
こんにちは、MSPの田所です。
AWS re:Invent 2024 のレポートです。
現場のイベント模様をお届けします。
セッション情報

Don’t get stuck: How connected telemetry keeps you moving forward
システムのトラブルシューティングの本質を教えます!
When you’re troubleshooting a problem, the worst feeling is getting stuck—you’re out of ideas and don’t know what to do next. In this session, learn about the three fundamental types of failure and a set of strategies to keep you moving forward as you troubleshoot, as well as strategies for remediation once you’ve found the problem. While these strategies can work with any observability toolchain, this session focuses on applying them using Amazon CloudWatch. Also discover recent CloudWatch features that can help guide you through troubleshooting.
システムのトラブルシューティングを一般化した上で、どうやったら早く解決に辿り着けるかコツを伝授します!
Session types: Breakout session
1時間の Breakout セッション
今回のまとめ
- トラブルシューティングのアルゴリズム化
- 従来のトラブルシューティングの実演
- CloudWatch Investigations を使った実演
セッションの詳細
トラブルシューティングとは何か?
インシデントが発生した時の最優先事項は、発生原因を見つけて復旧することです。
これをトラブルシューティングと呼びます。
そしてその後、根本原因を取り除くべく詳しい原因分析と対策を行います。

トラブルシューティングは、調査のためのツールや、戦術、戦略といった技術を組み合わせて行います。

トラブルシューティングの時の頭の中をメタ認知すると、やるべきことやパターンの一般化ができます。

原因には大きく分けて 5 つあると言います。
- 自分で加えた変更
- システムが加えた変更
- 上限に到達
- 構成要素のひとつが失敗
- 依存関係が失敗
そして原因に対して、ロールバックする、ブロックする、スケールアップする、再起動する、除外する、などのアクション候補が考えられます。

アルゴリズム化するとこうなります。
生粋のエンジニアですね。

トラブルシューティングの例
ALB 配下の EC2 でアプリケーションを稼働させており、ALB が 5XX エラーを返している時を想定します。
先ほどのトラブルシューティングのパターンに沿ってチェックしていきます。

CloudWatch アラームにて ALB 5XX エラーを検知しました。
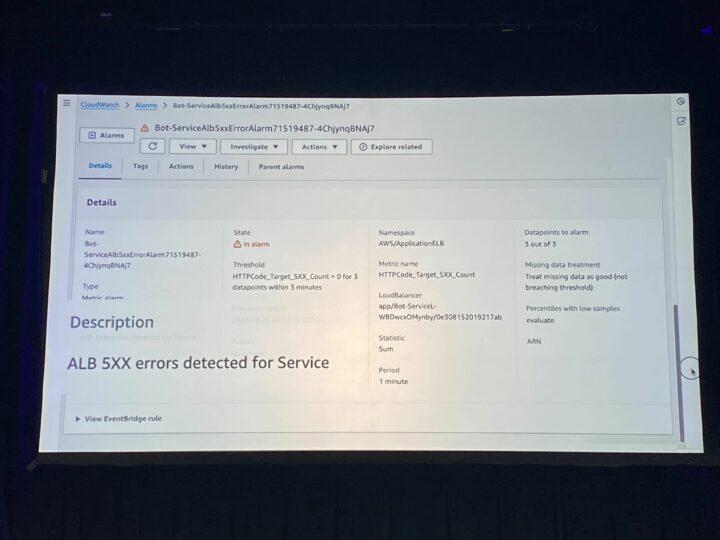
まず、ALB のメトリクスを見ます。
リクエスト数が上がっているようにも見えますが、はっきりしたことは言えません。

