
はじめに
2023/8/22に開催中の Google Cloud 主催の Generative AI Summit にて PaLM API の日本語対応が公に発表されました。
そのお祭りにのり、前回の Generative AI Studio を利用した PaLM API の日本語を試してみた では簡単なプロンプト入力による応答結果の変化を見てみました。
今度は実際に利用するようなケースをイメージして、試してみます。
BigQuery での Vertex AI 利用
BigQuery の ML.GENERATE_TEXT 関数にて、以下のような用途で利用できるような内容を大規模言語で出すことが可能でした。
Classification Sentiment Analysis Entity extraction Extractive Question Answering Summarization Rewriting text in a different style Ad copy generation Concept ideation
今回はその内容の日本語を試します。
BigQuery を利用した PaLM API 日本語利用で試すこと
内容としては、Google のマーケットプレイス内にある、Google BigQuery 一般公開データセットの google_trends を利用して、日本で急上昇ワードとして選ばれたワードに対して、「なぜ人気になったのか、トレンド入りしたのか」をみてみたいと思います。
実行手順
データセットを作成します
Vertex AI 大規模言語モデルに相当するリモートモデルを作成するために、このデータセットが必要になります。
今回 bq_llm_hsaito で作成しました。
コネクションを作成します
Google BigQuery 一般公開データセットに接続するためのコネクションを作成します
bq mk --connection \
--location=US \
--project_id=$プロジェクトID \
--connection_type=CLOUD_RESOURCE bq_llm_hsaito_connection
※bq_llm_hsaito_connectionはコネクションIDです
サービスアカウントへの Role 付与
コネクション作成時にサービスアカウントが紐づいて作成されます。
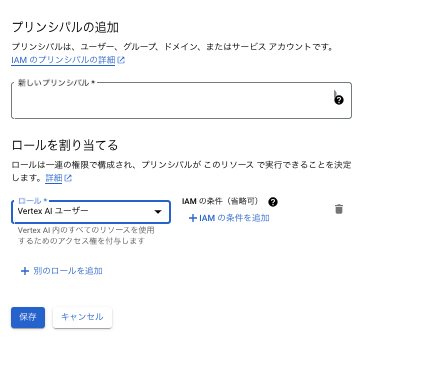
そのサービスアカウントに 「Vertex AI ユーザー」の Role を付与します。
リモートモデル作成
Vertex AI 大規模言語モデルに相当するリモートモデルを作成します。
これがデータセット配下に作成されます。
CREATE OR REPLACE MODEL bq_llm_hsaito.llm_model_hsaito REMOTE WITH CONNECTION `us.bq_llm_hsaito_connection` OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
※
bq_llm_hsaito.llm_model_hsaito は データセットID.モデル名 です
us.bq_llm_hsaito_connection は リージョン.コネクションID です
OPTIONS 行はそのまま変動ありません
Google の急上昇ワードに関する日本語のテキスト生成
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm_hsaito.llm_model_hsaito`,
(
SELECT
CONCAT('そのキーワードはなぜ人気なのでしょうか?何でトレンド入りしたか?と理由を教えてください', term)
AS prompt
FROM
`bigquery-public-data.google_trends.international_top_rising_terms`
WHERE
refresh_date >= DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 2 WEEK)
AND country_name = "Japan"
AND rank = 1
GROUP BY term
LIMIT
10
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
FALSE AS flatten_json_output));
ml_generate_text_result の応答の content 箇所にプロンプトの結果が入ってきます。また、 safetyAttributes 箇所には安全性の分類が入ってきます。詳細はリンク内容を参照ください。
ML.GENERATE_TEXT 関数にて、利用モデル、プロンプト内容、対象スキーマを定義します。
FROM 句で、どのデータに対するものか、WHERE 句では出力にあたっての条件を絞っています。
せっかくなので、日本の上昇キーワードで調べています。
STRUCT にて Generative AI Studio で定義したような、温度やトークン及び、その他も定義できるようになっています。
実行結果
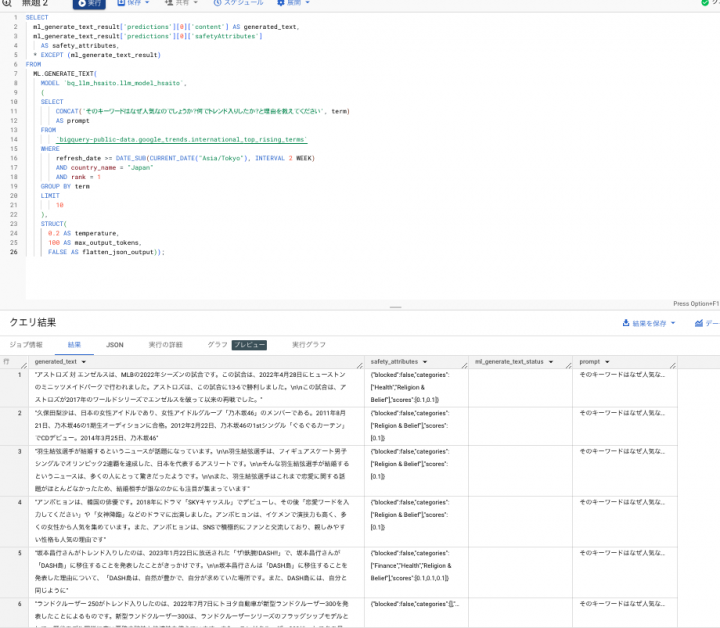
キーワードに対する上昇理由がしっかり出てきました。
私のミーハー具合にささる内容だと、羽生結弦さんのご結婚、V6の坂本さんですが、鉄腕DASHに出演し坂本さんは急上昇として入っていたようです。
通常の SELECT だとキーワードがわかるだけですが、それの理由がわかるような形となりました。
※元々英語ではもちろんできていましたが、日本語でもこの精度の結果が得られます。
纏め
モデルを利用した分析というのはハードルが高そうですが、それほど煩雑ではない手順で、大規模言語の恩恵を受けつつ、日本語での分析をすることが可能であることがわかりました。
ここに更に前回のプロンプトの記事に記載したような、温度等を調整することで、内容に応じたより効率的な分析が可能になるだろうと感じ、日本語対応は我々にとって、とても大きなアップデートになったと感じました。
参考記事
BigQuery で Vertex AI モデルを使って、SQL のみで LLM のテキスト生成を実行する
The ML.GENERATE_TEXT function
feedbackResponsible AI

