
YOLO(You Only Look Once)とは
物体検出手法の一種であり、動画像内の物体に対して物体名と信頼度の表示がリアルタイムで可能。
YOLOは、ワシントン大学のジョセフ・レッドモンとアリ・ファルハディによって開発され、現在はバージョン11まで存在する(2024/12/23時点)。
以下は、YOLOが出力した画像である。
 出典:
出典:画像を見ると、バウンディングボックスと呼ばれる四角の枠で囲われ、personやtieといった物体名が表示されており、その横に0.67など信頼度が表示されている。
ただ、スーツや顔などの物体は検出されていない・・
検出している物体、検出していない物体、、、この差はYOLOのモデルが関係している。
YOLOにおけるモデル
YOLOには、先ほどの例で使用された「既存モデル」と「独自モデル」というモデルが存在する。
- 既存モデル:事前に用意されている学習済みのモデルであり、犬や猫など80種類の物体を学習なしで検出が可能
-> 先ほどの例でスーツや顔が表示されなかったのは、既存モデルに含まれていなかったからである。
- 独自モデル:検出したい物体のデータを自ら用意し、学習させるモデルであり、多様な物体の検出が可能
-> 学習させれば何でも検出できるわけではなく、物体が小さかったり、遠すぎたりすると検出できない。
Ultralytics YOLO11とは
前述したYOLOのバージョン11であり、検出精度と速度が上昇している。
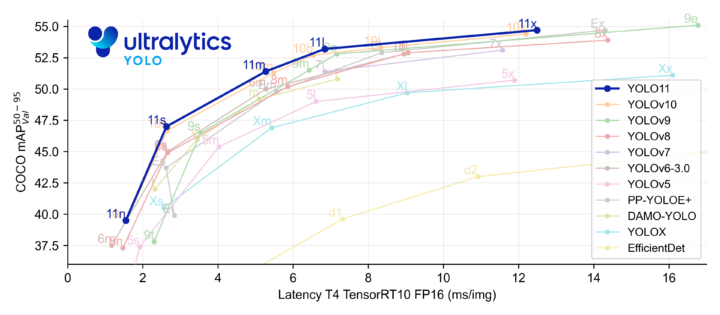 出典:YOLO11
出典:YOLO11
また、先ほどの物体検出(Object Detection)に加えて、「インスタンス分類」、「画像分類」、「姿勢推定」、「指向性物体検出」が利用可能である。
- インスタンス分類(Instance Segmentation):動画像内の物体に対して、物体に合わせた検出が可能
-> 以下の画像を見ると、ワンちゃんの形に型取られ、検出している。

- 画像分類(Image Classification):動画像内の物体をあらかじめ定義したクラスへの分類が可能
-> 以下の画像を見ると、左上に文字と数値が書かれているが、文字は模様と猫ちゃんの種類で、数値は信頼度を表している。tabbyはタビー柄のことなので合っているが、その他の猫の種類は合っていない。
この猫ちゃんは、アメリカンショートヘアとエキゾチックショートヘアのミックスだそうです。

- 姿勢推定(Pose Estimation):動画像内の人間の関節を識別し、骨格の推定が可能
->以下の画像と見ると、人間の関節が色ごとに表示されている。

- 指向性物体検出(Oriented Bounding Boxes Object Detection):動画像内の物体の向きに合わせて回転したバウンディングボックス(四角の枠)での物体の検出が可能
-> 先ほどのバウンディングボックスを見ると、形は変わっても、向きまでは変わっていないが、以下の画像だと、大量の船の向きに合わせて、バウンディングボックスが表示されている。
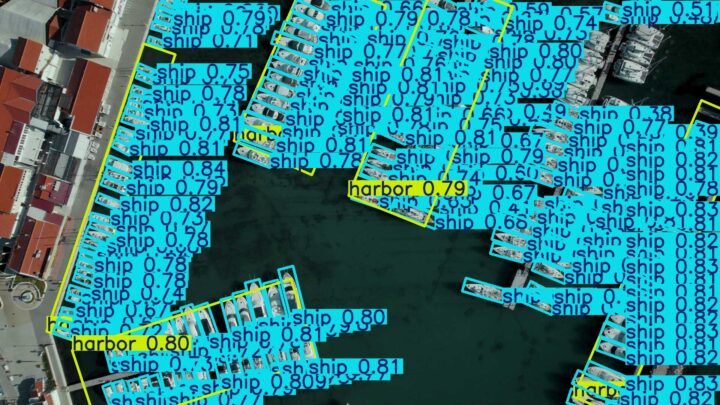
以上がYOLO11の機能である。
YOLOの実装は簡単なので、興味があれば、ぜひやってみてほしい。
参考資料
Ultralytics: HOME, <https://docs.ultralytics.com/>, (2024/12/25)
Ultralytics: 画像をAIに変換し, コードなしで有用な洞察を得る, <https://www.ultralytics.com/ja>, (2024/12/25)
画像提供(犬・猫):同期のHくん

