
概要
最近、LangChain に興味を持っており、「いろんな機能に触れつつ、LangChain に詳しくなっていければいいな」との思いから本記事を執筆しました。 LangChain 初心者ではあるので、知識不足な点は色々とありますが、温かい目で見ていただけますと幸いです🙇♂️
LangChain とは
全体像と、使用することのできる機能についてはLangChain 学習記①〜全体像を理解する〜をご覧ください。
LangChain を使って簡単なRAGを試してみる
LangChain の中の、「Retrieval」という機能の中の、「VectorStore」という機能を使用し、
PDF 文書を読み込んでその内容に基づいた回答を生成させる ということをしてみたいと思います。
今回は
令和5年版 労働経済の分析-持続的な賃上げに向けて- と、令和4年版厚生労働白書(令和 3 年度厚生労働行政年次報告)―社会保障を支える人材の確保―をLLMに与えた上で、二つの記事の違いについて回答してもらう、ということを試してみました。
全体像の整理
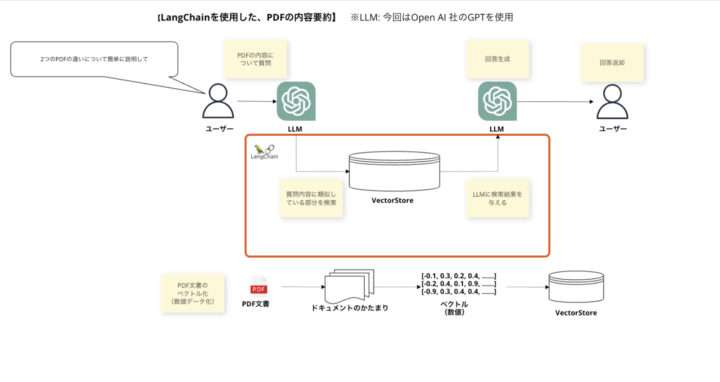
今回行うことは、以下のようなステップに整理できます。
1. ユーザーが質問をする
ユーザーが投げた質問が、LLM(今回はGPT)に渡ります。
2. PDF の内容をかたまりに分割、ベクトル化して VectorStore に保存
ユーザーから提供された PDF ファイルを、VectorStore に保存します。膨大な内容をそのまま保存することは不可能なので、細かいかたまりに区切って保存します。
また、LLM が利用しやすいようにベクトル化(数値化)して VectorStore に保存します。
3. VectorStore の中身から質問内容の回答に近しい内容を抽出し、それを LLM に渡す
質問内容に対する検索結果が抽出され、それが LLM のプロンプトにセットされます。
4. LLM が、VectorStore から渡された検索結果を元に回答を返却する
LLM は自身の持っている情報と、プロンプトに埋め込まれた、VectorStore から渡された検索結果を踏まえて、回答を生成・返却します。
コード
前提
①下記のライブラリをインストールする
pip install pymupdf langchain_community langchain_core langchain_openai
※ライブラリの簡単な説明
- pymupdf
- PDF からテキスト抽出を行うライブラリ
- ライブラリ名は pymupdf だか、import するときは fitz という名前でするらしい
- langchain_community
- langchain 関連の機能を使用する際に使うライブラリ
- langchain_openai
- langchain と openai を連携させる際に使用するライブラリ
②OPENAI_API_KEY の環境変数の設定
OpenAI 社の API を利用するために環境変数を設定します。
いろいろな方法があると思いますが、今回はexport OPENAI_API_KEY="XXXXXXXX"という形で環境変数を設定し、os.getenv('OPENAI_API_KEY')でコード内での API キーの読み込みを行っています。
# rag_sample.py
import os
import fitz
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_openai import OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai import ChatOpenAI
# 環境変数から API キーを取得
openai_api_key = os.getenv('OPENAI_API_KEY')
# PDF ファイルからテキストを抽出する関数
def extract_text_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
text = ""
for page in doc:
text += page.get_text()
return text
# PDF ファイルのパスを指定
pdf_paths = ["(PDFファイルへのパス)"]
# PDF からテキストを抽出
texts = [extract_text_from_pdf(pdf_path) for pdf_path in pdf_paths]
# 埋め込みモデルを初期化
embedding_model = OpenAIEmbeddings(api_key=openai_api_key)
# 抽出したテキストから埋め込みを作成
embeddings = [embedding_model.embed_documents(text) for text in texts]
# ベクトルストアを作成し、テキストを格納
vectorstore = DocArrayInMemorySearch.from_texts(texts, embedding=embedding_model)
# Retriever を設定
retriever = vectorstore.as_retriever()
# テンプレートとプロンプトを定義
template = """次の情報を参照して質問に答えてください
参照する情報: {reference_info}
質問: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# モデルを初期化
