
こんにちは、セキュリティエンジニアの田所です。
現地参加している AWS Summit Japan 2026 からセッションの模様をお届けします。
セッションについて
AIM201 本番展開を見据えて:エージェンティック AI に対する実践的アプローチ
AI 実証実験の46%は本番に届かず消滅する – 同じ経験をされた方も多いのではないでしょうか。本セッションでは、プロトタイプの壁を突破するために必要な4つの柱「運用」「データ」「信頼性」「堅牢性」を、これまで AWS が多くのお客様支援から得たナレッジをもとに体系的に解説します。既存サービスの活用判断から、オブザーバビリティ、データ整備、セキュリティ設計、評価の自動化まで、エージェントの価値を最大化するための近道をお伝えします。
ブレイクアウトセッションとして、AI エージェントを「動くもの」から「本番で使えるもの」へ引き上げるための勘所を、AWS の支援知見をもとに整理する内容でした。

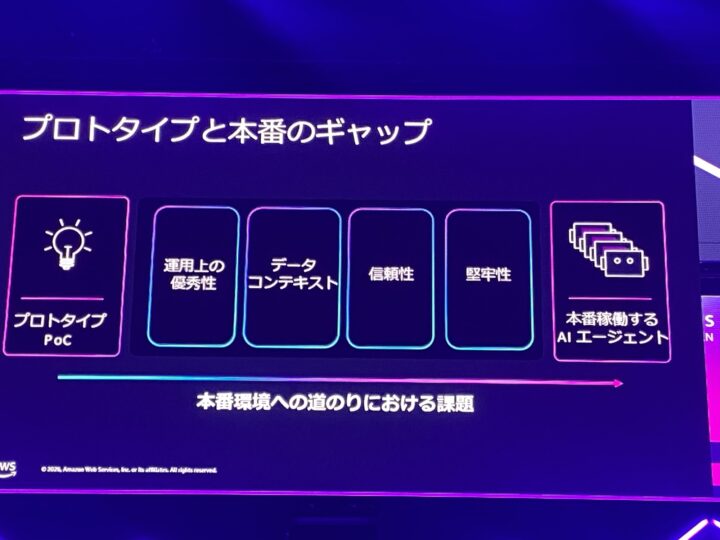
1. プロトタイプと本番のギャップ
冒頭で示されたのは、なかなかにショッキングな数字でした。
AI の実証実験のうち、実に46%が本番に届かないまま打ち切られているそうです。

「大体動く」プロトタイプと、本番運用の間には大きなギャップがあります。
本番では、スケール・セキュリティ・コンプライアンス・コストといった、プロトタイプでは後回しにしていた要件が一気に求められるからですね。
このギャップを埋めるために満たすべき要素として、セッションでは「運用上の優秀性」「データとコンテキスト」「信頼性」「堅牢性」という4つの柱が提示されました。
進め方としてまず勧められていたのは、いきなり自前で作るのではなく、既存のエージェント製品で要件を満たせないかを検討することです。
そのうえで、独自のロジック・専門知識・固有のコンプライアンス要件など、既存製品に当てはまらない部分が出てきたときに初めて自分たちで作る、という順序です。
AWS はそのためのプラットフォームやフレームワーク(Amazon Bedrock AgentCore、Strands Agents など)も提供しています。

残り2本の柱:データと信頼性
本記事では特に「運用」と「堅牢性」を掘り下げますが、残る2本の柱にも簡単に触れておきます。
ひとつは データとコンテキスト です。
「エージェントの失敗は、その多くがデータの失敗である」という指摘が印象的でした。
生データをそのまま渡しても、文脈を理解できない新入社員が初日から戦力にならないのと同じで、ナレッジへの変換が必要になります。
RAG は導入して終わりではなく品質を維持・向上させる運用が要り、短期・長期の記憶を保持するメモリ(AgentCore Memory)も鍵になります。

