
ナスです。
またまた Elasticsearch の話です。今回は Amazon Elasticsearch Service にデータが保存されなくなった話です。Amazon 特有の話なのかそうでないのかわかりませんが、実際に起こったので書いておきます。
気がついたら何も保存されていなかった
初期構築を終えて数日運用した後に Elasticsearch Service の様子を見てみたら、Indices タブにあるべきインデックス名が全く出ていませんでした。クラスタ数は 1 で設定してあるので、ステータスは常に Yellow だったので、これが原因とは思えない。かといってストレージの空きはわりとある。って状況で、最初はなかなか原因がわかりませんでした。
Monitoring タブで見れるグラフがなんかおかしい
Elasticsearch Service のグラフを見ていると、なんか気になる形を発見。Write IOPS が 0 だ…
この状況を基にいろいろ調べたら、このドキュメントが出てきました。
AWS サービスエラー処理 – Amazon Elasticsearch Service
なんかメモリくさいな… と思って、CloudWatch で Write IOPS と JVMMemoryPressure のメトリクスを見るとこうなってました。
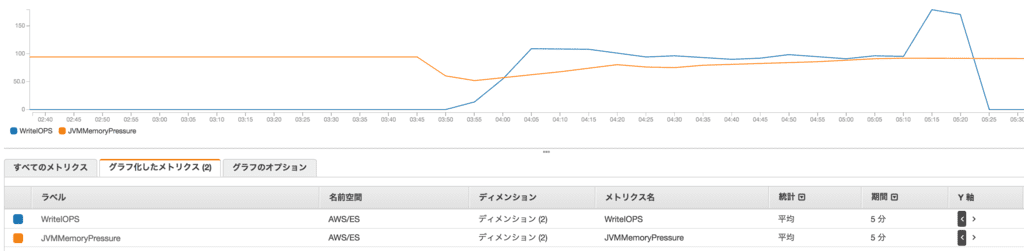
JVMMemoryPressure が92,93% あたりを超えると Write IOPS が 0 になり、JVMMemoryPressure が下がると同時に Write IOPS も増えていました。
原因は?
ドキュメントには、
t2 インスタンスでは、[JVMMemoryPressure] メトリクスが 92% を超えた場合、クラスターが赤の状態になるのを防ぐため、Amazon ES はすべての書き込みオペレーションをブロックすることによる保護メカニズムをトリガーします。
と書いてありますが、この環境ではデフォルトの m4.large を使っていますので、どうやら t2 だけに限らないっぽいです。もしかしたらデフォルトのインスタンスサイズ& t2 がこれに引っかかるという可能性もあります。(他のインスタンスタイプでは試せてないのでわかりません
どう対処したのか?
今回は、データが多すぎてメモリも多く使われたのだと仮定して、先日書いた↓の対応を行いました。
nasrinjp1.hatenablog.com
不要なデータを消した直後から、JVMMemoryPressure も下がり、無事に Write IOPS もガンガン上がり始め、ようやくデータが保存されていきました。
他には、クラスタ数を増やす、インスタンスのサイズをあげる、等の選択肢もありますが、不要なデータがたまりすぎている状況なら素直に不要データを削除するのがいいと思います。後は、JVM 関連のパラメータ調整くらいですかね。
Elasticsearch Service はマネージドサービスですが、ちゃんと使い方や特性を理解した上で運用しないと痛い目にあうなと思いました。マネージドサービス=何も気にしなくても運用できる、ではないことを再認識させられました。
元記事はこちら
「Amazon Elasticsearch Service でデータが保存されなくなった話 [cloudpack OSAKA blog]」
