
今回はPythonと各種ライブラリを使って
画像処理用の環境をセットアップする方法と
簡単な画像処理の手順について紹介してみます。
画像処理って何?

画像処理とは簡単に説明すると
「画像を変形する」「画像内の色を変更する」
「画像から何らかの情報を取り出す」
といった画像に関する幅広い処理のことを指します。
画像の色合いを変えることで画像内のノイズやぼけを取り除き
画像を見やすくしたり、画像内のものを識別することで
コンピュータやロボットを手助けしたりと
日常生活でもさまざまな場面で活用されている技術です。
今回はこの画像処理をPythonを使って
簡単に体験してみようという内容になります。
デモの流れ
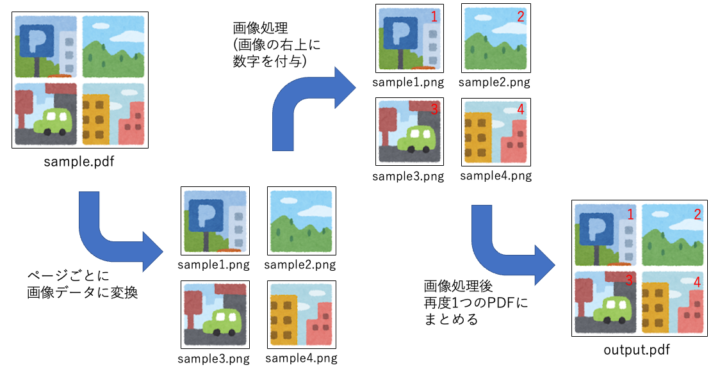
今回入力データとしてPDF形式のデータを用意して
ページごとに画像に変換した上で画像処理を実施、
その後再度PDFに戻すという流れでデモを進めていきます。
環境のセットアップ
Pythonの導入については省略します。
使用するライブラリを以下にまとめておくので
それぞれpip経由でインストールしておきましょう。
| pdf2image | PDFファイル形式のデータを画像形式に変換する目的で使用 https://pypi.org/project/pdf2image/ |
| numpy | pdf2imageで変換後の画像データを 後述のcv2ライブラリに渡す際に使用 https://pypi.org/project/numpy/ |
| cv2 | 画像処理に使用するメインのライブラリ https://pypi.org/project/opencv-python/ |
| pillow | PDF出力時に画像を読み込むために使用 https://pypi.org/project/pillow/ |
| reportlab | 画像処理後のPDF生成で使用 https://pypi.org/project/reportlab/ |
※pdf2imageライブラリを使用する前に
macOSではhomebrew経由でpopplerと呼ばれるライブラリを
入れておく必要があるので注意しましょう
エラーが発生してライブラリを使用できなくなります
画像処理を試してみよう
1. はじめに
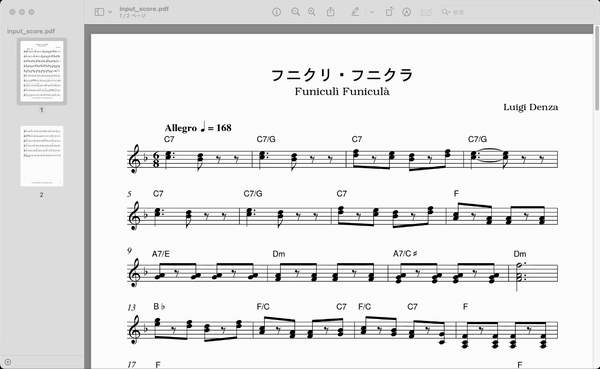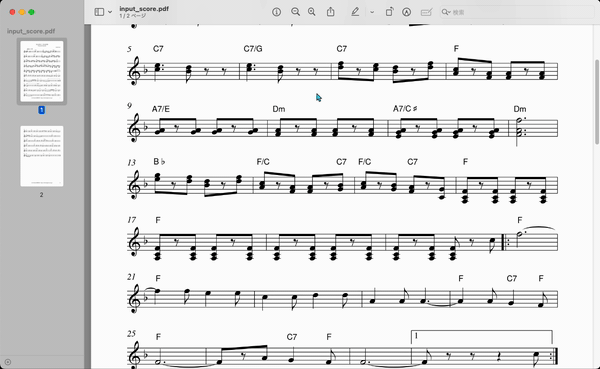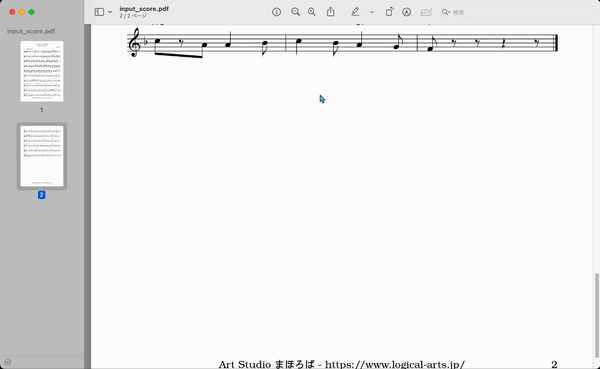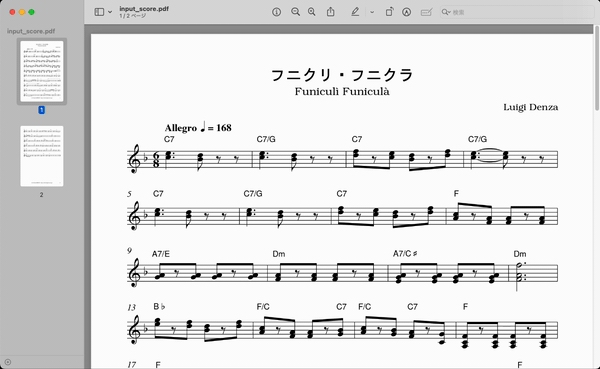
今回画像処理に使用するデータとして
計2ページの楽譜データを含んだPDFを用意しました。
※楽譜データは著作権切れのため無料で利用可能なものになります
2. PDFから画像を抽出
まずPDFの形式ではcv2ライブラリで画像処理を実施することができないので
一度画像形式に変換処理を行います。
import pdf2image
import cv2 as cv
import numpy as np
def main():
# PDFより画像データを取得(ページ数も取得しておく)
pdfimages = pdf2image.convert_from_path("input_score.pdf")
page_count = len(pdfimages)
for i in range(page_count):
# 画像処理ライブラリで加工できる形式に
cvimage = np.asarray(pdfimages[i]).copy()
