
Cloud Storage に保存された JSON ファイルを読み込む方法はいくつか考えられますが、ファイルサイズや用途により最適な方法が変わってきます。この記事では、json.loads、json.load、ijson を使った3つの方法を紹介しています。さらに補足ではメモリ使用量の比較も行います。
各種バージョン
Python 3.11.6 ijson 3.3.0 google-cloud-storage 2.18.2
3つの読み込み方法の例
以下の JSON ファイル(gs://your-bucket-name/example.json)を例にします。
{
"name": "Example Data",
"version": 1.0,
"features": [
{
"id": "1",
"name": "Feature A",
"value": 10
},
{
"id": "2",
"name": "Feature B",
"value": 20
}
]
}
また、エラー処理については触れません。
1. json.loads を使った方法
Blob クラス(Cloud Storage の Python API)の download_as_bytes メソッドでファイルをバイト列として読み込み、json.loads でパースします。
ファイル全体を一度にメモリに読み込むため、ファイルサイズが比較的小さい場合に適しています。
import json
from urllib.parse import urlparse
from google.cloud import storage
def load_json_from_gcs_loads(gcs_uri):
parsed_gcs_uri = urlparse(gcs_uri)
bucket_name = parsed_gcs_uri.netloc
object_name = parsed_gcs_uri.path.lstrip("/")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(object_name)
return json.loads(blob.download_as_bytes())
使用例
gcs_uri = "gs://your-bucket-name/example.json"
data = load_json_from_gcs_loads(gcs_uri)
print(data)
# 出力
{'name': 'Example Data', 'version': 1.0, 'features': [{'id': '1', 'name': 'Feature A', 'value': 10}, {'id': '2', 'name': 'Feature B', 'value': 20}]}
NOTE
公式ドキュメントに記載のとおり、download_as_string は非推奨のため download_as_bytes を使用しています。
Deprecated alias for download_as_bytes.
2. json.load を使った方法
Blob クラス の open メソッドでファイルオブジェクトを取得し、json.load でデータを読み込みます。
json.loads と同様、json.load もファイル全体をメモリに読み込んでからパースするため、巨大なファイルの場合にはメモリ不足となる可能性があります。
import json
from urllib.parse import urlparse
from google.cloud import storage
def load_json_from_gcs_load(gcs_uri):
parsed_gcs_uri = urlparse(gcs_uri)
bucket_name = parsed_gcs_uri.netloc
object_name = parsed_gcs_uri.path.lstrip("/")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(object_name)
with blob.open("r") as blob_file:
return json.load(blob_file)
使用例
gcs_uri = "gs://your-bucket-name/example.json"
data = load_json_from_gcs_load(gcs_uri)
print(data)
# 出力
{'name': 'Example Data', 'version': 1.0, 'features': [{'id': '1', 'name': 'Feature A', 'value': 10}, {'id': '2', 'name': 'Feature B', 'value': 20}]}
NOTE
load メソッドのソースコードを確認すると、内部的にはファイルオブジェクトの read メソッドの戻り値(テキスト I/O の場合は文字列)に対して loads メソッドを適用しています。
3. ijson を使った方法
巨大な JSON ファイルを扱ったり、そのうちの一部のみを読み込みたい場合などには ijson が適しています。ijson はストリーミングパーサーであり、メモリ使用量を抑えられます。以下は、特定のプレフィックスを持つアイテムのみを効率的に取得する例です。ファイルオブジェクトは Blob クラス の open メソッドで取得しています。
from urllib.parse import urlparse
import ijson
from google.cloud import storage
def load_json_from_gcs_ijson(gcs_uri, prefix):
parsed_gcs_uri = urlparse(gcs_uri)
bucket_name = parsed_gcs_uri.netloc
object_name = parsed_gcs_uri.path.lstrip("/")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(object_name)
with blob.open("r") as blob_file:
for item in ijson.items(blob_file, prefix):
yield item
使用例
gcs_uri = "gs://your-bucket-name/example.json"
prefix = "features.item" # "features"配列内の各オブジェクトを取得
data = load_json_from_gcs_ijson(gcs_uri, prefix)
for item in data:
print(item)
# 出力
{'id': '1', 'name': 'Feature A', 'value': 10}
{'id': '2', 'name': 'Feature B', 'value': 20}
prefix = "features.item.name" # "features"配列内の各オブジェクトの"name"値を取得
data = load_json_from_gcs_ijson(gcs_uri, prefix)
for item in data:
print(item)
# 出力
Feature A
Feature B
ijson.items を使用すると、prefix で指定したパスに一致するアイテムのみが抽出されます。ジェネレータ関数として実装することで、メモリ使用量を抑えながら巨大な JSON ファイルを効率的に処理できます。
他にも様々な解析パターンに対応しているので、詳しくは公式ドキュメントを参照ください。
NOTE
Options の説明のとおり、ファイルオブジェクトからの読み込みは buf_size で指定したサイズ単位(デフォルトで 64 KB)で行われます。
For functions taking a file-like object, an additional buf_size option (defaults to 65536 or 64KB) specifies the amount of bytes the library should attempt to read each time.
