
まえがき
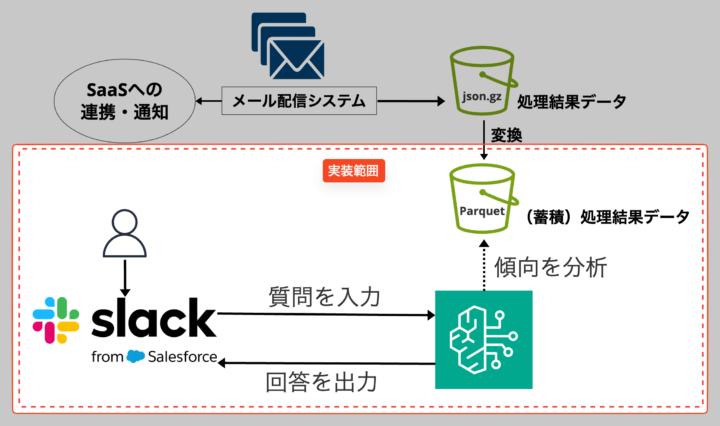
弊社では、1日約1万件のメールを受信しており、その中から重要な内容を迅速に見つけ出すための「社内メール通知統合システム」を社内向けに提供しています。このシステムでは、受信した大量のメールからフィルタ条件に一致するものを抽出し、他のSaaS(PagerDuty、Slack、Backlogなど)へ連携しています。
「社内メール通知統合システム」の事例ご紹介
https://cloudpack.jp/casestudy/209.html
そして「社内メール通知統合システム」で処理されたすべての処理結果データはS3にjson.gz形式で保存し、Athenaで安価・高速にクエリするためにParquet形式へ変換・蓄積しています。
なぜParquet形式がクエリコストの削減と高速化に寄与するのか?
その理由については、こちらの資料で詳しく解説しています。
今回は、これらの処理結果データを効率的に分析する方法を模索する中で、フルマネージドサービスな生成AIサービスであるAmazon Bedrockを活用したシステムを試験的に開発しました。
Slackから質問を入力すると、Amazon Bedrockで処理結果データを傾向分析し、その結果をSlackへ回答として出力することで、メールの傾向を迅速に把握できるようにすることを目指しています。
しかし、正確な回答を得るためには、質問内容やデータに応じた適切なプロンプト設計が重要です。
プロンプトエンジニアリングとは?
ここで、プロンプトエンジニアリングとは何かについて簡単に解説します。
プロンプトエンジニアリングとは、生成AIに対して適切な応答を引き出すための指示や質問を工夫して設計する技法のことです。これにより、より正確で有用な結果を得ることができます。
例えば、AWSのプロンプトエンジニアリングに関するガイドでは、明確なフォーマットの指定や前提条件の提供などが紹介されています。
この記事では、Parquet形式で蓄積された大量の処理結果データをどのようにAmazon Bedrockで分析したのか?実装方法の他にも、プロンプトエンジニアリングを活用しAthenaクエリの生成や結果分析にどのように役立てたかについても解説します。
技術選定
当初、大量の処理結果データを傾向分析するためにKnowledge Bases for Amazon Bedrockの導入を検討していました。
Knowledge Bases for Amazon Bedrockでは、分析したいデータをソースとして指定することで、ユーザーが自然言語で質問を投げ、膨大なデータの中から情報を抽出し、洞察を得ることが可能です。
この機能を使うことで、手動の分析作業を大幅に削減できると考えていました。
Parquet形式の制約
しかし、今回の処理結果データは分析用にParquet形式で蓄積しており
Knowledge Bases for Amazon Bedrockでは、Parquet形式のデータをソースとして指定できませんでした。
そのため、Amazon Bedrockで適切に分析を実施するには、クエリを使った処理結果データの前処理や抽出が必要になりました。
この制約を踏まえ、Slackからの質問に基づいて動的にAthenaクエリを生成し、その結果をAmazon Bedrockで分析するアプローチを採用しました。
この方法により、既存のデータフォーマットを維持しつつ、迅速で柔軟なデータ分析を実現できます。
Knowledge Bases for Amazon Bedrock利用時の注意点
Knowledge Bases for Amazon Bedrockの2024年8月15日時点のサポート情報に基づく対応データ形式は以下の通りです。
これ以外のソースデータである場合は利用が不可能のため注意が必要です。
| サポートしている形式 |
|---|
| .txt |
| .md |
| .html |
| .doc/.docx |
| .csv |
| .xls/.xlsx |
実際に作った “生成AI Slackbot”
このアプローチを基に、Slackを通じてユーザーからの質問を受け取り、それに基づいて社内処理結果データを分析し、結果を再びSlackで返答する生成AI Slackbotを作成しました。
