
渋谷で開催されたGenerative AI Summit Tokyo ’24 Fallにて第一興商様の事例のセッションのレポートになります!
私の上司の西田が登壇しました!
セッション情報
「試す」から「使う」へ!生成 AI とデータ活用による第一興商様の業務改善策 第二弾!
社内に眠るあらゆるデータが業務改善やビジネスチャンスとなる可能性を秘めています。今回は、Google Cloud Next’24 にてご紹介した第一興商様の生成 AI 活用事例、業務改善システム開発の第二弾です。生成 AI を活用した業務改善アプリから取得したデータを用いた、データ分析プロジェクトについてご紹介します。Google Cloud と生成 AI がデータ活用の可能性をさらに広げます。
お客様の課題
DAMの運用業務の中で大きく2つの課題がありました。
- 楽曲リクエストデータの表記揺れに対する補正への人的コスト
- データの活用
楽曲リクエストデータの表記揺れに対する補正への人的コスト
カラオケで配信して欲しい楽曲をリクエストするフォームがあり、フォームは自由入力のため表記揺れがありそれらを補正(名寄せ)するのに毎月5人日ほどかけて実施していました。
データの活用
第一弾でリクエストデータの表記揺れの業務改善を行なったことで楽曲リクエストデータの活用はしやすくなりましたが、まだ未活用データが残っている課題がありました。
第一弾 リクエストデータの表記揺れの業務改善
