
社内情報を活用した生成AI Slackbotを作ってみます。
Amazon BedrockとSlackを連携するサンプルがAWS公式ブログ「Deploy a Slack gateway for Amazon Bedrock」で紹介されていました。今回はこれをベースに「社内情報ナレッジベース(RAG)の参照」が行えるよう実装を変更していきます。
ついでに以下の改善も含めています。
- 参照元となったソースへのリンクを回答に含める
- サンプルでは1つの質問に対し重複した回答送信が頻発するので抑制する
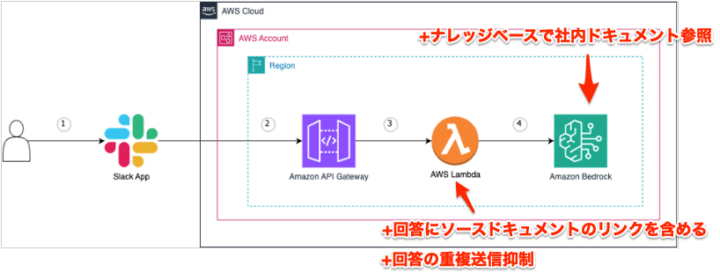
今回の流れ
- ① サンプル環境(AMAZON-BEDROCK-SLACK-GATEWAY)の構築
- ② 社内情報からナレッジベース(Knowledge Bases for Amazon Bedrock)を作成する
- ③ ナレッジベースを参照した回答が得られるよう実装変更
本記事では③をメインとし、①〜②については参考記事の紹介と簡単な解説にとどめます。
① サンプル環境(AMAZON-BEDROCK-SLACK-GATEWAY)の構築
「Deploy a Slack gateway for Amazon Bedrock」に構築方法が記載されているので基本的にはこれを進めるだけでOKです。ただし1箇所手順を変える必要があったのでその点も記載します。
元記事では以下の流れで手順が書かれています。
- 前提条件の確認
- Slackアプリの作成
- CloudFormationでAWS側のAPI+バックエンド構築
- Slackアプリと作成したAPIの紐付け
- テスト
詳細な手順があり、AWS側の構築もCloudFormationテンプレートが用意されているので試しやすいです。
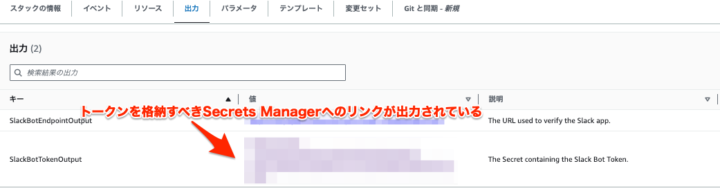
手順の中に「作成したSlackアプリのトークンを、CloudFormationスタック作成時にパラメータとして指定する記載」があります。しかし2024年6月27日の時点ではスタック作成時にこのパラメータを入れる箇所がありませんでした。代わりにスタック作成完了後にできあがるSecrets Managerに手動でトークン登録する必要があります。
記事上の手順
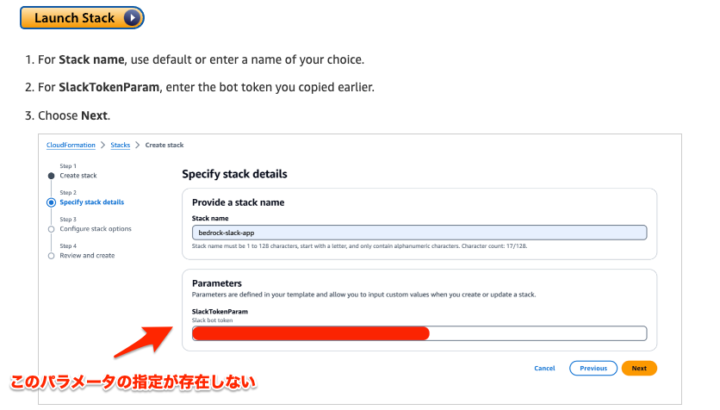
実際に行った手順
- Stackの出力に「SlackBotTokenOutput」という名前でSecrets Managerへのリンクが定義されているのでクリック
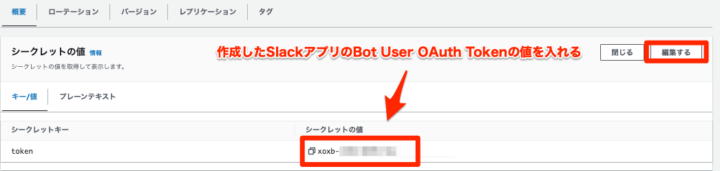
2.Secrets Managerに保存しているトークンを書き換える
② 社内情報からナレッジベース作成
ナレッジベースの作成方法については本記事では解説しませんが、KAGみのるんさんのAWSの生成AIで社内文書検索! Bedrockのナレッジベースで簡単にRAGアプリを作ってみよう「2. ナレッジベース作成編」の手順がとてもわかりやすくまとまっていました。
また今回は回答の根拠となった社内文書の実際のリンクを回答に入れ込みたいので読み込ませる文書にあわせ以下のようなメタデータを作成しておきます。こちらはソースドキュメントと同じフォルダ内に格納して読み込ませます。
{
"metadataAttributes": {
"title": title,
"src-uri": src_uri,
"category": category
}
}
- title:ソースドキュメントのタイトル。リンク名に使います。
- src-uri:ソースの実際の所在uri。リンク先として使います。
- category: ソースのカテゴリ。今回はリンク名のプレフィックスに使います。
参考:
ナレッジベースのデータソースを設定する
Knowledge Bases for Amazon Bedrock がメタデータフィルタリングをサポートし検索精度向上
社内文章を取り込み、同時にメタデータを作成する
③ ナレッジベースを参照した回答が得られるよう実装変更
SlackBotLambdaXXXXXXXX というLambda関数ができているはずなのでこちらに実装していきます。(XXXXXXXXには任意の英数字が入る)
最新のboto3を利用する
Lambdaに付属するboto3のバージョンが古く、モデルからのレスポンスに元データのメタデータ情報が含まれていなかったため、最新のboto3を使うように変更します。
$ mkdir python $ pip3 install boto3 -t ./python $ zip -r ./python.zip .