model = ChatOpenAI(model="gpt-4-1106-preview", temperature=0)
# OutPutParserを定義
output_parser = StrOutputParser()
# 参照する情報の取得と、質問の取得
query_and_retrieval = RunnableParallel(
{"reference_info": retriever, "question": RunnablePassthrough()}
)
#chain の定義
chain = query_and_retrieval | prompt | model | output_parser
# ユーザーの質問
user_question = "二つのPDFファイルの違いを簡単に説明して"
#chainの実行
result = chain.invoke(user_question)
print("結果:")
print(result)
解説
ざっくり、コード内で行われている処理をまとめます。
①PDF の文書からテキスト抽出
以下の部分で、pypdf というライブラリを使用し、指定されたパスに存在する PDF 文書からテキストの抽出を行っています。
# PDF ファイルからテキストを抽出する関数
def extract_text_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
text = ""
for page in doc:
text += page.get_text()
return text
# PDF ファイルのパスを指定
pdf_paths = ["(PDFファイルへのパス)"]
# PDF からテキストを抽出
texts = [extract_text_from_pdf(pdf_path) for pdf_path in pdf_paths]
②抽出されたテキストを使って Embedding(埋め込み)の作成、VectorStore への保存
Embedding とは簡単に表すと、ベクトル化された(数値化された)テキストといえます。
この部分で、テキストが数値に変換され、VectorStore に保存されます。
# 埋め込みモデルを初期化 embedding_model = OpenAIEmbeddings(api_key=openai_api_key) # 抽出したテキストから埋め込みを作成 embeddings = [embedding_model.embed_documents(text) for text in texts] # VectorStore を作成し、テキストを格納 vectorstore = DocArrayInMemorySearch.from_texts(texts, embedding=embedding_model)
③Retriever の作成
as_retriever()というメソッドを使用して、VectorStore に対してどのような形で検索を行うかを指定しています。
retriever = vectorstore.as_retriever()
as_retriever メソッドの中身をみてみると、下記のような形になっています。
引数にの search_type にある、
Can be “similarity” (default), “mmr”, or
“similarity_score_threshold”.
という部分で、similarity、mmr、similarity_score_threshold という3つの検索方法が指定できると記載があります。デフォルトではsimilarity という、質問の内容に最も近い内容を検索してくれる検索方法(類似性検索)が指定されています。
詳細が気になる方はこちらの記事を参照ください。
def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:
"""Return VectorStoreRetriever initialized from this VectorStore.
Args:
search_type (Optional[str]): Defines the type of search that
the Retriever should perform.
Can be "similarity" (default), "mmr", or
"similarity_score_threshold".
search_kwargs (Optional[Dict]): Keyword arguments to pass to the
search function. Can include things like:
k: Amount of documents to return (Default: 4)
score_threshold: Minimum relevance threshold
for similarity_score_threshold
fetch_k: Amount of documents to pass to MMR algorithm (Default: 20)
lambda_mult: Diversity of results returned by MMR;
1 for minimum diversity and 0 for maximum. (Default: 0.5)
filter: Filter by document metadata
Returns:
VectorStoreRetriever: Retriever class for VectorStore.
