
Google Cloud Next Tokyo ’23 の Day2 にて行われたセッション「Street Fighter 6 アーキテクチャー大解剖」のレポートです。
Google Cloud Next Tokyo ’23 とは
2023 年 11 月 15、16 日に東京ビッグサイトで開催された、Google Cloud が主催するイベントです。
https://cloudonair.withgoogle.com/events/next-tokyo
登壇者
株式会社カプコン
システム基盤部 ゲーム基盤室 ネットワークリードエンジニア 中島淳平 氏
システム基盤部 ゲーム基盤室 エンジニア 松村俊徳 氏
セッション内容
Street Fighter 6 ってどんなゲーム?
- 表記は Ⅵ じゃなくて 6 (ここ重要)
- クロスプレイ
- グローバル展開
- シビアなレイテンシー
- Capcom Fighting Network (CFN):コミュニティ機能
- Battle Hub:仮想ゲーセンのようなもの
アーキテクチャ
全体構成図
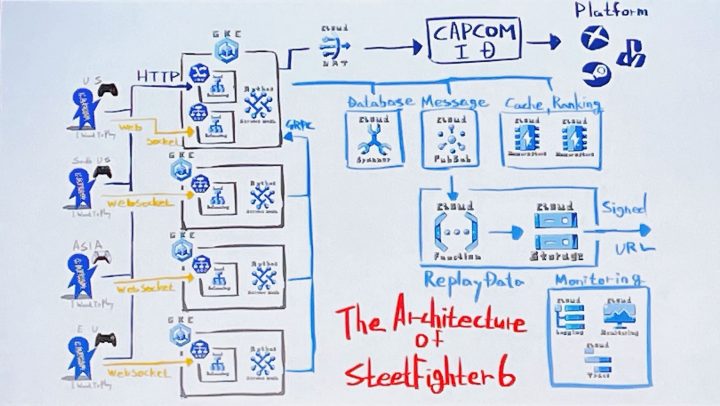
GKE クラスター詳細図
- Anthos Service Mesh クラスターで構成
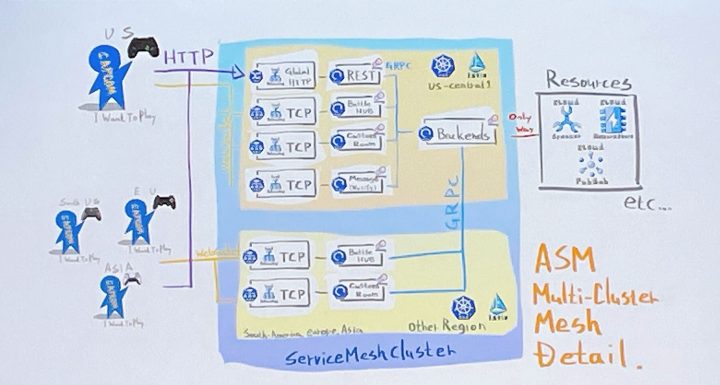
- 各サーバ概要
- API サーバー
- サーバー自体は処理を持たず、作業は GRPC を介して各サービスへ依頼
- ステートレスでオートスケール
- Battle Hub サーバー
- いわゆるビジュアルロビー
- WebSocket で通信
- ステートフル
- 各リージョンに複数台
- 基本的にロビー内の閉じた処理
- DB 操作をする場合は、GRPC を介して各サービスへ依頼
- CustomRoom サーバー
- ビジュアルロビーからビジュアル要素を除いたもの
- 各リージョンに Pods をプールしており、ユーザーの要請に応じて活性化
- Battle Hub とほぼ同じコードで構成
- Notify サーバー
- クライアントへ Push 通知を行うサーバー
- WebSocket で通信
- ステートレスにスケール
- ユーザがオンライン状態である間はずっと接続し続けている
- Cloud Pub/Sub から流れてきたパケットを適切な宛先に送る
- その他大勢のサーバー
- マイクロサービス
- 認証やマッチングなど含めて 20 サービスくらい
- 実態は GRPC サーバー
- ステートレスにスケール
- プリエンティブを使用してコスト削減
- API サーバー
GKE
- なぜ DB 処理などのバックエンド通信をメインクラスターだけが行うのか?