もうひとつは 信頼性 です。
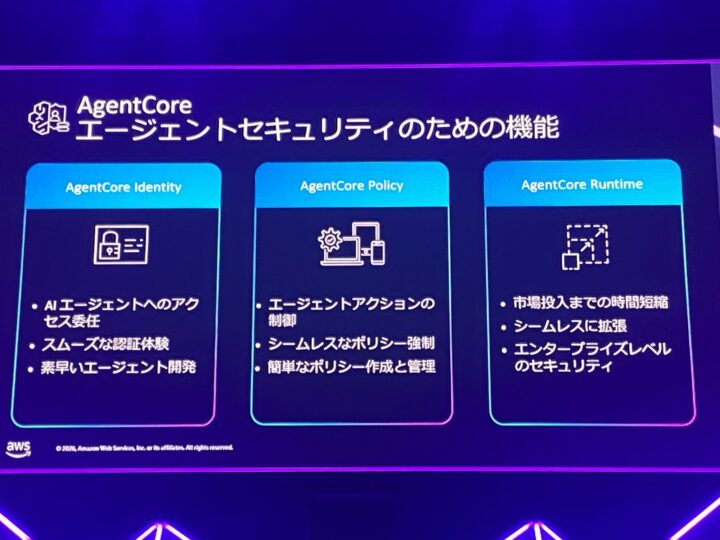
スケールするほど、データやツールへのアクセスをきめ細かく制御する必要が出てきます。
事故が起きてから対処するのではなく、構造的に事故が起こらない状態を目指すという考え方のもと、AgentCore は Identity・Policy・Runtime といったセキュリティ機能を提供しています。
なお、応答内容を精査する Guardrails に対し、Policy は呼び出し時に強制をかける、という棲み分けも紹介されていました。
セキュリティは任意ではなく必須、という言葉が刺さりますね。
2. 運用上の優秀性
ここからは1本目の柱、運用上の優秀性です。

本番のスケールに耐えられるか。
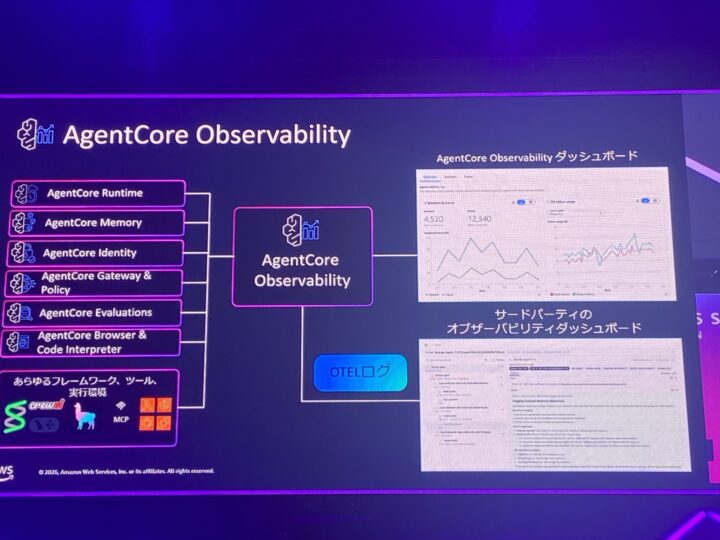
その健全性を評価する土台になるのがオブザーバビリティです。
ただ、AI エージェントは非決定的に動き、LLM やツールの呼び出しが複数ステップにまたがるため、トレースが断片化しやすいという特性があります。
さらに、その挙動を人間が評価していくと、時間的なボトルネックになりがちです。
- オブザーバビリティは後付けではなく、はじめから設定しておく
- AgentCore では OpenTelemetry 形式のトレースを自動発行
- AgentCore Observability でエンドツーエンドの解析が可能
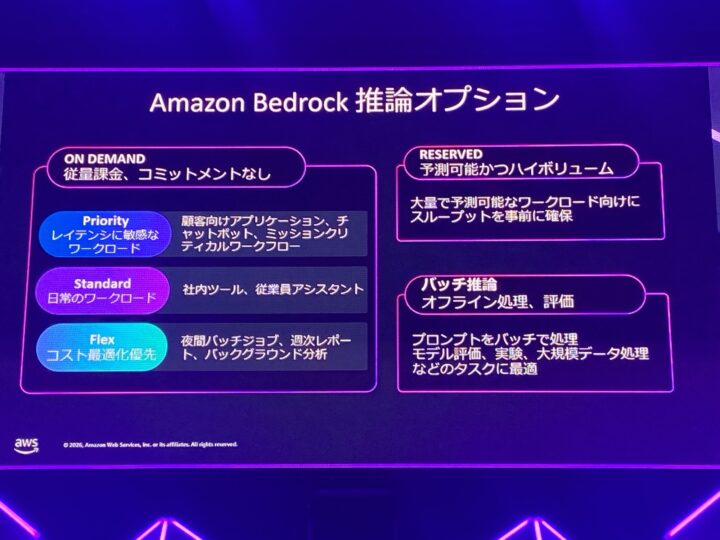
運用では、コスト・レイテンシ・精度の3つを適切にトレードオフすることも重要です。
Amazon Bedrock には複数の推論オプションが用意されており、ワークロードの要件に応じて使い分けることで、この3要素のバランスを調整できます。
加えて、組織内に散らばるエージェントのスキルや MCP を可視化・一元管理する AWS Agent Registry も紹介され、再利用性とガバナンスの観点が補強されていました。
3. 堅牢性
最後は堅牢性、つまりエージェントが一貫して正しく動作することを証明できるか、です。

