
※プレゼントキャンペーンは終了しました。ご応募ありがとうございました。
クラウドインテグレーション事業部、MSP開発セクションの高橋修一です。
iretスペシャリストによるブログリレーキャンペーン「iretスペシャリストからの挑戦状」の第3弾ということで、私からは「レガシーシステムのリプレイス」について紹介します。
社内に 「受信メールをフィルタして各種外部サービスに通知・登録するシステムや設定」 が複数存在し、またそれが古くなっていました。
私の方でそれらを新しいシステムでリプレイスし、しばらく運用しています。
今回はその仕様・アーキテクチャ・運用について選定と振り返りを共有しますので、何か1つでも参考になる部分があれば幸いです!
自己紹介
私の所属するMSP開発という部署では、社内業務の効率化・フォロー・自動化を担うサービスの開発と運用をしています。
外部サービスの組み合わせや使い方で解決することもあります。
元々は組み込みの開発エンジニアで、C++でガラケーやカーナビを作っていました。
アイレットに入ってからはAWS、Google Cloud、Pythonをよく触ります。スペシャリスト認定のインタビュー記事はこちらです。趣味は筋トレですがサボり気味です!
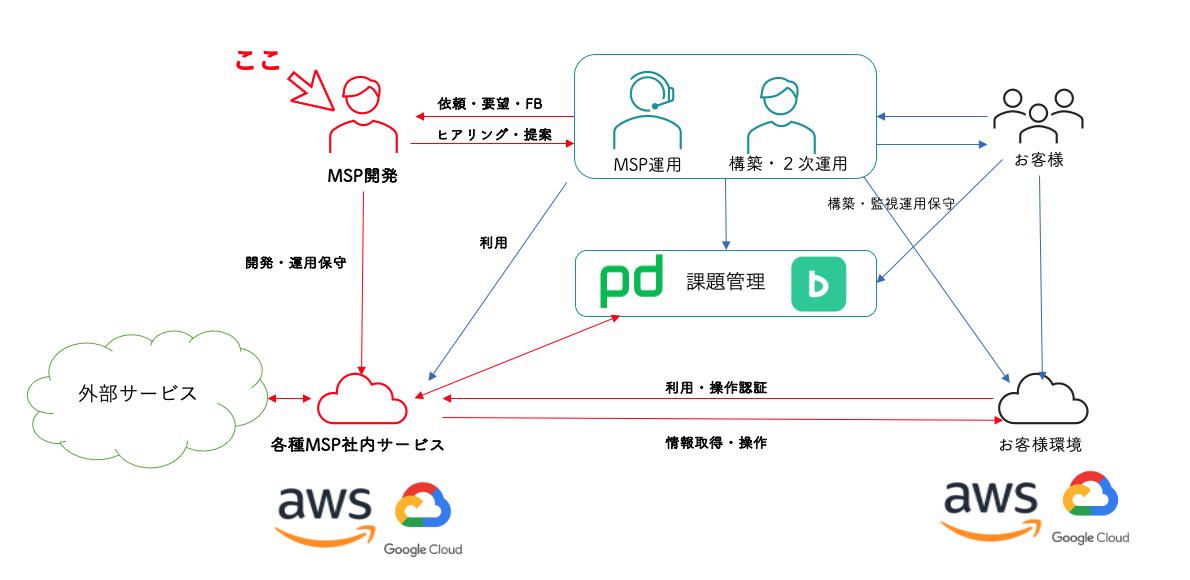
今回ターゲットとなるシステム・設定
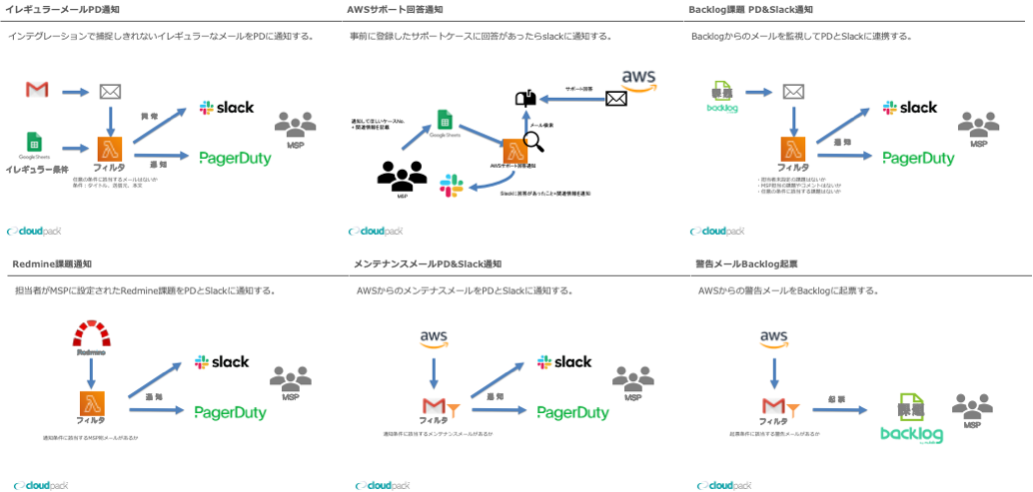
乱立していた 「受信メールをフィルタして各種外部サービスに通知・登録するシステムや設定」 ですが、その対象や仕組みは様々です。
対象はAWSから届くメールだったり、その他のサービスから届くメールだったり。仕組みはSESで受けてLambdaのコードでフィルタを実装しているもの、Gmailの転送フィルタを使っているもの、検索APIを定期実行しているもの。条件の詳細をスプレッドシートで定義更新しているものなど。MSP開発セクションで開発したものもあれば、他の部署から引き継いだものもあります。
システムや設定の例(簡易イメージ)
課題
以下の課題を抱えており、保守の負荷が大きくなってきていました。
- 仕組みがそれぞれ異なり保守するときのオーバーヘッドが高くつく
