
Google Cloud Next ’24 にて行われたセッション「Real-time operational data streaming for enabling analytics and generative AI apps using Datastream」のレポートです。
Google Cloud Next ’24 とは?
2024 年 4 月 9 ~ 11 日にラスベガスのマンダレイ ベイで開催されている、Google Cloud が主催する最大級規模のイベントです。
https://cloud.withgoogle.com/next/
登壇者
Google Cloud, Head of Products, Databases
Chai Pydimukkala 氏
Google Cloud, Engineering Director, Data Movement
Zeev Suraski 氏
Rocket Money, Director of Data Science and Analytics
Gilbert Watson 氏
セッション内容
従来のデータ分析の課題
従来のデータ分析には以下のような課題があり、理想的なデータ分析ができずビジネスの拡大が停滞していました。
- 組織が異なるデータベースやシステムでデータを管理しているため、統合が非常に難しいこと
- 組織がビジネスの変化に適応できず、迅速な意思決定ができないこと
- 生成AIを使用したアプリケーションを実用化することが難しいこと
Datastreamのメリット
Datastreamを使用することで以下のメリットを得られます。
- シンプルな体験
- ミッションクリティカルなデータが保存されているデータストアから、リアルタイムに取り込みが可能
- BigQueryとのシームレスな統合
- システムやデータベース間の接続についての説明があり、簡単かつ安全である
- サーバーレスでスケーラブル
- デプロイするサーバーや管理するリソースが不要
- データの増加に合わせて低遅延で自動的にスケーリング
- Google Cloudのデータ関連サービスとの統合
- Dataflowがデータを処理するための特別なテンプレート(Kafka、Cloud SQL、Cloud Spannerなど)
- Cloud Logging、Cloud Monitoring、IAM などへの統合
Datastreamの使い方
Datastreamはデータソースの選択、出力先の選択、検証および作成といった数ステップで設定が可能です。
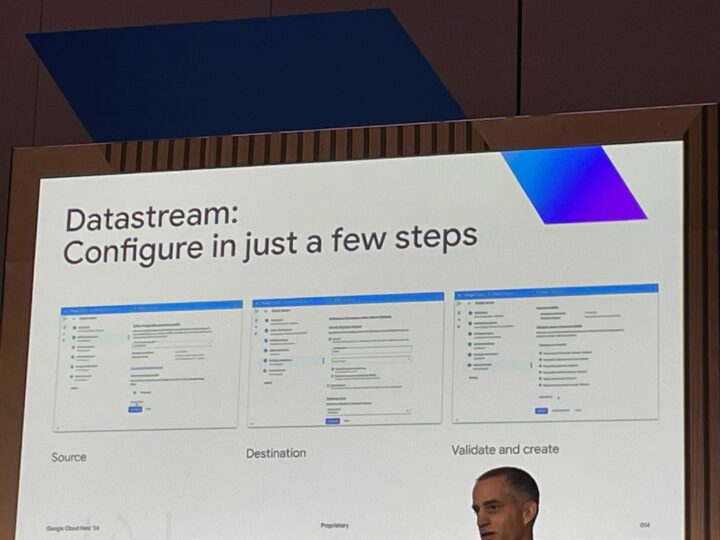
Datastreamは、データベースからデータをBigQueryにレプリケートして、ELT、データ配信、ストリーミングおよびオペレーショナル分析などを可能にするためのフルマネージドのソリューションを提供することができます。

非常に簡単ですが、フルマネージドなのでカスタマイズ性は低いのかなと思いました。
しかし、Dataflow組み合わせることにより、データの処理や変換を柔軟にカスタマイズすることができるため、要件に合わせた設定も可能です。

Rocket Money社の事例
Rocket Money社では、以下のような課題を抱えていたとのことです。

問題:
データはAWS RDSにあるが、次の目的でBigQueryが必要になった
- Lookerでの分析のサポート
- AI/MLモデルの開発とバッチ実装のサポート
- CRMメッセージングを強化するリバースETLプロセスのサポート
他社クラウドを使用していても、分析にはBigQueryを使いたいというのはありがちな状況ですね。
この問題のソリューションとして、従来では以下のような方法で実現する必要がありました。

- Auroraバックアップ スナップショットを作成
- S3へのエクスポート
- Data TransferなどによるGoogle Cloud Storageへのデータ読み込み
- Cloud StorageからBigQueryへの読み込み
毎日60 TB以上のデータがあり、これを処理するには8時間かかる場合もあれば、72時間かかる場合もあったとのことです。時間が長すぎて、ちゃんと完了するかの保証がないので不安定な状態ですね。
これに対して、Datastreamを使用した場合は以下の方法で実現できます。

- レプリケーションスロットのようなAuroraからの継続的な変更の検知
- BigQueryへの継続的な書き込み(BigQuery への反映までの遅延時間も設定可能)
この変更だけで60 TB以上のデータ処理が1日あたり最大130MB まで削減できています。
比較すると削減率は99%以上で、BigQueryへのデータの到着タイミングも90%以上改善されたとのことでした。
上記から、Datastreamを使用することで以下のメリットを得られたとまとめています。
- データの到着タイミング
- BigQuery内のデータの最大遅延時間がソースDBに対して設定可能であるため、リバースETLのユースケースにおいて高い精度を確保できる
- コスト
- データベースのエクスポートのバッチ処理から脱却したことで、コストを50%以上削減できた
- 管理のシンプルさ
- 簡単なセットアップと構成が可能で、データ保管場所が1つ減っているため、セキュリティも向上している
- 部分的なバックフィル
- 他ツールでは提供していない、特定の範囲のみのデータ再処理が可能
感想
Datastreamを使うことのメリットについて事例を含めて紹介いただきました。
リアルタイムの分析と聞くとコストは上がるのではないかと思っていたのですが、処理にかかる時間の削減やシンプルな構成となることから、大幅にコスト削減ができることに感心しました。
実際に私も従来の方法でデータエクスポートなどを行っていたのですが、簡単な設定方法で他サービスとの統合など親和性も高いため、Datastreamを積極的に使用していきたいと思いました。


