
はじめに
前回 Google Cloud Datastream で構築するデータ分析基盤:構成パターンの解説で構成パターンについて記載してみました。
今回は、ソースデータベースから BigQuery へデータを連携する具体的な設定手順をステップバイステップで紹介します。
手順

今回の手順は図のように Cloud SQL をソースとした BigQuery へのデータ連携の手順となっています。用途に応じて読み替えて参照ください。
事前準備
Datastream はソースデータベース側でバイナリログの出力など、ソースデータベースに応じて設定内容が異なりますので、Google Cloudの公式ドキュメントを参照し、設定します(リンクはMySQLになっています)。
その他にも Datastream の API 有効化や必要なロールは割り当てを行います。
接続プロファイル(ソース編)
1.Datastream のプロファイル作成画面から対象を選択します。
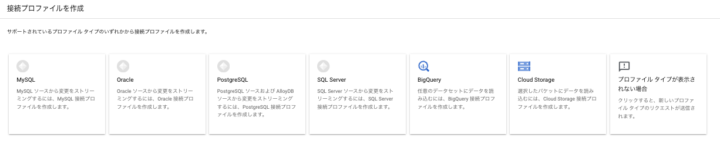
2.接続設定を定義します
- ホスト名 or IP、ポート、ユーザ名、パスワード(Oracle とかだと SID が必要だったりデータベースによって差があります)
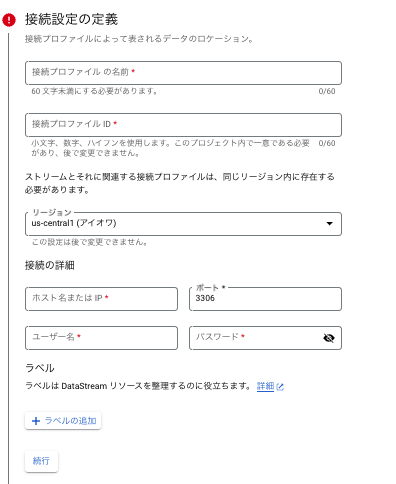
3.ソースへの接続を保護
- 各種暗号化が必要な通信はここで証明書情報をアップロードします
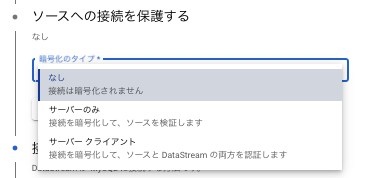
4.ソースへの接続の定義(接続の定義の詳細は前回の記事を参照ください)
- IP許可リストであれば、Datastream のパブリック IP を許可します。
- フォワード SSH トンネルであれば、SSH ユーザ情報と証明書をアップロードします。
- プライベート接続であれば、Datastream の VPC とプロキシーの役割をする GCE がいる VPC とピアリングする接続を選択します。
5.接続テストでテストができればOK
接続プロファイル(デスティネーション編)
1.Datastream のプロファイル作成画面から対象を選択します。
2.Cloud Storage であれば、対象バケットや保存パスの接頭辞を指定し保存対象を定義します。BigQuery であれば、リージョンの定義となります。
ストリーム作成
1.「ストリームを作成」ボタンをクリックして、新しいストリームを設定します。
2.以下のような画面に遷移しますので、それぞれ入力します。
