
cloudpack の 自称 Sensu芸人 の かっぱこと 川原 洋平(@inokara)です。
はじめに
前回 CloudTrail が東京リージョンで利用出来るようになったので簡単に触ってみましたが、実際にログを眺めてみて可視化出来ないかひたすら悩んでみました。また、せっかくログが出力されたことが SNS → SQS に通知が飛ぶのでそのあたりを利用してログ収集の自動化もやってみたいと思います。尚、以下は実験的な要素をかなり含んでおり現在も安定稼働出来ていないので参考程度に…。
参考
今回の構築、設定に伴い、以下のサイトやドキュメントを参考にさせて頂きました。
- exec_filter Output Plugin
- fluentd / lib / fluent / plugin / out_exec_filter.rb
- fluentd out_exec_filter を使ってみた
- td-agent(fluentd)でtagを色々してみたメモ②-out_exec_filterでタグをもっといろいろしてみる
- Norikra+FluentdでDoS攻撃をブロックする仕組みを作ってみた
有難うございます。
構成
図
以下のようなイメージで構築します。
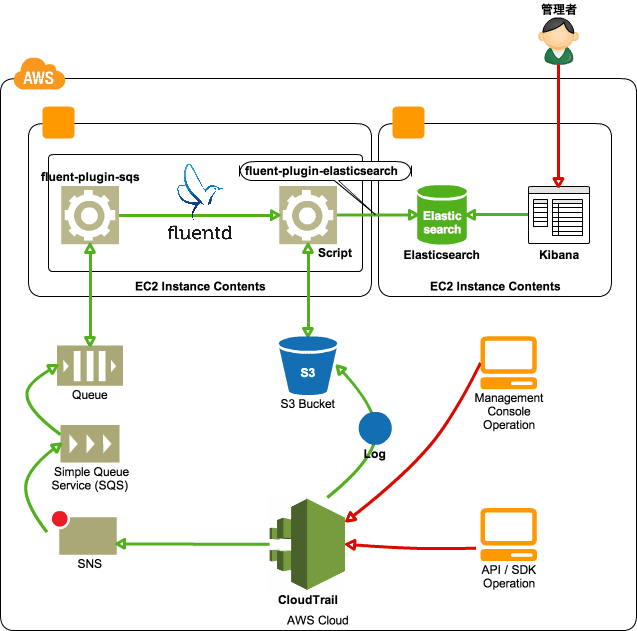
ポイント、処理の流れ
処理の流れ
- CloudTrail がログを出力したタイミングで SNS に通知を飛ばし、SNS の Subscription 先として SQS のキューを指定しているのでログが保存されている S3 のパス等の情報がキューに届く
- fluent-plugin-sqs が定期的に SQS のキューを確認してキューにメッセージががあれば自作スクリプト(これがまたショボイ)を使って S3 からログを取得する
- スクリプトは S3 に保存されているログを展開してログに書きだされるので fluent-plugin-elasticsearch を利用して Elasticsearch に放り込む
ポイント
- ログのルーティングは極力 fluentd のみで行うようにする
- 出来るだけ自作ツールに頼らない(コードの行数を減らす)→ちゃんと作れればその類ではないけど…
使うもの
今回の CloudTrail からのログ収集と可視化を行うにあたって以下のようなツールを利用します。
全体を通して
- ログ収集基盤の決定版、fluentd
ログ可視化
- fluent-plugin-elasticsearch
- みんな大好き、僕も大好き Kibana と Elasticsearch
ログ収集の自動化
- Amazon SQS
- fluent-plugin-sqs
- fluentd の out_exec_filter
- out_exec_filter から利用するスクリプト(自作)
キモはやっぱり out_exec_filter で利用するスクリプトの出来にかかっていると思うのですが…これがナカナカのナカナカでして安定しておりません…orz。
各ツールのインストール
については割愛。特に難しいことはないかと思いますので各種ツールのドキュメント、又は数多の検索結果を参考にツールのインストールを行いましょう。
スクリプト
エラーハンドリング等も甘く、人に見せられるものでは無いのですが一応こちらに張っておきます。ご指摘やこんな風にしたら良くなるよとかご意見お待ちしております!
