreのテーブルビューでLookを作成する場合はカラム名や書式指定を設定する
- 操作するカラム(ディメンション、メジャー)がどのようなものかExploreで確認できるように設定する
- 検索条件(フィルタ)を設定するように制限してデータソースへの負荷がかからないようにする
いくつかあるので順番に見ていきます。
ExploreのテーブルビューでLookを作成する場合はカラム名や書式指定を設定する
まず、ViewをExploreで利用する場合はカラム名(label)や書式指定(value_format)を設定します。
これによって、カラム名や書式がわかりやすくなるのと同時にLookの作成に統一感を持たせることができます。
これらは特定のdimensionやmeasureに定義できます。
カラム名と書式指定を設定する場合は下記のようにLookMLを定義します。
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
label: "Customer ID"
}
dimension: time {
type: time
sql: ${TABLE}.time ;;
label: "Order Time"
}
dimention: amount{
type: number
sql: ${TABLE}.amount ;;
label: "Order Amount"
value_format: "#,##0"
}
これでLookMLで定義した内容がExplore上の表示名に反映されます。
また、“を設定することで書式を設定できます。
操作するカラム(ディメンション、メジャー)がどのようなものかExploreで確認できるように設定する
次に、操作するカラム(ディメンション、メジャー)がどのようなものかExploreで確認できるように設定します。
ソースコードでいうところのコメントです。
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
label: "Customer ID"
description: "お客様を特定するIDです。"
}
dimension: time {
type: time
sql: ${TABLE}.time ;;
label: "Order Time"
description: "注文した時間を表します。"
}
dimention: amount{
type: number
sql: ${TABLE}.amount ;;
label: "Order Amount"
value_format: "#,##0"
description: "お客様が購入した金額を表します。"
}
これでExplore上でカラムの説明が表示されるようになり、ユーザーがどのようなカラムを操作するかがわかりやすくなります。
また、複数のdimentionおよびmeasureはソースごとにview_labelでまとめることができます。
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
label: "Customer ID"
view_label: "お客様情報"
description: "お客様を特定するIDです。"
}
dimension: time {
type: time
sql: ${TABLE}.time ;;
label: "Order Time"
view_label: "お客様情報"
description: "注文した時間を表します。"
}
dimention: amount{
type: number
sql: ${TABLE}.amount ;;
label: "Order Amount"
view_label: "お客様情報"
value_format: "#,##0"
description: "お客様が購入した金額を表します。"
}
上記のように定義することでお客様情報というview_labelでdimentionおよびmeasureをまとめることができます。
つまり、Exploreではお客様情報という括りでdimentionおよびmeasureを操作できるようになります。
ちなみに弊社ではPagerDutyのデータをLookerで可視化できるようにしているため、PagerDutyというview_labelで
dimentionおよびmeasureをまとめています。

検索条件(フィルタ)を設定するように制限してデータソースへの負荷がかからないようにする
最後に、検索条件(フィルタ)を設定するように制限してデータソースへの負荷がかからないようにします。
Exploreでデータを取得する際には、データソースに負荷がかかることがあります。
検索条件(フィルタ)によってはデータソースをフルスキャンすることにつながるため、データソースへの負荷を軽減するために検索条件を制限することが重要です。
検索条件(フィルタ)を制限するにはalways_filterをmodelに設定します。
explore: orders {
always_filter: {
filters: [orders.time: "2024-07-01 00:00:00"]
}
}
補足:検索条件(フィルタ)でsuggestionsを設定しないとフルスキャンを実行する?!
