
前回からだいぶ時間が経ってしまいましたが、Google Cloud Next Tokyo ’23 の Day2 にて行われたセッションD2-DA-03「データ分析を加速する BigQuery 性能最適化のポイント」に関するレポートと感想の後半です。
中間テーブルの利用

BigQueryでも当然中間テーブルは有効。
図のようにローデータをBigQuery のストレージ コンポーネントを利用し、中間テーブルを作成することで高速化が見込めます。
そもそもJOINが多い場合も割り切って、高速化用の中間テーブルの作成はBIに向けての利用でも有効だと思います。
シリアル処理の削減

Spannerでも同じことがいえるのですが、スロットを意識することは重要です。
とはいえRDBからデータを持ってくるケースも多いと思うので、auto incrementを使ってるとそうもいかないのですが、改めてID振り分けをする際にuuidなどを利用するといった分散は良いかと。
パーティショニング

RDBでも大量のデータを扱う場合のパーティショニングは重要なので、これはBigQueryでも意識しておきたい部分。
マテリアライズドビュー

これは所謂キャッシュ化なのでBIの参照で更新頻度を割り切った用途で使うと有効だと思います。
Lookerだと似たようなタイル多くなったりするので。
あとは類似を減らし、使いまわしできるように管理ルールを取り決めたいところ。
SEARCH INDEX
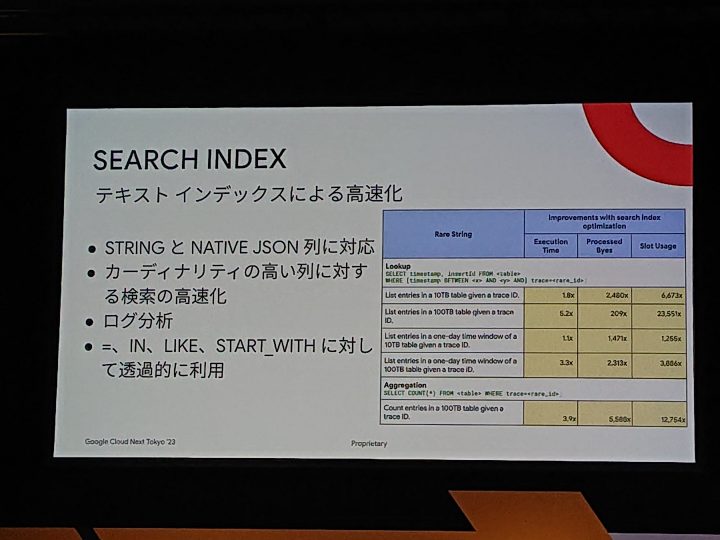
BigQueryはローデータを突っ込むケースが多く、その中から文字列パターンでフィルタを作成し、一致条件。というのをLookerでもよくやります。
個人的にはSEARCH INDEXはよく使う高速化方法です。
テーブルの非正規化
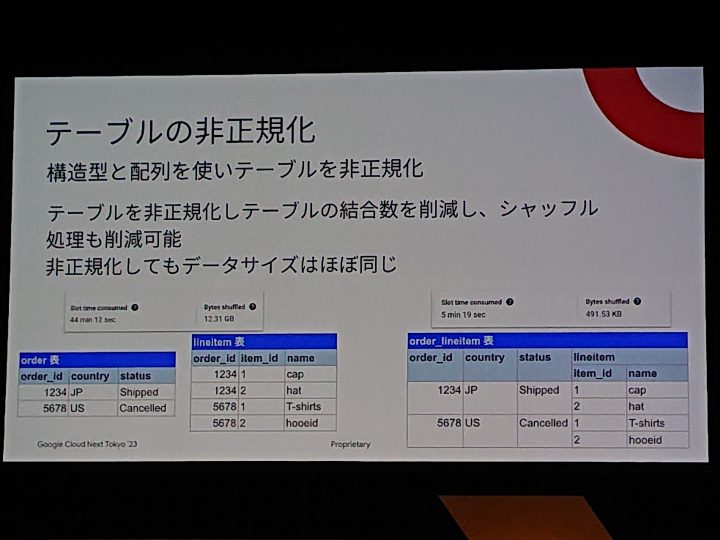
配列を使う。という部分は個人的にちゃんと使えてないので、割り切って使っていきたいと思いました。
主キーと外部キーで結合を最適化
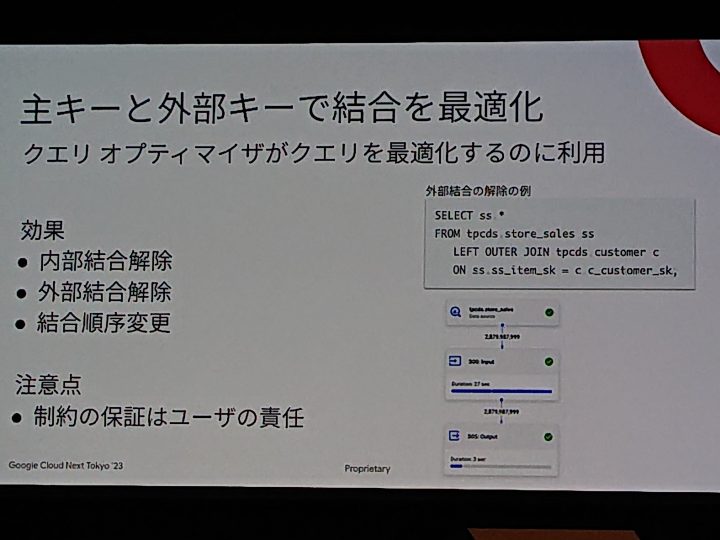
特に結合順序は気にしていないので、詰めるとここまでやる必要があるのかと。
DWH特有のデータ量の多さなら差が出てくるのかなと。
Metadata Cachingメタデータのキャッシュ保存

これはCloud Storage BigLake テーブルを作成して使っている場合に限るネタですね。
リアルタイム性を問われないケースが多いので、有効ですね。
まとめ

「なるべく少ないリソースで結果に辿りつける書き方を心がける」はRDBに対してのクエリ作成においても基本かつ最も重要なことなので
やはりそこに帰結するなと思いました。
AIによるクエリ生成など開発への敷居はどんどん下がりますが、職人的なチューニングはBigQueryにおいても普遍的なものですね。