- フィルタ条件や通知内容がほとんどハードコーディングされていて更新にはデプロイ/リリース作業が必要
-デプロイの仕方も様々 - テストや検証環境が用意されていないものもある
- 仕様の負債も溜まってきている
-経緯のはっきりしない特殊なフィルタ条件が存在する
-もう使われていなさそうな仕組みもある - 使われている技術が古い
-近々EOLを迎えるバージョンが使われている
そもそもメールをインプットにするのではなく可能なものはWebhookやAPIなどに置き換えたいところですが、メールでしか受け取れない情報や都合があるものが残っています。
ということで、これらの仕組みを1つのシステムに統合してリプレイスすることにしました。
余談
別案として、Gmailのフィルタ+転送機能やZapierをフル活用する形に寄せ切って、それを安全に運用する仕組みを構築する筋も検討してみました。結果としては、要件の複雑さ、クォータ(割り当て)、拡張性などを考慮し、採用しませんでした。
仕様
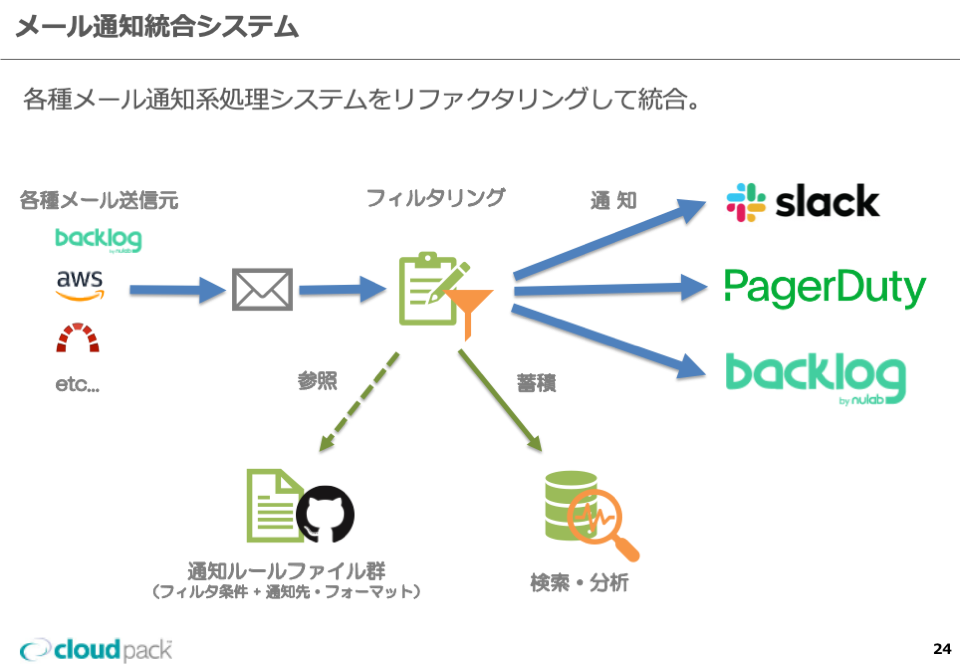
- 旧システムと新システムで仕様(フィルタ条件や通知内容)は原則差異を出さない方針
-仕様の整理は旧システム側で行ってから開発中の新システムにも適用
-廃止してしまえそうなものは廃止で調整 - フィルタ条件+通知内容は原則ルールファイル(JSON)で記述し、Git管理
-ただし複雑な条件を持つものは、モジュールを分離してコード上で実装 - 受信したメールと処理結果はクエリ可能な形で貯めておき、あとから検索・分析可能にする
振り返り
基本的にフィルタ条件や通知内容は変更しない。
今回のような大きく手を入れるタイミングは仕様の負債も返上するチャンスです。ただリスクを極力避けたかったので新旧の通知仕様は同じものとし、突き合わせて比較する並走期間を設けました。バグや考慮漏れを並走期間で検出し潰せたので、この選択にしてよかったと思っています。
仕様の整理は旧システム側で行ってから新システムにも適用。
いくつかの特殊な条件や処理は経緯を追って関係する担当者と確認・調整することで外すことができました。おかげで当初予定よりシンプルなルールにできました。ただ、この「仕様整理の期間」をもっと長めに確保しておけば、予めもう少し潰せたかもしれません。
