
はじめに
日々の運用業務でアラート調査やQA対応を行う中、改めて効率的な調査手法を学びたいと感じていました。
そこで、DatadogのAPM(Application Performance Monitoring)に関するオフラインセミナーに参加する機会を得ました。
セミナーは、APMの基本的な概念から、実際のアプリケーションのデバッグ、ボトルネック特定方法まで、実践的な内容で有益な時間となりました。
この記事が、同じような課題を抱える方の助けとなれば幸いです。
イメージ図
今回のセミナーの全体イメージは以下のようなものになります。
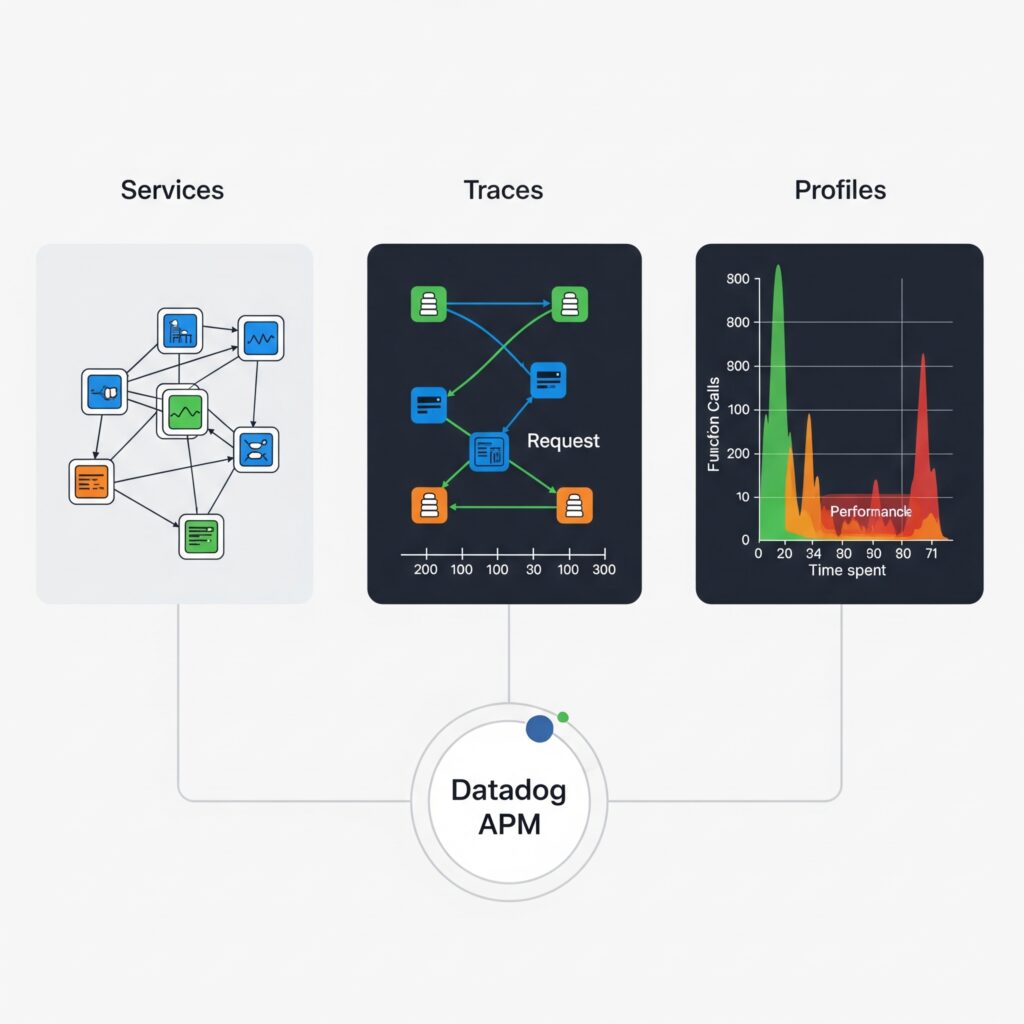
Datadog APMでできること:3つの主要機能
Datadog APMは、アプリケーションのパフォーマンスを監視し、問題の根本原因を特定するための強力なツールです。主に以下の3つの機能に分かれています。
- サービス(Service): マイクロサービス全体の健全性を一目で把握
- トレース(Traces): リクエストがアプリケーション内でどのように流れるか経路を追跡
- プロファイル(Profiles): コードレベルでの詳細なパフォーマンス分析
これらの機能は、アプリケーションの健全性チェックから、詳細なデバッグまで、開発者や運用チームを強力にサポートします。
1. サービス:マイクロサービスの全体像を把握
「サービス」は、アプリケーションを構成する個々のマイクロサービスやコンポーネントを一覧表示し、その健全性を確認する機能です。
- リアルタイムの依存関係マッピング: サービス間の連携を視覚的に把握できます。どのサービスがどのサービスに依存しているか、マップ形式で確認できます。
- 健全性の確認: リクエスト数、レイテンシー、エラーレートなどのハイレベルなメトリクスを一覧で確認できます。
- サービスカタログ: サービスのオーナーシップ情報や、GitHubリポジトリへのリンク、ダッシュボードへのリンクなどを一元管理できます。メトリクスを発行していないサービスでも、YAMLファイルをアップロードすることでリストに追加できるため、組織全体のサービスを網羅的に管理することが可能です。
セミナーでは「store-frontend」サービスにエラーが発生していることを題材にして実施体験をいたしました。
2. トレース:リクエストの旅路を追う
「トレース」は、ユーザーからの1つのリクエストがアプリケーション内でどのように処理されるかを詳細に追跡する機能です。
