
Google Cloud Next Tokyo ’23 の Day2 にて行われたセッションD2-DA-03「データ分析を加速する BigQuery 性能最適化のポイント」に関するレポートと感想の前半です。
主な発表内容
- BigQueryは継続的なパフォーマンスチューニング、最適化を継続して行っている
- BigQueryの性能を活かす上で最適化のポイントを解説
- WHERE句で使用する列
- ORDER BY の見直し
- 結合順序の指定
- クロスジョインの回避
- COUNT(DISTINCT)の見直し
- ウィンドウ関数の見直し
- 最新レコードを取得すう集計関数の見直し
個人的にBigQueryは様々な案件で利用しており、Google Cloudを採用する上で強みとなっているDWHです。
前半にはアーキテクチャの紹介と継続的なチューニング、最適化を行っているということで直近の改善点の発表がありましたが
後半の最適化のポイントをメインに書いていきたいと思います。
話されたことはデータベース、DWHを使った開発やクエリ作成で汎用的な考えであり結構当たり前と言われそうな内容ですが、そういうことこそできてない現場も多く、自分も気付きが多くありました。またそういったBigQuery独自ではなく汎用的な考えが使える。ということがBigQueryの良さではないかと思います。
WHERE句で使用する列
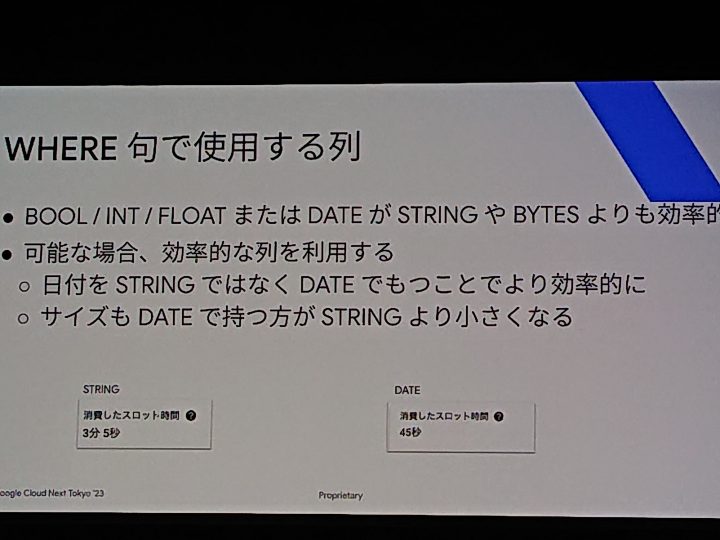
ここは型定義の正規化が重要ということになります。
スライドにある通り日付を文字列にしてしまって関数処理で柔軟に対応できますが、やはり日付型で持つべきといったところ。
サイズや消費スロットに関しての言及もあり勉強になります。STRINGとINTEGERだけでとりあえず突っ込んでおこう。というのはよろしくないということですね。
アイレットは設計段階でのこれらを踏まえた整理、もしくは既存がボロボロでも性能改善における正規化を提供できます!
ORDER BY の見直し

「ORDER BYは最も外側のクエリで利用する」は複数のクエリを繋げて作ったりする場合にそれぞれにそのままORDER BYかけがちなので、開発チームにも改めて啓蒙したいところ。
「limitを使って絞る」はデータ検証段階で処理時間ではなく金額に跳ね返ってきたケースがあったので、これは本当に重要です。自分は毎回癖で付けるようになっています。
結合順序の指定

「なるべくテーブルはサイズの大きい順でSQL内に記述する。」
恥ずかしながら、これはほぼ意識したことなかった。
クロスジョインの回避

スライドの例がわかりやすいですが、結合条件が無い。はさすがにやらないと思いますが、等価結合ではないWHERE句、OR入れちゃってる例などは参考になります。
SQLのレビューは大事ですが、毎回人を挟むのは効率的ではないので、初級エンジニアがやりがちなこういう最低限のチェックはAIでやっていきたいところ。
COUNT(DISTINCT)の見直し

ここは「近似集計関数を使う」という点は参考になりました。
用途によってが大前提になりますが、速報ベースのものはこれでいいじゃんと思ってしまった。
ウィンドウ関数の見直し
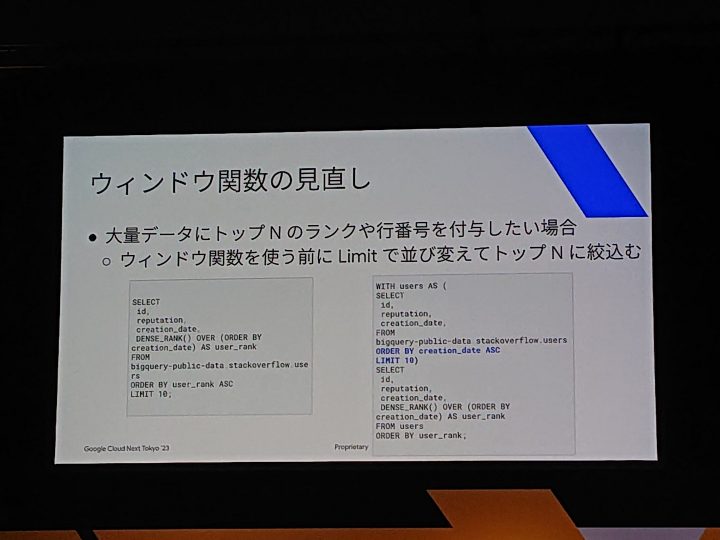
ランク(ランキング)や行番号に関してはアプリケーションやLookerのようなBIで表示する場合はSQLベースでというところは考えず、対応方法はあるかと思いますが
BigQueryからの取得した状態でというところを考えると、こういう考え方があるのかと気付かされました。
最新レコードを取得する集計関数の見直し

row_number ~ as rownum はOracle使ってた人はやりがちな印象が個人的にはあります。
max_by、min_byも一般的なSQL関数なのでちゃんと意識しておきたいところ。
まとめ
性能最適化のポイントの前半はSQLにおいての改善ポイントでした。
これエンジニアに言っても当たり前ですよ~と言われると思いますが、実際に徹底しているかどうかは話が別です。
BigQueryの性能に頼らず、課金の面でもBigQueryでは重要な要素なので、細部こそ意識するエンジニアチームを作っていきます!すでにありますが!もっと作ります!