新しいシステムではこれまでより通知ルールの更新やテストは行いやすくなりました。仕様の整理や改善は徐々に進めていこうと思います。
ただし条件や通知内容の作成が複雑なものは、モジュールを分離してコード上で実装
複雑なフィルタ条件をルールファイルに落とし込もうとすると、可読性が著しく下がったり、ルールファイルのフォーマットが複雑になったりするため、一部のフィルタは諦めてコード上に実装しました。
アーキテクチャ
技術スタック
メイン部分: SES / S3 / Lambda / SQS / DynamoDB / Athena
CI/CD: Code Pipeline / Code Build
IaC: AWS SAM / CloudFormation
コード: Python3.8
コード管理: GitHub
監視 : New Relic
可視化: New Relic / X-Ray
メイン部分
MSP開発セクションはメンバーの数よりもサービスの数の方が多く、サービスの規模は小さなものが多いです。1つのサービスを構成するとき、モノリシック寄りにするかマイクロ寄りにするか毎回迷うところですが、今回は以下のような構成にしてみました。
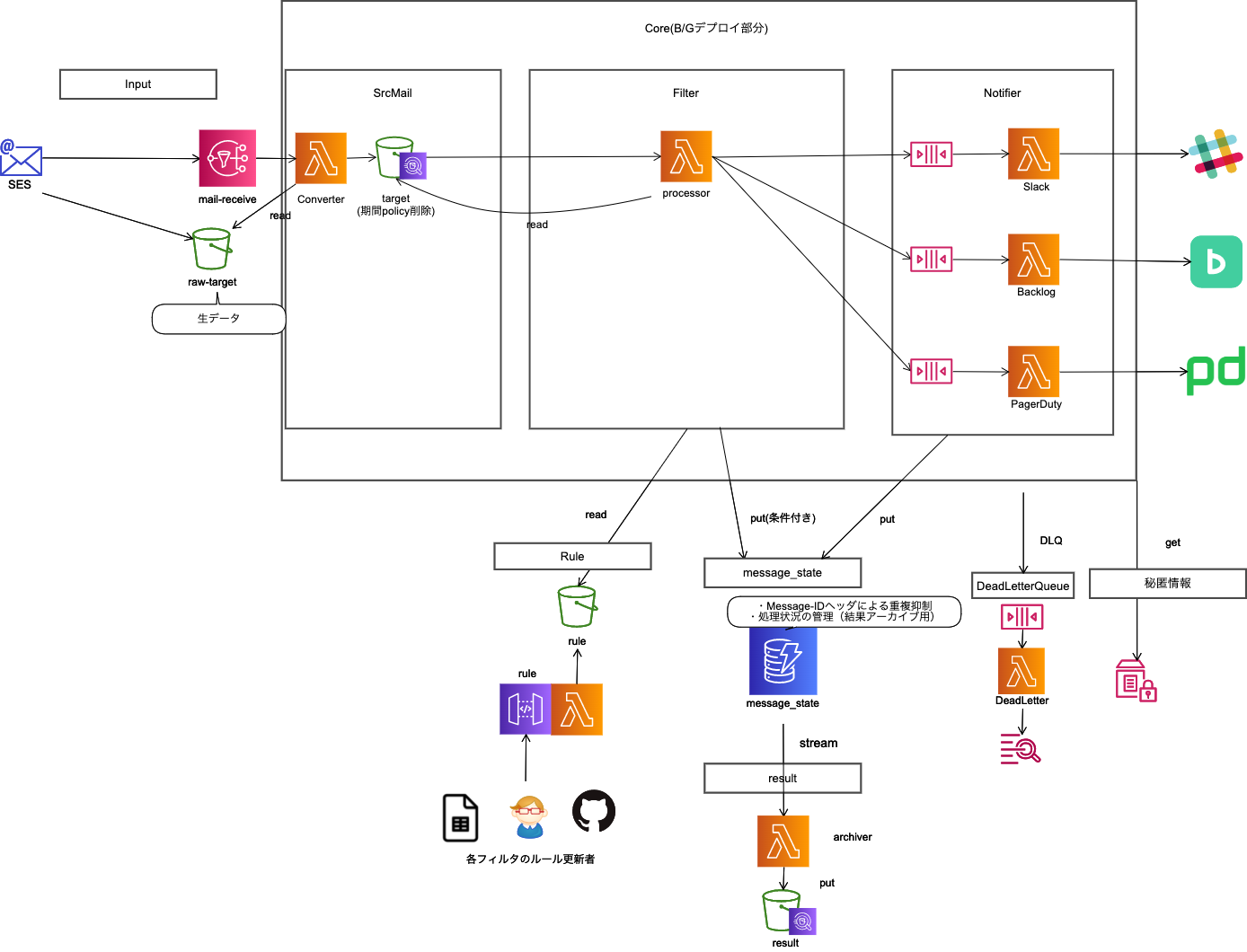
- 外部サービスへの通知部分は独立させ、リトライのチューニングを行いやすくする
- メールの処理状況はDynamoDBに登録
-メールの転送経路などによって同じメールが何通も届くといった部分のケアは、メールのMessage-IDヘッダをキーにした条件付き書き込みで制御
-DynamoDB Streamsで項目の変更をキャプチャしてLambdaに流してS3に処理結果をアーカイブし、あとからAthenaでクエリをかけられるようにする - 変更が入りやすい部分だけBlue/Greenデプロイ対象
-アクティブはSESとの関連付でスイッチ。複数繋いでいる場合は前述のDynamoDB排他テーブルによって先勝ちで動く
振り返り
外部サービスへの通知部分は独立させ、リトライのチューニングを行いやすくする