# 画像を表示
cv.imshow(f"output image {i + 1} sample", cvimage)
cv.waitKey(0)
if __name__ == "__main__":
main()
8行目:pdf2image.convert_from_path()で対象のPDFを指定して画像データへの変換を行い、
13行目:np.asarray()でさらに画像データを画像処理可能な形式に変換します。
16行目:cv.imshow()で対象の画像を別ウィンドウで表示することができます。
17行目:cv.waitKey()でキー入力を受けとったタイミングで次の画像を表示する形で実装しています。

3. 簡単な画像処理を実施
線の描画
import pdf2image
import cv2 as cv
import numpy as np
def main():
# PDFより画像データを取得(ページ数も取得しておく)
pdfimages = pdf2image.convert_from_path("input_score.pdf")
page_count = len(pdfimages)
for i in range(page_count):
# 画像処理ライブラリで加工できる形式に
cvimage = np.asarray(pdfimages[i]).copy()
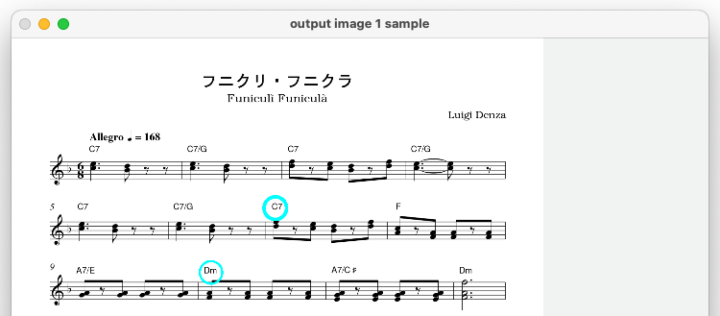
# 線の描画
cv.line(cvimage, (240, 330), (470, 330), (0, 0, 255), 3)
# 画像を表示
cv.imshow(f"output image {i + 1} sample", cvimage)
cv.waitKey(0)
if __name__ == "__main__":
main()
16行目:cv.line()で線を引くことができます。
引数については画像データ、線の始点座標、線の終点座標、線の色、線の太さを順に指定しています。
座標については画像の左上を(0, 0)として
画像の右部にいくほどx座標の数値が大きく、
画像の下部にいくほどy座標の数値が大きくなります。
色についてはRGBの数値をそれぞれ255段階で指定するのですが
cv2ライブラリではBGRの順番で指定する必要があるので注意が必要です。
(今回はRのみ255なので赤色の線が描画される)

円の描画
import pdf2image
import cv2 as cv
import numpy as np
def main():
# PDFより画像データを取得(ページ数も取得しておく)
pdfimages = pdf2image.convert_from_path("input_score.pdf")
page_count = len(pdfimages)
for i in range(page_count):
# 画像処理ライブラリで加工できる形式に
cvimage = np.asarray(pdfimages[i]).copy()
# 円の描画
cv.circle(cvimage, (820, 530), 35, (255, 255, 0), 10)
cv.circle(cvimage, (620, 730), 35, (255, 255, 0), 6)
# 画像を表示
cv.imshow(f"output image {i + 1} sample", cvimage)
cv.waitKey(0)
if __name__ == "__main__":