まとめ
この記事では、Cloud Storage から JSON ファイルを読み込むための3つの方法を紹介しました。
比較的小さなファイルやファイル全体を一度に扱いたい場合は json.loads または json.load、大規模ファイルやその一部のみを効率よく処理したい場合は ijson が適している考えられます。
補足 — メモリ使用量の比較
約 300 MB の JSON ファイルを読み込んだ際のメモリ使用量を Memory Profiler と Memray を用いて計測しました。
(sys.getsizeof(blob.download_as_bytes()) の結果は 305677726 ≈ 305.7 MB)
Memory Profiler による比較
line-by-line memory usage による結果は以下のとおりです(実行ごとに細かい数値は異なるが大まかな値は同じ)。
json.loads のプロファイル結果
Line # Mem usage Increment Occurrences Line Contents
=============================================================
5 87.7 MiB 87.7 MiB 1 def load_json_from_gcs_loads(gcs_uri):
6 87.7 MiB 0.0 MiB 1 parsed_gcs_uri = urlparse(gcs_uri)
7 87.7 MiB 0.0 MiB 1 bucket_name = parsed_gcs_uri.netloc
8 87.7 MiB 0.0 MiB 1 object_name = parsed_gcs_uri.path.lstrip('/')
9
10 88.0 MiB 0.2 MiB 1 storage_client = storage.Client()
11 88.0 MiB 0.0 MiB 1 bucket = storage_client.bucket(bucket_name)
12 88.0 MiB 0.0 MiB 1 blob = bucket.blob(object_name)
13
14 970.8 MiB 882.8 MiB 1 return json.loads(blob.download_as_bytes())
json.load のプロファイル結果
Line # Mem usage Increment Occurrences Line Contents
=============================================================
5 87.7 MiB 87.7 MiB 1 def load_json_from_gcs_load(gcs_uri):
6 87.7 MiB 0.0 MiB 1 parsed_gcs_uri = urlparse(gcs_uri)
7 87.7 MiB 0.0 MiB 1 bucket_name = parsed_gcs_uri.netloc
8 87.7 MiB 0.0 MiB 1 object_name = parsed_gcs_uri.path.lstrip('/')
9
10 88.0 MiB 0.2 MiB 1 storage_client = storage.Client()
11 88.0 MiB 0.0 MiB 1 bucket = storage_client.bucket(bucket_name)
12 88.0 MiB 0.0 MiB 1 blob = bucket.blob(object_name)
13
14 969.7 MiB 0.0 MiB 2 with blob.open("r") as blob_file:
15 969.7 MiB 881.7 MiB 1 return json.load(blob_file)
ijson のプロファイル結果
※本文で定義した load_json_from_gcs_ijson 関数の内部ではなく、関数が返すデータのメモリ使用量に着目しています。
Line # Mem usage Increment Occurrences Line Contents
=============================================================
24 87.8 MiB 87.8 MiB 1 def ijson_profile(gcs_uri, prefix="Records.item"):
25 87.8 MiB 0.0 MiB 1 data = load_json_from_gcs_ijson(gcs_uri, prefix)
26 87.8 MiB 0.0 MiB 1 count = 0
27 132.8 MiB 45.0 MiB 100 for item in data:
28 132.8 MiB 0.0 MiB 100 count += 1
29 132.8 MiB 0.0 MiB 100 if count >= 100:
30 132.8 MiB 0.0 MiB 1 break
json.loads および json.load はどちらもほとんど同じような結果となりました。ファイルサイズ自体は 300 MB 程度ですが、パースされたオブジェクトは 900 MB 程度となったことがわかります(return 行のメモリ増加量より)1。
どちらもファイル全体を一度に読み込んだ上でオブジェクトに変換するため、ファイルサイズが大きいとメモリ負荷が高くなる可能性があります。
一方、ijson を用いたコードでは各ジェネレータ式でのパース対象のサイズにも依りますが、メモリ使用量がファイル全体を読み込む場合と比較して大幅に抑えられていることがわかります。
指定した部分のみを逐次読み込むためメモリ効率が高く、巨大なファイルや特定データのみを処理する場面に有効です。
NOTE
公式ドキュメントに記載のとおり、line-by-line memory usage で得られる Mem usage, Increment は該当行を実行した後のメモリ使用量とその差分です。そのため、必ずしも実行中のピーク値を表すとは限りません。
the second column (Mem usage) the memory usage of the Python interpreter after that line has been executed. The third column (Increment) represents the difference in memory of the current line with respect to the last one.
