
連載の軌跡
〜実践!Google Cloud × Geminiで作るナレッジ自動化〜
| # | テーマ | ひとことで言うと |
|---|---|---|
| 1 | 開発の背景と全体アーキテクチャの展望(統括編) | 課題・理想・企画・結果の共有 |
| 2 | 本記事 | Zendeskチケットを Gemini で要約させ スプレットシート 経由で BigQuery へ流すまでの自動化 |
| 3 | Gemini × Agent Development Kit (ADK) × Slackで作る「人とAIが対話して決める」業務自動化パイプライン | ADK のマルチエージェントと Slack で記事の自動作成 & 人による承認フロー |
| 4 | Gemini × BigQuery × Cloud Runで実現!SlackからGoogleドキュメントを自動生成するナレッジ蓄積パイプラインの構築と24/7運用化 | 承認後の本文自動生成と Cloud Run + Scheduler での 24/7 運用 |
はじめに
弊社では、Zendeskを使用してお客様対応をさせていただいております。
そのためZendeskには膨大なナレッジが眠っておりますが、そのすべてを人間が確認してナレッジ化するのは不可能です。
今回、Google Apps Script(GAS)を使って、Gemini APIでチケット内容を自動要約、さらにBigQueryへリアルタイム連携する「完全自動のナレッジ蓄積パイプライン」を構築しました。その全工程について、具体的な実装コードを用いて解説します。
今回実現した構成
- 抽出
GASがZendesk APIを叩き、解決済み(Solved)以降のチケットを抽出。 - 要約
最新の Gemini 2.5 Flash モデルを使用し、会話履歴から「事象」「解決策」「技術ポイント」を400字程度で構造化要約。 - 蓄積(中間)
Googleスプレッドシートを「中間DB」として活用。人間が目視確認できる状態を維持。 - データ基盤
BigQueryの「外部テーブル」機能を使用。スプレッドシートが更新されるとBigQuery側も即座に反映。
※「運用負荷の最小化」と「将来の拡張性」を重視した、サーバーレスな構成を実現しております。
モデルの選択
- Gemini 2.5 Flashの採用:
大量のチケットを安価かつ高速に処理するため、軽量・高性能なFlashモデルを採用しました。
結果としてテキストとログの要約において、上位モデルに見劣りしない精度で、1,000件超の要約を約1.5時間でスムーズに完走させることができました。
検証の手順説明(具体的な実装)
本システムは、大きく分けて「初期設定」「API連携と要約」「バッチ処理の実行」「BigQuery連携」の4つのステップで構築しました。
1. APIキーと環境変数の準備
まず最初のステップとして、「ZENDESK_API_KEY」、「GEMINI_API_KEY」の取得・有効化を行います。
コード内に直接APIキーを書き込むのはセキュリティ上危険なため、GASの「スクリプトプロパティ」を利用して環境変数を管理します。
function getConfig() {
const prop = PropertiesService.getScriptProperties();
return {
SUBDOMAIN: 'YOUR_SUBDOMAIN',
EMAIL: 'YOUR_EMAIL/token',
BRAND_NAME: 'YOUR_BRAND_NAME',
BATCH_SIZE: 15, // 1回あたりの要約件数
ZENDESK_API_KEY: prop.getProperty('ZENDESK_API_KEY'),
GEMINI_API_KEY: prop.getProperty('GEMINI_API_KEY'),
GEMINI_MODEL: 'gemini-2.5-flash' // ご指定のモデル
};
}
2. Zendeskからの抽出とエラー時の自動リトライ処理
Zendeskから対象のチケットIDを全件取得します。一度に大量に取得しようとすると通信が切断されるリスクがあるため、取得件数を50件に制限。さらに、通信エラー時には3秒待機して最大3回まで自動リトライする堅牢なロジックを組み込み、1,000件超のデータ取得を安定させました。
function fetchAllTicketIds(config) {
const auth = Utilities.base64Encode(config.EMAIL + ':' + config.ZENDESK_API_KEY, Utilities.Charset.UTF_8);
const query = encodeURIComponent(`type:ticket brand:"${config.BRAND_NAME}" status>=solved`);
// ★データが途切れるのを防ぐため、1回に取得する件数を 100 から 50 に減らしました