main()
16行目:cv.circle()で円を描くことができます。
引数については画像データ、円の中心座標、円の半径、線の色、線の太さを順に指定しています。
テキストの描画
import pdf2image
import cv2 as cv
import numpy as np
def main():
# PDFより画像データを取得(ページ数も取得しておく)
pdfimages = pdf2image.convert_from_path("input_score.pdf")
page_count = len(pdfimages)
for i in range(page_count):
# 画像処理ライブラリで加工できる形式に
cvimage = np.asarray(pdfimages[i]).copy()
# テキストの描画
font = cv.FONT_HERSHEY_SIMPLEX
cv.putText(cvimage, "OpenCV", (80, 200), font,
4, (0, 255, 0), 2, cv.LINE_AA)
# 画像を表示
cv.imshow(f"output image {i + 1} sample", cvimage)
cv.waitKey(0)
if __name__ == "__main__":
main()
17行目:cv.putText()でテキストを追記できます。
引数については画像データ、追記するテキスト、テキストの座標、フォント、
文字サイズ、文字色、文字の太さ、テキストの出力方式を順に指定しています。

今回紹介した画像処理はあくまで一例で
他にも多くの関数が用意されています。
もし興味がある人はリファレンスを読んで色々試してみてください。
https://docs.opencv.org/4.x/index.html
4. 加工後の画像を出力
37行目:cv.imwrite()を使うことで画像処理後の画像を出力することができます。
今回はoutputフォルダを作成し、その中に画像を出力しています。
import os
import pdf2image
import cv2 as cv
import numpy as np
def main():
# PDFより画像データを取得(ページ数も取得しておく)
pdfimages = pdf2image.convert_from_path("input_score.pdf")
page_count = len(pdfimages)
# 画像出力先のディレクトリを作成
if not os.path.exists("output"):
os.makedirs("output")
for i in range(page_count):
# 画像処理ライブラリで加工できる形式に
cvimage = np.asarray(pdfimages[i]).copy()
# 線の描画
cv.line(cvimage, (240, 330), (470, 330), (0, 0, 255), 3)
# 円の描画
cv.circle(cvimage, (820, 530), 35, (255, 255, 0), 10)
cv.circle(cvimage, (620, 730), 35, (255, 255, 0), 6)
# テキストの描画
font = cv.FONT_HERSHEY_SIMPLEX
cv.putText(cvimage, "OpenCV", (80, 200), font,
4, (0, 255, 0), 2, cv.LINE_AA)