fluentd の設定
fluentd の設定は下記のような設定です。
<source>
type sqs
aws_key_id AKxxxxxxxxxxxxxxxxxx
aws_sec_key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
sqs_url https://sqs.ap-northeast-1.amazonaws.com/123456789012/xxxxxxxxxxxx
sqs_endpoint sqs.ap-northeast-1.amazonaws.com
receive_interval 60
tag cloudtrail
</source>
<match cloudtrail>
type copy
<store>
type file
path /tmp/sqs
</store>
<store>
type exec_filter
command /opt/cloudtrail/parse-cloudtrail-log.rb
in_format json
out_format json
buffer_type file
buffer_path /tmp/script_buffer
tag cloudtrail.parsed.last
</store>
</match>
#<match cloudtrail.parsed>
# type json_nest2flat
# tag cloudtrail.parsed.last
# json_keys Records
#</match>
<match cloudtrail.parsed.last>
type copy
<store>
type file
path /tmp/for_debug
</store>
<store>
type elasticsearch
include_tag_key true
tag_key @log_name
host xxx.xxx.xxx.xxx
port 9200
logstash_format true
index_name cloudtrail
flush_interval 10s
</store>
</match>
/opt/cloudtrail/parse-cloudtrail-log.rb を out_exec_filter 経由で実行しています。
出来たもの
自動化の部分に関しては冒頭の図を見てイメージして戴くとして可視化に関しては以下のように Elasticsearch に入ったレコードを Kibana から拾うことが出来ている。
