
cloudpack の 自称 Sensu芸人 の かっぱこと 川原 洋平(@inokara)です。
はじめに
Sensu をプロダクション環境で運用しようとすると、その中核となる RabbitMQ はどう見ても SPOF になるんでは?という疑問から HA Proxy や Route 53 を使って HA 構成がとれないか検証してみた。
構成
下記のように Sensu クライアント及び Sensu サーバーが Route 53 に定義されたドメイン名に対してアクセスするような構成を構築して検証する。
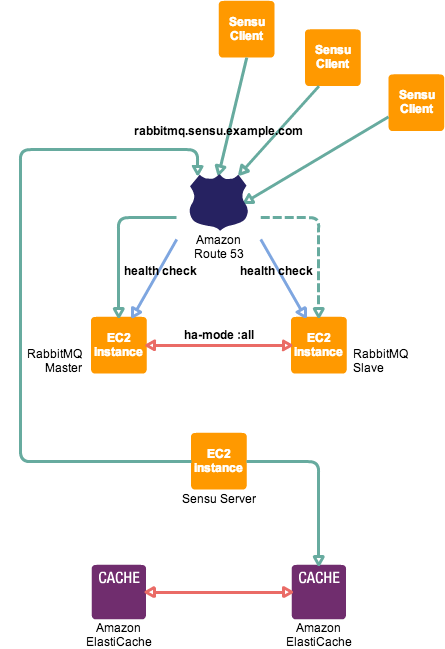
尚、今回は ElastiCache for Redis は用いずに Sensu サーバー上に構築した Redis サーバーを利用した。
Route53 による Health Check の設定
参考
設定の条件
- RabbitMQ ノードのグローバル IP を sensu-rabbitmq.test.hoge.com の A レコードに追加
- TTL は 60 秒で設定
- RabbitMQ ノードのグローバル IP をヘルスチェックに追加
- ヘルスチェックは “RequestInterval”: 10, でしきい値は “FailureThreshold”: 2 を設定
設定の確認
一応、上記の設定条件を aws cli にて確認。
aws route53 list-resource-record-sets
{
"HealthCheckId": "xxxxxxxx-xxxxxxxxx-xxxxx-xxxxxxx1",
"Name": "sensu-rabbitmq.test.example.com.",
"Type": "A",
"Failover": "PRIMARY",
"ResourceRecords": [
{
"Value": "xxx.xxx.xxx.xx1"
}
],
"TTL": 60,
"SetIdentifier": "sensu-rabbitmq-Primary"
},
{
"HealthCheckId": "xxxxxxxx-xxxxxxxxx-xxxxx-xxxxxxx2",
"Name": "sensu-rabbitmq.test.example.com.",
"Type": "A",
"Failover": "SECONDARY",
"ResourceRecords": [
{
"Value": "xxx.xxx.xxx.xx2"
}
],
"TTL": 60,
"SetIdentifier": "sensu-rabbitmq-Secondary"
}
aws route53 list-health-checks
{
"HealthChecks": [
{
"HealthCheckConfig": {
"Type": "TCP",
"RequestInterval": 10,
"IPAddress": "xxx.xxx.xxx.xx1",
"Port": 5672,
"FailureThreshold": 2
},
"CallerReference": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx1",
"Id": "zzzzzzzz-zzzz-zzzz-zzzz-zzzzzzzzzzz1"
},
{
"HealthCheckConfig": {
"Type": "TCP",
"RequestInterval": 10,
"IPAddress": "xxx.xxx.xxx.xx2",
"Port": 5672,
"FailureThreshold": 2
},
"CallerReference": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx2",
"Id": "zzzzzzzz-zzzz-zzzz-zzzz-zzzzzzzzzzz2"
}
]
}
実際のところどう?
検証
HA Proxy と同じ内容の検証を行う。
パターン
- RabbitMQ クラスタの 1 台が停止した(rabbitmqctl stop_app にて再現)
- RabbitMQ クラスタの 2 台が停止した(rabbitmqctl stop_app にて再現)後で 1 台復旧させた
- RabbitMQ の vhost を意図的に削除
- 登録したドメインの ttl を 10 秒にする
確認手順
- Sensu Dashboard にて目視による監視継続の確認
- /var/log/sensu/sensu-server.log の監視
- /var/log/sensu/sensu-client.log の監視
上記のlogを監視して RabbitMQ への接続エラーが発生しないかを目視にて監視。また、合わせて Redis 内の history データベースの目視による監視も行った。
検証メモ(パターン 1)
結果
- 監視は継続された
- Primary に定義されているノードの RabbitMQ を停止したところ、HA Proxy 同様に “reconnecting to rabbitmq” のログが 一度だけ 発生した
- Secondary への切り替えは Route 53 の Health Check の定義に準ずると思われる(ログ見たい!)が RabbitMQ クライアント(Sensu クライアントや Sensu サーバー)に関しては、レコード設定の ttl に準ずる挙動となる
- ということで 60 秒間は RabbitMQ と接続が出来ない状態となる
- HA Proxy 利用時 “reconnecting to rabbitmq” が出力され続けるのは HA Proxy の 5672 ポートは正常に Listen している為
検証メモ(パターン 2)
結果
- 双方の RabbitMQ を stop_app した際には RabbitMQ への reconnecting が 一度だけ 表示され監視のログが流れなくなってしまう
- 1 ノードを RabbitMQ を start_app すると監視が再開された
検証メモ(パターン 3)
- RabbitMQ との接続を切らない限りは監視は継続された
- 但し、RabbitMQ との接続をリセットしたり、新しい RabbitMQ クライアント(Sensu クライアント、サーバー)は以下のようなログを吐いて落ちる
{"timestamp":"2014-06-04T09:05:27.563115+0000","level":"warn","message":"stopping reactor"}
検証メモ(パターン 4)
結果
- フェールオーバーの時間が短縮された(30 秒)
- ttl の 10 秒 + Health Check の 10 秒 × 2 となる
考察
Sensu において RabbitMQ の HA を Route 53 で担保する使うメリット
- RabbitMQ が HA 構成で稼働することになるので Sensu による監視の信頼性が向上する
- RabbitMQ のキューは enqueue や dequeue は自動で同期されるので監視キューのロストはや重複等は無いと思われる
- AWS のサービスを利用することで管理しなければいけないコンポーネントを減らすことが出来る
- 一応、Route 53 自体が単一の障害ポイントにはならない
Route53 を使うデメリット
- あくまでも DNS なので ttl の設定等に限界があるので収束に一定時間を要する
memo
- Health Check の挙動を調べる
元記事は、こちら