AWSのサービスだけでなく、外部サービスのリクエストレート制限やメンテナンス、障害も考慮する必要があります。Lambdaの1実行の中でウェイトさせながらグルグルリトライするだけでは無駄にAPIレートを消費する可能性もあります。また障害やメンテナンス時に数十分待機させておくのが難しいです。
SQSで分離し、可視性タイムアウトと受信回数の設定でLambdaの実行時間制限に囚われないリトライをチューニングしています。今後シビアにレート制限をかけたい場合はLambdaの同時実行数による制御も検討します。
DynamoDB Streamsで項目の変更をキャプチャしてLambdaに流してS3に処理結果をアーカイブし、あとからAthenaでクエリをかけられるようにする
これは「メールを後からクエリで検索できるようにしておきたい」という要望もあって実装したのですが、処理結果もあわせて格納しているので「デバッグ」や「計測」にも役立ちました。
Athenaのパーティションについては、最初は細かく分割しようとGlueクローラーを使っていました。ただ運用しながら、保持期間とデータサイズからして、荒く1日単位でパーティション切っても十分だと判断し。Maxのパーティション数は少ないですが、より設定が楽なPartition Projectionに切り替えました。
参考: テーブルあたりのパーティションの数
- Glue使う場合: 10,000,000 (引き上げリクエスト可)
- Glue使わない場合: 20,000
https://docs.aws.amazon.com/general/latest/gr/glue.html#limits_glue
https://docs.aws.amazon.com/athena/latest/ug/service-limits.html#service-limits-glue
メールの転送経路などによって同じメールが何通も届くといった部分のケアは、メールのMessage-IDヘッダをキーにした条件付き書き込みで制御
