
はじめに
プレビュー機能ではありますが、Vertex AI の根拠付け設定が可能になり、Vertex AI Studio にて Vertex AI Search 上で作成したデータストアの情報を参照のうえ回答させることが可能になりました。
その機能の説明と、実際に動作させてみた内容を記載します。
根拠付け機能とは
生成 AI は必ずしも100%正しい回答をだせるわけではなく、間違った回答をしてしまうケースがあります。
その現象を「ハルシネーション(幻覚)」と呼んでいます。
生成 AI のハルシネーションに対する Google Cloud の取り組みに関して、Google Cloud Next Tokyo ’23 の DAY 1 の基調講演でもデモがされていましたが、それの解決策として「グラウンディング」と呼ばれる、「根拠付け」設定を行うことで、あるデータソース情報から検索し回答を行うことが可能になり、「ハルシネーション」を防ぐことができます(リンクはデモ画面あたりに遷移します)。
このように外部に出された情報を参照して回答を行うことを RAG(Retrieval Augmented Generation) と呼ばれています。
本来は対象のモデルに学習させるために、リソースや時間などがかかるところを、Google CLoud のマネージドサービスにて、この RAG の仕組みを比較的容易に構築することが可能になります。
今回はこの根拠付け有無による回答内容の違いを実際に見ていきたいと思います。
作業イメージ
まずは、実際に作業をしていく中で私がイメージしたサービス間の接続は以下のような形になります。
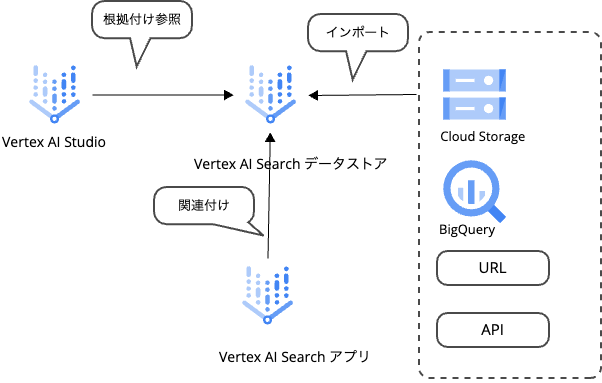
