
Google Cloud Next Tokyo ’23の Day2 にて行われたセッション「DMM における AWS から BigQuery へのデータ基盤移行」のレポートです。
Google Cloud Next Tokyo ’23 とは
2023 年 11 月 15、16 日に東京ビッグサイトで開催された、Google Cloud が主催するイベントです。
https://cloudonair.withgoogle.com/events/next-tokyo
登壇者
合同会社DMM.com
マーケティング本部 データ戦略部 データインフラグループ マネージャー 藤井亮太氏
セッション内容
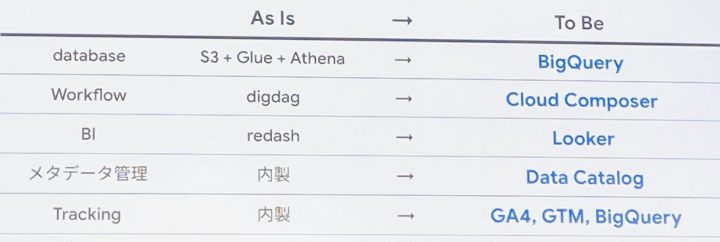
データ基盤移行の背景
- 1500 以上のテーブル数
- ほとんど日次更新
- job 再実行などの保守が定常的に発生
- 30000 クエリ/week
- 5オペレーション/week
- 稼働中のシステム保守以外に追加更新
課題・期待
- オペレーション省力化
- データオペレーションが多く、活用拡大にリソースを割けない
- 自動化、省力化を進める
- ガバナンス
- アウトプットの質が利用者依存
- 誰でも高品質なアウトプットができるシステムへ
- データ活用の拡大
- データ活用が社内に閉じていた
- 社外システムとも柔軟に連携できるシステムへ
Google Cloud 移行の狙い
1.Severless、Managed を活用した低保守コストなシステムへ
2.データ利用者増加に耐えるガバナンスと運用設計
- リフト → シフトと単純にフェーズ分けをせず、特性に沿った形で設計
- データの収集からアウトプットまでに介在する人組織に注目し、フィジビリティのある運用設計
- アウトプットの質を高めるために信頼性のある設計
3.社外のサービスや組織との柔軟な連携
- Data Activation / ReverseETL
- MAツールなどとの連携
- コラボレーション
- サービスアカウント、IAM による社外Google CLoud プロジェクトとの容易な連携
基盤移行の流れ
移行全体像
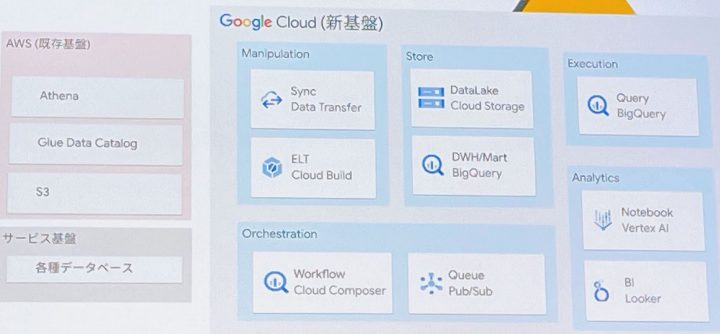