- リクエストのパス: リクエストがどのサービスを、どの順番で、どれくらいの時間をかけて通過したかを可視化します。これにより、レイテンシーの原因がどのサービスにあるかをすぐに特定できます。
- フレームグラフ(Flame Graph): トレースを時間軸で視覚化したもので、各「スパン」(棒グラフ)がメソッドやDBクエリなどの処理を表します。特に処理に時間がかかっている部分が長く表示されるため、ボトルネックが一目でわかります。
以下は、store-frontendサービスのリクエストトレースを示しており、discounts-serviceに1.55秒かかっていることがわかります。これは全体の実行時間の96.4%を占めており、明らかなボトルネックです。
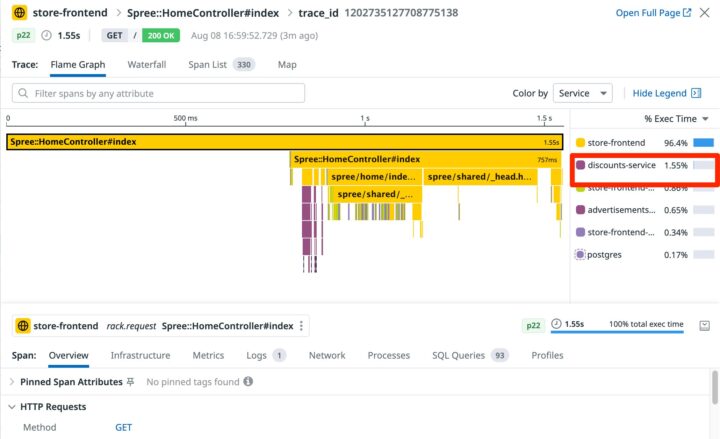
- APMエージェント: この機能を利用するには、各サービスにDatadog APMエージェントを導入する必要があります。エージェントがトレースデータを収集し、Datadogに送信します。
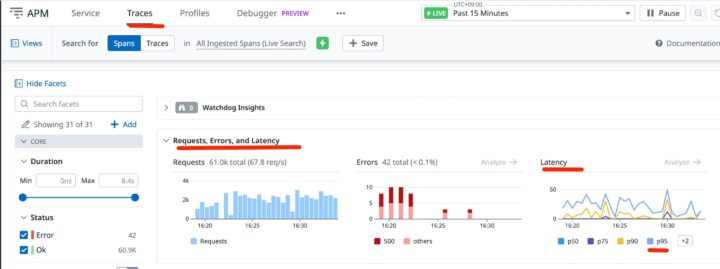
以下は、トレースの概要画面で、リクエスト数、エラー数、そしてレイテンシーの分布(p50、p75、p90、p95)を確認できます。p95(95パーセンタイル)のレイテンシーが突出している場合、一部のリクエストが非常に遅い状態であることを示唆しており、詳細な調査が必要です。
3. プロファイル:コードレベルのパフォーマンス分析
「プロファイル」は、追加ライセンスが必要な機能ですが、コードレベルでの詳細な実行状況を可視化します。
- 開発者向けの情報: どのコードがCPUやメモリを最も消費しているかなど、開発者がパフォーマンス改善を行う上で重要な情報を提供します。
- コードホットスポット: レイテンシーの原因となっている特定のコードブロックを特定できます。
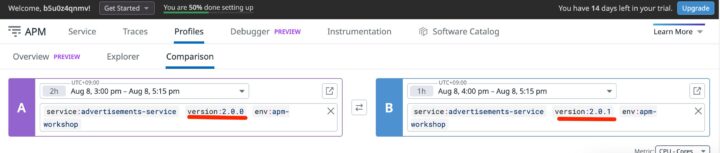
- プロファイル比較(Profile Comparision): 以下の画像にあるように、バージョン2.0.0と2.0.1のように異なるバージョンのパフォーマンスを比較することができます。これにより、新しいバージョンがリリースされた際にパフォーマンスが改善されたか、あるいは悪化していないかを簡単に確認できます。
env:apm-workshopやservice:advertisements-serviceなどのタグでフィルタリングすることで、比較対象を絞り込んでいます。