同一のメールでも異なる経路から配信された場合は複数回SESに配信されることを当初把握できていませんでした。これは並走期間中に気付きました。このあたりの考慮はGmailのフィルタ転送では勝手にしてくれますが、自前で実装する場合は考慮が必要です。また通知部分のSQSにはFIFOを使っています。ただそれでもLambdaのトリガー自体が必ず1回という保証があるわけではありません。通知の重複は頻繁に起こると問題ですが、頻繁でなければ問題ないので許容しています。
外部サービス側で重複抑制の仕組みが用意されている場合もあります。PagerDutyに対しては「dedup_key」というパラメータを指定して重複起票されないようにしています。
CI/CD
所属部署ではCI/CD ツールとして CircleCI を主に利用していますが、今回は AWS の Codeシリーズを使ってみました。「Codeシリーズの知見を積んでおいたほうがよさそう」というのが主な理由で、この部分は「あわなければ途中でCircleCIに変えればいい」ぐらいの気持ちで使い始めました。
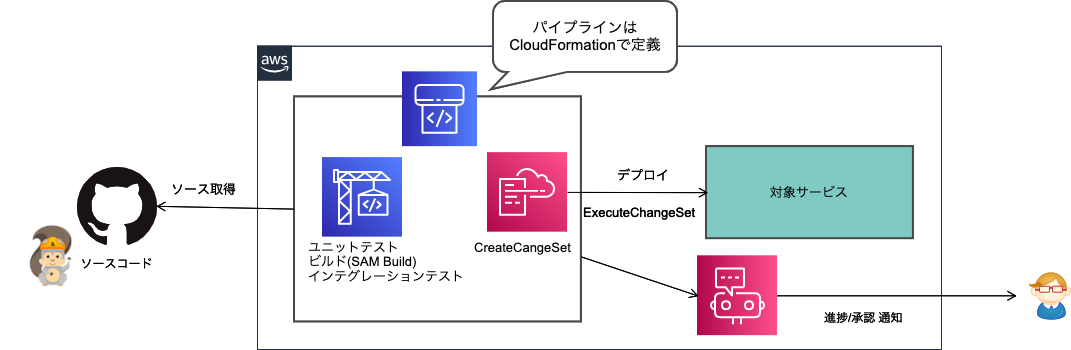
PipelineはCloudFormationで定義してステージ毎に立てています。1つのパイプラインに紐づけられるブランチは1つのみです。CloudFormationに渡すパラメータで対象ブランチや承認の有無などを分けています。
テスト
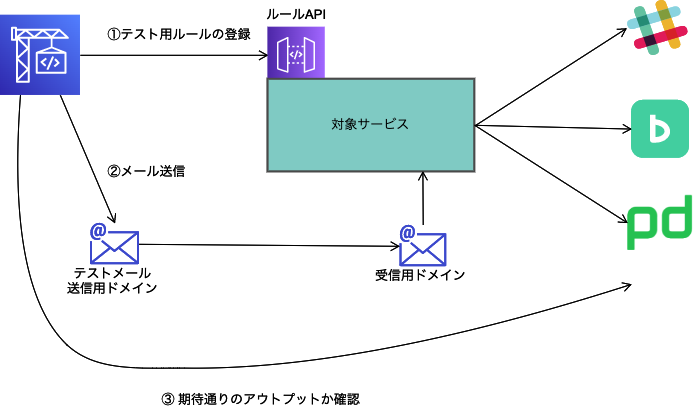
インテグレーションテストでは 「実際にメールを送信して、期待通りのアウトプット(通知)が行われたか確認する」 シナリオをいくつか実行しています。インテグレーションテストのエンジンにはユニットテスト用エンジンのpytestを利用しています。 試作時の記事(このときはpytestではなくunittest)
振り返り
Codeシリーズは出始めの頃に触って、当時それほど印象はよくなかったのですが、久しぶりに触ると機能が拡充されていて使いやすかったです。 ( 例: Code Buildのビルド環境にSessionManagerで入れるようになっていた )
余談ですがAmplifyはモノレポに対応(リポジトリ内で対象ディレクトリを指定可)したので、CodePipelineにも同じようなアップデートが入ることを期待しています!