楽曲リクエストデータの表記揺れに対する補正への人的コストへの改善内容について詳細を知りたい方は下記をご覧ください。
第二弾の実績と結果
第一弾との構成比較
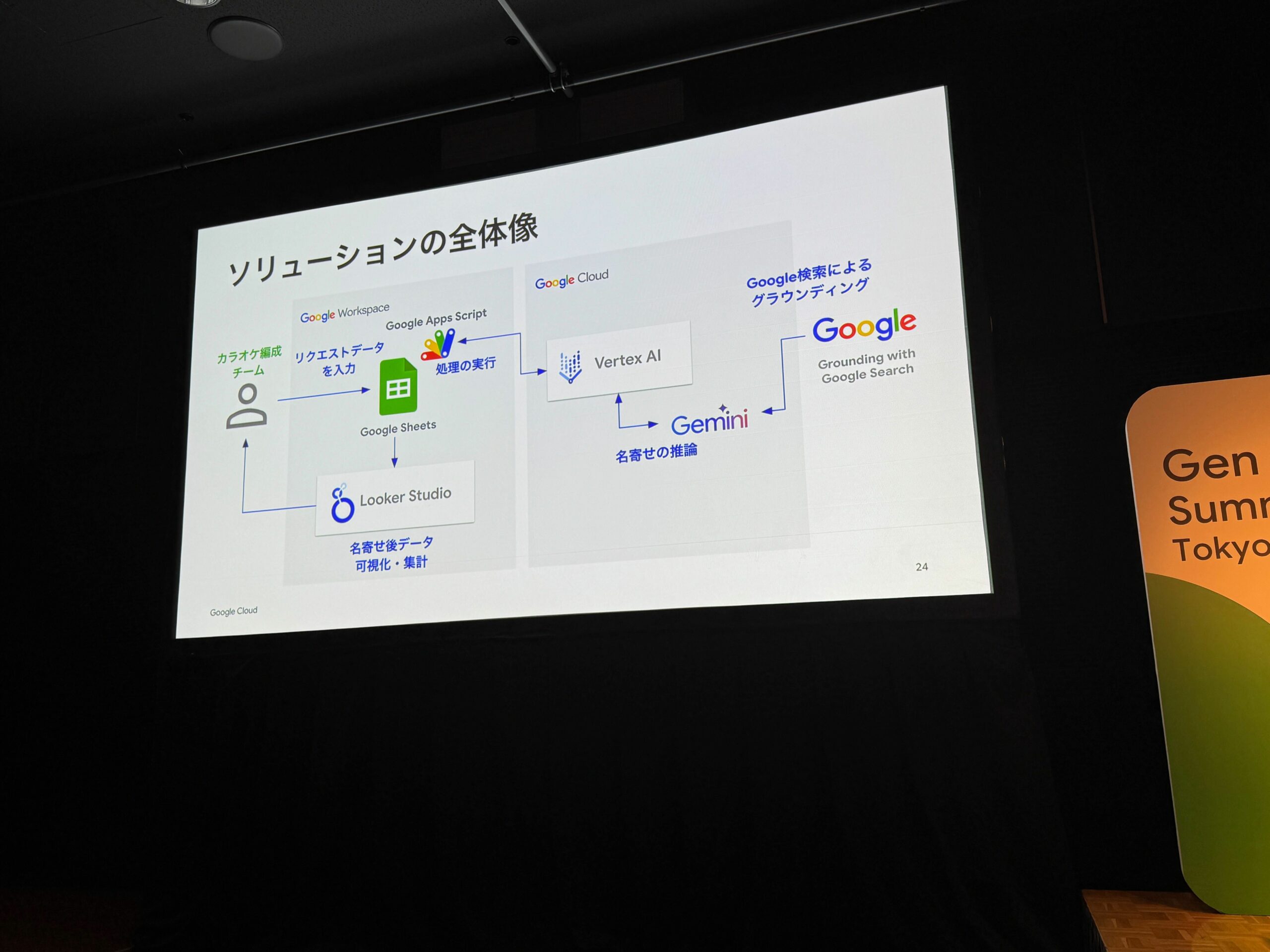 こちらが第一弾の楽曲リクエストデータを名寄せするための構成でした。
こちらが第一弾の楽曲リクエストデータを名寄せするための構成でした。
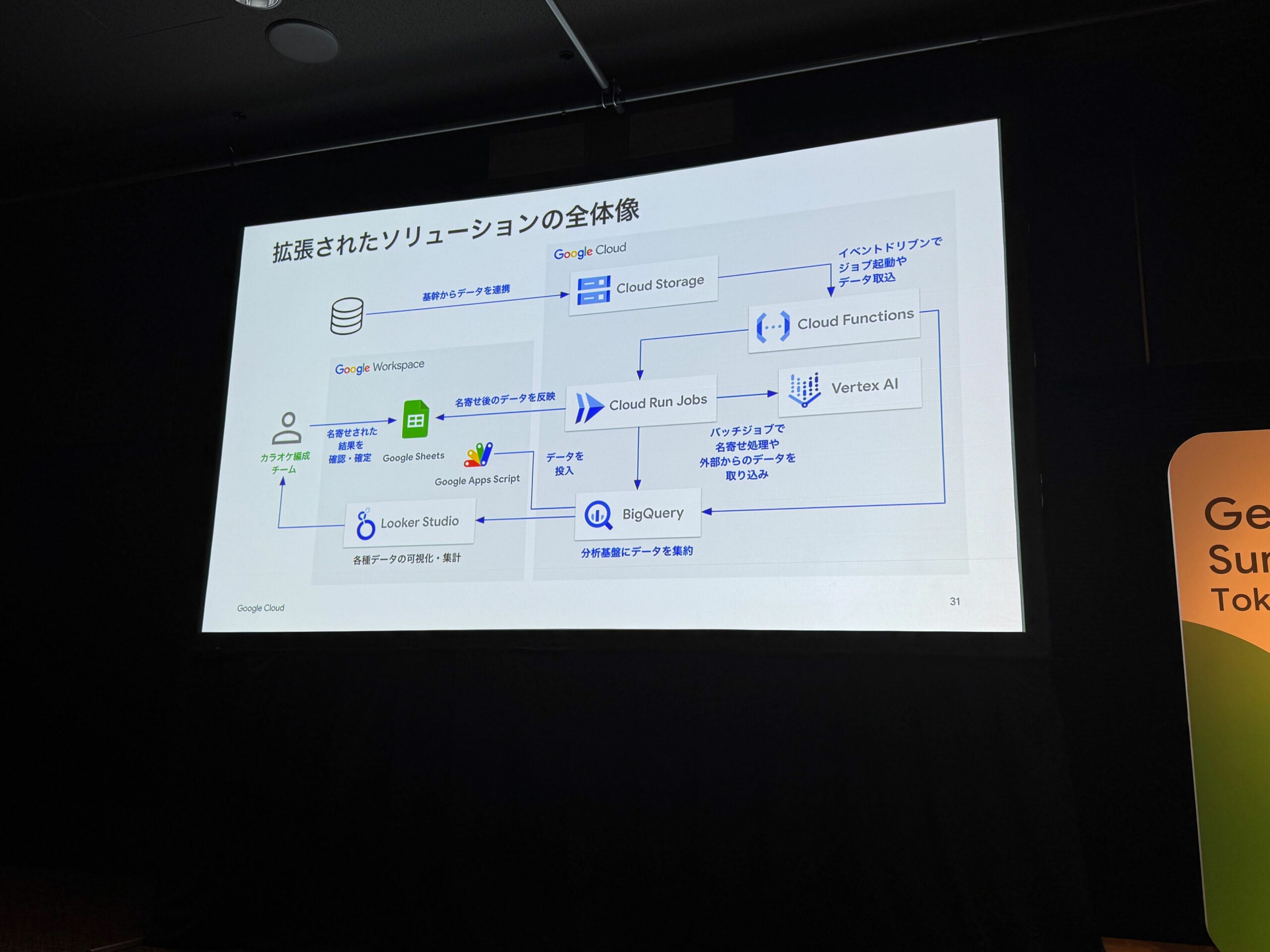
そしてこちらが、第二弾で拡張された構成です。
第一弾から拡張された部分として、基幹システムからのデータをCloud Storageにアップロードし、それらをCloud Run関数、Cloud Run Jobsを用いて、分析基盤としてのBigQueryにデータを集約する形に。
また、第一弾の名寄せ処理は、Google Apps Scriptで行なっていた名寄せをCloud Run Jobsに移行し処理を高速化させました。

蓄積されたデータを、Google Workspaceで利用可能なLooker Studioを用いて、名寄せ後の楽曲リクエストデータとDAMの配信済みの楽曲リクエストデータを突き合わせて、どの楽曲リクエストデータがまだDAMで配信されてないのかなどダッシュボードで可視化することができるようになりました。
 結果として、Looker Studioのダッシュボードで多様なデータを可視化することで、よりデータを活用した意思決定が可能になりました。