# 画像を表示
cv.imshow(f"output image {i + 1} sample", cvimage)
cv.waitKey(0)
# 加工後の画像を出力
cv.imwrite(f"output/output{i + 1}.png", cvimage)
if __name__ == "__main__":
main()
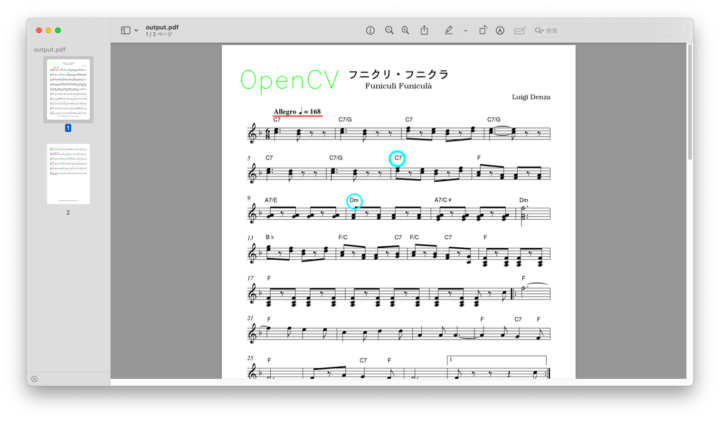
さらに画像を1つのファイルにまとめてPDF形式にしたい場合は
reportlabライブラリを使用します。
import os
import pdf2image
import cv2 as cv
import numpy as np
from PIL import Image
from reportlab.pdfgen import canvas
def main():
# PDFより画像データを取得(ページ数も取得しておく)
pdfimages = pdf2image.convert_from_path("input_score.pdf")
page_count = len(pdfimages)
for i in range(page_count):
# 画像処理ライブラリで加工できる形式に
cvimage = np.asarray(pdfimages[i]).copy()
# 線の描画
cv.line(cvimage, (240, 330), (470, 330), (0, 0, 255), 3)
# 円の描画
cv.circle(cvimage, (820, 530), 35, (255, 255, 0), 10)
cv.circle(cvimage, (620, 730), 35, (255, 255, 0), 6)
# テキストの描画
font = cv.FONT_HERSHEY_SIMPLEX
cv.putText(cvimage, "OpenCV", (80, 200), font,
4, (0, 255, 0), 2, cv.LINE_AA)
# 画像を表示
cv.imshow(f"output image {i + 1} sample", cvimage)
cv.waitKey(0)
# 画像出力先のディレクトリを作成
if not os.path.exists("output"):
os.makedirs("output")
# 新規PDFファイルを作成
c = canvas.Canvas("output.pdf", pagesize=(1655, 2340))
for i in range(page_count):
# PDFに画像を挿入
image = Image.open(f"output/output{i + 1}.png")
width, height = image.size
c.drawImage(f"output/output{i + 1}.png", 0, 0, width, height)
# 改ページ
c.showPage()
# PDFファイルを保存
c.save()
if __name__ == "__main__":
main()
46行目:drawImage()で先ほど画像処理を実施した画像をPDFに追加、
49行目:showPage()で次のページへ移動する処理を画像の枚数だけ繰り返して
最終的に1つのPDFファイルを作成します。
まとめ
今回はPythonを使った簡単な画像処理について紹介してみました。
PDF形式のファイルに画像処理を実施するケースは
意外と業務でも役立つ場面があるかと思うので皆さんの役に立てば嬉しいです。