移行の流れ
- 1.AWS → Google Cloud データ同期
- 1.Data Transfer による同期
- 2.Cloud Storage の変更検知と job の遅延実行
- 3.変更対象に応じた Merge クエリの生成
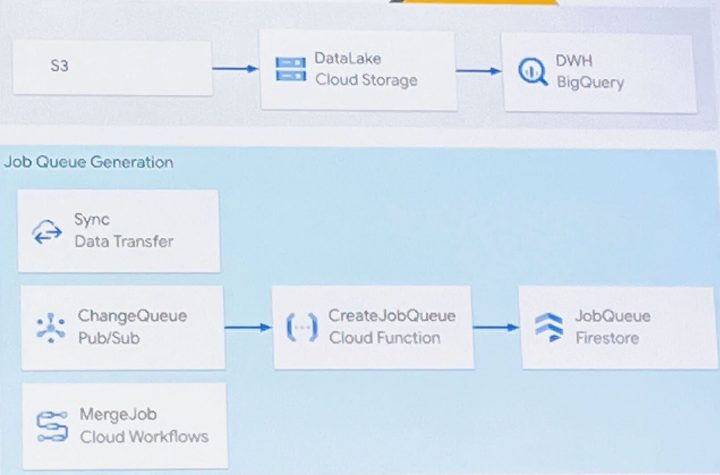
- Point 1:差分更新
- S3 から Cloud Storage、Cloud Storage から BigQuery ともに差分のみを更新することで小コストで高頻度なデータ同期が可能
- Point 2:データの差分検知
- 同期されたデータの際を検知する機能を実装
- クエリ実行環境
- 1.データの保存領域とデータ利用部門毎のクエリ実行環境を分離
- 2.データ利用部門毎に一部管理を譲渡
- データ利用者の追加・削除
- Sandbox 環境内での DDL 実行、スケジュールクエリの実行
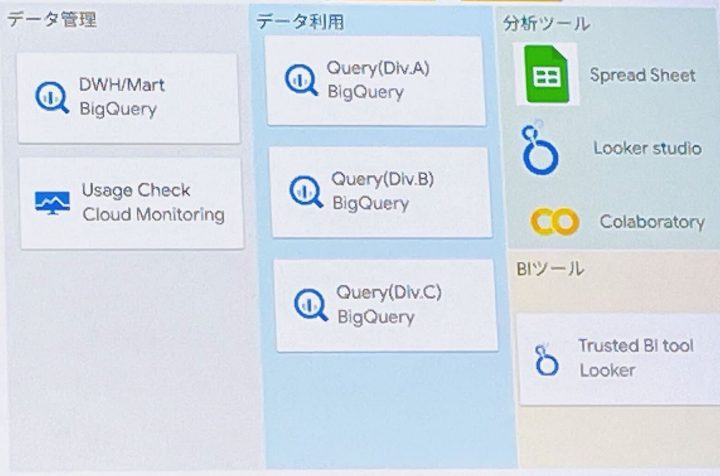
- Point 1:ガバナンスと民主化
- ユーザ管理の譲渡(Google Group)
- 過剰利用の監視(Cloud Monitoring)
- 部門ごとの利用料に応じたコスト按分(Editions導入)
- データの信頼度定義と委譲(GitLab の Trusted Data Criteria をベース)
- アナリスト向けパイプライン
- 1.SQL と簡単な設定でマートを生成可能
- プログラミング未経験のメンバーが容易に実行できるように
- 2.スケジュールクエリのリポジトリを管理
- データ利用プロジェクトと対応した Code Owner を設定
- クエリの Dry Runによるテスト
- 書き込み対象領域の権限チェック
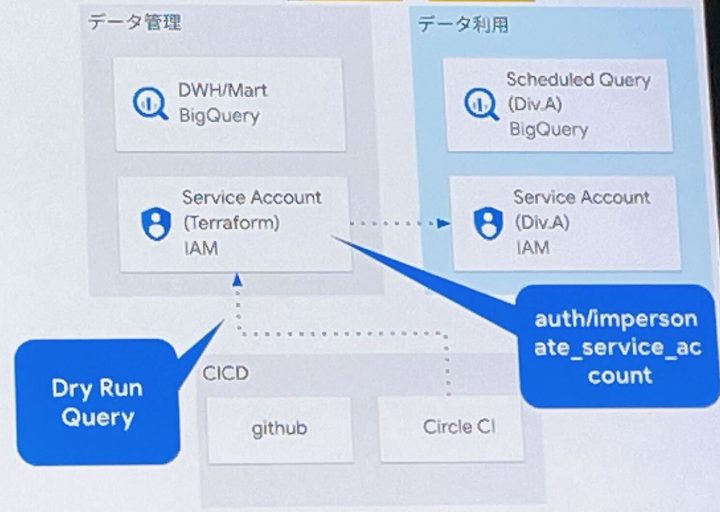
- Point 1:レビューとテスト
- Code Owner によるレビュー
- CI への BigQuery Dry Run 取り組み
- 1.SQL と簡単な設定でマートを生成可能
- Looker 連携
- 1.Looker のプロジェクトは組織よりも細かいチーム粒度で分割