let url = `https://${config.SUBDOMAIN}.zendesk.com/api/v2/search/export.json?filter[type]=ticket&query=${query}&page[size]=50`;
let results = [];
const options = {
"headers": { "Authorization": "Basic " + auth },
"muteHttpExceptions": true
};
while (url) {
let success = false;
let retryCount = 0;
let data = null;
// ★エラーが起きた場合に最大3回まで自動リトライする仕組み
while (!success && retryCount < 3) {
try {
const res = UrlFetchApp.fetch(url, options);
if (res.getResponseCode() !== 200) {
Logger.log(`APIエラー(${res.getResponseCode()}): ${res.getContentText()}`);
break; // 認証エラー等の場合はリトライループを抜ける
}
data = JSON.parse(res.getContentText());
success = true;
} catch (e) {
retryCount++;
Logger.log(`データの読み込みが途切れました。再試行します (${retryCount}/3回目)...`);
Utilities.sleep(3000); // 3秒待機してリトライ
}
}
// 3回リトライしてもダメだった場合は、取得できた分までで処理を続行
if (!success) {
Logger.log("データの取得が継続できないため、取得できた分までで処理を続行します。");
break;
}
results = results.concat(data.results);
url = (data.meta && data.meta.has_more && data.links) ? data.links.next : null;
Logger.log(`${results.length} 件のIDを取得中...`);
}
return results;
}
3. Geminiによる要約処理
チケット本文とコメント履歴を取得し、Gemini APIへ渡して要約させます。ここでのポイントは、AIへのプロンプトで出力フォーマットを厳格に指定し、ナレッジとして再利用しやすい形に構造化することです。
function processAndAppendTicket(ticketId, sheet, config) {
const auth = Utilities.base64Encode(config.EMAIL + ':' + config.ZENDESK_API_KEY, Utilities.Charset.UTF_8);
const options = { "headers": { "Authorization": "Basic " + auth }, "muteHttpExceptions": true };
try {
// チケット本文とコメントを取得
const tRes = UrlFetchApp.fetch(`https://${config.SUBDOMAIN}.zendesk.com/api/v2/tickets/${ticketId}.json`, options);
const cRes = UrlFetchApp.fetch(`https://${config.SUBDOMAIN}.zendesk.com/api/v2/tickets/${ticketId}/comments.json`, options);
if (tRes.getResponseCode() !== 200) return;
const ticket = JSON.parse(tRes.getContentText()).ticket;
const comments = JSON.parse(cRes.getContentText()).comments;
const conversation = comments.map(c => `[${c.public ? '公開' : '内部'}] ${c.plain_body}`).join("\n\n---\n\n");
// Gemini APIで要約
const summary = callGemini(ticket.subject, conversation, config);
// 重複を気にせず追記(initializeSyncでクリア済みなため)
sheet.appendRow([
ticket.id,
ticket.status,
ticket.subject,
summary,
ticket.updated_at
]);
} catch (e) {