結果として、Looker Studioのダッシュボードで多様なデータを可視化することで、よりデータを活用した意思決定が可能になりました。
「PoC」から「本番運用」まで

今では、生成AIというワードを聞かない日がないくらい浸透している生成AIですが不確実性がどうしても伴い、思ったよりうまくいったり、いかなかったりということが発生します。
まずは、「試す」ためのPoCを安く早く実施し、それらがうまく行けば本番化して「使う」のフェーズに入っていくというアプローチにGoogle Cloudはうってつけということです。
最後に
変化が激しい時代において、よりデータを活用することは大事だなと改めて認識できるセッションでした。
私自身、第一興商様のプロジェクトに参加させていただいており、思いを馳せながらセッションを聴いておりました。
また今回の第一興商様の事例については、以下に情報がございますので是非ご覧になってください!
- 導入事例:生成 AI の活用で DX 促進! Google Cloud と Gemini で人的リソースのかかる集計業務を大幅改善
- ブログ:第一興商様導入事例とGoogle スプレッドシートとGeminiを組み合わせた生成AI活用について
- Google Cloud Next Tokyo ’24セッション内容:生成AI活用最前線!生成AIを活用した第一興商様の業務改善システム開発
生成AIの導入支援も行なっておりますので、是非お気軽にご相談ください。