Memray による比較
Flame Graph Reporter を用いてメモリ使用量を調べました。
json.loads の結果
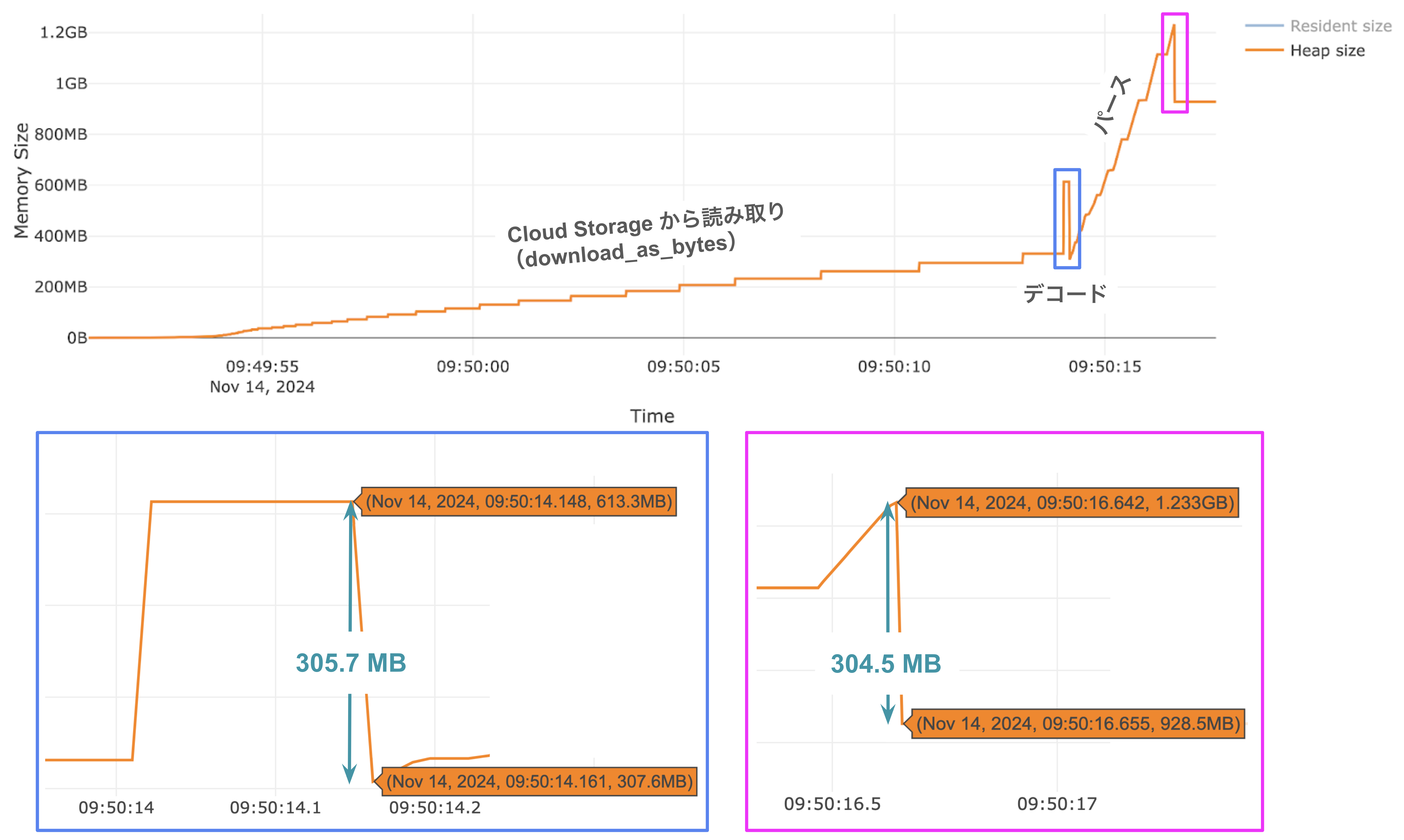
時系列グラフから使用メモリが徐々に増加していく様子が読み取れ、Cloud Storage からのダウンロード状況を表すと考えられます。
さらに興味深いこととして、二つのピークがあります。一つ目のピークはデコード処理を表す(変換元と変換先データの同時メモリ確保と、変換後の元データのメモリ解放)と推測されます。メモリ量の低下もファイルサイズと一致します。二つ目はパースに伴うもの(デコードされたデータとそれをパースしたデータのメモリを確保することで発生し、デコードされたデータ等のメモリ解放により低下)と考えられます。
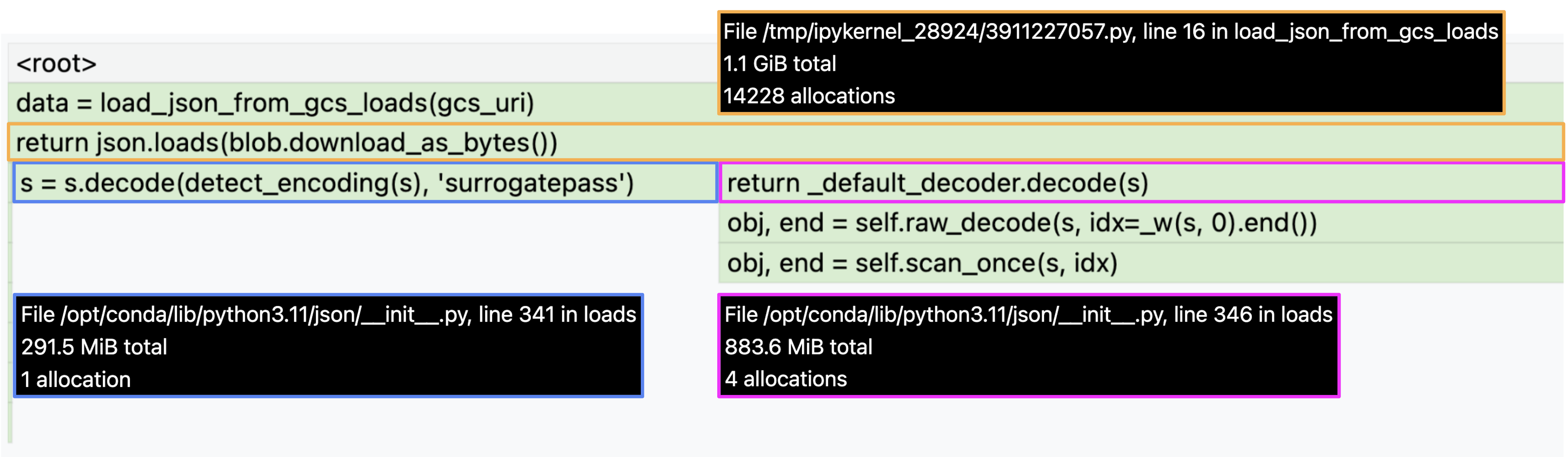
また、flame graph (icicle mode) から json.loads が return するオブジェクトのメモリ量は 883.6 MiB であり、 Memory Profiler での return 行でのメモリ増加量とほぼ同等であることがわかります。
ijson の結果
※Memory Profiler での実行(イテレートを100回に制限)とは異なり、ファイル全体を走査しています。
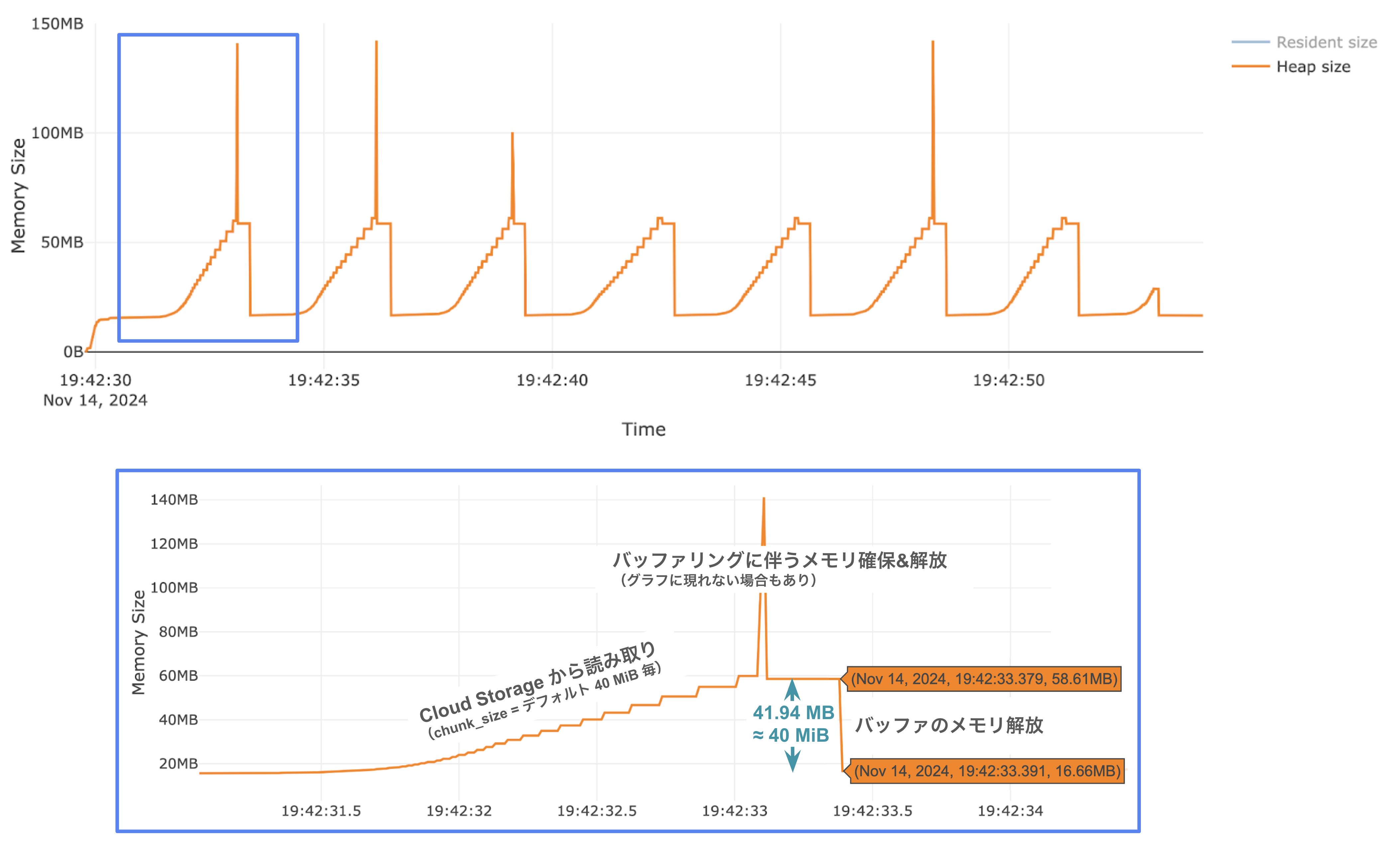