Logger.log(`ID:${ticketId} の処理失敗: ${e.message}`);
}
}
4. バッチ処理による実行
GASの実行時間制限(6分)を回避するため、プロパティストアを活用して進捗を管理。1分ごとのトリガーで15件ずつ処理を再開させる「バッチ処理エンジン」を実装しました。
function mainBatchProcess() {
// 二重起動を防止するためのロック取得
const lock = LockService.getScriptLock();
try {
if (!lock.tryLock(1000)) return; // ロックが取れなければ終了
const config = getConfig();
const prop = PropertiesService.getScriptProperties();
const ticketIdsJson = prop.getProperty('TICKET_IDS');
if (!ticketIdsJson) {
deleteTriggers();
return;
}
const ticketIds = JSON.parse(ticketIdsJson);
let index = parseInt(prop.getProperty('CURRENT_INDEX') || '0', 10);
// 全件終わったかチェック
if (index >= ticketIds.length) {
deleteTriggers();
Logger.log("🎉 全件の要約と書き込みがすべて完了しました!");
return;
}
const ss = SpreadsheetApp.getActiveSpreadsheet();
const sheet = ss.getSheetByName("要約済みチケット");
const end = Math.min(index + config.BATCH_SIZE, ticketIds.length);
Logger.log(`${index + 1}件目から${end}件目を処理中... (残り ${ticketIds.length - end}件)`);
// 15件分ループ
for (let i = index; i < end; i++) {
processAndAppendTicket(ticketIds[i], sheet, config);
}
// 次の開始位置を保存
prop.setProperty('CURRENT_INDEX', end.toString());
Logger.log("現在のバッチ完了。次のトリガー待機中...");
} catch (e) {
Logger.log("エラー発生: " + e.message);
} finally {
lock.releaseLock();
}
}
5. BigQueryの外部テーブル設定(連携)
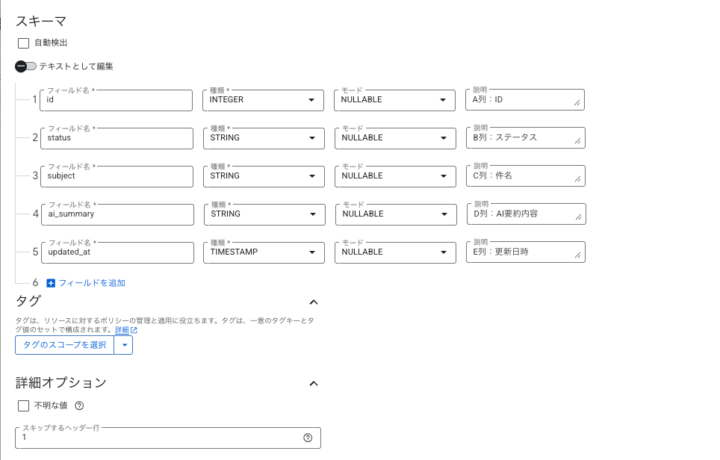
- BigQueryコンソールから「テーブルを作成」を選択。
- ソースを「ドライブ」にし、スプレッドシートのURIを指定。
- スキーマは手動で以下のように定義します。(自動検出による日本語見出しの文字化けを防ぐため)
id(INTEGER)status(STRING)subject(STRING)ai_summary(STRING)updated_at(TIMESTAMP)
- 詳細オプションの「スキップするヘッダー行」に
1を指定して作成。
※スプレッドシートが更新されると、BigQuery側もリアルタイムで最新状態になるよう設定します。
つまずいたところ
構築過程で直面した課題と解決策をご紹介します。
- パースエラーと通信の切断:
一度に100件のチケットを取得しようとすると、レスポンスが巨大すぎてZendesk側から通信を切断される現象が発生しました。取得件数を1回50件に絞り、エラー時には「3秒待機して最大3回まで自動リトライする」処理を加えることで耐障害性を高めました。 - ステータスの定義(SolvedとClosedの違い):
Zendeskの仕様上、対応完了直後は「Solved(解決済み)」となり、数日後にシステムで「Closed(終了)」に移行します。status:closedだけでは対応直後のチケットがヒットしなかったため、検索クエリをstatus>=solvedに広げることで、リアルタイムな反映を実現しました。
まとめ
GASとGeminiを組み合わせることで、これまで「ただ溜まっていただけのログ」が「いつでも検索・分析可能なナレッジ資産」に変わりました。
また、自動的にデータが更新される仕組みになっているため、日々の運用保守を心配する必要もありません。
BigQueryにデータが入ったことで、今後はLooker Studioでのダッシュボード化や、社内RAG(検索拡張生成)チャットボットの回答ソースとしての活用など、幅広い用途での使用が可能になりました。
生成AI×データ基盤の構築は、連携の工夫次第で圧倒的な業務効率化を生み出せるため皆様もぜひ試してみてください。