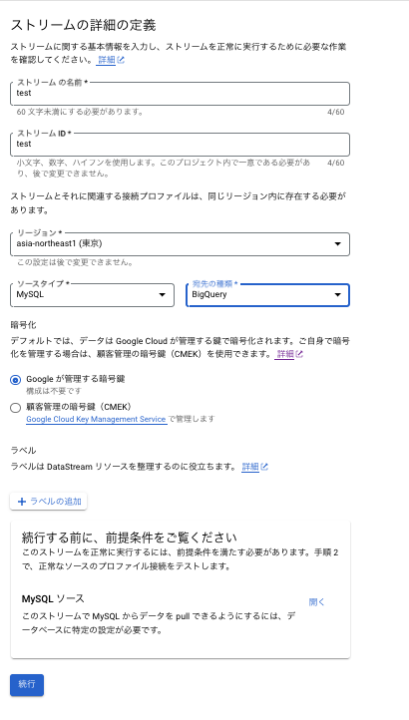
2-1.作成したプロファイルに合わせて、ソースタイプを選択します。
2-2.作成したプロファイルに合わせて、宛先の種類を選択します。
2-3.続行する前に前提条件をご覧ください、の箇所を開くことで事前に設定が必要な内容を閲覧できます(内容としては事前準備に記載したソースデータベース側の設定内容すべき内容を確認できます)
3.先ほど作成したプロファイルを指定して、ソースデータベースの接続プロファイルを定義します
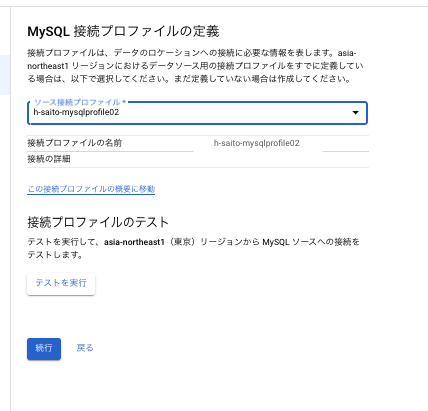
4.次へ遷移すると以下のような画面になります。
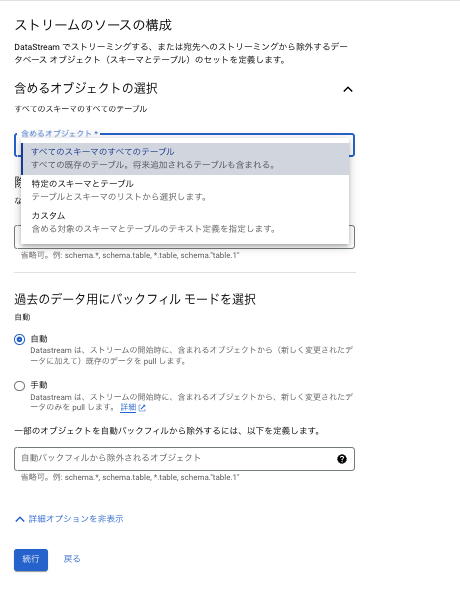
4-1.連携及び除外対象を選ぶことができ、デスティネーションへの連携が不要なテーブルなどは除外しておくことが可能です。
4-2.バックフィルの方法を自動か手動のいずれか指定する形になり、自動はストリーム開始時に対象データをすべて(新しく含まれるデータと既存データ)連携する、手動は差分のみ(新しく変更されたデータのみ)連携する、を選択します。
5.次に宛先のプロファイルを選択します。
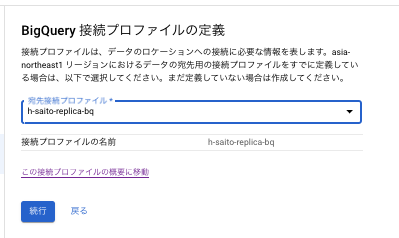
6.次へ遷移すると、以下のような画面になります。
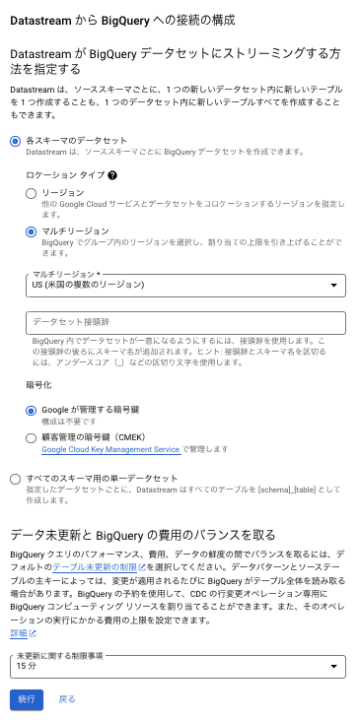
6-1.BigQuery へのストリーミングする方法を「各スキーマのデータセット」か、「すべてのスキーマ用単一のデータセット」を選択をします。「各スキーマのデータセット」を選択すると、データセットをデータベースのスキーマ単位で保存し、テーブル名はソースデータベースと同じテーブル名となります。「すべてのスキーマ用単一のデータセット」を選択すると、保存先のデータセットを選択することができますが、テーブル名は「ソースデータベースのスキーマ名_テーブル名」、という形で保存されます。
6-2.未更新に関する制限事項、の設定を、0、5分、15分、1時間、4時間、8時間、1日から選択可能です。この設定の意味合いとしてはGoogle Cloud の公式ドキュメントの参照をお勧めします。
7.次の画面で確認画面となり、作成とするか、作成後ストリーミングを開始するか、選択することができます。
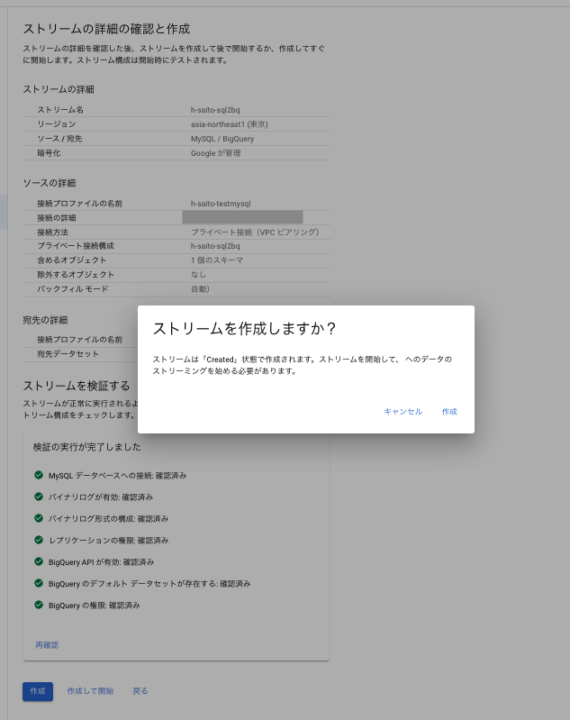