Examples:
.. code-block:: python
# Retrieve more documents with higher diversity
# Useful if your dataset has many similar documents
docsearch.as_retriever(
search_type="mmr",
search_kwargs={'k': 6, 'lambda_mult': 0.25}
)
# Fetch more documents for the MMR algorithm to consider
# But only return the top 5
docsearch.as_retriever(
search_type="mmr",
search_kwargs={'k': 5, 'fetch_k': 50}
)
# Only retrieve documents that have a relevance score
# Above a certain threshold
docsearch.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={'score_threshold': 0.8}
)
# Only get the single most similar document from the dataset
docsearch.as_retriever(search_kwargs={'k': 1})
# Use a filter to only retrieve documents from a specific paper
docsearch.as_retriever(
search_kwargs={'filter': {'paper_title':'GPT-4 Technical Report'}}
)
"""
tags = kwargs.pop("tags", None) or []
tags.extend(self._get_retriever_tags())
return VectorStoreRetriever(vectorstore=self, **kwargs, tags=tags)
④LLM に投げる質問のテンプレートとプロンプトを定義
LLM が検索情報を参考にして回答を生成できるように、質問のテンプレートと質問文を準備しています。
また、この部分でどの LLM のモデルの使うのか、回答の振る舞い方を指定しています。
temperature は回答のランダム性を指定する値で、0以上1以下の値で指定します。
(※0を指定すると毎回同じ回答になります。)
# テンプレートとプロンプトを定義
template = """次の情報を参照して質問に答えてください
参照する情報: {reference_info}
質問: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# モデルを初期化
model = ChatOpenAI(model="gpt-4-1106-preview", temperature=0)
⑤OutputParser の定義
# OutputParser を定義 output_parser = StrOutputParser()
OutputParser とは、LLM が出力した回答を指定した形に変換、加工する処理を行う役割を担うものです。
その中でも、StrOutputParser とは、回答を文字列に変換してくれるものです。
他にも、OutputParser には色んな種類があるようです。興味のある方はこちらをご覧ください。
⑥参照情報の取得と、質問の取得
# 参照する情報の取得と、質問の取得
query_and_retrieval = RunnableParallel(
{"reference_info": retriever, "question": RunnablePassthrough()}
)
プロンプトに埋め込まれている{reference_info}と、{question}の値を辞書型で指定しています。
{reference_info}ではretriever(VectorStoreに格納されている、情報の検索結果)を、
{question}ではユーザーの質問(chain.invoke()が実行された際の引数)をそのまま指定しています。
(RunnningPassthrough()についてはこちらをご参照ください。)
⑦chain の定義
chainが実行される際、どのような処理を行うかを定義している部分です。
#chain の定義 chain = query_and_retrieval | prompt | model | output_parser
見慣れない記法がありますが、これはLCEL(LangChain Expression Language)という、LangChainにおける処理を連鎖的に実行するための記法のようです。
Linux コマンドで使われるパイプと同じような考え方のようです。
ざっくり説明すると、chain が実行される際、以下のような形で処理が立て続けに実行されます。
query_and_retrieval の処理が行われる →query_and_retrieval での処理結果が prompt に渡される →prompt での処理結果が model に渡される →model の処理結果が output_parser に渡される →output_parser の処理が行われる
⑧chain の実行と結果の出力
⑦で定義されたc hain が、chain.invoke()によって呼び出され、実行されます。
# ユーザーの質問
user_question = "二つの PDF ファイルの違いを簡単に説明して"
result = chain.invoke(user_question)
print("結果:")
print(result)
結果
質問に対する回答は下記のようになりました。
PDF データを踏まえて回答の生成がされ、目的であった RAG を実現することができました。
いい感じに要約もしつつ、質問内容である「2つの PDF ファイルの違いの説明」もしてくれているようです。
結果: 二つの PDF ファイルは異なる内容の報告書であり、それぞれ厚生労働省が発行した異なる年度の報告書です。 1. 最初の PDF ファイルは「令和5年版 労働経済の分析 -持続的な賃上げに向けて-」というタイトルの報告書であり、賃金の動向、賃上げの現状と課題、賃上げによる企業や労働者への好影響、企業と賃上げの状況、スタートアップ企業と賃金の関係、転職によるキャリアアップや正規雇用転換と賃金の関係、最低賃金制度や同一労働同一賃金の政策による賃金への影響などについて分析しています。 2. 二つ目の PDF ファイルは「令和4年版 厚生労働白書(令和3年度厚生労働行政年次報告)-社会保障を支える人材の確保-」というタイトルの報告書であり、医療・福祉サービス提供の担い手の確保が最重要課題であること、医療・福祉就業者数の推計、医師や看護職員などの人材確保に関する取り組み、介護職員や保育人材の処遇改善、地域共生社会の取り組み、多様な人材の確保や参入促進、ロボットや ICT の活用などについて述べています。 要するに、最初のPDFは賃金と労働経済に焦点を当てた報告書であり、二つ目の PDF は医療・福祉分野の人材確保と社会保障制度の持続可能性に関する報告書です。それぞれ異なるテーマに基づいており、対象とする内容と目的が異なります。