上記コマンドで作成したzipをLambdaレイヤーとして登録し、SlackBotLambdaXXXXXXXXに追加します。
参考:
Lambda でのレイヤーの作成と削除
関数へのレイヤーの追加
呼び出しを変更する
RAGを使いたいためdef call_bedrock(question) の中身をinvoke_modelからretrieve_and_generateへの呼び出しに変更します。呼び出すためのクライアントも「bedrock-runtime」から「bedrock-agent-runtime」に変更します。
サンプル
Before
bedrock_runtime_client = boto3.client('bedrock-runtime')
〜
def call_bedrock(question)
〜
response = bedrock_runtime_client.invoke_model(
body=body,
modelId=model_id,
accept=accept,
contentType=content_type
)
After
bedrock_agent_runtime_client = boto3.client('bedrock-agent-runtime')
〜
def call_bedrock(question)
〜
response = bedrock_agent_runtime_client.retrieve_and_generate(
input={
'text': question
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': knowledge_base_id,
'modelArn': model_id,
}
}
)
knowledge_base_idには作成したナレッジベースのIDを入れてください
参考:
Boto3 AgentsforBedrockRuntime / Client / retrieve_and_generate
回答にソース情報へのリンクを含める
回答はテキストに加え、メタデータを参照して回答のソースとなったドキュメントへのリンクも含めてみます。
response = bedrock_agent_runtime_client.retrieve_and_generate(〜
answer = make_answer(response)
〜
def make_answer(bedrock_response):
result_lines = []
for citation in bedrock_response["citations"]:
text_response_part = citation['generatedResponsePart']['textResponsePart']['text']
result_lines.append(text_response_part)
for ref in citation['retrievedReferences']:
md = ref['metadata']
ref_line = f"* "
result_lines.append(ref_line)
return "\n".join(result_lines)
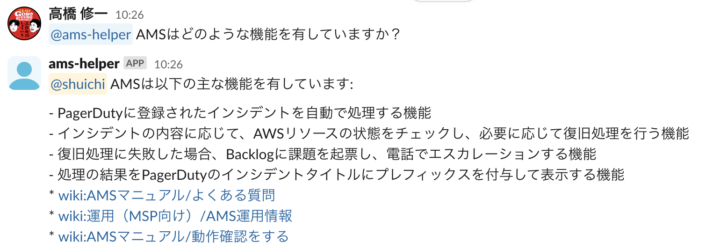
出力例
運用自動化ツールの社内wikiをナレッジベースに取り込んだbotでの出力例。

回答が重複するのを抑制する
Slackへのメッセージ送信はサンプルに実装されていますが、実際に試してみると1回の質問に対して複数回同じような回答が返ってきます。
これはSlackアプリがメンションで質問を受けたイベントがSlack側のリトライ機構によりAPI Gateway -> Lambdaに複数回到達することがあるためです。
リトライ時は「x-slack-retry-num」というヘッダにリトライ回数が入っています。
今回は簡易的にリトライの場合は何もせずskipする実装をhandlerの最初の方に入れて重複を緩和する方法で実装します。
if int(event['headers'].get("x-slack-retry-num",0)) > 0:
return {
'statusCode': 200,
'body': f"message skipped {slack_retry=}"
}
ただしこれだとイベント到達しなかったときのリトライを捨ててしまうので、きちんと対応したい場合は別の方法を取る必要があります。
レスポンスヘッダに「x-slack-no-retry: 1」を返すことでこれ以上のリトライを抑止できるようですが、回答を生成している間にリトライイベントが到達してしまうためか、これだけでは重複を抑制できませんでした。
リクエストの一意な情報を見て重複制御を実装する必要がありそうです。このあたりまた試してみようと思います。
参考:
Slack/Events API/ErrorHandling/Retries
まとめ
シンプルな仕組みなのでこれをベースに以下のようなことも試していけそうです。また何かあれば記事にも上げていこうと思います!
- 回答品質をあげるためプロンプトやRAGなどチューニング
- 「モデル」「ナレッジベース」「プロンプト」「チューニング」のセットをパラメータストアあたりにアプリ別に保持しておいて、リクエスト元のアプリに応じて切り替えることで、同じ仕組みで複数のbotをホスト