Vertex AI のアイコンでほとんど同じになってしまいましたが、Vertex AI Studio から Vertex AI Search のアプリに紐づけたデータストアの内容を参照して、Vertex AI Studio のプロンプトにて、データストアに基づいた回答をすることが可能になります。
現状、データストアとして利用可能なものですと、Cloud Storage 、BigQuery 、Webサイト上のURL、APIのいずれかが選択可能でした。
では実際に行っていきます。
やってみた
参照情報
・Vertex AI における根拠づけの前提条件がリンクに記載されています。
・Vertex AI Search を使ってみるにVertex AI Search の作成については記載されており、参照しております。
1. Vertex AI Search にアプリとデータストアを作成する
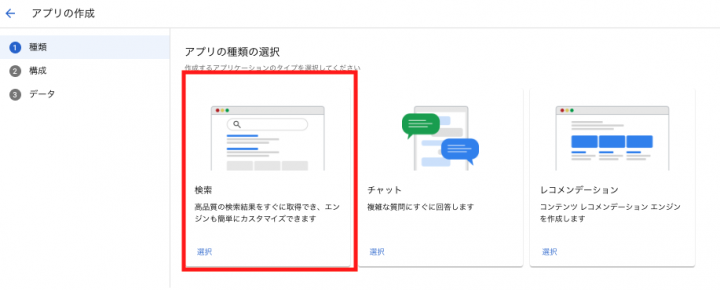
以下の中から「検索」を選択します。
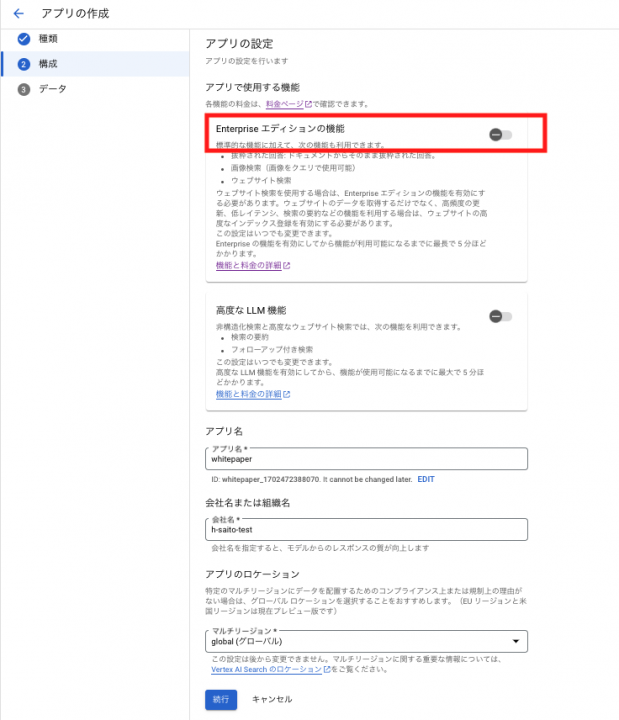
次に検索のアプリの設定画面で「Enterprise エディション」は有効にしておく必要があります。
次にデータストアの作成画面になります。
データストアはまだ作成していないので、データストアの作成画面へ遷移します。
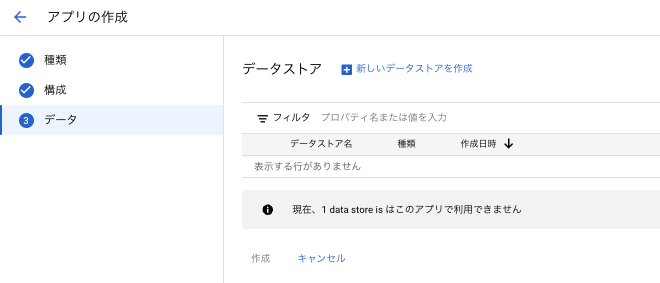
今回 Cloud Storage を利用したいと思うので、Cloud Storage を選択します。
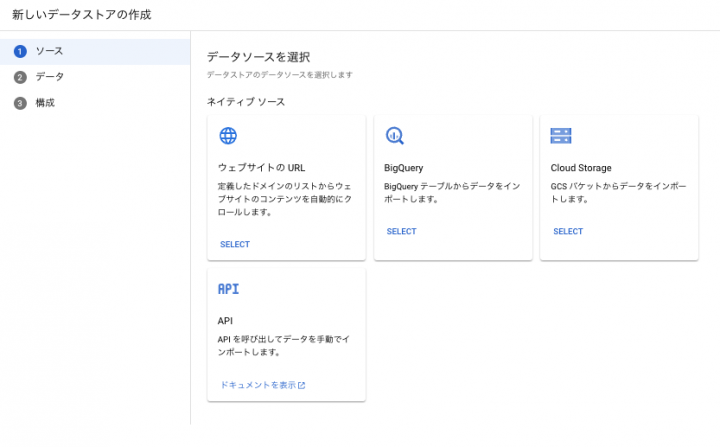