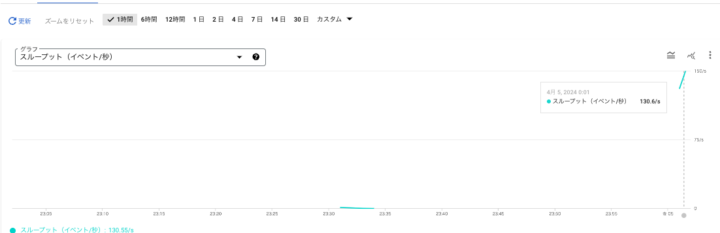
8.実施するとモニタリング画面でスループットのメトリクスに変化があり、ログにも CDC を読み取り、Backfill を行い、テーブルが作成されたことを追うことができ、無事に連携されていることを確認できます。
メトリクス変化
ログ内容

ちなみに Datastream を失敗させてみる
ソースの DB 側でテーブルのカラムの変更があった場合
Datastream の制限(参考までにMySQL)だと、ソースデータベース側の列をドロップする処理や、テーブルの列を中央に入れる処理でデータが破損する可能性があと記載あります。
そしてスキーマ変更として列をドロップしたところ、ストリーミングが見事に失敗しました。
ログにも BigQuery に書き込めなかったよ、のログが出ていました(消しどころ、追加どころの問題?)。
サポートされていないイベントとしてメトリクスが表示される
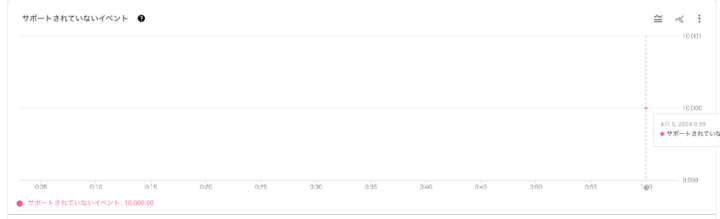
BigQueryへ書き込めないログ

どのように対応するか
もし再作成でも良ければ、、
対象の Datastream を一時停止し、BigQuery 上で対象テーブルを削除します。
そして、Datastream を再開し、対象テーブルの Backfill を実施することで、BigQuery 上で新たなテーブルが作成され、引き続きストリーミングが可能です。
もし再作成がダメでデータの結合などが必要なら、、
既存の BigQuery のテーブルをリネームし、Backfill を実施することで、新たなテーブルが作成されるはずです。必要なら、既存のテーブルと新たなテーブルへのデータ移行やデータ結合をするような運用用途に応じた対応が必要なのかな、と思いました。
まとめ
前回の Datastream の構成パターンと、今回の Datastream の設定手順の2つを書いてみました。
ハードルが高そうな作業でしたが、Datastream というサービスの強力さに助けられ、データ連携することがそこまでハードルが高くなく行えることがわかっていただけたかと思います。
余裕があってもう少し突っ込んで詳細をみていく場合はストリームのライフサイクルを理解し、運用状態や要件に応じてストリームの同時実行制御のチューニングを行いカスタマイズし、それによるストリーミング速度の違いや、負荷状況を見てみると面白いかな、と思います。データ分析に携わる機会があったので、これからも取り組んでいきたいと思います。