“生成AI Slackbot”の構成図
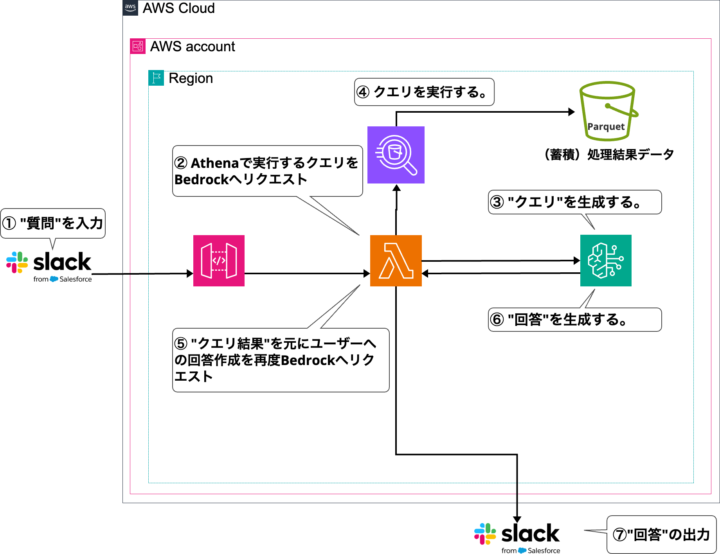
構成図にかかれている具体的な流れを纒めると以下のような7つ処理になっております。
| 処理No | 処理内容 | 詳細 |
|---|---|---|
| ① | 質問の入力 | ユーザーはSlack上からメンション付きで社内メールに関する質問を入力します。 |
| ② | Athenaで実行するクエリをBedrockへリクエスト | 質問はAPIGatewayを通じて受信され、Lambda関数に送信されます。 このLambda関数は、Slackメンションで受信した「質問」と、予めソースコード記述されているプロンプト(命令)をAmazon Bedrockに送信します。 |
| ③ | クエリ生成 | Amazon Bedrockは、プロンプトに従ってAthenaクエリを生成します。 |
| ④ | クエリ実行 | Lambda関数は、Amazon Bedrockで生成されたクエリをAthenaに送信し、実行します。 |
| ⑤ | クエリ結果を元にユーザーへの回答作成を再度Bedrockへリクエスト | Lambda関数は、Slackメンションで受信した「質問」、クエリ実行結果、およびプロンプト(命令)を再度Amazon Bedrockに送信します。 |
| ⑥ | 回答生成 | Amazon Bedrockは、プロンプトに基づいて最終的な回答を生成します。 |
| ⑦ | 回答出力 | 分析結果と社内処理結果データの集計がSlackに出力され、ユーザーに回答として返されます。 |
実装手順は以下の通り進めました。
実装
前提条件として、Athena分析環境が既に存在していることを前提とします。
※Amazon BedrockではClaude 3 Sonnetを採用しています。
Lambda関数のソースコード全文
(1) Amazon BedrockとSlackを連携するサンプルAppのデプロイ
AWS公式ブログ「Deploy a Slack gateway for Amazon Bedrock」で紹介されているサンプルAppをデプロイし、これをベースに処理結果データを分析するSlackbotを作っていきます。
一部ですが手順通りにいかない箇所がありましたので、弊社の高橋(修)による記事「Amazon Bedrockで社内情報を参照する生成AI Slackbotを簡単に作成」を参考に構築しました。
こちらの参考記事では、SlackとAmazon Bedrockを連携させるための手順が詳しく説明されており、役立ちました。
(2) Lambda実行ロールにIAMポリシーを付与する
「(1) Amazon BedrockとSlackを連携するサンプルAppのデプロイ」が完了すると、Lambda関数(Python 3.12ランタイム)が作成されます。
Lambda関数を選択し、「設定」タブから「アクセス権限」を開くとLambda実行ロールが確認できます。
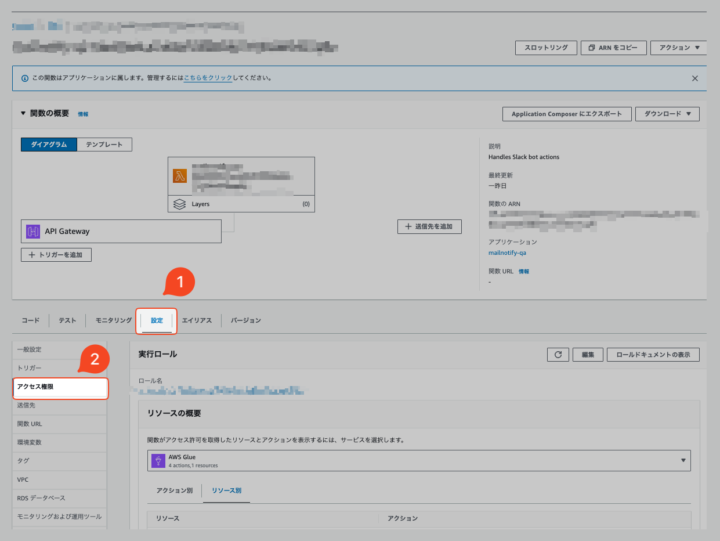
以下のIAMポリシーを新規作成し、Lambda実行ロールに紐づけることで、Athena分析環境へLambdaがアクセスできるようにしました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"athena:StartQueryExecution",
"athena:GetQueryExecution",
"athena:GetQueryResults"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:CreateBucket",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::{Athenaクエリ結果保存用S3バケット名}",
"arn:aws:s3:::{Athenaクエリ結果保存用S3バケット名}/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::{処理結果データ格納用S3バケット名(Parquet形式)}",