時系列グラフを見ると山が8つあることがわかります。この数は Cloud Storage が chunk_size (デフォルト 40 MiB)単位でダウンロードした結果と考えられます。実際、大きな山が7個(7 × 40 MiB)と最後の小さな山のサイズを足し合わせるとちょうど JSON ファイルと同等のデータサイズとなり、8回に分けてファイル全体がダウンロードされたことが推測されます(ijson のファイルオブジェクトからの読み取りは 64 KB単位で行われ、今回の例ではジェネレータが200,000回イテレートされます。そのため、はじめは8つの山の意味を理解できていませんでした)。
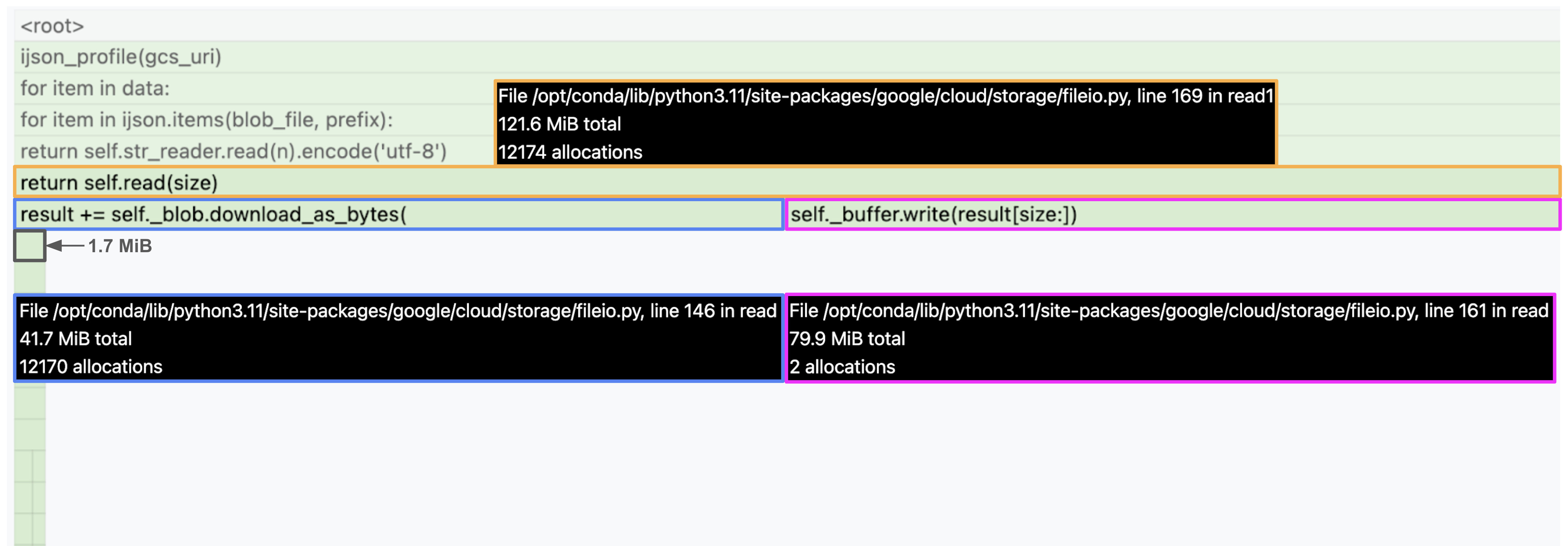
また、鋭いピークについては flame graph も踏まえて、read メソッドでのスライス処理とバッファへの書き込みのためのメモリ確保の影響だと考えられます2。
self._buffer.write(result[size:])
NOTE
Blob クラス の open メソッドの chunk_size サイズの説明。デフォルトでは 40 MiB。chunk_size より小さい読み込み要求があった場合(ijson の例では 64 KB)でも chunk_size の分だけダウンロードされ、残りはバッファリングされる。