注意点
OpenAI の利用料金にご注意
使用するモデルによって、トークンあたりの利用料金がかかるので利用する際は注意が必要です。
※OpenAI の料金体系についてはこちら参照
使用するモデル、文書の内容の多さによってはトークンの長さ制限に引っかかることがある
初めは、使用する OpenAI のモデルとして、gpt-3.5-turbo を使用していましたが、
トークン数の制限に引っかかってしまいました。選択肢としては
- トークンを減らす(使用する文書を変更する)
- トークン使用上限が多い上位のモデルを使用する
が考えられると思ったため、
OpenAI の公式ドキュメントを見て、今回は128000トークンまで利用可能な gpt-4-1106-preview(学習データは2023年9月まで)を使用するようにしたら、解決しました。
# モデルを初期化(失敗時) model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# トークン数の上限エラー
openai.BadRequestError: Error code: 400 - {'error': {'message': "This model's maximum context length is 16385 tokens. However, your messages resulted in 24305 tokens. Please reduce the length of the messages.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
※こちらの記事によれば、
map_reduce や、refine といった方法を使うことで、LLM に渡るトークン長が制限を超えることを防ぐ工夫もできるようです。今回は LangChain 公式にもmap_reduce や、refine についての記事があったので、機会があれば学習してみたいなと思います。
Vector Storeの仕組みについて
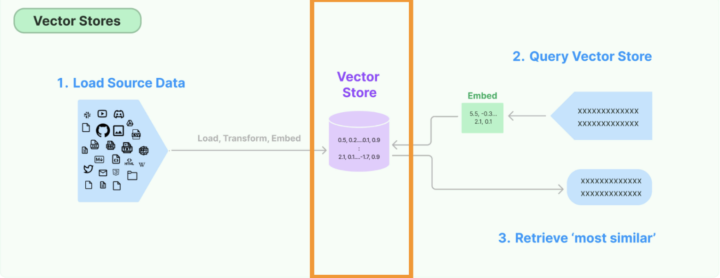
(LangChain公式から引用)
Langchain の機能の中に、VectorStore という機能があります。
Langhchain 公式の説明は下記です。
One of the most common ways to store and search over unstructured data is to embed it and store the resulting embedding vectors, and then at query time to embed the unstructured query and retrieve the embedding vectors that are ‘most similar’ to the embedded query. A vector store takes care of storing embedded data and performing vector search for you.
ざっくりまとめるとこんな感じです。
- 文章や画像などのデータをベクトル化(数値に変換)して、VectorStoreという、データベースのようなものに保存する
- そうすることで、LLM(言語モデル)がデータを扱いやすいようになる
- 単語の意味の近さを、ベクトルの関係性で表現している
- 厳密にはコサイン類似度という考え方が使われているようです。(ここでは詳細については触れません。興味のある方は以下記事がわかりやすいのでそちらをご覧ください。
- LLM に投げられた質問に関連する部分を VectorStore の中から検索し、それを LLM に与えてあげることで、LLM が検索結果を踏まえた回答を生成することができる
最後に
今回は簡単な RAG を実装してみました。
機械学習に関する深い知識がなくても、比較的容易に RAG の仕組みを構築できるな、と感じました。
とはいえ、内部的な仕組みを深く理解しようとすると労力がかなりかかりそうだな、という印象でした。
今回、「VectorStore」というベクトルデータベースの概念が出てきましたが、その仕組みにおいて、高校時代・大学時代の講義で学習したベクトルの仕組みが使われていて個人的には興味深かったです。
LangChain の中には非常にたくさんの機能があり、使いこなすのは大変そうではありますが、引き続き情報をキャッチアップしていけたらと思っています。
個人的にはStreamlitと LangChain を連携させたアプリケーション構築に興味があるので、次回はアプリケーションを作成してみた記事を書いてみようと思います。(記事によるとたった18行のコードで LLM 搭載アプリケーションが構築できる?とあったので気になっています)
参考文献
★ブログ記事・公式サイト
https://zenn.dev/umi_mori/books/prompt-engineer/viewer/langchain_overview
https://qiita.com/ysv/items/82dd14ae7a1328ef5ee2
https://happy-nap.hatenablog.com/entry/2023/02/11/220235
https://dev.classmethod.jp/articles/gpt-4-turbo-api-long-tokens/
https://qiita.com/ksonoda/items/ba6d7b913fc744db3d79
https://qiita.com/sakabe/items/5f14999ded1de087c9b5
https://zenn.dev/peishim/articles/c696ff85a539bd
https://python.langchain.com/v0.1/docs/expression_language/primitives/parallel/
https://blog.serverworks.co.jp/langchain-runnable-memo-1#RunnablePassthrough
https://qiita.com/cyberBOSE/items/fd65de9f857d36180fa5
★厚生労働省統計資料
「令和5年版 労働経済の分析」
https://www.mhlw.go.jp/content/12602000/001149098.pdf
「令和4年版厚生労働白書」
https://www.mhlw.go.jp/content/000988388.pdf