次にターゲットグループの UnHealthyHostCount を確認しますが、変化はありません。

インスタンスごとの CPU 使用率にも変化はありません。
この時点で、システム的な変更がかかっていたり、何かの上限に引っ掛かっている可能性は低そうです。

そしてログ情報を見にいくと、何やらアプリケーションのログが大量に出ています。
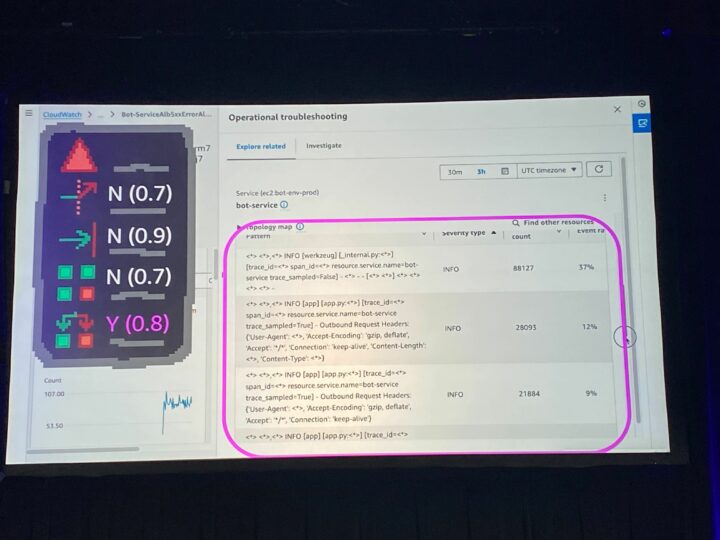
X-Ray Trace を確認すると、bot-forge にてエラーが起こっていることが分かります。

bot-forge で失敗したリクエストを見ると、特定のインスタンスのみで失敗していました。
原因箇所の特定ができました。

調査の流れをまとめるとこのようになります。

ここでやや複雑なところは、原因調査の過程でインフラの階層からアプリケーションの階層に移る必要があることです。
これにはログとトレースの情報が紐付いている必要があります。

Amazon Q Developer in Amazon CloudWatch
CloudWatch で Amazon Q Developer を使える Investigations という機能が発表されました。
CloudWatch 内の多くのメニューから Investigations を開始できるのですが、例えば失敗が確認されたサービスから Investigation を作成します。

対象サービスの Investigation が作成されました。
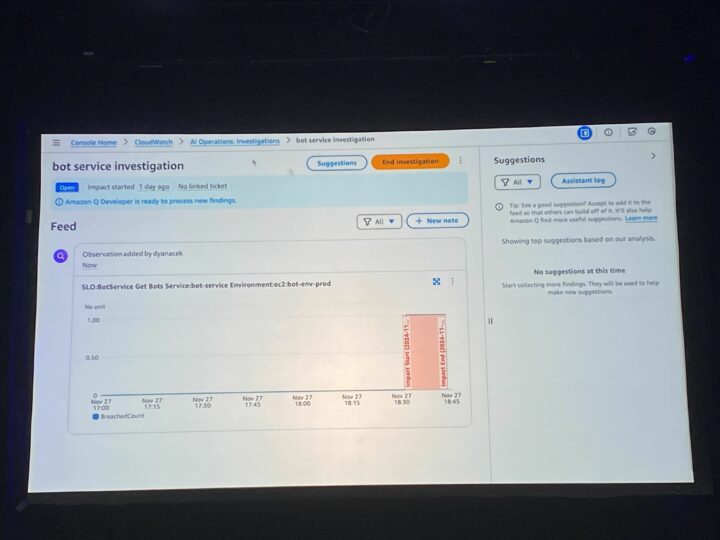
DynamoDB でポリシーが変更されたことが原因の候補として表示されました。

根本原因の仮説を提示してくれます。

対処のステップまで提示してくれます。
権限自体を見直す他、ポリシー変更のプロセスを見直すよう再発防止策まで提案してくれます。
至れり尽くせりですね。

MSPとして
1. アルゴリズム化する
トラブルシューティングで怪しい箇所の仮説を立てて、それを検証する流れは何度も経験してきました。
ただ今回、綺麗にアルゴリズム化されているのを見て、一般化して語るにはこのくらいの深さが必要であると思い知りました。
またトラブルシューティングをアルゴリズム化できるなら、広く業務はアルゴリズム化可能であるとも感じました。
効率化や自動化を考えるにあたり、重要な要素であるように思います。
2. 生成AI を使いこなす
生成AI の力を借りれば、状況把握、原因調査、対策の労力を大きく減らすことができるようになりました。
実装となるとかなりのハードルの高さですが、機能を使いこなすことなら可能です。
効率を上げるためにあらゆるツールや技術に手を出していくマインドは、今後ますます重要になってくると感じます。
おわりに
トラブルシューティングの一般化と、CloudWatch の新機能を使っての実例を見てきました。
新機能も素晴らしいのですが、David Yanacek氏 の理路整然さに感動しっぱなしでした。
改めて AWS のタレントはとんでもないと溜息が出るのでした。
おしまい