- BigQuery の組織単位のプロジェクトと紐づけ
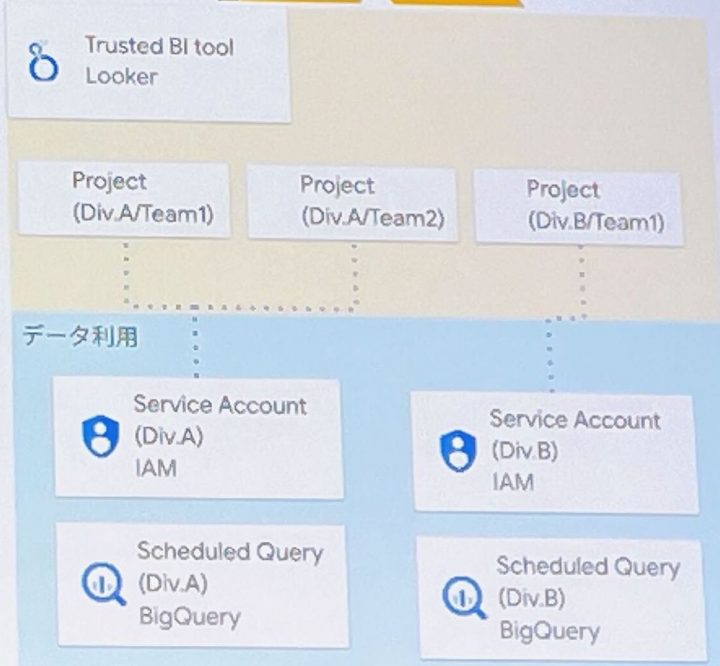
- BigQuery の組織単位のプロジェクトと紐づけ
- 1.Looker のプロジェクトは組織よりも細かいチーム粒度で分割
- AWS依存解消
- 1.Cloud Composer で dag 制御
- 2.Cloud Build で Embulk を実行

- Point 1:Information Schema の活用
- Cloud Storage → Staging Table → DWH 用 Table へ Merge
- 差分取り込みのための Staging Table で不要コストを抑止
- 一連の処理は取り込み対象テーブルの Schema から自動生成
- 設定ミスによる不揃いな型での取り込みが発生しない
- Cloud Storage → Staging Table → DWH 用 Table へ Merge
- Point 2:IP固定
- Cloud Composer の Private pool
- Private サービス接続とカスタム Export
まとめ
- Severless、Managed を活用した程保守コストなシステムへ
- インフラの保守運用よりも機能開発により多くの時間を割けるようになった
- 各機能の繋ぎこみも Cloud Pub/Sub、Cloud Functions を採用することで開発がスムーズに進んだ
- データ利用者増加に耐えるガバナンスと運用設計
- Information Schema の活用によって、データ取り込みやデータ利用量の監視をスケーラブルな方法で実現できた
- 組織拡大に対して再現性のある運用方法を構築できた
- Delivery 重視なアドホック分析や、Quality 重視なダッシュボード作成を提供できた
感想
AWS から Google Cloud へのデータ移行方法は多種多様ですが、一般的な手法や単純にベストプラクティスに従うのではなく人組織に合ったやり方を考えて実践していることに非常に感心しました。
また、移行の各フェーズでのポイントを説明していただいたことで、実際にどのような技術および機能で工夫されているかがわかりやすかったです。