- API の処理はほぼ DB 操作なので、DB よりも API サーバーをどこに置くかに注目
- 影響範囲を考えると人口の多いアメリカが無難
- その場合、アメリカから遠い国ほどレイテンシーが増え、その遅延は避けられない
- 自国に API サーバーをおいたら DB 処理が行われるたびに遅延が発生する
- API サーバーもアメリカに置いて最初にアメリカへの通信を行うことで、後続の処理遅延を削減
- API の処理はほぼ DB 操作なので、DB よりも API サーバーをどこに置くかに注目
- Battle Hub はなぜ各リージョンにあるのか?
- 同期サーバはレイテンシーがより大事なので、しかたなく各リージョンに置くことに
- DB 操作は?
- Anthos Service Mesh を信じろ(実際 Google Cloud 内部線だから速かった)
- リージョン障害があったらどうするのか?
- トラフィックは Anthos Service Mesh で制御されているので、別リージョンがメインクラスターに昇格する
- 一応サブクラスターが pods 数 0 で待機している
Cloud Spanner
- RDBMS っぽいのにスケール、フルマネージドですごい!という触れ込み
- よかったところ
- スケールが楽
- 当時はオートスケーリングの仕組みがなかったので適当なメトリクスを監視して判断(今はオートスケーリングが実装済み)
- マイグレーションやリストアなどのパワーがいる作業をするときは一時的に増やしたりしていた
- しんどかったところ
- SQL っぽいけど SQL ではない
- チューニングの勘所もかなり違う
- SELECT FOR UPDATE ができないの想定外のロックがかかった
- Spanner で開発する上でのテクニック
- トランザクションやクエリに独自のタグが付けられる
- スロークエリなどの特定に役立つ
- SPANNER_SYS.xxxx テーブルに各種統計情報が格納されている
- 上記のタグはここでの調査に役立った
- バッチ処理などの重い処理は PartitionedQuery を使う
- ロックのペナルティがきついので Spanner でのロックは諦め、Redis で排他ロックという方法を採用した
- 負荷試験などのために暖気は必要(結果的に本番リリース時は無しでいけたけど)
- 検索機能のクエリ負荷が高かったり応答速度が悪い場合は、Local Limit や Sort Limit を理解したインデックスパターンを用意するべき
- トランザクションやクエリに独自のタグが付けられる
監視
- 監視の監視はしない
- Cloud Monitoring、Cloud Logging、Cloud Trace を採用
- 基本的に落ちないので、多少使いづらくても全部乗っかる方針
- 省エネでやる(実装者のエネルギーのことで利用料金ではない)
- 具体的には、基本的にデフォルトでレポートされるもので頑張る
- 細かいメトリクスを取っても見ない
- そもそもデフォルトでも割と細かくレポートしてくれる印象
- ベンダー SDK は使わず、全て OpenTelemetry でやる
- 最悪 Prometheus に移行できる
- 基本的にライブラリ層で解決する
- クエリ投げる前に trace span 打ったり、自動でタグ打ったりなど
- アプリ側のコードで何もしてなくてもトレースできるようにしておく
- 具体的には、基本的にデフォルトでレポートされるもので頑張る
- 見ていて楽しい
- リアルタイム接続数や通報数、現在のプレイ人口なども出している
- OpenTelemetry 経由だと簡単に好きな値を送信できる
- サーバ負荷を見るだけでなく、ゲーム内容と合わせて監視すると良い
- 負荷グラフだけではそれだけしかわからないので、複合的な情報から状況判断を行うため
- (例)プレイ人数が多ければ CPU 負荷上昇、マッチング待ち人数が多ければ DB 負荷上昇など
- 開発部隊と運用部隊が分かれていないメリットだと思っている
感想
全世界向けのサービス且つオンライン対戦(しかも格ゲー)ということで、どのようにレイテンシーを抑えているのか?が気になっていましたが、その部分についての対策や工夫が十分に説明されており、個人的に興味深いセッションでした。
GKE クラスターの構成詳細も、一見複雑に思えましたが、それぞれのサーバーの役割と実際のゲームプレイのどこに当たるかを紐づけて説明があり理解しやすかったです。
また、開発部隊が監視運用も行なっているという観点で、私にはない視点があり非常に勉強になりました。