ステージ と 運用
環境のステージは「本番」「ステージング」「開発(複数立てることもある)」の3種類を今回用意しました。
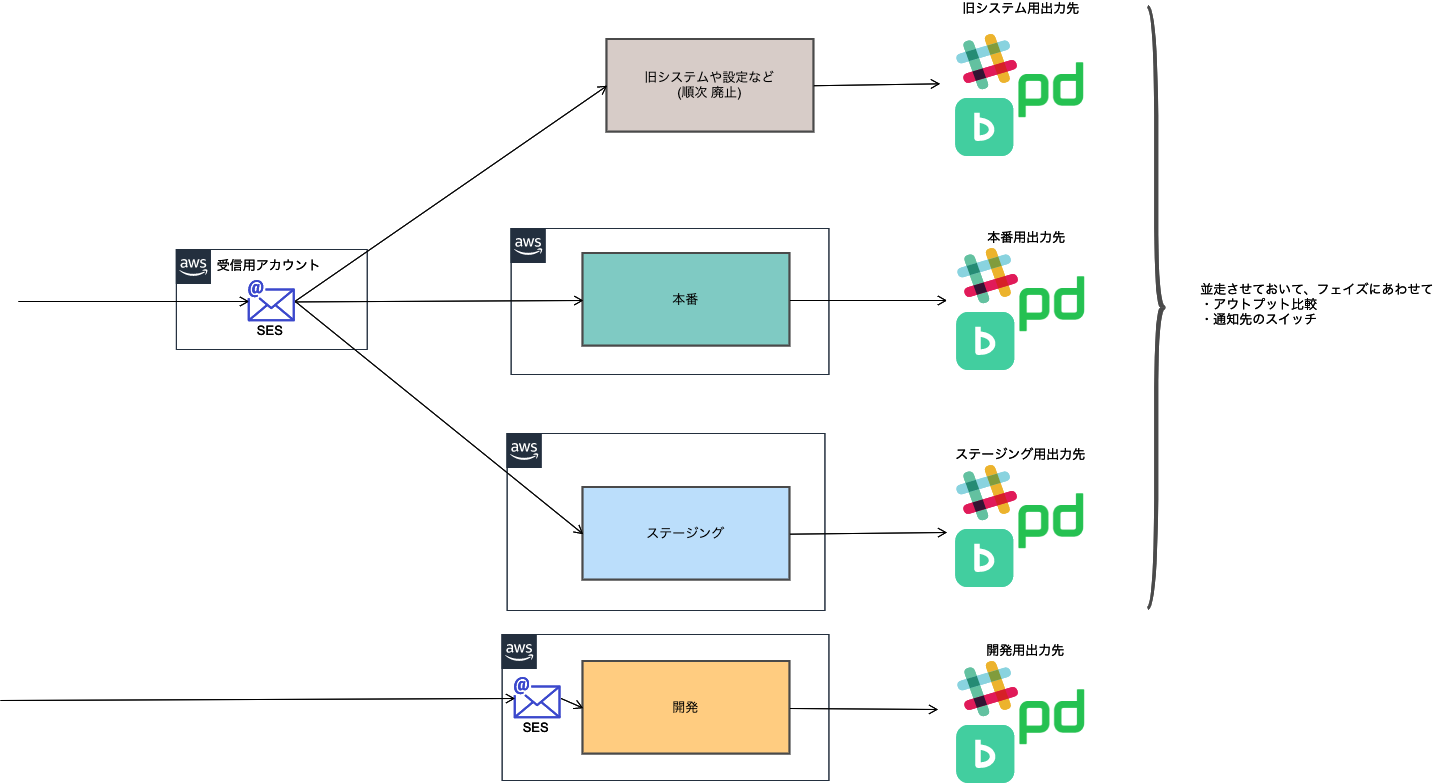
「ステージング」のインプット(受信メールの紐付け)は「本番」と同じにしてあり、同じものが流れてきます。アウトプットだけルールファイルの記載で変更してあるという状態です。
振り返り
ステージング環境は「検証」「アウトプットの比較」「X-Rayによる分析」などで重宝しています。「本番に何かあったときのバックアップ」としても使えそうです。
ただ環境の構成図を見ても分かる通り、ステージ毎にアウトプットの「Slackチャンネル」「Backlogプロジェクト」「PagerDuty」が存在します。Slackでも条件によってチャンネルをわけてたりするので、結構な数になってしまいました。多いと管理が負担になってくるのでまとめる工夫はしていったほうがよさそうです。元は別々のシステムでしたが、今となっては利用者目線でも通知先はまとめていくほうがいいかもしれません。
おわりに
元々この内容は、振り返りとして部署内で共有しようと考えていたものです。良い機会だったのでブログという形で公開させてもらいました。
今回アウトプットし切れていない部分や、今後さらに運用してみて気づいた点は、また何かしらの形で出せたらなと思っています。