補足になりますが、LookerのExplorerでは以下のようなプルダウンメニューをフィルタに実装できます。
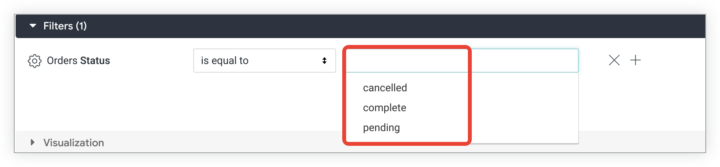
ですが、実装するうえでの注意点として以下のような点があります。
ダッシュボードで、ダッシュボード フィルタが type: string のフィールドをフィルタリングしている場合、Looker はフィルタ オプションも提案します。
これらのフィルタの候補は、ディメンションに対して SELECT DISTINCT クエリを使用して作成されるため、そのフィールドの既存のデータと一致する値のみが返されます。
つまり、なにも考えずにフィルタ条件にプルダウンメニューを実装して利用してしまうと
検索条件が設定されていないSELECT DISTINCTのクエリを実行してしまうため、テーブルに対してフルスキャンを実行することになります。
スキャンの対象に設定されているデータベースへの高い負荷や高額課金の原因になりますので注意が必要です。
上記の問題を暫定的に回避する場合はsuggestionsで入力候補をハードコードしておくことをおすすめします。
恒久的な対応ではparameterを実装するかもしくは入力候補用のテーブルを別で作成しておくことです。
リファクタリング
では前提を踏まえて、Viewをリファクタリングしてみましょう。
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: time {
field: orders.time
}
column: amount {
field: orders.amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
label: "Customer ID"
view_label: "お客様情報"
description: "お客様を特定するIDです。"
}
dimension: time {
type: time
sql: ${TABLE}.time ;;
label: "Order Time"
view_label: "お客様情報"
description: "注文した時間を表します。"
}
measure: first_order {
type: MIN
sql: ${TABLE}.time ;;
label: First Order
view_label: "お客様情報"
description: "初めて注文した時間を表します。"
}
dimention: amount{
type: number
sql: ${TABLE}.amount ;;
label: "Order Amount"
view_label: "お客様情報"
value_format: "#,##0"
description: "お客様が購入した商品の金額を表します。"
}
measure: total_amount {
type: sum
sql: ${TABLE}.amount ;;
label: "Sum Order Amount"
view_label: "お客様情報"
value_format: "#,##0"
description: "金額の合計を表します。"
}
}
Viewをテストする
LookerではViewをテストすることができます。以下の例は「ordersテーブルで2024-07-01 00:00:00のamountが3000円である」ことをテストする例です。sortsでは昇順に並べ替え、limitでは1件のみ取得するように設定しています。
test: orders {
explore_source: orders {
column: time {}
column: amount {}
filters: [orders.time: "2024-07-01 00:00:00"]
sorts: [orders.time: asc]
limit: 1
}
assert: amount {
expression: ${orders.amount} = 3000 ;;
}
}
まとめ
この記事ではLookerにおけるViewの作り方について説明しました。
作り方を説明するにあたって、Viewとテーブルの関係について深掘りし、クエリ→テーブル→Viewという関係が成り立つことを説明しました。
また、派生テーブルにはネイティブ派生テーブルとSQLベースの派生テーブルがあり、ネイティブ派生テーブルはSQLを使わないことを前提としているのに対し、SQLベースの派生テーブルはすでにあるSQL資産を活用できるという違いがあることを説明しました。
ExploreでViewを利用する際にはカラム名や書式指定を設定すること、操作するカラム(ディメンション、メジャー)がどのようなものかExploreで確認できるように設定すること、データソースへの負荷がかからないよう検索条件を制限する流れについて説明しました。
最後に作成したビューをテストする方法について解説しました。
おまけ
おさらいとしてこの記事で解説したLookMLの用語を図解にしておきますので参考にしてください。
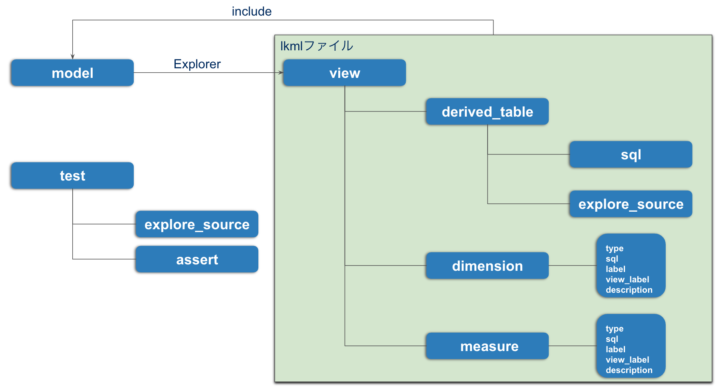
※lkmlファイル:viewファイルを定義するファイルのこと