ここでの中心的なメッセージは「可能な限りコードで解決する」でした。
コードは速く、安く、決定論的です。
エージェントの役割はコードの代替ではなくオーケストレーションであり、推論が必要なタスクに限定して使います。
コードで解決できることにわざわざツール呼び出しを使わない、という割り切りです。

具体例として、ツール呼び出しに頼らずメタデータで処理することで 25 % 高速化できたケースが示されていました。
なんでもかんでも LLM に任せるのが最適解ではない、というのは大きなポイントですね。

そして、ブレが許容範囲に収まっているかを判断するための評価も欠かせません。
モデル選定や品質・コスト・レイテンシのバランスを、感覚ではなくデータで判断し、初期からビジネスメトリクスやベンチマークを確立しておくことが勧められていました。
評価を手作業で回し続けるのは現実的でないほどの時間と労力がかかります。
そこで、プログラム・LLM・人間で評価を分担し、ツール(LLM-as-a-Judge や AgentCore Evaluations など)を使いながら継続的なプロセスとして組み込むことが提案されていました。
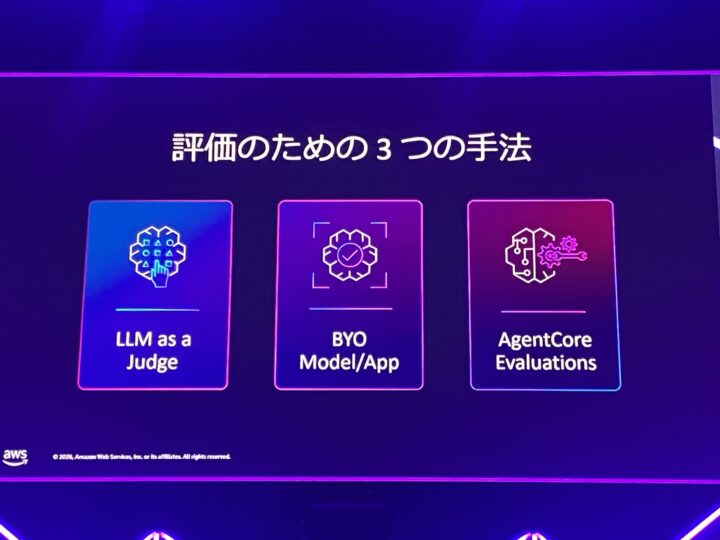
まとめ
エージェンティック AI を本番に届けるための4つの柱「運用・データ・信頼性・堅牢性」を見てきました。
本番化には越えるべき壁が4つもあるわけですが、裏を返せば、AWS にはそれぞれに対応するビルディングブロックが揃っているということでもあります。
サービスを要件に応じて使い分けることで、現実的な AI エージェント運用に近づけそうだと感じました。
個人的には、エージェントの利用を「推論が必要なタスクに限定する」という使い分けが印象的でした。
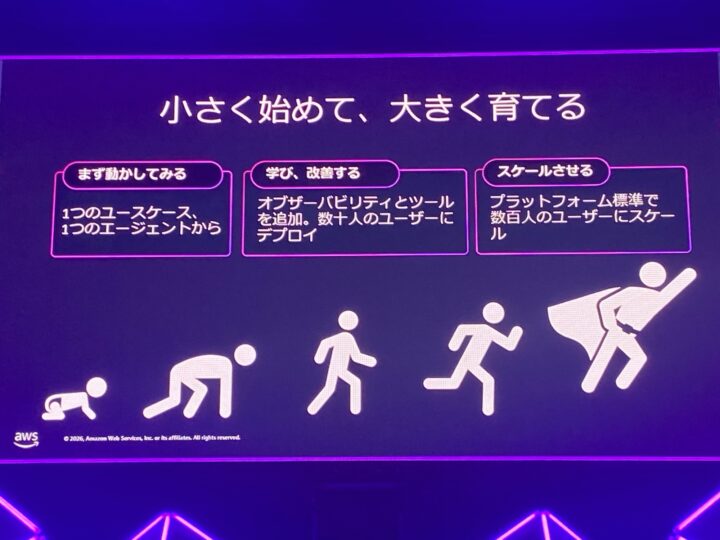
そして締めくくりは「小さく始めて、大きく育てる」。
考慮すべき要素はたくさんあるものの、まずは最初の一歩を小さく踏み出すことが大切だというメッセージでした。
バランス良く AI エージェントを育てて本番に持っていきたいですね。
おしまい
![[AWS Summit Sydney 2026] エージェンティックな世界における先進的なチーム構造](https://iret.media/wp-content/uploads/2026/06/5be593864f50750d0997386cb691de4f-220x123.jpg)