"arn:aws:s3:::{処理結果データ格納用S3バケット名(Parquet形式)}/*"
]
},
{
"Effect": "Allow",
"Action": [
"glue:GetTable",
"glue:GetTables",
"glue:GetDatabase",
"glue:GetDatabases"
],
"Resource": "*"
}
]
}
(3) クエリを生成するためのプロンプトを記述
補足
・ここでは、ユーザーが入力した質問から開始日と終了日を抽出し、その期間に基づいてクエリを実行するようにAmazon Bedrockにリクエストしています。
・なお、この段階では日付以外の条件を設定せず、質問の内容に応じた具体的な分析は次の「(4) クエリ結果と質問を分析するプロンプトの作成」で行っています。
ソースコードを編集し、Amazon Bedrockへリクエスト送信する際に必要なプロンプト(命令) を書いていきます。
これにより、Amazon Bedrockはgenerate_query_promptに格納されているプロンプトに従って分析されます。
# ここでは、Athenaクエリを生成するためのプロンプトを定義しています。
# Slackからの質問に基づいて動的に日付を設定し、指定された期間内のデータを取得するクエリを構築します。
generate_query_prompt = f"""
・次のAthenaクエリを作成するために、指定された形式に従って開始日と終了日を設定してください。
SELECT
"from",
mail_id,
subject,
ses_timestamp
FROM
message
WHERE dt >= '{{start_day}}'
AND dt <= '{{end_day}}'
・SlackAppから入力された質問{{query_text}}から開始日と終了日を読み取って、上記のAthenaクエリの{{start_day}}と{{end_day}}にそれぞれ代入してください。
'query_text'の内容はこちらです→→ {query_text}
・SlackAppから入力された質問{{query_text}}に開始日や終了日の記載がない場合、例えば直近や最近のデータを取得する場合は、以下のように指示してください。
・本日({datetime.now().strftime('%Y-%m-%d')})の日本時間を起点として開始日と終了日を設定してください。
e.g. 「直近2週間」ならば、本日から2週間前までの期間を設定してください。
・本日({datetime.now().strftime('%Y-%m-%d')})の日本時間である当日はデータが存在しないです、そのため基本的に分析可能範囲は昨日までの日時を使用してください。
・出力形式:
生成されたAthenaクエリのみを出力してください。前置きや説明文を追加しないでください。
"""
# Bedrockにプロンプト(命令)を投げてクエリを取得
bedrock_response = call_bedrock(generate_query_prompt)
# クエリを直接取得
query = bedrock_response.strip()
プロンプトエンジニアリングによるチューニングポイント
generate_query_prompt内には以下の3つの指示を含めることで、Amazon BedrockにAthenaクエリを正確に生成させています。
1. Athenaクエリのテンプレートを定義
{start_day}と{end_day}というプレースホルダーを設定し、クエリの基本構造を定義します。
2. Slackの質問内容に基づく日付の抽出
- Slackからの質問内容から開始日と終了日を読み取り、
{start_day}と{end_day}というプレースホルダーに代入
3. 日付が指定されていない場合の対応
- Slackからの質問内容開始日や終了日の指定がない場合は、当日の日付を起点にして日付を設定する
- 例として「直近2週間」という表現があった場合には、現在の日付から2週間前までの期間を設定する