For reads, the minimum number of bytes to read at a time. If fewer bytes than the chunk_size are requested, the remainder is buffered. For writes, the maximum number of bytes to buffer before sending data to the server, and the size of each request when data is sent. Writes are implemented as a “resumable upload”, so chunk_size for writes must be exactly a multiple of 256KiB as with other resumable uploads. The default is 40 MiB.
Flame Graph Reporter 作成に使用したコード
Jupyter Notebook で実行しました。
%%memray_flamegraph data = load_json_from_gcs_loads(gcs_uri) time.sleep(1)
%%memray_flamegraph
def ijson_profile(gcs_uri, prefix):
data = load_json_from_gcs_ijson(gcs_uri, prefix)
for item in data:
pass
ijson_profile(gcs_uri)
time.sleep(1)
補足 — サンプルファイルに関するメモリサイズ
sys.getsizeof と recursive sizeof recipe の total_size を使用。
str_sample = """{
"name": "Example Data",
"version": 1.0,
"features": [
{
"id": "1",
"name": "Feature A",
"value": 10
},
{
"id": "2",
"name": "Feature B",
"value": 20
}
]
}"""
sample = json.loads(str_sample)
print(f"文字列長: {len(str_sample)}")
print(f"空文字列のメモリサイズ: {sys.getsizeof('')} B")
print(f"サンプル文字列のメモリサイズ: {sys.getsizeof(str_sample)} B")
print(f"パースされたオブジェクトのメモリサイズ: {total_size(sample)} B")
出力
文字列長: 216 空文字列のメモリサイズ: 49 B サンプル文字列のメモリサイズ: 265 B パースされたオブジェクトのメモリサイズ: 1268 B