次にインポート対象のバケットを選択します。
この時点で対象バケットにドキュメントが無いとインポートに失敗しますが、このあとデータストア画面からインポートはもちろん可能です。
ただ今回手間が多くなってしまうので、予めバケット内にはドキュメントを入れておき、インポートしています。
またPDFファイルで試そうと思っているので、非構造化ドキュメントを選択します。
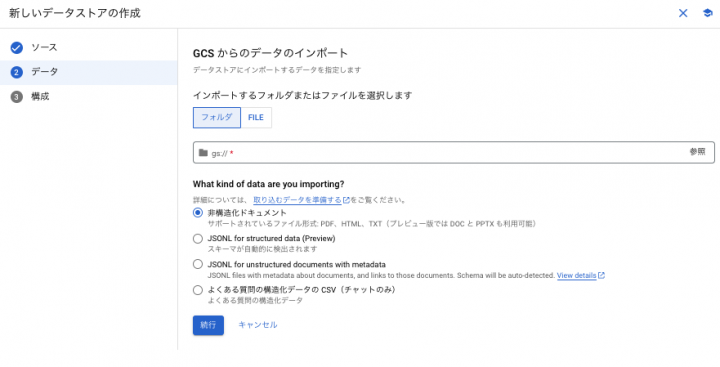
次にデータストア名を入力します。
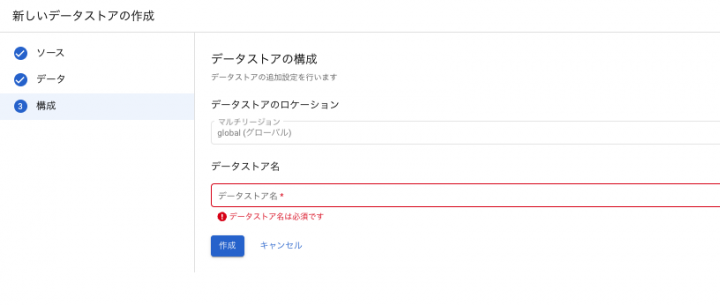
最後に作成ボタンを押下します。
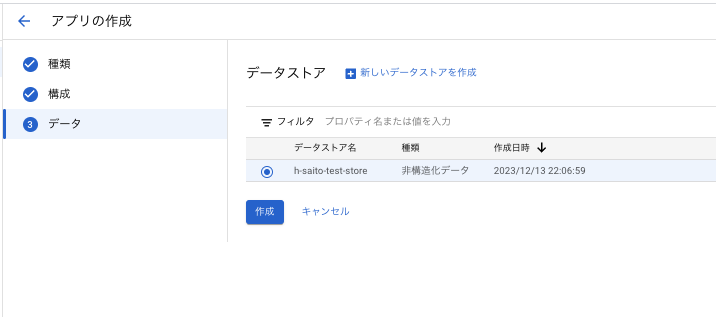
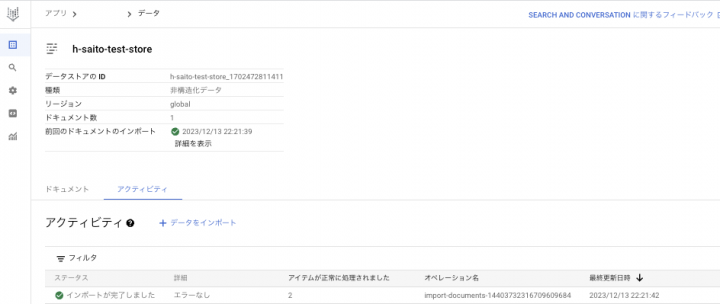
以下の通り、アクティビティを選択すると、ドキュメント2つをインポートできたことがわかります。
Vertex AI Studio で根拠付けする
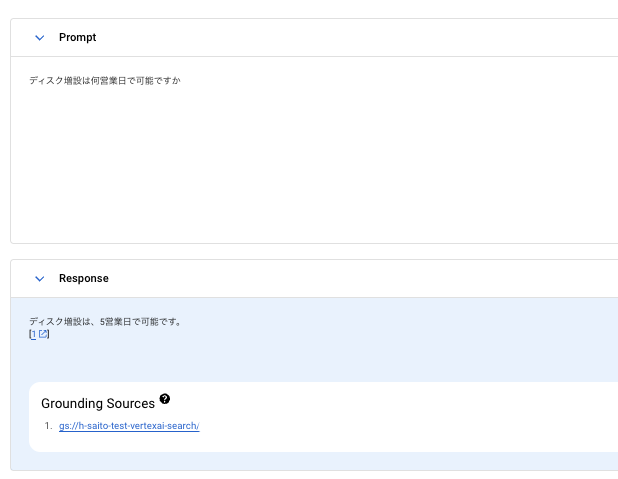
今回インポートしたドキュメントには、GCEに関する作業がどれくらいで可能か、をPDFに仮でまとめた内容をアップロードしています。
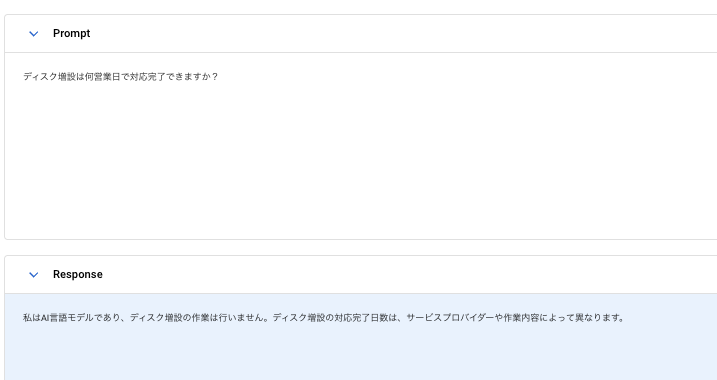
まずは根拠付け設定前に根拠付けをしていない状態の回答を見てみます。
どれくらい、、という回答が来ると良かったですが、もっともな回答が返ってきました。
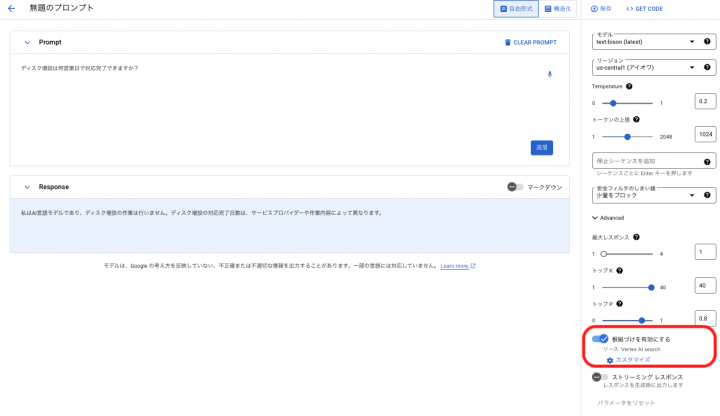
この状態から「根拠付けを有効にする」を有効にします。