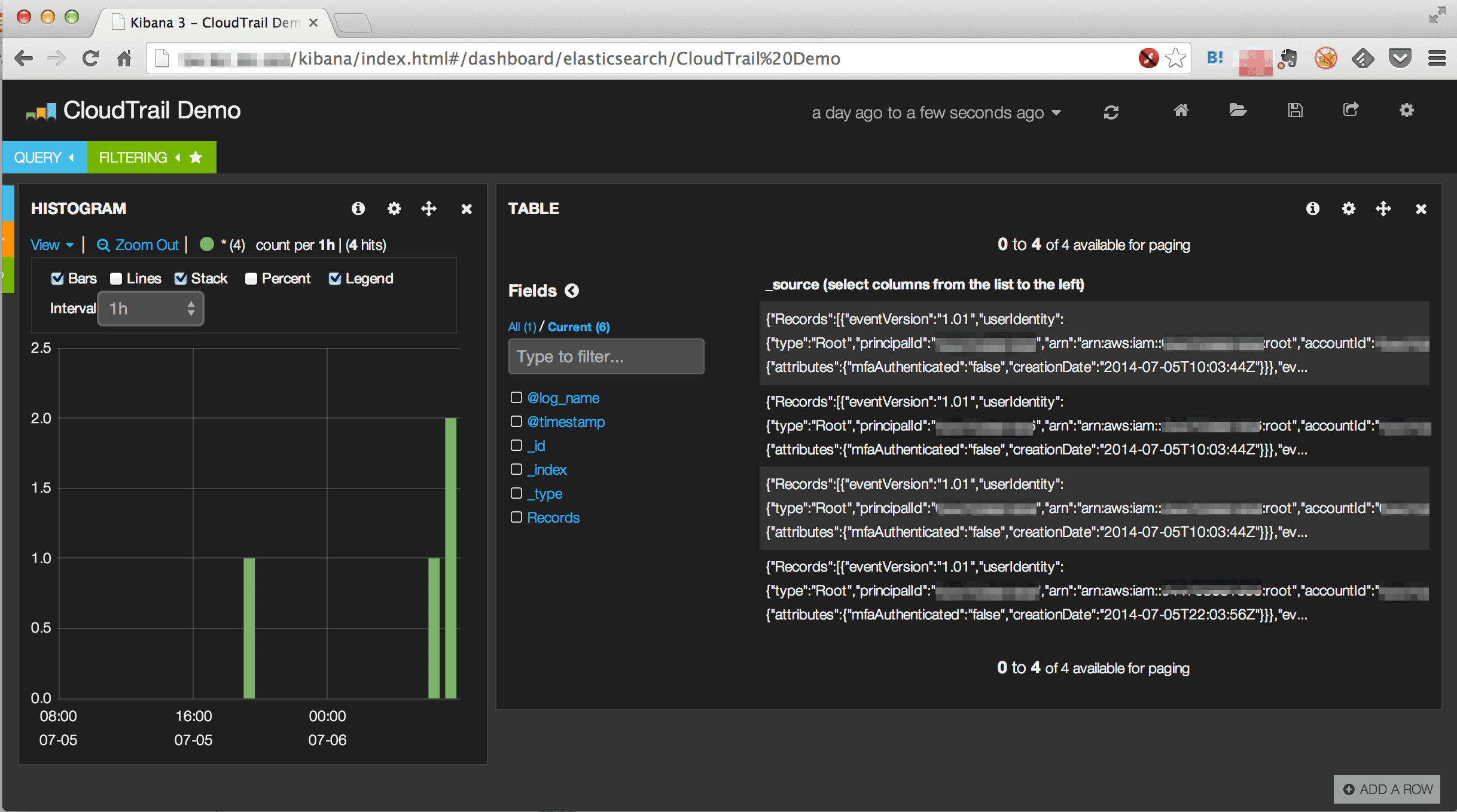
但し…
この可視化は以下の点について不完全な状態です。
- S3 から取得して展開したレコードをそのまま突っ込んでいるだけ
- 実は一つのレコードには複数の時系列ログが記録されている
- 本来であれば複数の時系列ログは個々のレコードとして Elastisearch に登録されるべき
現在…
上記の不完全な状態を解決するべく改良、調査中です。一応、下図のように一つに圧縮された複数のログを展開して一つのレコード毎に Elasticsearch に登録は出来ているようですが、out_exec_filter で動いているスクリプトが落ちてしまう(スクリプトを大幅に見直す必要があるようです)ので引き続き調査を行っている段階です…orz。
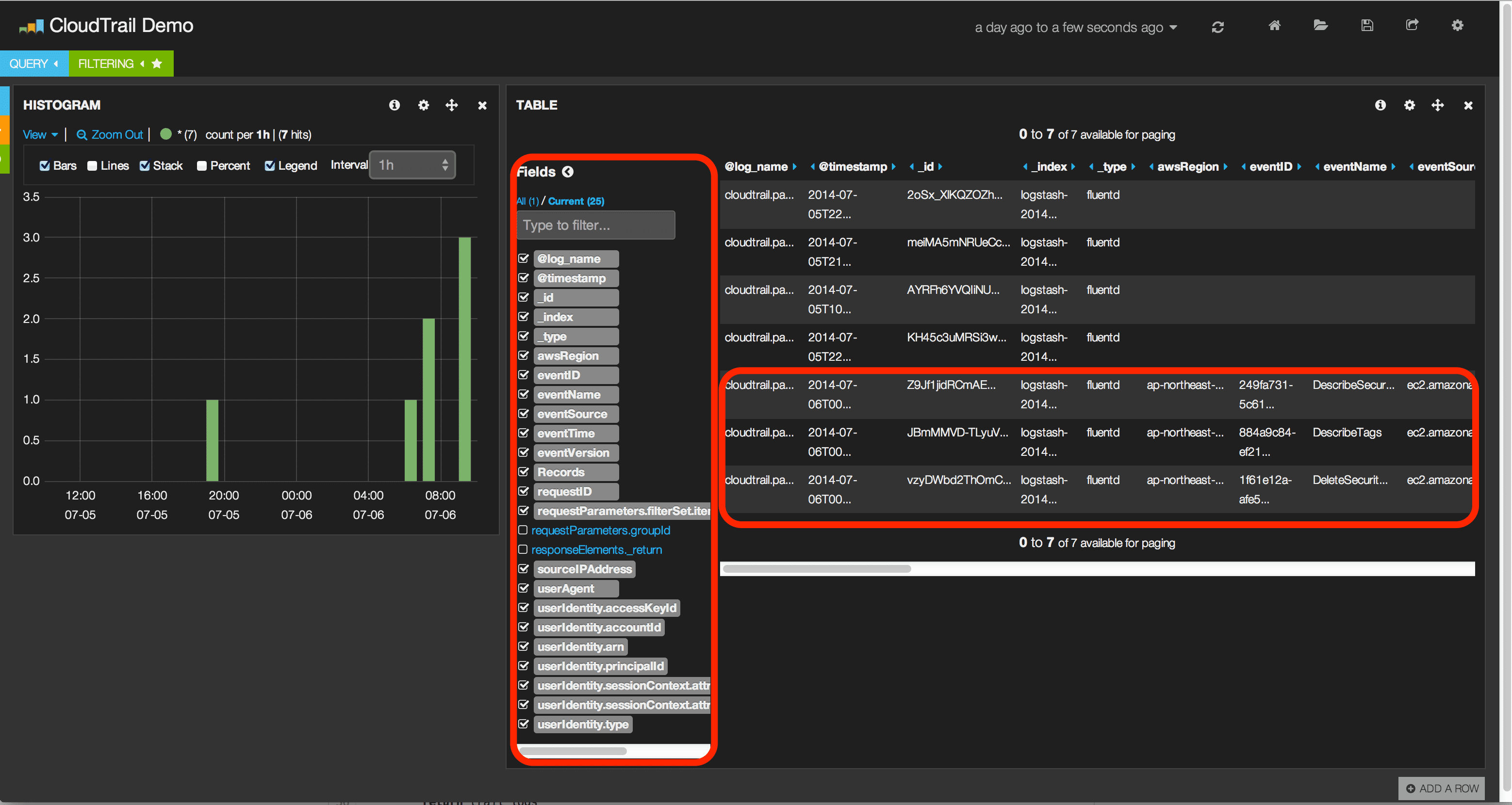
ちょっと進化
以下のように時系列毎にログが取得出来るようになったのでイベント毎、ユーザーエージェント毎にカウントが出来るようになりました。
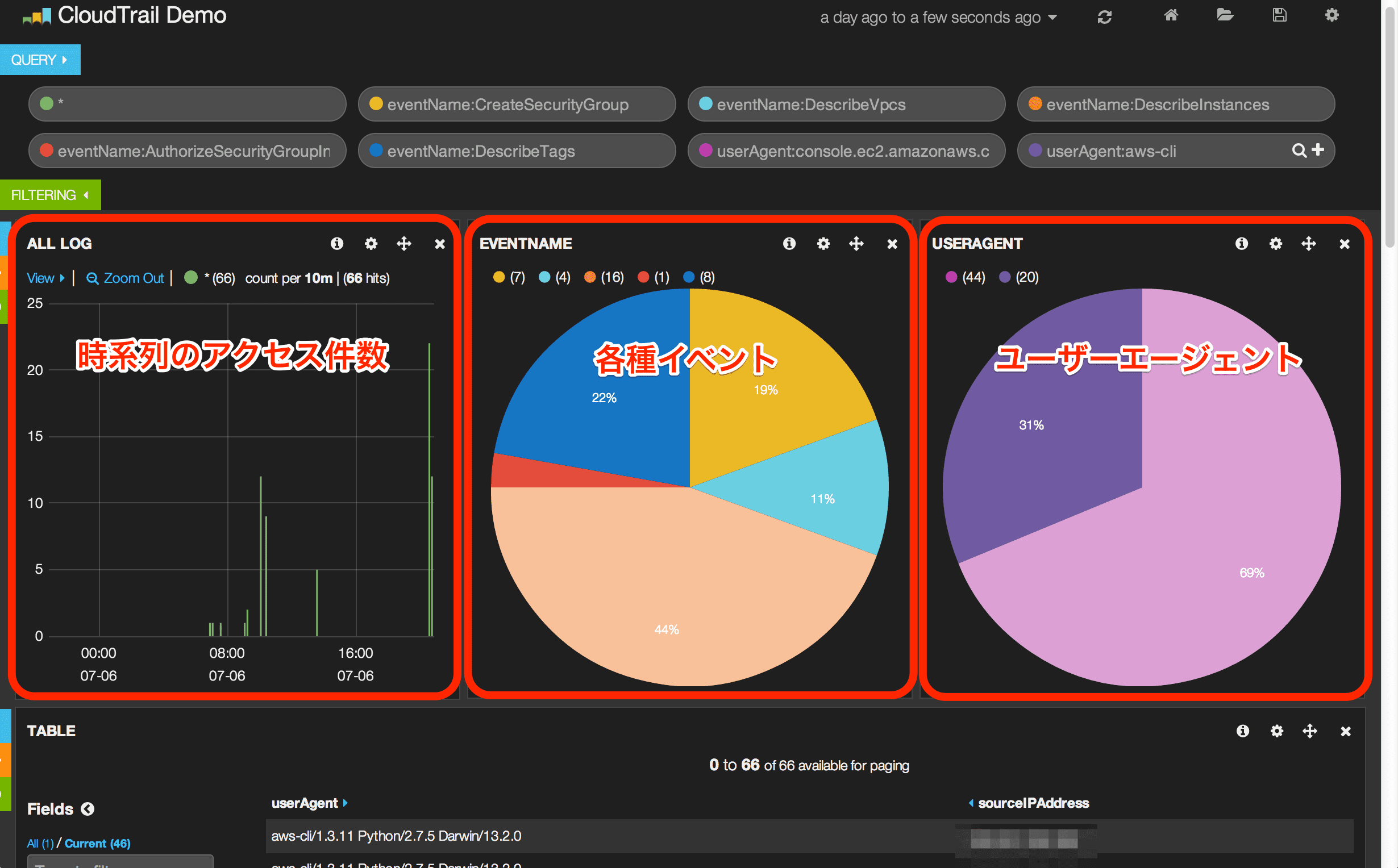
スクリプトの改修は引き続き…。
引き続き
残課題
- 自作スクリプトの改修(エラーハンドリング、ロギングの実装)
元記事は、こちら