アプリケーションデバッグの具体的な流れ
セミナーでは、実際にアプリケーションに発生した問題をDatadog APMを使って解決するシナリオを体験しました。
- エラーの発見: サービス一覧からエラーが発生しているサービス(例:
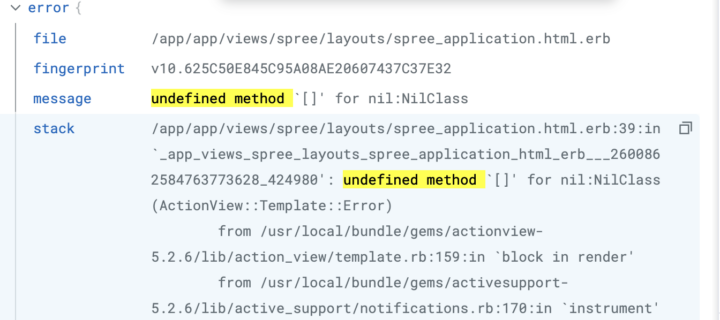
store-frontend)を発見します。 - エラー詳細の確認: 以下にエラー詳細の画像になります。APMのError Trackingから詳細なスタックトレースを確認している様子です。「
undefined method []' for nil:NilClass」というメッセージが表示されており、コードの特定の箇所でエラーが発生していることがわかります。 - ボトルネックの特定: トレースのフレームグラフを確認し、パフォーマンスのボトルネックを特定します。このシナリオでは、
discounts-serviceへのリクエストが遅延の原因でした。 - コード修正と効果測定: 問題のあるコードを修正し、再デプロイします。その後、修正前と後でパフォーマンスが改善されたか(例:
discounts-serviceへのリクエストがなくなった、あるいは処理時間が大幅に短縮された)をAPM上で確認します。 - モニタリング設定: 今後同様の問題が発生しないよう、エラーレートやレイテンシーを監視するモニターを設定します。例えば、エラーレートが0.0%より大きくなった場合にアラートを出すように設定します。
まとめ
Datadog APMは、アプリケーションの問題解決において強力なツールとなります。
- サービス:システム全体の健全性を俯瞰し、問題の発生箇所を特定
- トレース:リクエストの流れを追跡し、パフォーマンスのボトルネックを特定
- プロファイル:コードレベルで詳細な分析を行い、根本原因を特定
これらの機能を組み合わせることで、「アプリが遅い」「エラーが発生している」といった漠然とした事象を、「どのサービスで」「どの処理が」「どのバージョンのコードに起因して」発生しているのか、具体的な答えに結びつけることが可能です。特に、env、service、versionといったタグを適切に設定することで、デバッグやバージョンごとの比較が飛躍的に効率化されます。
セミナーを通じて、これらのAPM機能を実務で適切に活用すれば、調査時間を短縮できることを改めて確信しました。今後は、こうした知見を活かした運用を目指していきたいと考えています。



