
大量のドキュメントが Cloud Storage に階層的に保存されている場合、それらを個別に登録していては手間がかかります。そこで本記事では、そうした非構造化データを Vertex AI Search で活用するために一括で登録する方法を解説します。
背景
複数階層にまたがったファイル群を一括で取り込むためには、「リンクされた非構造化ドキュメント(JSONL とメタデータ)」を使用する必要があります1。
なぜなら、公式ドキュメントに記載のとおり、メタデータなしではフォルダを選択したとしても再帰的にはインポートされないためです。
Data import is not recursive. That is, if there are folders within the bucket or folder that you specify, files within those folders are not imported.
JSONL ファイルを用いて、Cloud Storage 内のファイルパスとメタデータを記述することで、階層構造にあるドキュメントを一括でデータストアに登録することができます。
JSONL ファイル生成コード
以下の Python コードは、Cloud Storage に保存されたファイル一覧を取得し、メタデータを含む JSONL ファイル (metadata.jsonl) を生成します。
import json
from pathlib import Path
from typing import Iterable
from google.cloud import storage
SUFFIXES = [
"pdf",
"html",
"txt",
"docx",
"pptx",
"xlsx",
]
def generate_json_lines(
bucket_name: str, blobs: Iterable[storage.Blob]
) -> Iterable[str]:
for blob in blobs:
uri = f"gs://{bucket_name}/{blob.name}"
record = {
"id": blob.id.split("/")[-1],
"structData": {
"title": Path(blob.name).stem,
},
"content": {
"mimeType": blob.content_type,
"uri": uri,
},
}
yield json.dumps(record, ensure_ascii=False)
def main():
bucket_name = "your-bucket-name"
prefix = "prefix/"
match_glob = f"**/*.{{{','.join(SUFFIXES)}}}"
storage_client = storage.Client()
blobs = storage_client.list_blobs(bucket_name, prefix=prefix, match_glob=match_glob)
metadata_file = "metadata.jsonl"
with open(metadata_file, "w", encoding="utf-8") as f:
for line in generate_json_lines(bucket_name, blobs):
f.write(line + "\n")
if __name__ == "__main__":
main()
データストアへの登録
以下の手順により、生成した JSONL ファイルをデータストアに登録できます。
- 生成された
metadata.jsonlを任意のGCSロケーションにアップロード - Agent Builder の「データストアの作成」画面からデータソースとして Cloud Storage を選択
- インポートするデータの種別を「リンクされた非構造化ドキュメント(JSONL とメタデータ)」に設定
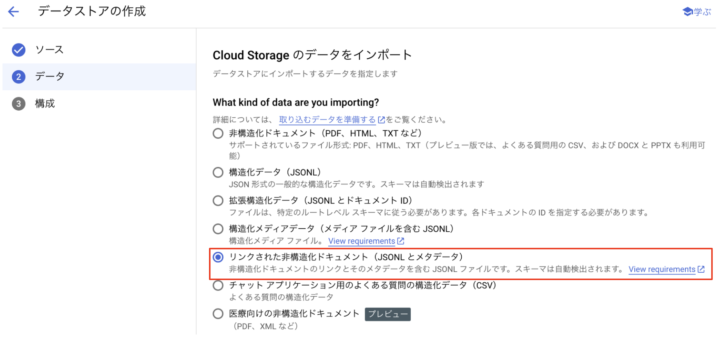
- アップロードした JSONL ファイルをインポートファイルとして指定
- データストアの構成で目的のドキュメントパーサーを指定
コードの解説
インポート対象ファイルの抽出
storage_client.list_blobs(bucket_name, prefix=prefix, match_glob=match_glob)
では、インポート対象の指定を行います。
prefix: バケット内の特定の階層以下のオブジェクトを対象とするために設定(接頭辞フィルタを使用してバケット内のオブジェクトを一覧表示する)。match_glob: サポートされたファイル形式のみ返されるよう設定。これにより、インポートできないファイル形式がデータストアに登録されることを防ぐ(加えて処理対象ファイルを最小限にする)ことを目的としています。
Vertex AI Search の非構造化データでは PDF、HTML、TXT、DOCX (Preview)、PPTX (Preview)、XLSX (Preview)形式のファイルを扱うことができます23。
そこで、今回は各ファイルの拡張子の形式を想定して以下のようにglobのパターンを生成しています。match_glob で使えるパターンについてはList objects and prefixes using globを参考にしてください。
SUFFIXES = [
"pdf",
"html",
"txt",
"docx",
"pptx",
"xlsx",
]
print(f"**/*.{{{','.join(SUFFIXES)}}}")
# 出力
**/*.{pdf,html,txt,docx,pptx,xlsx}
メタデータの生成
generate_json_lines 関数は、各ファイルのメタデータを JSONL 形式で生成します。
record = {
"id": blob.id.split("/")[-1],
"structData": {
"title": Path(blob.name).stem,
},
"content": {
"mimeType": blob.content_type,
"uri": uri,
},
}
id:Blobオブジェクトのidプロパティのうち、末尾の数値文字列のみを抜き出して使用しています。idとして指定できる文字列長には上限があり、それを超えると以下のようにエラーとなります。
"document.id" must have length equal to or less than the maximum length limit of 63 charactersstructData: 構造化データ。ここではtitleとしてファイル名から拡張子を除いた部分を設定しています。
まとめ
本記事では、Cloud Storage の階層構造にある非構造化データを Vertex AI Search のデータストアに一括登録する方法を解説しました。この方法を活用することで、大量のドキュメントに対する検索システムを効率的に構築できます。
また、作成したメタデータファイルを活用した例などについては、以前の記事であるLangGraph で Vertex AI Search retriever を使用した簡単な ReAct agent の作成、【Vertex AI Search】非構造化データの検索結果リンクを自由に設定などもご参考ください。