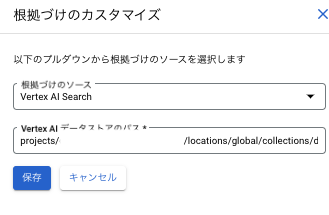
更にカスタマイズ部分をクリックし、対象のデータストアを入力します。入力形式は以下になります。
collection_nameは「default_collection」が今のところ固定で入り、datastore_nameは「データストアのID」を入力しました。
projects/{project_id}/locations/global/collections/{collection_name}/dataStores/{datastore_name}
根拠付を有効にすると、以下の通り、PDFに従った回答と、Grounding Sources 情報が出力されます。
所感
Cloud Storage にデータを格納してしまえば、その内容に従った回答が行われることがわかりました。データストアとして Cloud Storage や BigQuery に情報をためているケースは多いと思うので、そういった部分でも、これから取り組まれる方にとっては嬉しい機能になるのではないでしょうか。
学習させるような場合、それに関する技術や行うための時間、リソースを多く要しますが、今回のマネージドサービスを利用することで、比較的容易に情報ソースをもとにした回答を行わせることができます。その結果ハルシネーションも防ぐことが可能になりました(現状聞き方を変えても確認した範囲ではソースに記載した回答が行われます)。
つい数ヵ月前に Vertex AI Studio のやってみた記事を出したところでしたが、今やこういった機能までも日本語で追加されていて、スピード感がすごくついていくのが大変ですが、これからも追いかけていきたいと思います。