(4) クエリ結果と質問を分析するようプロンプトを記述
ソースコードを編集し、Amazon Bedrockにクエリ結果を分析させるためのプロンプト(命令) を作成します。
このプロンプトは、analysis_promptに格納され、Bedrockはそれに従って分析を実行します。
# Athenaクエリ結果に基づき、指定された期間内の処理結果データを分析するためのプロンプトを定義します。
# このプロンプトにより、Amazon Bedrockに正確な分析を指示します。
analysis_prompt = f"""
・言語は日本語で出力してください。
・以下のフォーマットに従って、「参照期間」と「分析結果」の項目のみを回答として出力してください。
参照期間:
{query.split("AND dt >= ")[1].split("'")[1]}〜{query.split("AND dt <= ")[1].split("'")[1]}
分析結果:
ここに分析した結果を出力する。
分析方法と観点:
(1) 以下のAthenaクエリ結果をそのまま使用してください。データに変更や追加を加えないでください。
<Athenaクエリ結果開始>
{formatted_results}
<Athenaクエリ結果終了>
(2) (1)のAthenaクエリ結果をソースデータとして、{query_text} の分析結果を出力してください。
(3) mail_idのカラムを確認し重複している場合はカウントしない。カウント・集計結果を検算して一致するかも確認してください。
"""
# Bedrockにプロンプト(命令)を投げて洞察を取得
msg = call_bedrock(analysis_prompt)
プロンプトエンジニアリングによるチューニングポイント
analysis_prompt内にも以下の5つの指示を含めることで、Amazon Bedrockにクエリ結果に基づき質問内容の洞察した分析結果を正確に生成させています。
1. 日本語での出力指定
- 出力言語を明確に指示することで、言語の齟齬を避け、正確な出力を保証します。
2. フォーマット指定
- 分析結果の出力フォーマットを指定し、参照期間と分析結果の形式を固定することで、一定のフォーマットでデータが出力されるようにします。
3. クエリ結果に変更を加えない
- クエリ結果そのままを使用するよう指示し、データの改ざんや誤操作を防ぎます。
4. Slackで入力された質問内容に基づく分析結果の出力
- 質問内容に即した分析を行うように指示し、出力結果が質問の意図に沿ったものであることを保証します。
5. 重複の排除と検算
- 処理結果データが持つ一意なmail_idの重複排除を指示します
- カウント・集計結果が正しいか検算させることで、データの信頼性を確保します。
(5) Lambdaのデプロイ
(1)~(4)までの内容を更新し再度Lambda関数をデプロイする。
Slackより@メンション+質問を入力することで、回答が出力されることを確認します。
実装の振り返りと今後の展望
今回のプロジェクトを通じて、プロンプトエンジニアリングの重要性とその難しさを実感しました。
Athenaクエリの生成や結果分析において、プロンプト設計が成果に大きく影響することが分かりました。
プロンプトを細かく調整することで精度を向上させることができましたが、まだ完全ではなく、日本語の微妙な表現によっては、正しい期間を算出できない場合や、生成AIの集計結果に狂いが生じることもあります。
そのため、現状ではAthena実行クエリのURLを生成し、最終的な検算を問い合わせ担当者に依頼する運用にしています。
今回は試していませんが、プロンプトエンジニアリングのチューニング技法として他に、ファインチューニングなどの事前学習する方法もありました。
こちらは試せていないので今後の課題としてやっていきたいなと思っています。
また、Parquet形式の処理結果データもKnowledge Bases for Amazon Bedrockが直接利用できないという制約がありながらも、代替のアプローチを駆使して実装することができた点は、大きな学びとなりました。
生成AIの分野は非常に奥が深く、引き続き学び続けることが必要だと感じました。


